夜雨聆风
夜雨聆风前几周我们聚焦 AI 写代码(从单线程编码到智能体管理|斯坦福 CS146S|现代软件开发者 | 第三周第二讲:2025 年 AI 编码指南(附核心方法论))、改代码(代码写得越「像正确的」,越要有人把关|斯坦福 CS146S|现代软件开发者 | 第七周第一讲:AI 代码审查)、生成应用(一条提示词,能不能长成一个应用?|斯坦福 CS146S|现代软件开发者 | 第八周第一讲:单个提示词构建端到端应用),仿佛这就是软件工程的全部。
但斯坦福 CS146S 现代软件开发者第九周第一讲,Mihail Eric 把镜头从 IDE 推向生产环境。代码上线之后,真正的考验才开始:PagerDuty 警报响起,数据库查询的 500 错误暴涨,仪表盘闪红,Slack 里开始有人问:谁最近动过这里?数据库是不是满了?是不是刚发版?是不是某个下游服务拖死了连接池?
这一刻才懂:软件开发最难的部分,是让代码在生产环境稳定运行。
AI DevOps 的价值,不是让 AI 成为一个「自动灭火机器人」,而是让 AI 成为事故现场的证据整理员、系统地图员、假设推进员和可审计执行助手。它不会立刻替代 SRE,但它正在改写 SRE 值守时最混乱、最消耗人的那几十分钟。
01 | 写代码只占 30%,70% 的挑战在生产环境
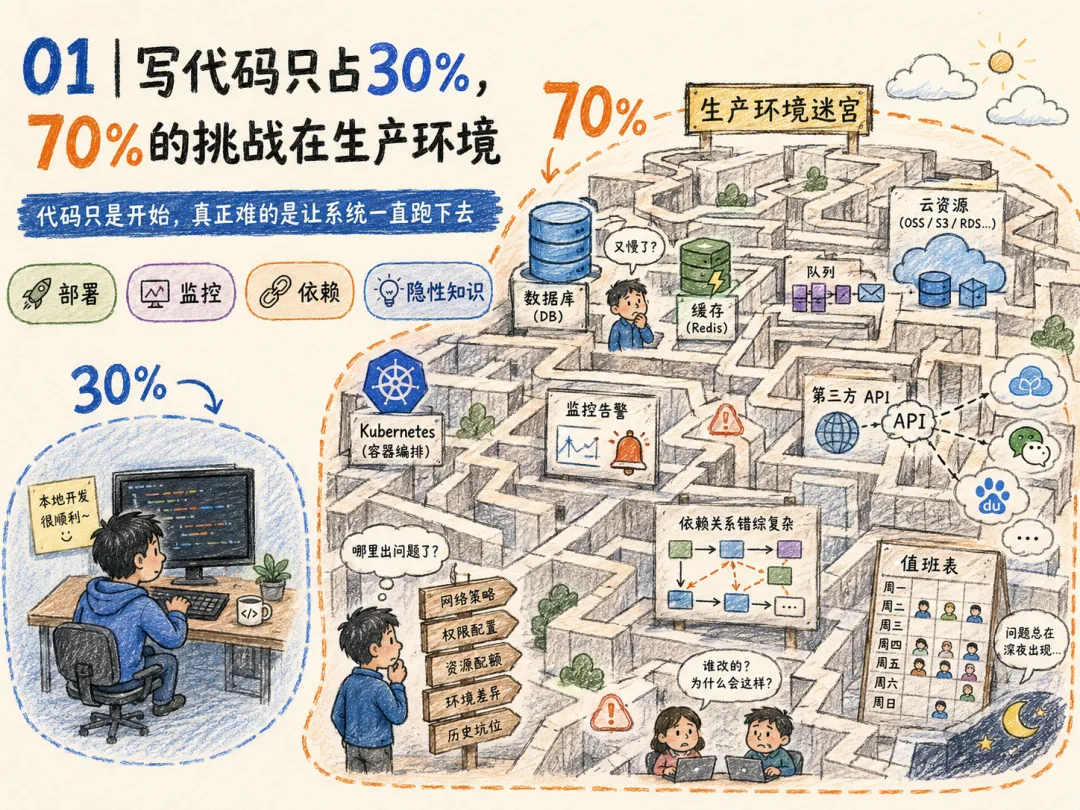
线上生产环境的软件系统监控,始终是至关重要的核心工作。
编码仅占工程师整体工作时长的三成。剩余七成难度更高的工作,是在生产环境中部署运行代码——各类系统复杂度、工具壁垒、知识盲区与多方依赖关系,在此集中交织爆发。
