 夜雨聆风
夜雨聆风GPT 是自然语言处理、深度学习、Transformer、大语言模型和生成式人工智能中非常重要的一个术语,全称是 Generative Pre-trained Transformer,通常可译为“生成式预训练 Transformer”。它用来描述一种基于 Transformer 架构、通过大规模文本预训练获得语言生成能力的模型。换句话说,GPT 是在回答:模型怎样根据已有文本,继续生成符合上下文的后续内容。
如果说 BERT 更像一个擅长阅读理解的双向编码模型,那么 GPT 更像一个擅长续写、回答、对话和生成内容的语言模型。它会根据前文不断预测下一个 token,再把生成出的 token 接到上下文后面,继续预测下一个 token,直到形成完整回答。
因此,GPT 常用于对话问答、文章写作、摘要生成、翻译、代码生成、信息抽取、智能客服、工具调用、智能体规划和多模态系统中的语言生成部分,是理解现代大语言模型的重要基础概念之一。
一、基本概念:什么是 GPT
GPT 是 Generative Pre-trained Transformer 的缩写。
它包含三个关键词:
• Generative:生成式,表示模型能够生成文本
• Pre-trained:预训练,表示模型先在大规模文本上学习通用语言规律
• Transformer:表示模型基于 Transformer 架构
一个典型 GPT 任务可以是:
输入:请解释什么是机器学习。
输出:机器学习是一种让计算机从数据中学习规律,并用这些规律进行预测或决策的方法。
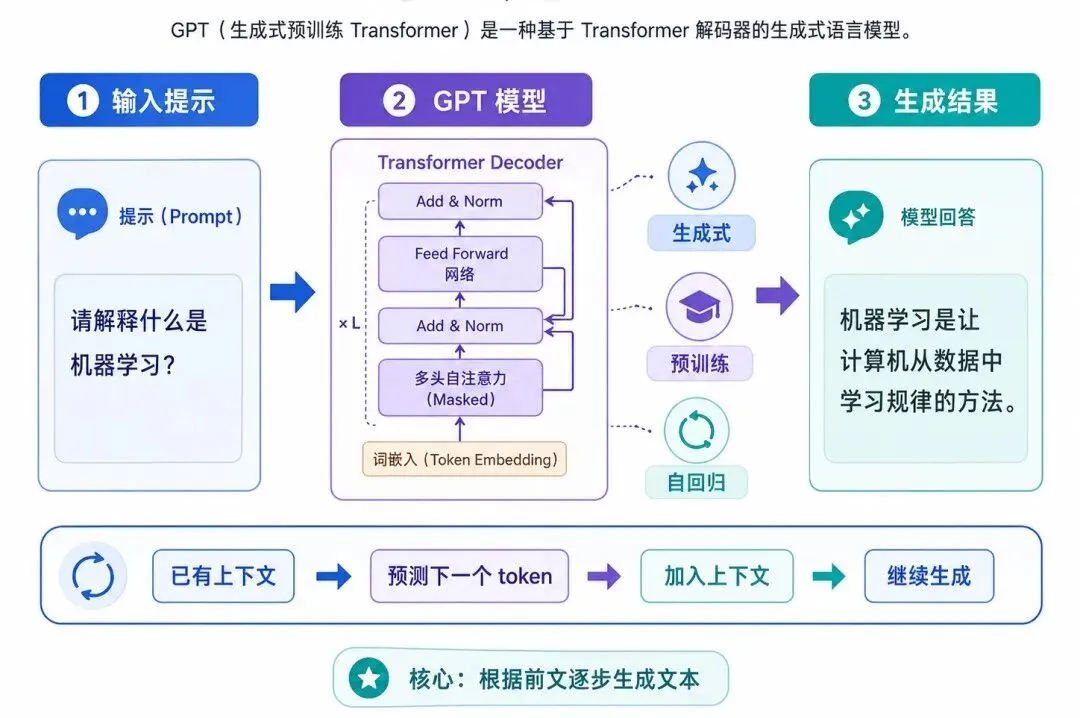
图 1:什么是 GPT
从通俗角度看:GPT 就是一个根据上下文继续生成文字的模型。
它不是简单从资料库中复制答案,而是根据训练中学到的语言规律、知识关联和当前输入,逐 token 生成输出。
GPT 的基本生成过程可以概括为:
已有上下文 → 预测下一个 token → 加入上下文 → 继续预测 → 形成完整文本
例如:
人工智能 → 正在 → 改变 → 世界模型每一步都在回答:根据前面已经出现的内容,下一个 token 最可能是什么?
