 夜雨聆风
夜雨聆风研究AIOps已有大半年,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。
如果你一直看我公众号文章,那你一定了解我的案例大部分都是使用MCP。然而就有一些朋友说:现在都用Skill了,你还在搞MCP,这都要淘汰的东西了。
其实,我想说的是在AIOps领域里,这个MCP我们还真不能扔掉,它依然是一个非常重要的组件。今天这篇文章就跟大家深入聊聊AIOps领域里的MCP和Skill该如何选。
01 | AIOps 里的 MCP 和 Skill 的定位
我认为搞AIOps 不是选 MCP 或 Skills的问题,而是要先分清:你现在缺的是“接系统的能力”,还是“按正确流程干活的能力”。
MCP 更像“插头”和“连接层”,而Skills 更像“操作手册”和“作业方法”。真正做 AIOps,最后大概率是两个都要。但落地顺序,不能反。
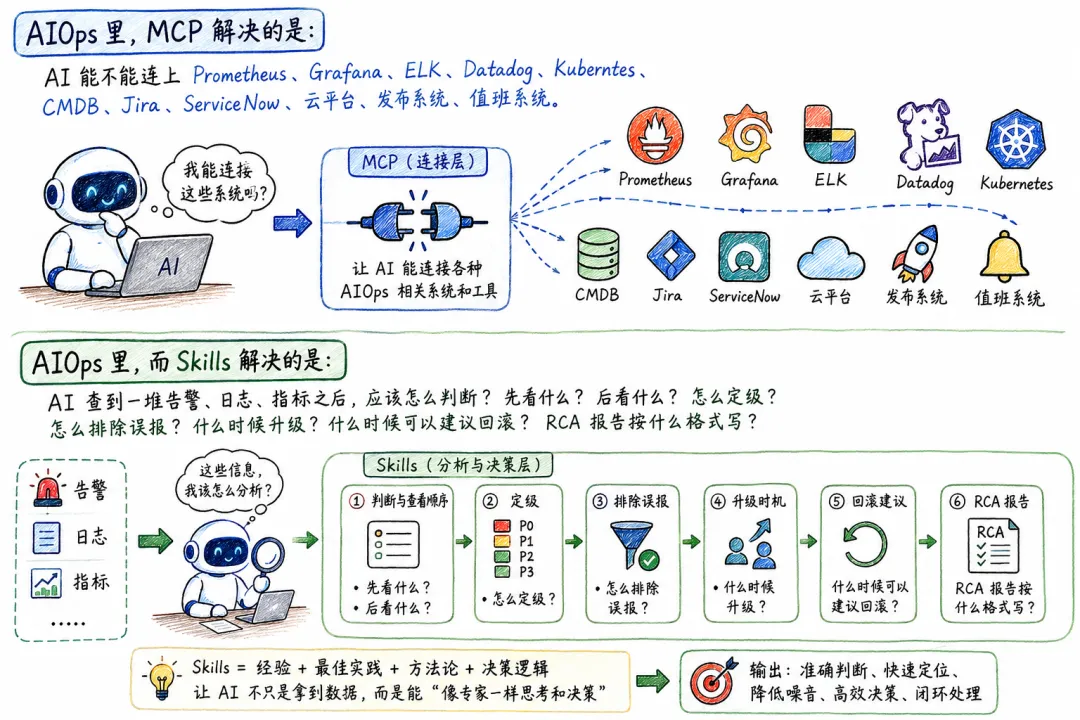
AIOps 里,MCP 解决的是:AI 能不能连上 Prometheus、Grafana、ELK、Datadog、Kubernetes、CMDB、Jira、ServiceNow、云平台、发布系统、值班系统。
也就是:AI 能不能摸到现场。
而Skills 解决的是:AI 查到一堆告警、日志、指标之后,应该怎么判断?先看什么?后看什么?怎么定级?怎么排除误报?什么时候升级?什么时候可以建议回滚?RCA 报告按什么格式写?
也就是:AI 会不会按你的运维规矩干活。
02 | AIOps 不能只靠MCP
很多技术团队第一反应是:先把 MCP Server 搭起来。接监控,接日志,接工单,接 Kubernetes,接云平台 API。看起来很酷,AI 好像一下子拥有了很多手脚。
但这里有个坑:能接系统,不代表会处理故障。比如线上接口延迟突然升高,AI 通过 MCP 查到了如下问题:
服务 P95 延迟上涨;
某个 Pod CPU 飙高;
最近 20 分钟有一次发布;
数据库连接池等待时间增加;
同时间段工单里有人反馈下单失败。这些信息本身不等于结论。一个靠谱的 SRE 会继续问:
这是全站问题,还是单租户问题?
是入口层问题,还是下游依赖问题?
发布变更和异常时间是否严格对齐?
有没有容量、限流、缓存穿透、数据库锁等待、第三方超时?
当前是止血优先,还是定位优先?