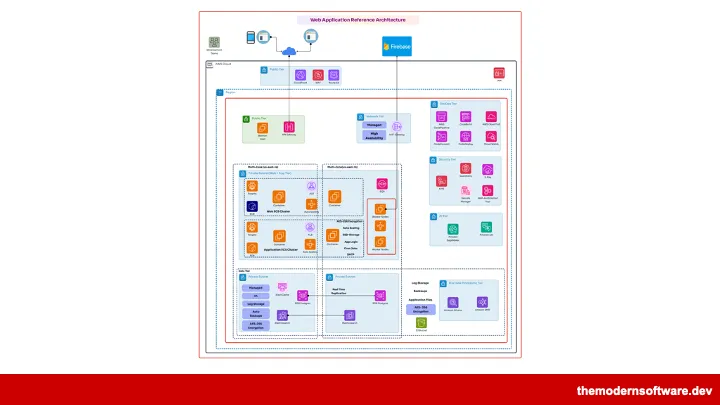
我们总把软件开发等同于 IDE 里的编码、测试、提测、上线,但一个真实运行的系统,是数据库、缓存、队列、权限、配置、云资源、Kubernetes、第三方 API、历史技术债、团队隐性知识与凌晨值班表交织的活系统。
代码上线后,便有了自己的运行状态。生产环境运维工作,往往需要站点可靠性工程师(SRE) 耗费大量精力完成繁琐的软件问题分级排查。
传统 DevOps 与 SRE 的工作,看似是监控、值班、排障、基础设施管理、安全防护,实际却是在分散在工具间拼凑信息:在 Datadog 看指标、日志平台搜报错、Kubernetes 查 Pod、GitHub 找最近提交、Slack 跨团队问询、Confluence 翻过期手册。
这就是 Mihail 说的「旧世界」:不是缺少信息,而是信息太多、太散、太旧,完全无法集中使用。
编者注:现代软件开发者早已不能只懂「构建」,更要懂「守城」。大型系统从不是一次性写出来的,而是在运行、修补、迭代中持续完善的。
02 | 旧世界:SRE 在工具荒原里拼地图
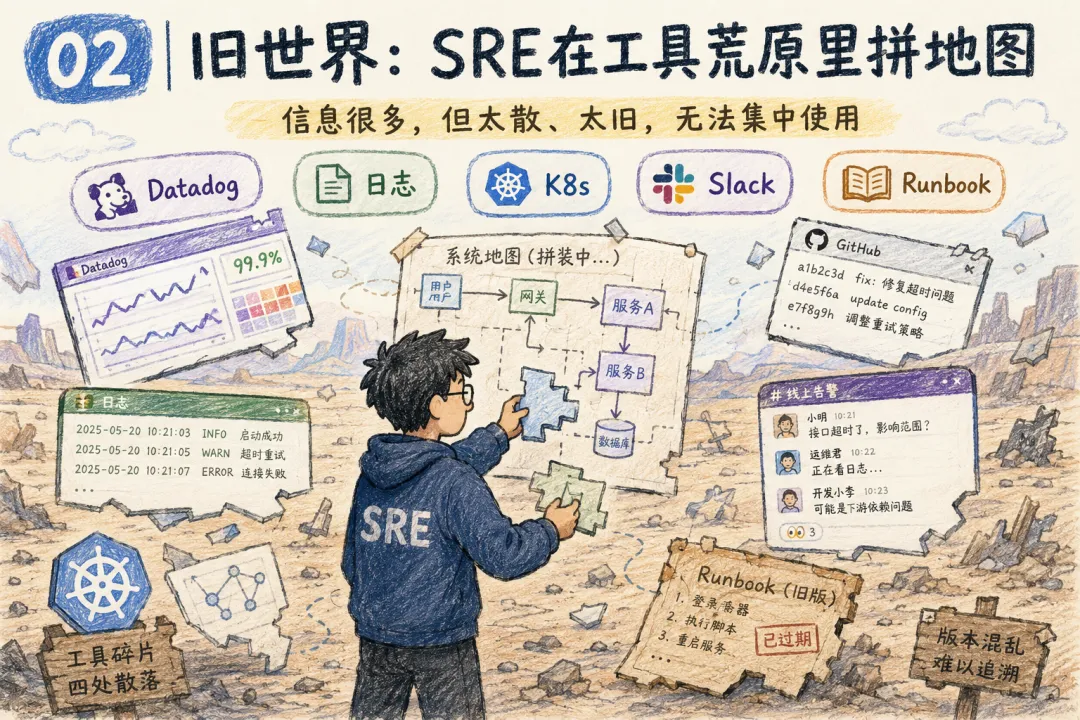
SRE 的痛苦不在于不知道系统坏了——警报早已明确提示。
难题是:不知道故障根因、影响范围、扩散风险,以及如何安全处置、避免二次故障。
一个生产事故通常不是一个错误。
它更像一团雾。
前端看到报错 500、应用提示超时、数据库连接数打满、Kubernetes触发重启,再叠加近期发版、灰度扩容等变量。每个工具只呈现碎片信息,SRE必须手动把碎片拼成完整真相。