二、为什么需要 GPT
GPT 之所以重要,是因为许多自然语言任务本质上都可以转化为“根据输入生成输出”。
例如:
• 问答:根据问题生成答案
• 写作:根据主题生成文章
• 摘要:根据原文生成简短概括
• 翻译:根据源语言生成目标语言
• 代码:根据需求生成程序
• 对话:根据上下文生成回复
• 推理:根据问题逐步生成分析
在 GPT 出现之前,很多 NLP 任务往往需要分别设计模型或任务结构。
例如:
• 分类任务用分类模型
• 翻译任务用翻译模型
• 摘要任务用摘要模型
• 问答任务用问答模型
GPT 代表的生成式预训练模型,让许多任务都可以用统一的文本生成方式处理:
任务说明 + 输入内容 → 生成结果
从通俗角度看:GPT 的价值在于,它把许多语言任务统一成了“读懂提示词,然后生成合适回答”的问题。
这也是现代大语言模型能够通过提示词完成多种任务的重要原因。
三、GPT 的核心结构:Transformer Decoder
GPT 基于 Transformer 架构,但它主要使用的是 Decoder 部分。
Transformer Decoder 的关键特点是:只能看到当前位置之前的 token,不能提前看到未来 token。这非常适合文本生成。
1、输入 token 序列
一句话会先被切分成 token。
例如:
人工智能正在改变世界可以被切分为:
人工 / 智能 / 正在 / 改变 / 世界实际模型中的 token 切分可能更复杂,可能是字、词、子词或符号片段。
2、因果掩码
GPT 在训练和生成时使用因果掩码,使当前位置只能关注前面的 token。
例如,生成第 k 个 token 时,模型只能看到:
t₁, t₂, ..., tₖ₋₁而不能看到未来的:
tₖ₊₁, tₖ₊₂, ...可以简化表示为:
其中:
• t₁, t₂, …, tₖ₋₁ 表示已有 token
• t_k 表示当前要预测的 token
• p 表示模型预测概率
从通俗角度看:GPT 像写文章时从左往右写,不能先偷看后面的答案。
3、逐层更新表示
GPT 由多层 Transformer Decoder 堆叠而成。每一层都会根据已有上下文更新 token 表示。
可以简化为:
其中:
• H⁽ˡ⁻¹⁾ 表示上一层隐藏表示
• H⁽ˡ⁾ 表示第 l 层输出表示
经过多层处理后,模型会得到当前位置的上下文表示,并预测下一个 token。
四、自回归生成:GPT 的关键思想
GPT 的核心生成方式是自回归生成。
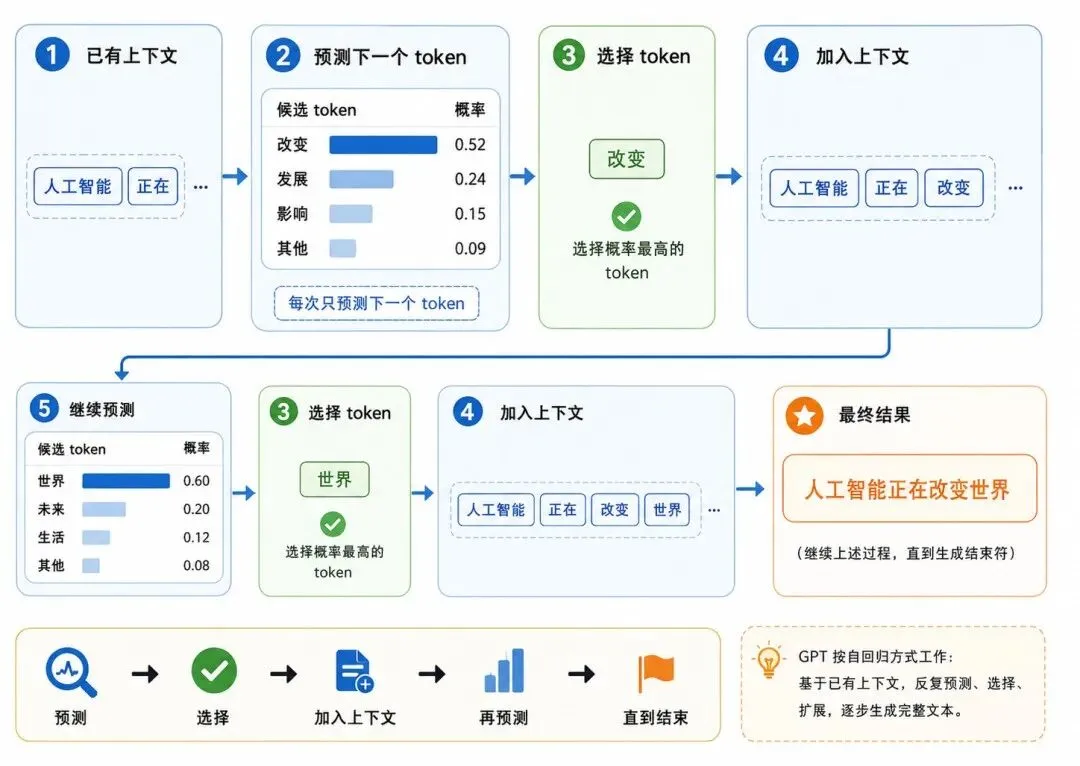