这套判断逻辑,不是 MCP 自动带来的。MCP 只是把门打开。进门之后怎么查,怎么判断,怎么收敛,靠的是运维经验、流程规范和组织共识。这正是 Skills 该干的事。
03 | AIOps 也不能只靠 Skills
反过来,只做 Skills 也不行。如果你把故障排查流程写得很漂亮:“先看告警,再看日志,再看变更,再看依赖,再输出 RCA。”听起来没问题。
但 AI 如果拿不到真实数据,就只能泛泛而谈。最后输出的东西很像:“建议检查网络、数据库、缓存、服务依赖。”这类话不能说错,但没什么用。
AIOps 的核心不是写一篇漂亮分析,而是从海量运维数据里聚合、降噪、关联、定位并推动响应。
AIOps 会聚合 IT 组件、监控工具、工单系统等数据,用分析和机器学习来识别关键信号、诊断根因,并支持事件响应和修复。
所以 Skills 如果没有工具和数据支撑,就容易变成“高级提示词库”。能规范表达,但不能真正干活。
04 | 正确姿势:不是二选一,而是分层
做 AIOps,可以把能力拆成三层。
1)第一层是数据和工具接入。
这一层适合 MCP。比如:读指标;查日志;查链路;查变更;查工单;查 CMDB;查 Kubernetes 状态;查云资源状态;触发只读诊断脚本。
这些能力需要稳定、标准、可复用的连接方式。MCP 的价值就在这里。
2)第二层是运维流程和判断方法。
这一层适合 Skills。比如:告警降噪规则;P0/P1/P2 定级标准;某类故障的排查路径;数据库慢查询分析模板;Kubernetes Pod 异常排查步骤;发布故障回滚判断标准;RCA 报告模板;值班交接格式;升级通知话术。
这些东西不是“接口”,而是组织里的经验。把它们做成 Skills,比写在 Confluence 里更容易被 AI 调用,也更容易复用。
3)第三层是动作和治理。
这一层不能只靠 MCP,也不能只靠 Skills。比如:重启服务;扩容实例;切流量;回滚发布;封禁异常租户;修改限流规则;关闭某个开关。
这些动作都有风险。这里需要权限控制、审批、审计、回滚机制和人工确认。尤其是生产环境,别一上来就让 AI 自动执行修复。
比较稳的方式是:先只读,再建议;先低风险自动化,再高风险审批;先局部场景,再全链路闭环。
05 | 什么时候优先选 MCP?
如果你的主要问题是“AI 拿不到现场数据”,优先做 MCP。
典型情况是:监控在一套系统,日志在一套系统,链路在一套系统,工单又在另一套系统;值班同学排障时,要在十几个页面之间来回切;AI 只能靠人复制粘贴日志和截图;不同 AI 应用接同一批系统,每个都要重复开发接口。
这时 MCP 很有价值。
它可以把常用系统变成标准工具,让 AI 用统一方式访问。Anthropic 当初推出 MCP,也是为了解决 AI 助手和数据源之间碎片化集成的问题,希望用开放标准替代一堆一次性接口。
但这里有个前提:MCP Server 不能随便接,权限不能随便给。
自定义 MCP Server 会让 LLM 访问、发送、接收外部应用中的数据,甚至执行动作;也建议只连接可信服务器,优先选择服务商官方服务器,不要随便接不明第三方 MCP。
这句话放到 AIOps 场景里尤其重要。因为运维系统里不是普通数据,而是生产系统的钥匙。
06 | 什么时候优先选 Skills?
如果你的主要问题是“人和 AI 都不知道该按什么标准处理”,优先做 Skills。很多公司其实不是缺工具,而是缺统一做法。
同一个告警,A 同学会先看发布,B 同学会先看机器,C 同学会直接重启。最后故障恢复了,但过程不可复盘,经验也沉淀不下来。这种情况下,先做 MCP 可能只是让 AI 更快地重复混乱。
更好的做法是,把成熟专家的处理路径固化成 Skills。
比如做一个“Java 服务延迟升高排查 Skill”,里面写清楚:
① 先判断影响面;
② 再看入口指标;
③ 再看最近变更;
④ 再看下游依赖;
⑤ 再看线程池、连接池、GC、慢 SQL;
⑥ 再输出止血建议和进一步定位建议;
⑦ 最后按固定格式生成故障记录。
这类 Skill 不一定一开始就要很复杂。它可以先是一份好用的排障手册,后面再逐步加脚本、模板、检查清单和自动化代码。
Skills 是可复用的、基于文件系统的资源,能提供领域工作流、上下文和最佳实践,把通用 Agent 变成更专门的 Agent。
这句话很适合 AIOps。因为 AIOps 最缺的不是“会聊天的 AI”,而是“懂你们现场规矩的 AI”。
07 | 我的建议:AIOps 落地顺序
如果从零开始,我建议这样做。
第一步,先做 Skills。
把最常见的 5 到 10 类故障流程写下来。比如接口延迟升高、错误率升高、Pod CrashLoopBackOff、磁盘打满、数据库连接池耗尽、发布后异常、消息堆积、缓存命中率下降。
不要追求大而全。先让 AI 在没有自动执行能力的情况下,能按你们团队认可的方式分析问题、输出排查路径和 RCA 草稿。
第二步,做只读 MCP。
先接监控、日志、链路、工单、变更、CMDB。这个阶段不让 AI 改东西,只让它查东西。目标是减少值班同学来回切系统、复制粘贴信息的时间。
第三步,把 Skills 和 MCP 串起来。
让 AI 按 Skill 里的流程,通过 MCP 去查数据。不是让 AI 想查什么就查什么,而是按排障路径一步步查。这样结果会稳定很多。
第四步,再考虑低风险自动化。
比如自动创建故障群、生成工单、补充 RCA 初稿、整理时间线、推荐责任团队、生成升级通知。这些动作即使错了,风险也相对可控。
第五步,最后才是生产修复动作。
比如扩容、重启、回滚、切流量。这些必须加审批、权限、灰度、审计和回滚。别把“自动化”理解成“没人管”。
成熟的 AIOps,不是让 AI 无人驾驶生产系统,而是让 AI 在正确边界内减少人的重复劳动。
我的运维大模型课上线了,目前还有很大优惠。扫码咨询优惠(粉丝优惠力度大)