传统 SRE 的责任是:运营监控、值班、故障排查、基础设施管理、安全。事件处理时,要从不同工具、不同团队、不同服务里找信息,还要依赖经常过期的 runbook。
云原生时代,容器、Kubernetes、多云与微服务进一步放大了系统依赖复杂度,数据量暴增、调用链路变长、隐性关联增多,也成为 SRE 职业倦怠的核心诱因——不是人不够努力,而是工作方式被系统复杂度彻底压垮。
03 | SRE 核心基本功:监控的四个黄金信号
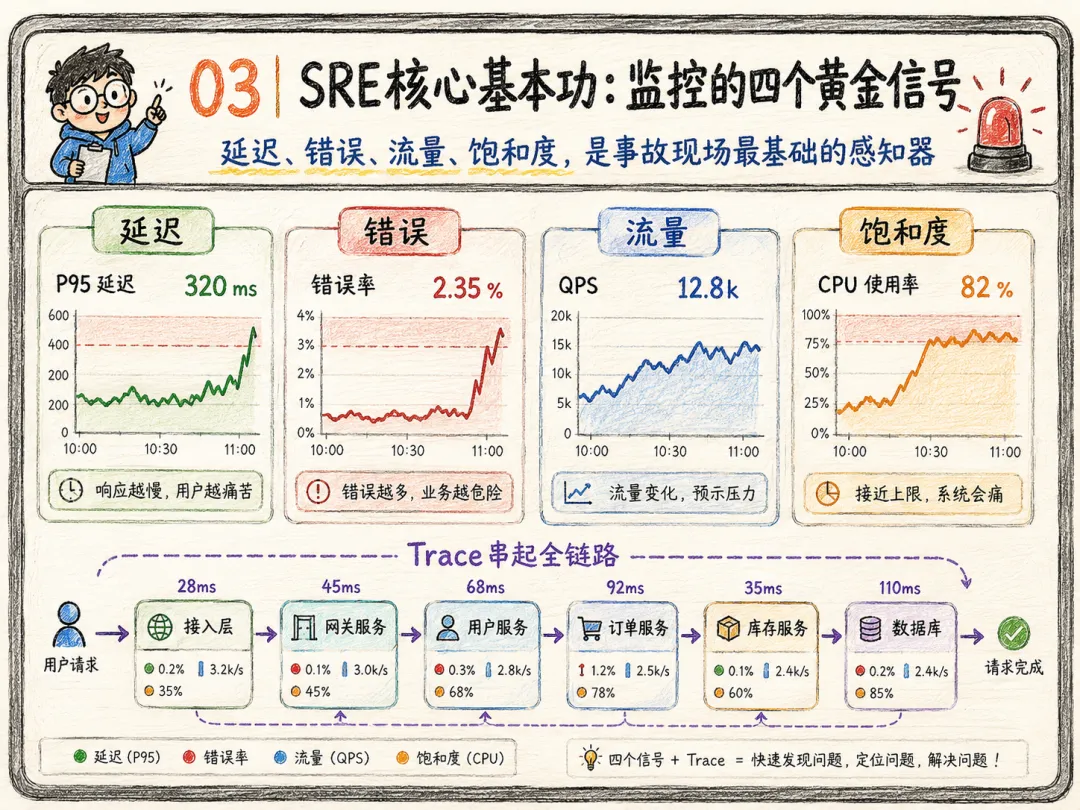
这讲回到一个非常经典的 SRE 基本功:四个黄金信号。
延迟、错误、流量、饱和度。
延迟(Latency)用于衡量单次请求的处理耗时。需分开统计成功请求与失败请求,HTTP 500 这类失败请求会扭曲平均耗时数据。高耗时异常报错隐患极大,必须重点紧盯监控。
错误率(Errors)告诉你:请求失败的发生占比,分为显性报错(如 HTTP 500)、隐性异常(状态码 200 正常但内容错误)、规则违规(超出响应时长约定)。搭建多层监控,全面捕获各类故障。
流量(Traffic)代表系统业务负载,常用每秒请求数衡量,也可按业务适配统计口径:流媒体统计会话数、数据库统计事务数。
饱和度(Saturation)反映系统资源占用饱满程度,监控 CPU、内存、磁盘 IO 等紧缺资源。系统往往未达 100% 使用率就开始卡顿,需划定安全阈值。密切监测延迟上涨、存储即将占满等资源即将触顶的前兆。
用户是不是真的受影响了?
影响范围是一小段流量,还是全站?
错误是新出现的,还是老问题被放大了?
最近有没有发版、迁移、配置变更、扩容缩容?
数据库慢,是数据库自己慢,还是应用侧把连接池打爆了?
