 夜雨聆风
夜雨聆风登录注册:从进入系统开始
进入平台后,用户可以完成登录注册,也可以根据自己的使用习惯切换不同主题颜色,让后台系统不再只有单一的视觉风格。
首页:先看当天最重要的事
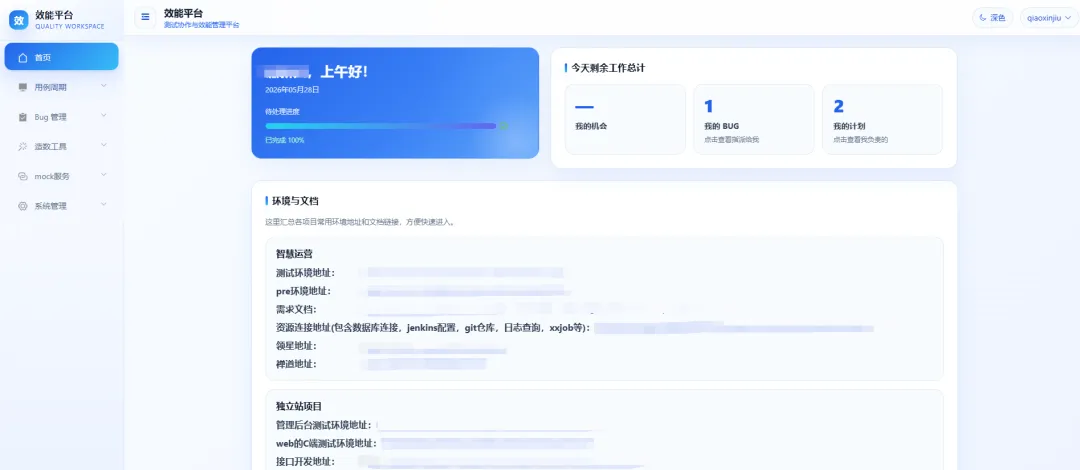
首页主要用来快速查看当天还剩多少未解决 Bug、多少测试计划还没有完成。打开系统后,团队可以第一时间掌握当前测试工作的整体进度。
用例周期:从产品、项目到用例执行
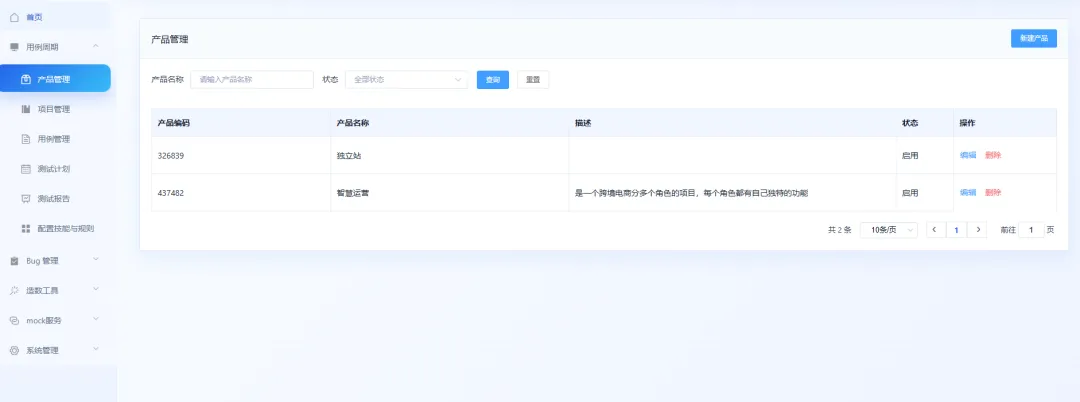
产品管理
在产品管理中,可以先新增产品,再在对应产品下面继续新增项目。这样产品和项目之间的关系会更清晰,后续维护起来也更方便。
2.项目管理
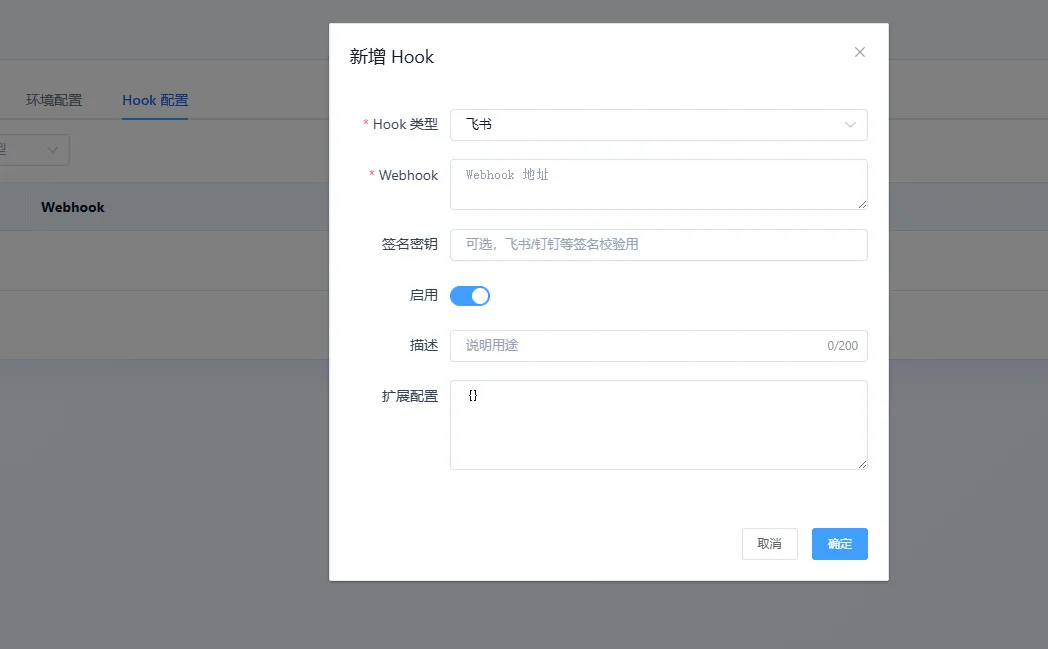
