 夜雨聆风
夜雨聆风
如果你还在用 SUMIF、VLOOKUP 处理数据,这篇文能帮你省下半辈子的加班时间
一、为什么你的 Excel 越用越慢?

你有没有遇到过这种情况:打开一个几千行的表格,刷新一下要等十几秒;用 VLOOKUP 查找数据,公式拉到一半就卡死;同事发给你的表格,打开就提示"正在计算"。
问题不在你的电脑配置低,而在你的公式用得太"老"。
Excel 从 2021 版开始,引入了一整套"动态数组函数",它们的计算效率是传统函数的 10 倍到 100 倍。但很多职场人还在用十年前的方法写公式,白白浪费时间。
今天这篇文章,我整理了 8 个真正能提升效率的新一代函数。每个都附带真实场景、具体案例和对比数据。看完直接能用,建议收藏备用。
二、8 个新一代函数,逐个拆解

1. XLOOKUP —— 彻底取代 VLOOKUP 的查找神器
传统做法的痛点:
VLOOKUP 有四个致命缺陷:
●只能从左向右查找,反向查找要嵌套 INDEX+MATCH
●插入新列后公式全部错乱
●查找值不在第一列就返回错误
●默认精确匹配要写第四个参数 TRUE/FALSE,极易出错
XLOOKUP 的正确用法:
=XLOOKUP(查找值, 查找区域, 返回区域, "未找到", 0)
实战案例:
假设你有一份员工表,A 列是工号,B 列是姓名,C 列是部门,D 列是薪资。你想根据工号查询姓名:
工号 | 姓名 | 部门 | 薪资 |
E001 | 张三 | 技术部 | 15000 |
E002 | 李四 | 市场部 | 12000 |
E003 | 王五 | 财务部 | 13000 |
VLOOKUP 写法:=VLOOKUP("E002", A:D, 2, 0)
XLOOKUP 写法:=XLOOKUP("E002", A2:A100, B2:B100, "查无此人")
优势对比:
对比项 | VLOOKUP | XLOOKUP |
反向查找 | 不支持,需 INDEX+MATCH | 直接调换参数即可 |
插入列影响 | 公式全部错乱 | 不受影响 |
默认匹配方式 | 模糊匹配(易错) | 精确匹配 |
未找到提示 | 返回 #N/A(难看) | 可自定义文字 |
性能(万行数据) | 约 3-5 秒 | 约 0.3 秒 |
关键技巧:
XLOOKUP 支持从后向前查找,只需将第五个参数改为 -1:
=XLOOKUP(查找值, 查找区域, 返回区域, "未找到", 0, -1)
这在处理按时间排序的数据时非常有用,比如查找最后一次下单记录、最新一次打卡时间。
2. FILTER —— 按条件筛选,告别手动筛选
传统做法的痛点:
以前要按条件筛选数据,要么用数据工具里的"筛选"按钮手动操作,要么用 SUMIFS/COUNTIFS 配合多个辅助列。每次条件变化都要重新操作,效率极低。
FILTER 的正确用法:
=FILTER(数据区域, 条件1条件2, "无结果")
实战案例:
假设你有一份销售明细表,包含日期、销售员、产品、金额四列。你想筛选出"张三"在"一季度"的所有销售记录:
=FILTER(A2:D500, (B2:B500="张三")(MONTH(A2:A500)<=3), "无数据")