微服务时代必须监控生产环境追踪数据(Traces)。单条日志只能反映单个服务的状态,而 Trace能串联用户请求从入口、服务调用、数据库到缓存的全链路,帮你精准定位请求在哪里摔倒。
编者注:AI SRE 无法凭空分析根因,它依赖指标、日志、追踪、部署记录、运行手册等可观测数据。如果底层数据质量差,AI 只会把错误信息包装得更逼真。
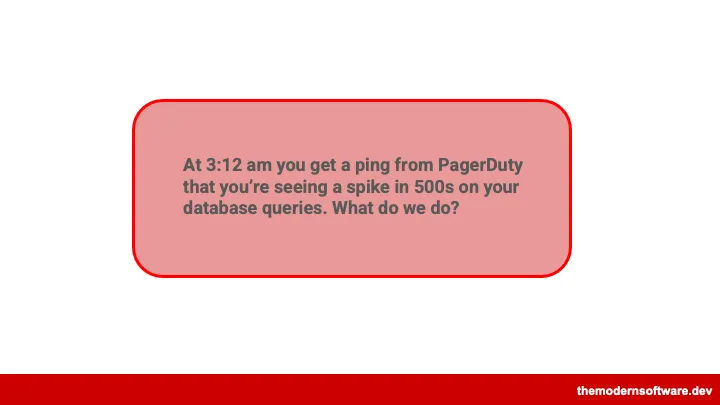
04 | 凌晨 3:12:一次数据库 500 错误的值班剧本
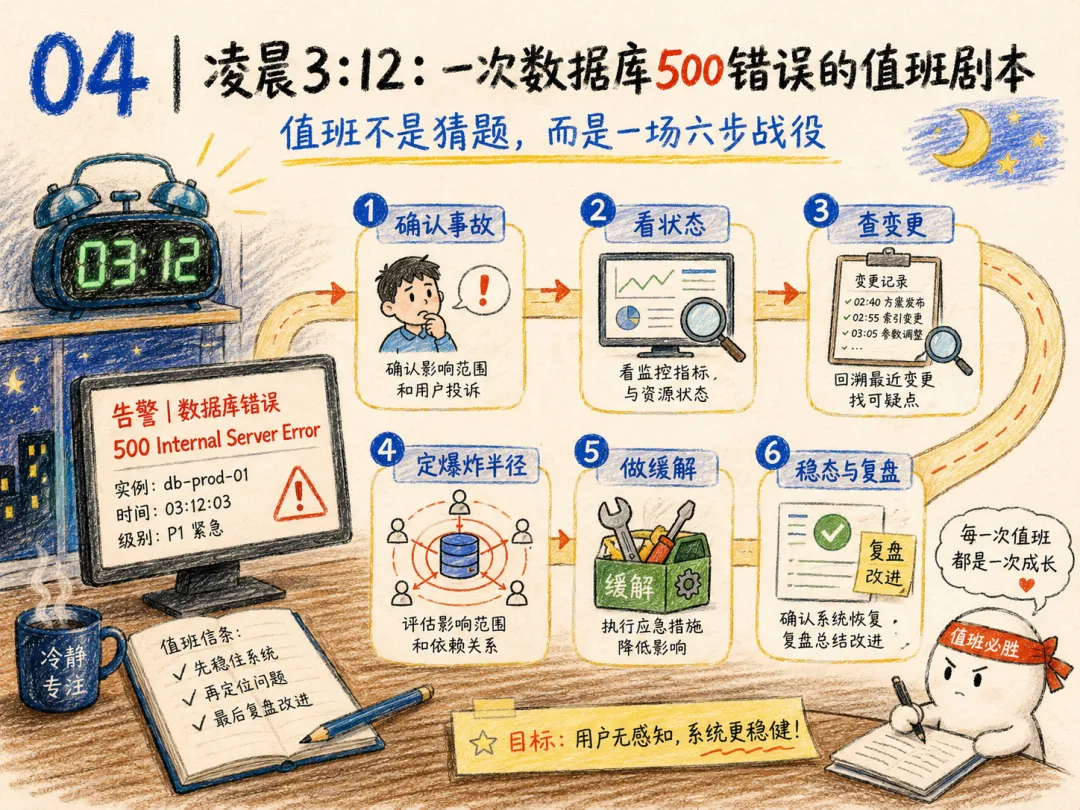
Mihail 还原了最真实的值班场景:
凌晨 3:12,PagerDuty 提醒你,数据库查询的 500 错误出现尖峰。现在怎么办?
这不是选择题,而是一场标准化的小型战役,标准 Playbook 是如下六个步骤:
1先确认事故,别让报警孤零零挂着。确认严重级别,看应用和数据库仪表盘,判断是局部异常,还是一次真正的线上事故。
2接着看数据库和应用状态。连接数是不是打满了?P95 延迟有没有突然上升?错误是 timeout、refused connection,还是 transaction aborted?CPU、IOPS、锁、内存、复制延迟有没有异常?
3然后看最近变化。最近有没有部署?有没有数据库迁移?环境有配置或 Feature Flag 改动?有没有自动扩缩容事件?如果高度相关,先回滚,再争论。
4再定位爆炸半径。是所有查询,还是某几个查询?是读还是写?是主库还是副本?是某个 shard,还是全部实例?是应用连接池问题,还是数据库负载问题?