项目创建完成后,可以继续维护项目成员、环境配置以及 Hook 通知配置。通知方式支持飞书、钉钉和企业微信,后续测试计划、冒烟测试、Bug 提醒等信息都可以推送给指定人员。比如开发提测后,可以创建一个开发冒烟计划,通过飞书通知对应人员执行;Bug 相关消息也可以按项目进行定制化推送。
3.用例管理
用例管理主要分为四块:用例模块、用例列表、用例脑图,以及 AI 生成用例。
用例模块支持手动新增。通过 AI 生成的用例在审核通过后,也可以自动沉淀到对应模块中,方便后续分类管理。
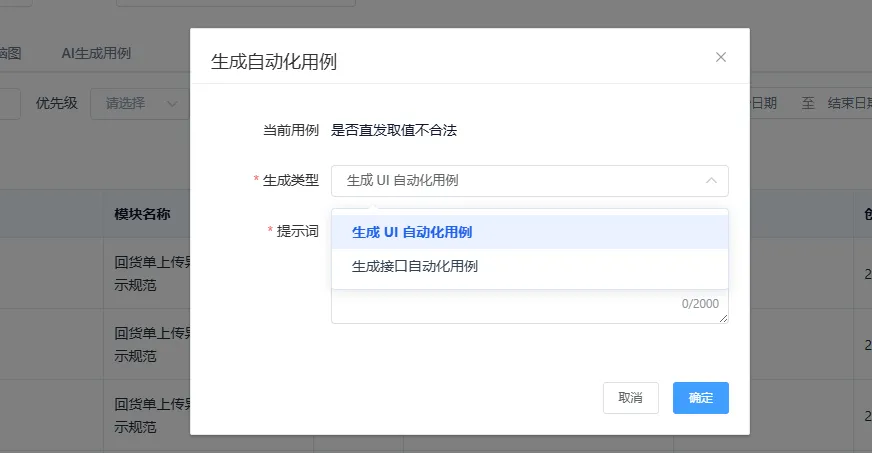
用例列表支持自定义筛选条件,也支持自定义表头展示。用例可以手动新增,也可以通过 Excel 批量导入,导入模板和禅道模板比较接近,上手成本会比较低。列表中还可以直接生成自动化用例,选择 UI 自动化或接口自动化后,系统会调用自动化框架 API 和大模型 Agent,通过预置 Skills 按要求生成可维护、可执行的自动化用例,尽量减少人工反复维护的成本。