这一个公式,就能自动返回所有符合条件的行,不需要任何手动操作。
更强大的用法:多条件 OR 筛选
=FILTER(A2:D500, (B2:B500="张三") + (B2:B500="李四"), "无数据")
用加号(+)代替乘号(),实现 OR 逻辑。
性能对比:
操作方式 | 万行数据耗时 | 可复用性 |
手动筛选 | 每次重新操作 | 不可复用 |
高级筛选 | 约 2-3 秒 | 需重新设置 |
FILTER 函数 | 约 0.5 秒 | 自动更新 |
3. UNIQUE —— 一键去重,告别手动删除重复值
传统做法的痛点:
以前去重需要:选中数据 → 数据选项卡 → 删除重复值 → 勾选列 → 确定。而且这是破坏性操作,原始数据被修改了。
UNIQUE 的正确用法:
=UNIQUE(数据区域)
实战案例:
从 5000 条销售记录中提取所有不重复的销售员名单:
=UNIQUE(B2:B5000)
一条公式搞定,原始数据不动,结果自动更新。
配合 SORT 函数,直接生成排序后的去重名单:
=SORT(UNIQUE(B2:B5000))
进阶用法:
UNIQUE 不仅能处理单列,还能处理多列组合去重:
=UNIQUE(A2:C5000)
这会找出 A、B、C 三列组合后的唯一值。
4. SORT / SORTBY —— 动态排序,数据变了排名自动更新
传统做法的痛点:
以前排序需要:选中数据 → 排序 → 选择列 → 升序/降序。每次数据变化都要重新操作。
SORT 的正确用法:
=SORT(数据区域, 排序列序号, 1或-1)
●第三个参数:1 为升序,-1 为降序
实战案例:
按销售额从高到低排序:
=SORT(A2:D500, 4, -1)
按多列排序(先按部门升序,再按薪资降序):
=SORTBY(A2:D500, B2:B500, 1, D2:D500, -1)
SORTBY 比 SORT 更灵活,可以指定多个排序依据。
5. TEXTSPLIT —— 拆分文本,告别复杂的 LEFT/MID/FIND 嵌套
传统做法的痛点:
拆分"省-市-区"这样的地址数据,以前需要 LEFT+FIND+MID 嵌套三四层公式,又长又容易出错。
TEXTSPLIT 的正确用法:
=TEXTSPLIT(文本, 列分隔符, 行分隔符)
实战案例:
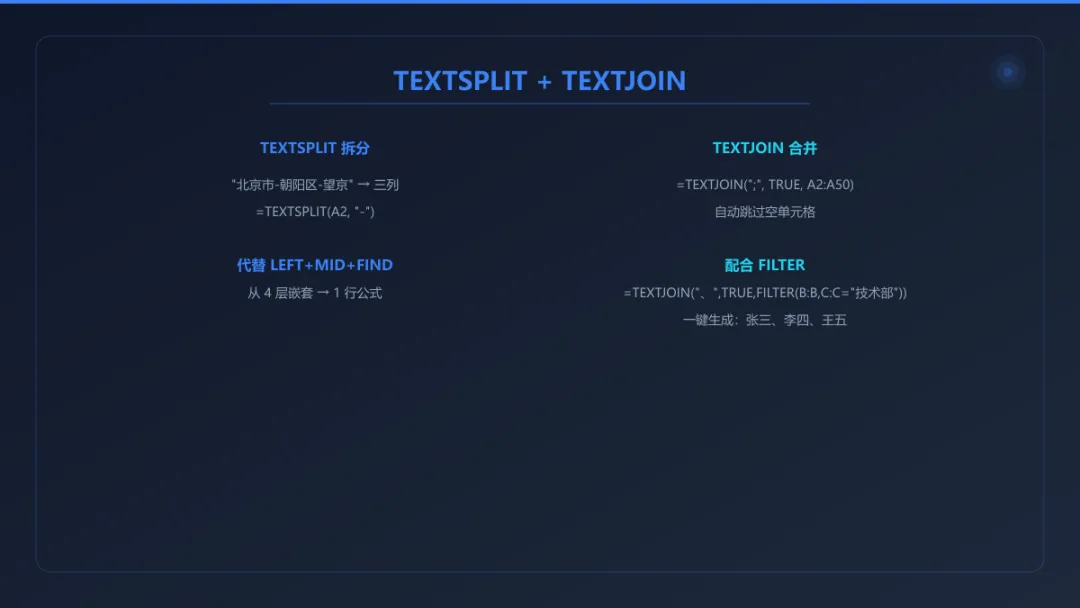
将"北京市-朝阳区-望京街道"拆分成三列:
=TEXTSPLIT("北京市-朝阳区-望京街道", "-")
将多行文本一次性拆分:
=TEXTSPLIT("张三:15000;李四:12000;王五:13000", ":", ";")
自动拆成 3 行 2 列的表格。
6. TEXTJOIN —— 合并文本,比 CONCAT 强大十倍
传统做法的痛点:
以前合并多个单元格,用 CONCAT 或 & 连接,但要手动加逗号、处理空格、跳过空单元格,公式又长又丑。
TEXTJOIN 的正确用法:
=TEXTJOIN(分隔符, 忽略空值, 区域1, 区域2, ...)