5之后才是缓解。连接问题可以重启应用 Pod 或降低并发。数据库饱和可以暂停重任务、限流、把读请求导到副本。慢查询可以临时关功能、降级、走缓存。副本延迟可以调整读路由。节点异常要区分主库和副本,不要在恐慌中乱重启最关键的那台机器。
6最后是稳定、沟通、记录。看 500 率、数据库延迟、流量是否恢复。确认没有重试风暴和级联故障。每 10 到 15 分钟给出简短更新:发生了什么、正在做什么、现在状态如何。事故结束后整理时间线,写清楚根因、补充索引、修查询、调容量、改重试策略。
这套流程逻辑清晰,难点在于:在凌晨、高压、信息噪声与跨团队沟通中,精准落地每一步。
同时,事故处置核心跟踪指标也明确:平均修复时间(MTTR)、介入事故的工程师数量、客户 SLA 达标情况。
05 | 新世界:AI SRE 不是神探,而是值守副驾驶
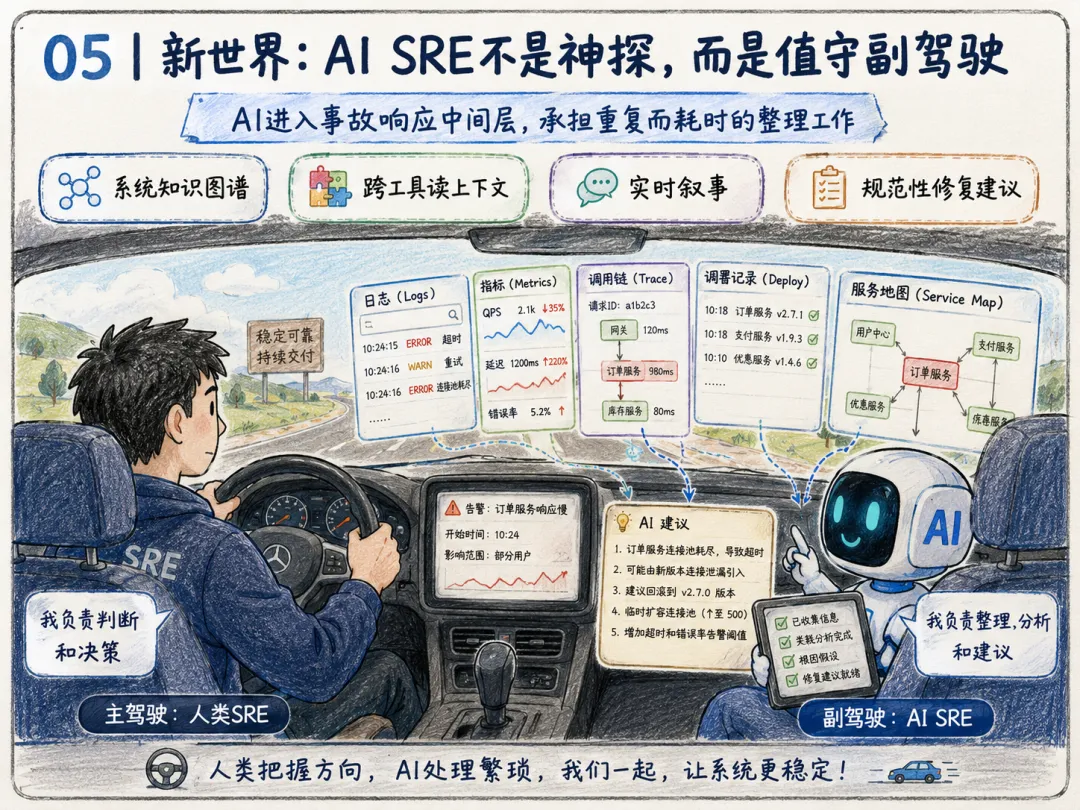
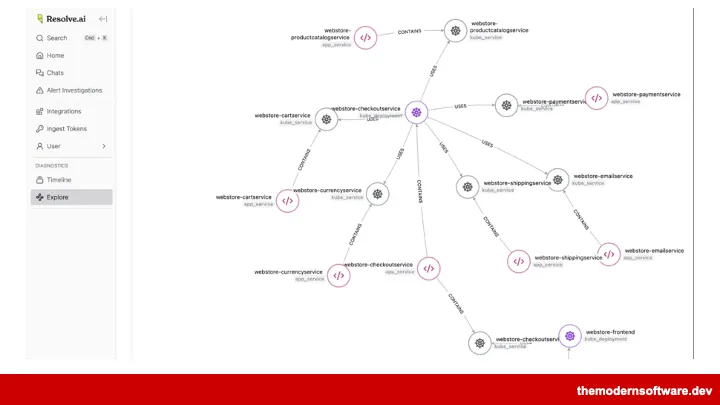
进入 AI 赋能的新世界,行业已出现几类工具:Resolve AI、Datadog Bits AI Agent、Splunk Observability Assistant。
但它们绝非「AI自动修复生产故障」的万能工具。
更准确的定位是:AI进入事故响应中间层,承担过去最消耗人力的重复性工作。AI SRE 的核心能力有四点。
第一,动态绘制系统知识图谱。过去你要靠人记住服务关系:这个 API 依赖哪个队列,哪个队列写入哪个消费者,消费者又写哪张表,哪张表有历史索引问题。AI SRE 的一个方向,是把这些关系从工程师记忆中搬出来,转化为可查询、可更新、可追踪的系统地图。