用例脑图采用类似 XMind 的树形结构,更适合用来做用例评审。只有评审通过的用例,后续创建测试执行计划时才能被选择;评审过程中发现问题,也可以直接编辑调整。
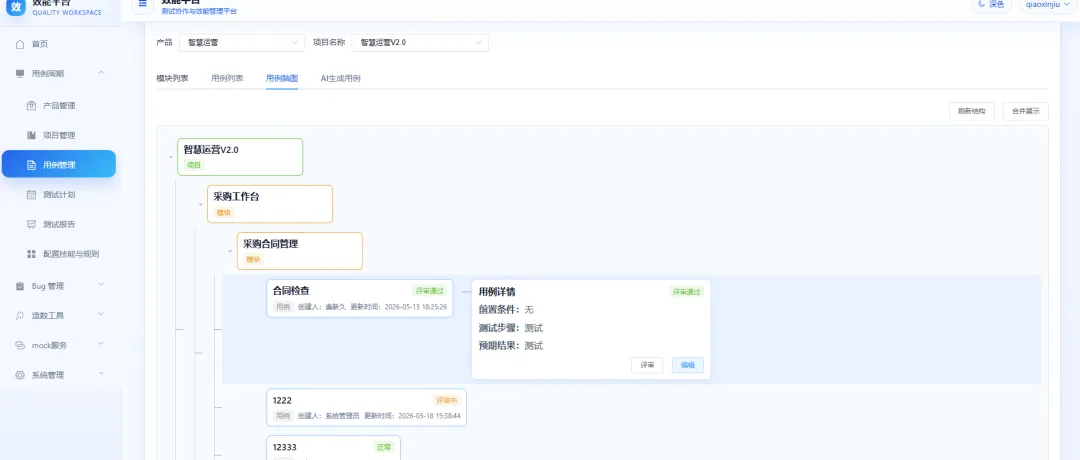
AI 生成用例支持批量上传 PRD,也可以选择 Skills 和业务规则一起参与生成。如果希望生成特定类型的异常用例,可以提前在 Skills 与业务规则里配置要求;如果 PRD 里没有写到某些业务规则,也可以单独维护到规则库中,生成用例时一起使用。没有额外选择时,系统会默认按四层结构的通用 Skills 生成用例。AI 生成后的用例审核通过,就可以同步到用例列表。
4.测试计划
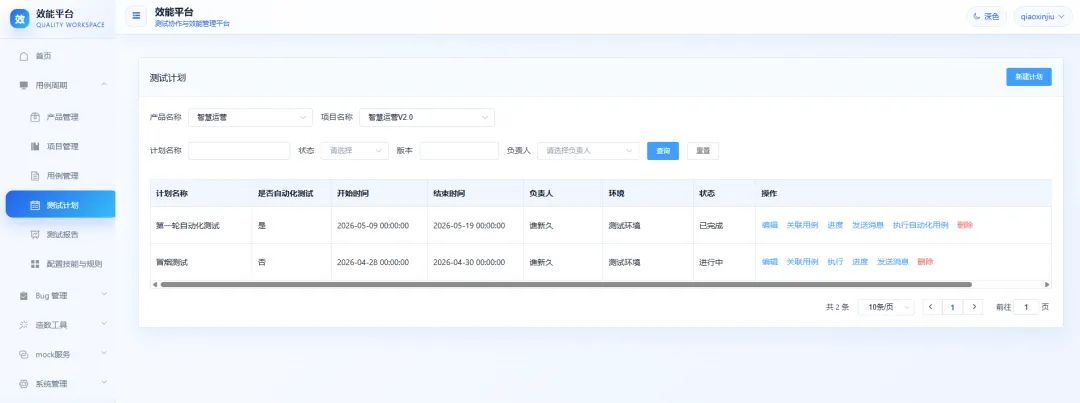
创建计划时,可以选择测试执行计划,也可以选择自动化计划。如果是测试执行计划,创建后需要关联当前项目下已经评审通过的用例。