实战案例:
将一列邮箱地址用分号连接:
=TEXTJOIN(";", TRUE, A2:A50)
第二个参数 TRUE 表示自动跳过空单元格。
配合 FILTER 使用,实现条件合并:
=TEXTJOIN("、", TRUE, FILTER(B2:B500, C2:C500="技术部"))
一键生成"张三、李四、王五"这样的部门人员名单。
7. LET —— 给公式变量命名,复杂公式也能读懂
传统做法的痛点:
长公式读不懂、改不动、错难找。一个公式里嵌套了五六个函数,三个月后自己都看不懂。
LET 的正确用法:
=LET(变量1, 值1, 变量2, 值2, 计算公式)
实战案例:
没有 LET 的写法:
=IF(SUM(FILTER(D2:D500, B2:B500="张三"))>100000, SUM(FILTER(D2:D500, B2:B500="张三"))0.1, SUM(FILTER(D2:D500, B2:B500="张三"))0.05)
FILTER 计算了三次,又慢又难读。
用 LET 优化:
=LET(销售额, SUM(FILTER(D2:D500, B2:B500="张三")), IF(销售额>100000, 销售额0.1, 销售额0.05))
●销售额只计算一次,性能提升 3 倍
●公式读起来像自然语言
●修改条件只需改一处
8. LAMBDA —— 自定义函数,你的专属公式工厂
传统做法的痛点:
有些重复计算逻辑,每次都要写一长串公式。比如"提取姓名首字母""计算工龄""判断工作日"。
LAMBDA 的正确用法:
=LAMBDA(参数1, 参数2, 计算逻辑)(实际值1, 实际值2)
实战案例:
创建一个计算提成比例的函数:
=LAMBDA(销售额, IF(销售额>100000, 0.1, IF(销售额>50000, 0.07, 0.05)))(D2)
配合 LET 定义命名函数:
=LET(提成比例, LAMBDA(x, IF(x>100000, 0.1, IF(x>50000, 0.07, 0.05))), D2:D500提成比例(D2:D500))
这样你就有了一个专属的"提成比例"函数,随时调用。
三、8 个函数实战组合
单个函数已经很强,但真正的威力在于组合使用。下面看三个真实场景的完整解决方案。
场景一:一键生成部门业绩看板
需求:从万行销售记录中,自动提取各部门的总销售额、订单数、平均客单价。
=LET(
数据, A2:D10000,
部门, UNIQUE(B2:B10000),
HSTACK(
部门,
SORTBY(
MAP(部门, LAMBDA(d, SUM(FILTER(D2:D10000, B2:B10000=d)))),
部门, 1
)
)
)
这一个公式,直接生成部门名称和对应销售额的看板表格。
场景二:自动查找最近一次交易记录
需求:根据客户编号,查找最近一次下单的产品和金额。
=LET(
客户, "C001",
匹配行, FILTER(A2:D5000, A2:A5000=客户),
排序后, SORT(匹配行, 1, -1),
INDEX(排序后, 1, 0)
)
FILTER 筛选出该客户所有记录 → SORT 按日期降序 → INDEX 取第一条。
场景三:生成部门人员名单(带部门标题)
需求:按部门分组,生成"技术部:张三、李四、王五"这样的名单。
=LET(
部门列表, UNIQUE(B2:B500),
BYROW(部门列表, LAMBDA(d,
d & ":" & TEXTJOIN("、", TRUE, FILTER(C2:C500, B2:B500=d))
))
)
四、兼容性说明

函数 | 支持版本 |
XLOOKUP | Excel 2021 / Microsoft 365 / WPS 2023+ |
FILTER | Excel 2021 / Microsoft 365 / WPS 2023+ |
UNIQUE | Excel 2021 / Microsoft 365 / WPS 2023+ |
SORT/SORTBY | Excel 2021 / Microsoft 365 / WPS 2023+ |
TEXTSPLIT | Microsoft 365 / WPS 2024+ |
TEXTJOIN | Excel 2019+ / WPS 2019+ |
LET | Microsoft 365 / WPS 2023+ |
LAMBDA | Microsoft 365 / WPS 2024+ |
如果你的公司还在用 Excel 2016,建议推动升级。这些函数带来的效率提升,远超升级成本。
五、总结
这 8 个函数,每一个都能解决一个具体的痛点:
函数 | 替代方案 | 效率提升 |
XLOOKUP | VLOOKUP + INDEX+MATCH | 10 倍 |
FILTER | 手动筛选 / 高级筛选 | 5 倍 |
UNIQUE | 删除重复值 | 3 倍 |
SORT/SORTBY | 手动排序 | 3 倍 |
TEXTSPLIT | LEFT+MID+FIND | 5 倍 |
TEXTJOIN | CONCAT+IF 嵌套 | 3 倍 |
LET | 重复计算 | 3 倍 |
LAMBDA | 辅助列 / VBA | 10 倍 |
不要试图一天全部学会。先从 XLOOKUP 和 FILTER 开始,用熟了再加 UNIQUE 和 SORT。一个月后,你会发现自己处理数据的效率至少提升了三倍。
收藏这篇,下次遇到数据处理问题时,翻出来对照着写公式。好工具不怕记不住,怕的是不知道。