第二,跨工具读取上下文。事故现场最烦人的不是没有数据,而是数据散在太多地方。一个智能体能够自动读取指标、日志、Trace、部署记录、代码变更等全量信息,免去人工复制整合。
第三,生成实时叙事。把冰冷的仪表盘数据,转化为清晰的故障时间线、可疑变更、验证假设,统一团队认知。
第四,给出规范性修复建议,而非模糊判断。不是一句「数据库可能有问题」,而是更接近:建议先回滚某次部署;建议暂停某个批处理任务;建议降低某 endpoint 的并发;建议把读流量切到主库或健康副本;建议生成一个 PR 修复慢查询或补索引。同时保留人类审批的核心护栏——人类审批、权限控制、审计记录和验证闭环。
编者注:不建议将 AI SRE 当做「机器人值班」,生产环境无试错空间。它更像不疲倦的副驾驶,帮你盯仪表、查手册、标风险,但最终处置决策,必须由工程师确认。
06 | 真正改变的是知识的流向
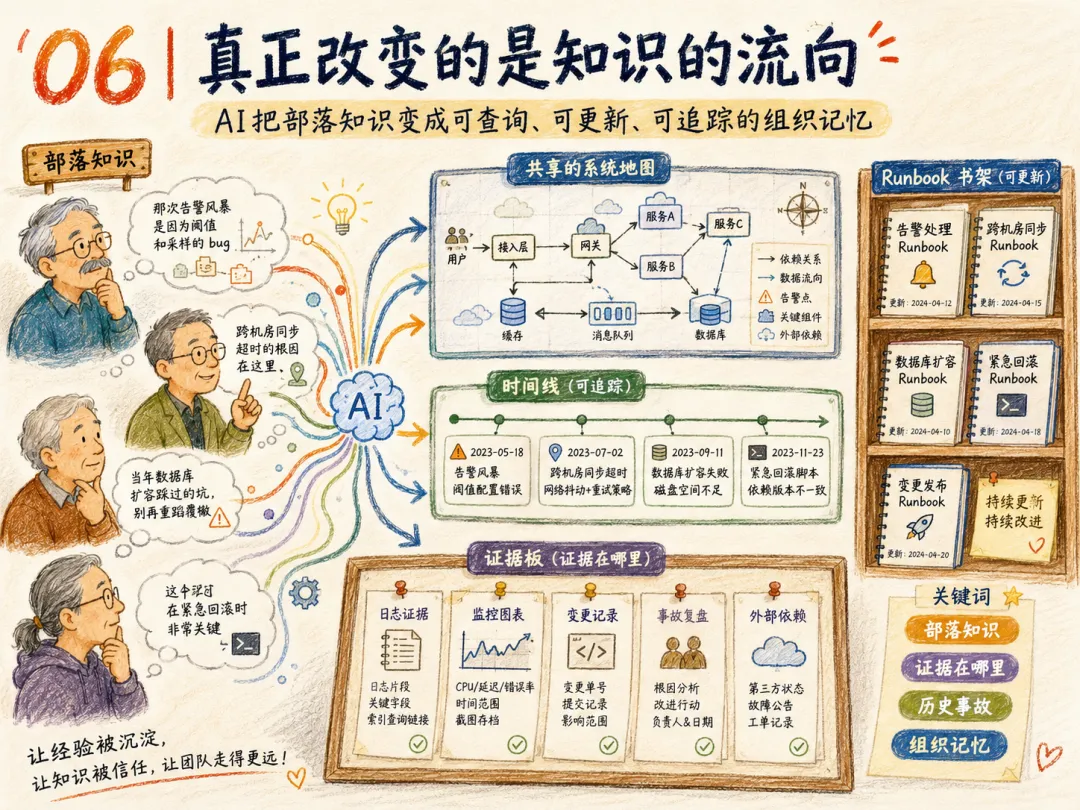
这一讲中很有意思的一个观点是,AI将规模化放大组织级与服务级知识。
过去,生产系统最值钱的知识,常常不是写在文档里,而是藏在人身上。这就是部落知识(Tribal Knowledge):老服务的重启禁忌、数据库索引的历史坑点、月末流量的规律波动,都在某几个资深工程师脑子里。
部落知识很珍贵,也更危险。
珍贵在于它来自血汗。危险在于它不可复制,不可审计,也很难稳定传承。懂它的人一走,系统就像失去了一段记忆。
AI SRE 的核心价值,是把这些散落的知识重新组织起来,重构知识流转方式。
把「谁知道」变成「证据在哪里」。
把「我记得上次」变成「历史事故有相似模式」。
把「你去手动翻文档」变成「自动整合全量相关信息」。
从编码智能体到运维智能体,AI 的价值也从提升个人效率,升级为完善组织记忆。
一个会写代码的编码智能体,解决的是个人效率。