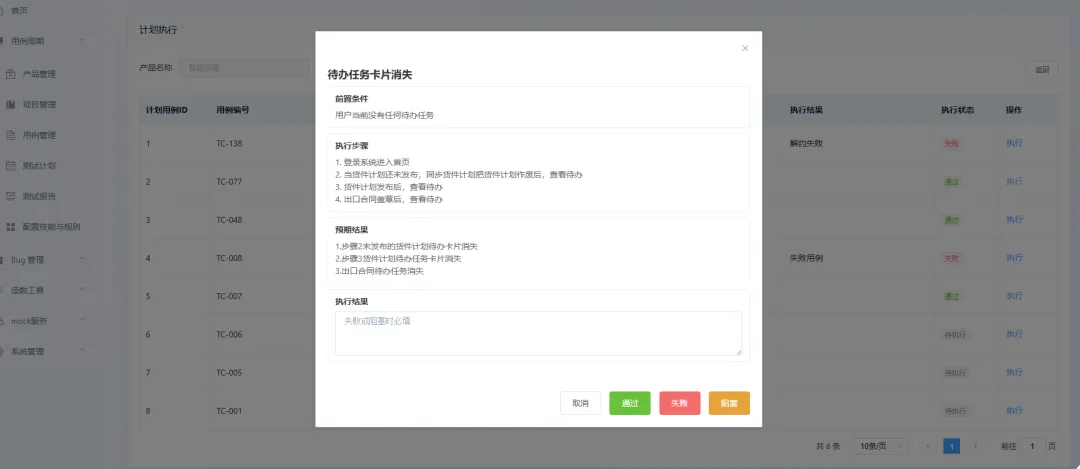
执行过程中可以记录每条用例的执行结果。失败的用例可以填写失败原因,后续报表统计时也会把这些结果汇总出来。
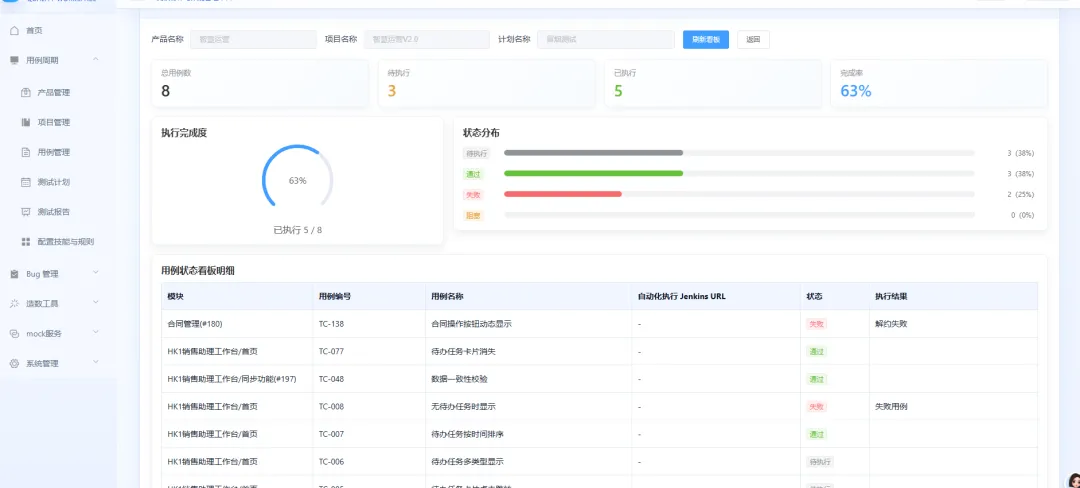
计划执行过程中,可以随时在列表里查看执行进度,清楚知道当前还有哪些内容没有完成。
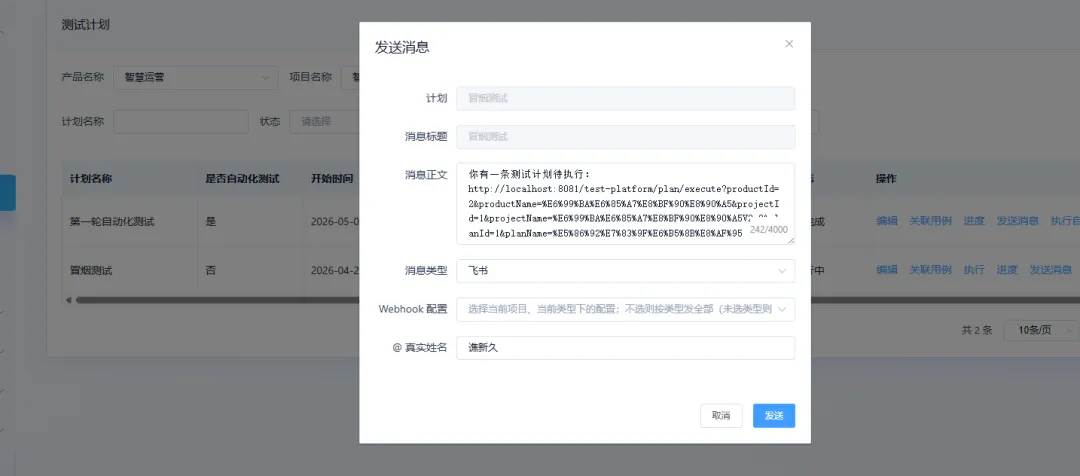
列表里的“发送消息”会使用当前项目配置好的 Hook,把计划或执行信息发送到对应通知渠道。
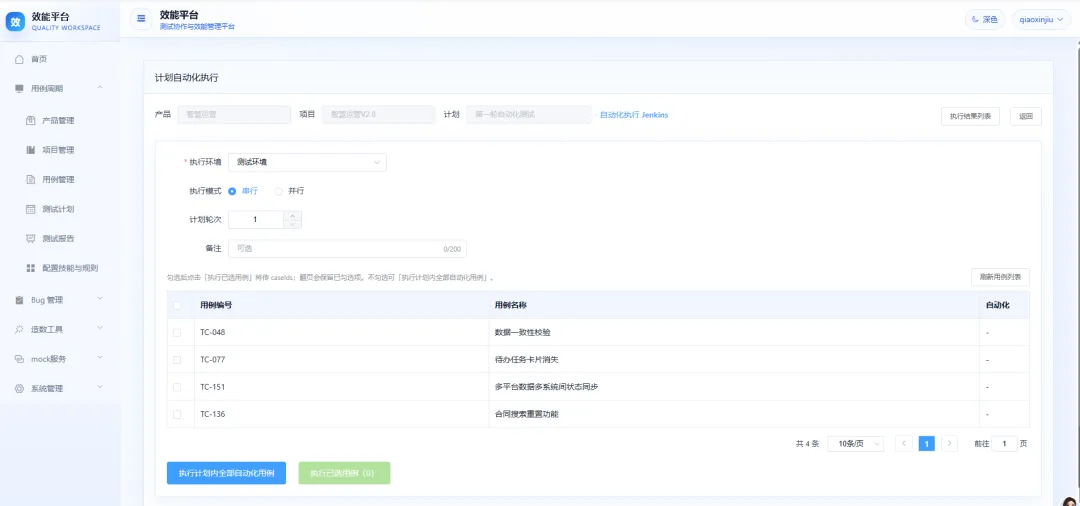
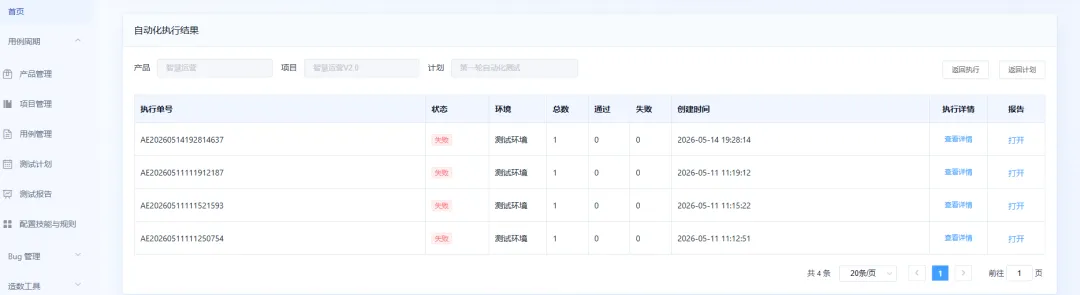
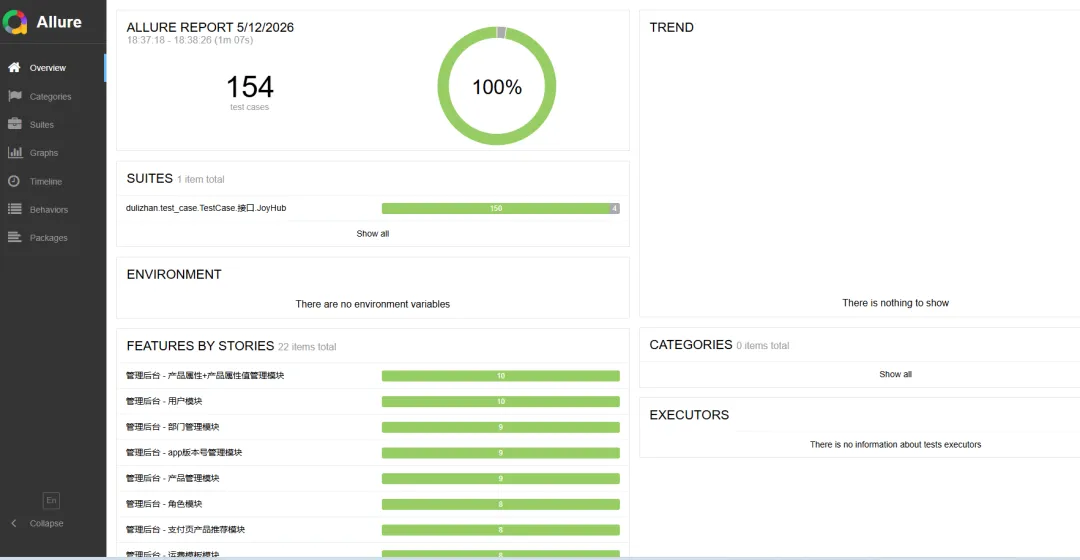
自动化计划需要填写 Jenkins Job 地址。当前自动化执行基于 Pytest 框架:点击执行自动化测试后,系统会筛选当前项目下已评审通过、并且“是否实现自动化”为“是”的用例。选择后开始执行,系统会把用例编号作为 Allure Story 标签传入自动化任务,执行完成后,结果会展示在对应的执行结果列表中。
测试报告
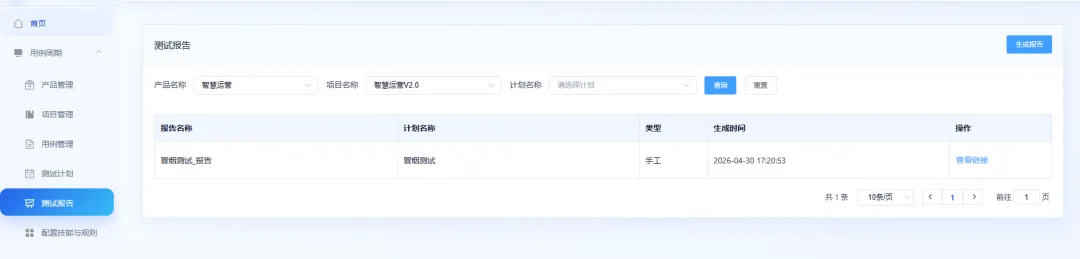
测试报告主要用于展示执行后的结果数据。这里的展示样式可以根据不同团队的习惯继续定制,目前重点是把对应的执行结果数据返回并展示出来。
Skills 与业务规则配置
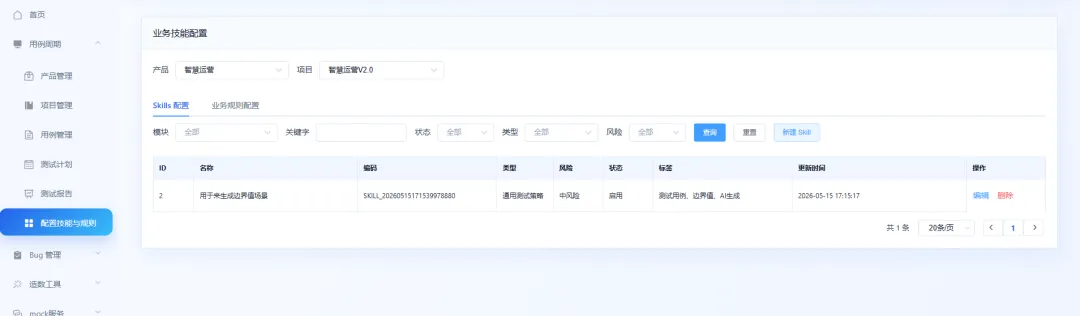
这里对应前面提到的 AI 生成用例能力。Skills 和业务规则可以决定 AI 生成用例时更关注什么内容。同时,后台也会把出现超过 2 次的同类型线上问题沉淀成业务规则。后续生成回归测试用例时,AI 会结合这些问题的影响范围,生成覆盖更全面的测试用例。