一个会深入生产环境的运维智能体,变革的是组织记忆。
07 | 但生产不会因为 AI 变简单
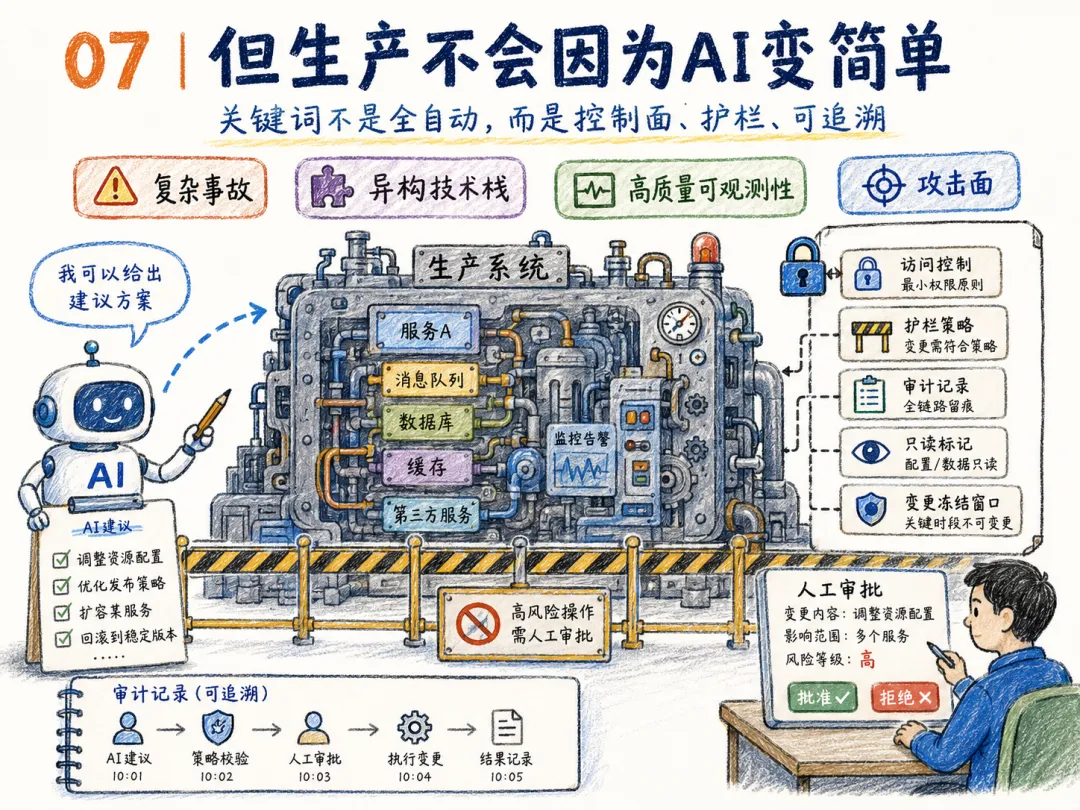
Mihail 并未神化AI DevOps,而是清晰列出了现实约束:
第一,复杂事故难解决。
真实生产事故往往不是单点根因,而是多因素叠加:一次部署、一个旧配置、一个容量边界、一个重试风暴,再加一个下游服务抖动。AI 可以形成假设,但它也易过早锁定单一解释。
第二,技术栈异构性。
云厂商、Kubernetes、数据库、消息队列、边缘服务、旧系统、内部平台,每家公司的生产环境都不一样。AI SRE 要接入这些工具,首先要过「上下文」这一关。
第三,修复能力有限。
根因分析是一回事,真正修复代码是另一回事。哪怕 AI 发现了某个查询导致数据库抖动,它也未必能安全地改业务逻辑、迁移数据、补索引、验证性能、处理回滚方案。现在很多提供商从根因分析开始,最终目标才是更深的修复。
第四,根因分析依赖高质量可观测性。
没有好的指标,没有干净的日志,没有完整的 trace,没有部署事件,没有服务所有权,AI SRE 就像一个进了档案馆却发现所有文件都没贴标签的人。
第五,AI 本身会成为新的攻击面。
只要一个系统能读日志、查代码、连工具、生成命令,它就值得被攻击。提示注入、权限滥用、越权读取、错误自动化、伪造证据,都可能从 AI 辅助功能变成生产风险。
所以,AI DevOps 的关键词不是「全自动」。
是控制面、护栏、可追溯。
这才像一个能进生产环境的系统。
08 | 给团队的一张落地清单

如果把这节课落成工程实践,团队可以从三张清单开始。
第一张,观测底座清单。
核心服务覆盖四大黄金信号,核心链路全量 Trace;部署、配置、功能开关变更可追溯;服务有明确负责人,运行手册定时更新验证。底层数据不完善,先别急着上线 AI SRE。