Bug 管理
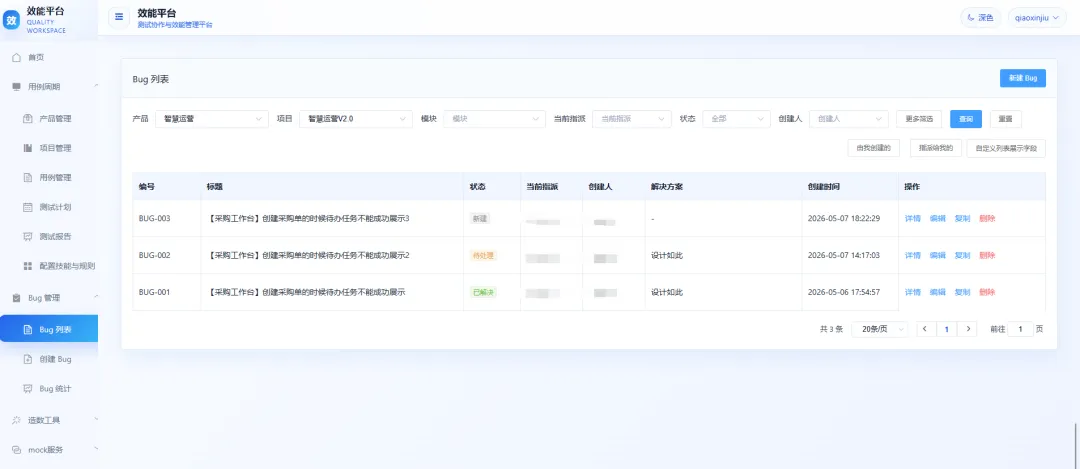
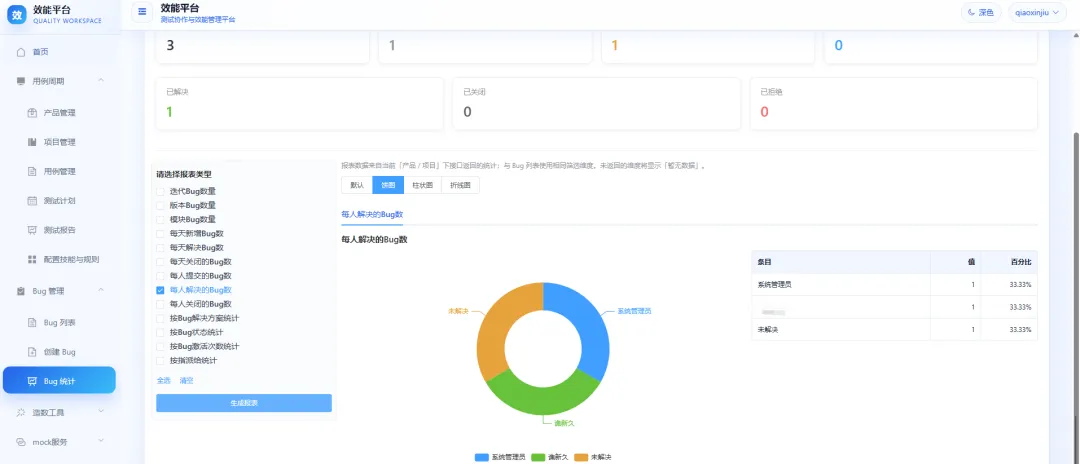
Bug 管理的提交流程和禅道、Jira 这类常见缺陷管理工具类似,同时也支持生成图表,方便团队查看缺陷统计情况。
造数工具
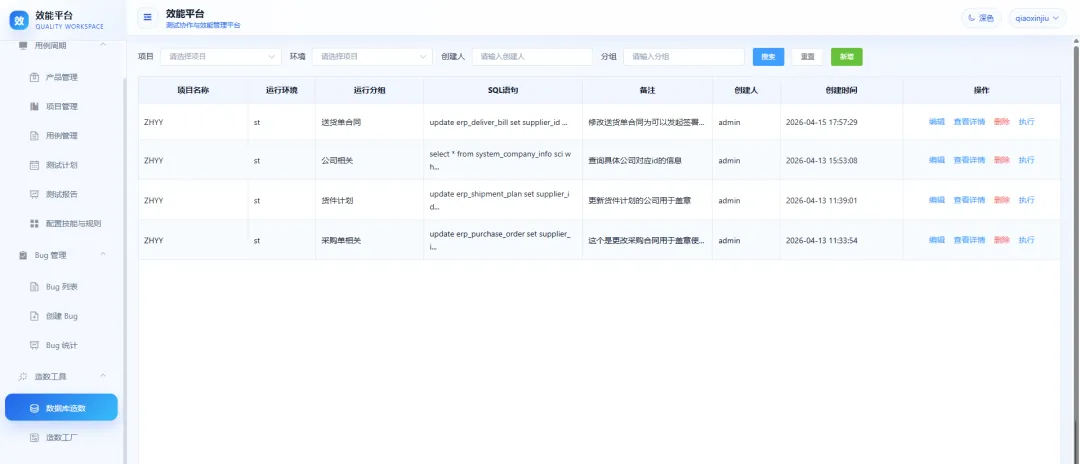
数据库造数支持按项目和环境配置数据库连接。配置完成后,直接输入 SQL 就可以执行造数操作。
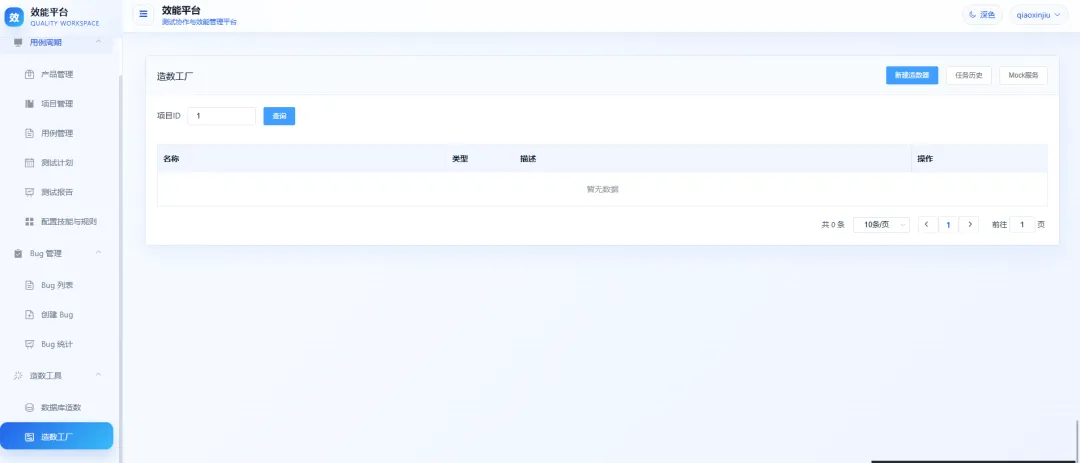
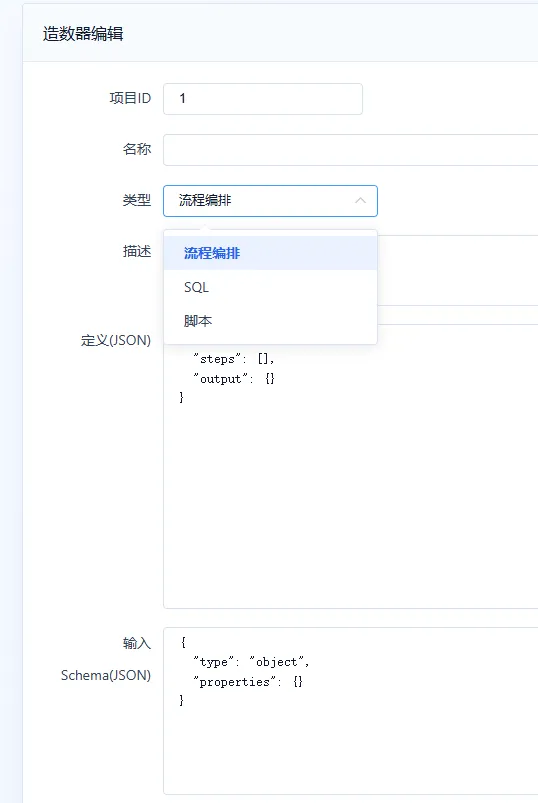
造数工厂可以结合已经完成的自动化关键字进行组装,支持 Mock、流程编排和脚本等方式,适合不同测试场景下的数据准备。
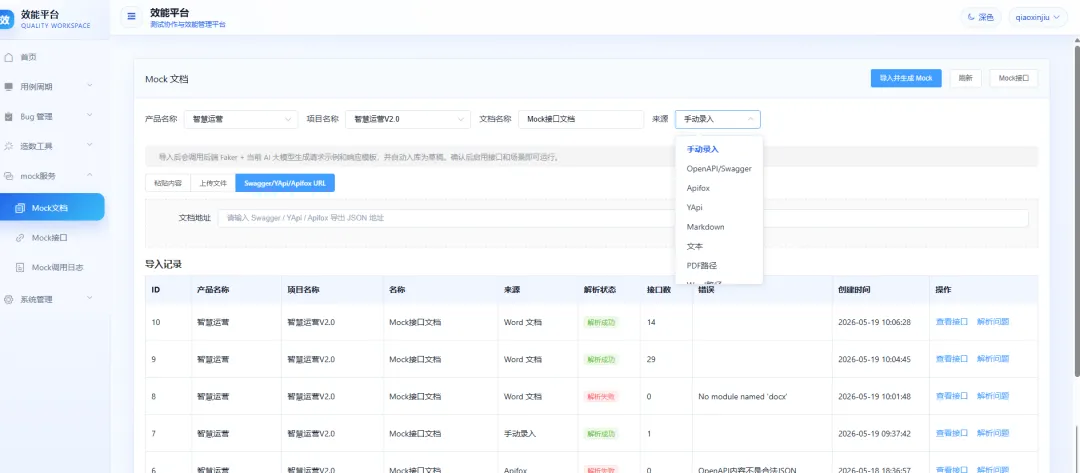
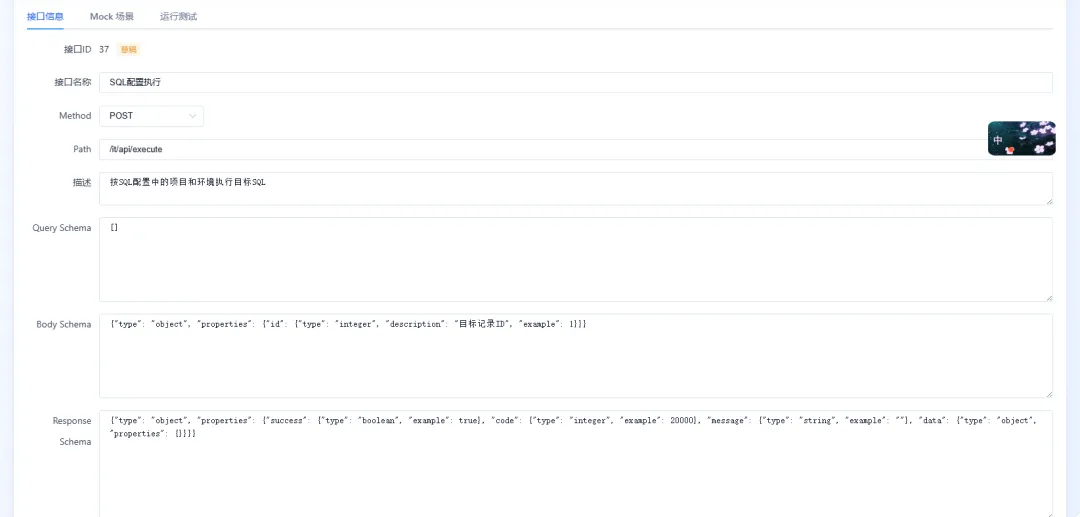
Mock 服务
Mock 服务支持导入接口文档或接口地址,也支持拉取 Git 仓库代码。无论是前端代码还是后端代码,系统都可以通过大模型进行分析总结,并生成对应的 Mock 数据。针对微服务场景,也支持请求透传,不过需要在发布的微服务上做好配置,将请求转发到效能平台服务。
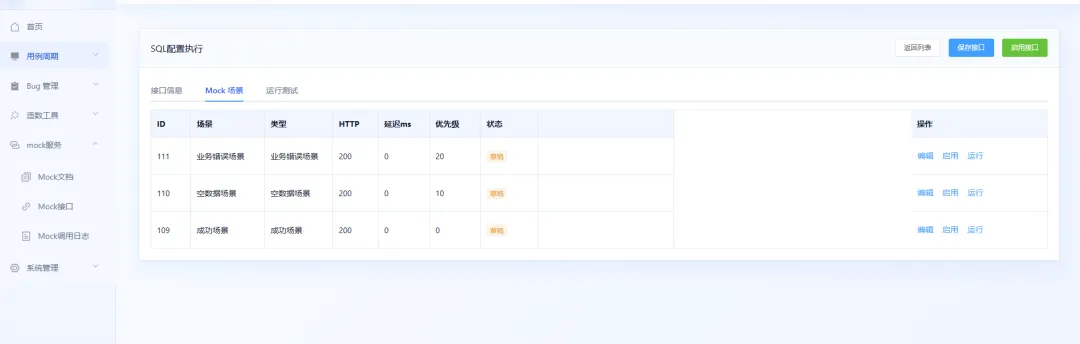
同一个 Mock 接口可以配置多种返回方式,异常场景也可以单独新增,只需要维护对应的返回模板即可。
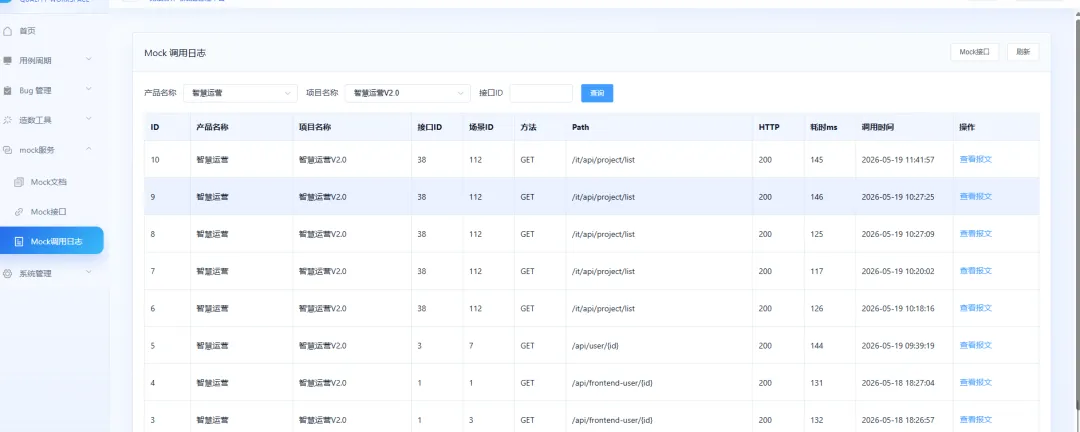
每次 Mock 接口的调用日志也可以查看,方便后续排查请求记录和返回结果。