第二张,事故工作台清单。
事故现场统一归集:当前症状、影响范围、时间线、近期变更、假设与排除项、执行动作、沟通节奏、回滚计划、后续事项。AI 最适合在此环节辅助整理。
第三张,AI 护栏清单。
第一阶段只读,不允许直接执行生产命令。第二阶段生成建议,但需要人审批。第三阶段允许低风险动作,比如创建工单、生成 PR、补充 postmortem 草稿。第四阶段才讨论受控执行,而且必须有权限边界、审计日志、回滚方案和验证信号。
生产环境需要保守,无边界的 AI SRE,不是救火员,而是无序操作的风险源。
09 | 软件工程新命题:从会构建,到会运行
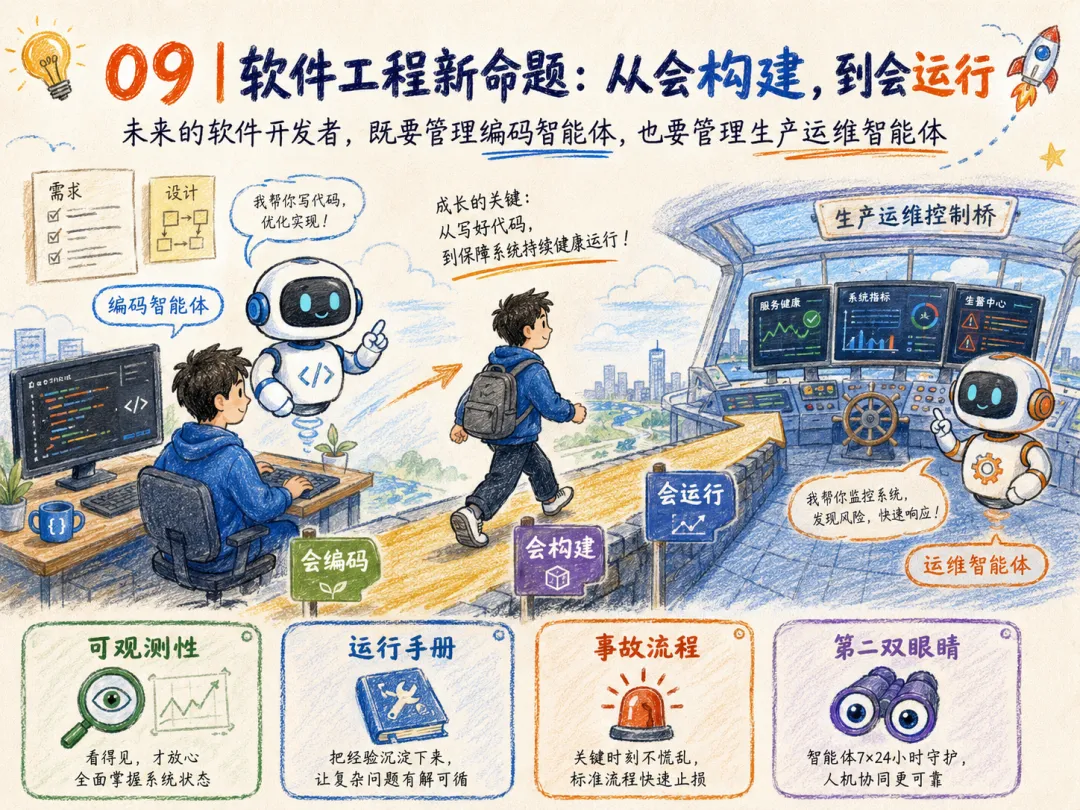
CS146S 课程此前一直传递一个核心判断:现代软件开发者,正在成为编码智能体的管理者。
第九周第一讲把这个判断又往前推了一步。
第九周第一讲把这个判断再推进一步:未来的软件开发者,既要管理编码智能体,也要管理生产运维智能体。
这将彻底改变工程师的能力结构:除了编码、架构、测试,还要掌握可观测性设计、运行手册维护、事故流程设计、AI 假设判断、自动化权限配置、生产动作审查、系统缺陷复盘。
AI 没有让软件工程变成魔法,而是让它回归系统工程的本质。写代码是开始,上线是开始,第一次警报也是开始。成熟的团队从不是零事故,而是能更快找证据、稳风险、深复盘,让同类故障不再重复发生。
AI SRE 如果能做到这一点,它就不是技术炫技,而是现代软件开发者的第二双眼睛。
下回我们继续看第九周第二讲:Agentic AI for software in production。也就是智能体真正进入生产软件后,工程团队会如何重新设计自己的工作方式。
10 | 课程 PPT