系统管理
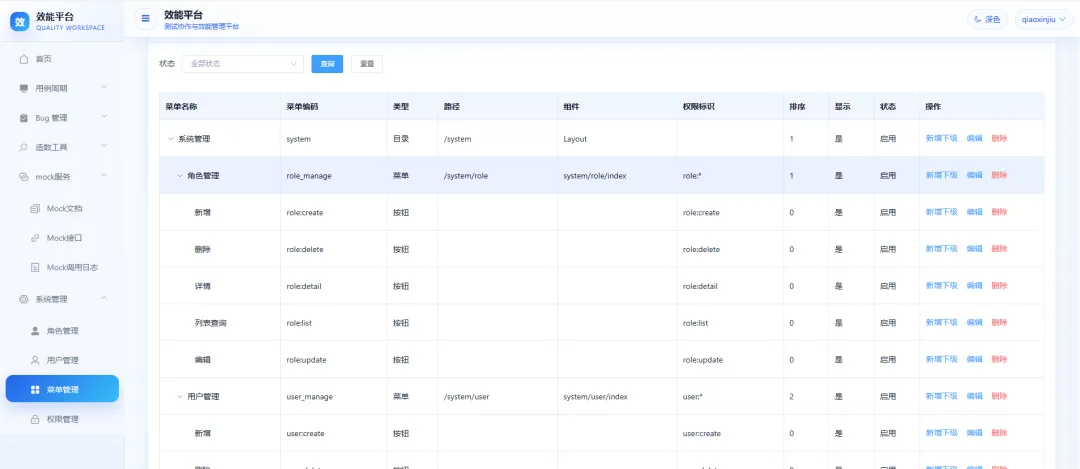
系统管理主要负责整个平台的权限控制,和传统权限体系类似,支持目录、菜单、按钮级权限设置,同时也支持数据权限。管理员可以先给角色分配权限,再把角色分配给对应人员。
后续规划
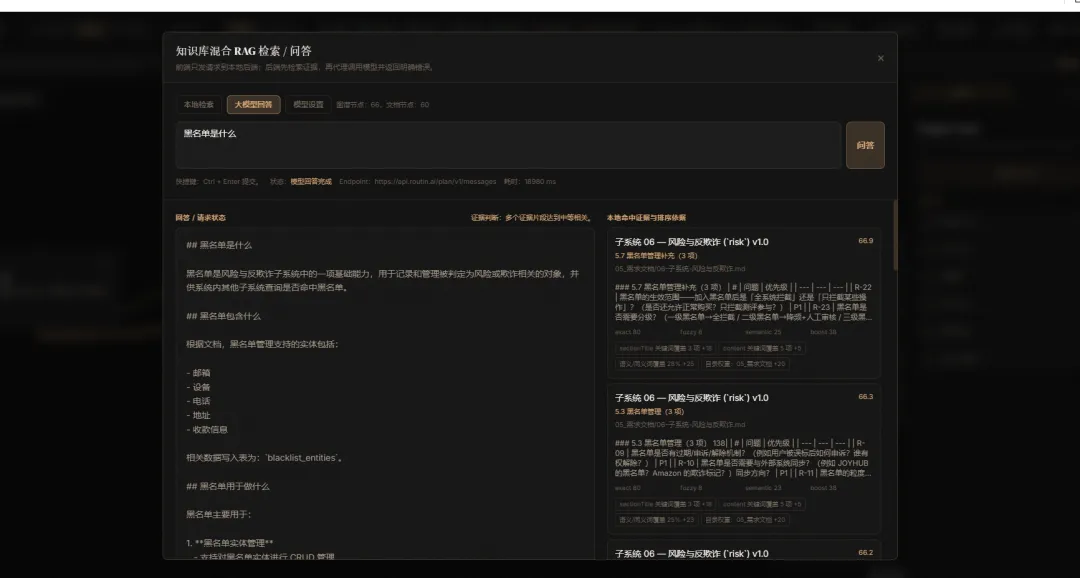
后续还会增加知识库能力。文档上传后,会统一存放到指定目录,并进行向量化存储和检索。用户提问时,系统可以从已有文档中筛选出相关内容并返回答案;如果是本地回答,会先通过 grep 定位,再结合 RAG 返回对应位置和上下文;如果需要总结、理解或生成答案,则会调用大模型完成。对于需求量比较多的业务,也可以建立专属业务知识库,让检索和问答更贴合实际项目。
开源git地址:
https://github.com/qiaoxinjiu/effekt/