图 2:GPT 的自回归生成过程
自回归生成指模型每次生成一个 token,并把这个 token 作为后续生成的上下文。
可以表示为:
其中:
• t₁, t₂, …, t_n 表示完整 token 序列
• p(t_k | t₁, …, tₖ₋₁) 表示根据前文预测第 k 个 token 的概率
• ∏ 表示连乘
从通俗角度看:一句话不是一次性生成出来的,而是一个 token 一个 token 接出来的。
例如:
输入:机器学习是一种模型可能依次生成:
让 → 计算机 → 从 → 数据 → 中 → 学习 → 规律 → 的 → 方法每生成一步,上下文都会变长。
这使 GPT 能够生成连贯文本,但也带来一个问题:前面生成错了,后面可能继续沿着错误方向生成。
因此,GPT 的输出质量不仅取决于模型能力,也取决于提示词、上下文、解码策略和外部工具。
五、GPT 如何预训练
GPT 的预训练目标通常是预测下一个 token。
训练数据来自大量文本。
模型看到一段文本前缀,学习预测后续 token。
例如:
人工智能正在模型需要预测:
改变可以写为:
其中:
• θ 表示模型参数
• t_k 表示第 k 个 token
• p_θ 表示模型在参数 θ 下给出的概率
• log 表示对数概率
这个目标的意思是:让模型尽量提高真实下一个 token 的预测概率。
从通俗角度看:GPT 的预训练像做“文本续写练习”。
模型反复练习:看到前文,猜下一个 token。
经过大量文本训练后,模型学会了:
• 词语搭配
• 语法结构
• 事实关联
• 文体风格
• 问答模式
• 代码模式
• 推理表达方式
这就是 GPT 能够进行多种语言任务的基础。
六、从 GPT 到指令模型
原始 GPT 主要学会“续写文本”。但现代用户通常希望模型“按照指令完成任务”。
例如,用户输入:
请用三点解释什么是过拟合。用户并不是希望模型随便续写,而是希望模型理解任务并按要求回答。
因此,GPT 类模型通常还会经过进一步训练和对齐。
1、指令微调
指令微调使用大量“指令—回答”样本训练模型。
例如:
指令:请解释什么是梯度下降。回答:梯度下降是一种……
它让模型从“会续写”变成“会按任务作答”。
可以概括为:
• 预训练:学习语言规律
• 指令微调:学习执行任务
2、偏好对齐
偏好对齐让模型更倾向于生成更有帮助、更清晰、更安全的回答。
常见方法包括:
• RLHF
• DPO
• RLAIF
这些方法通常使用“更好回答”和“较差回答”的比较数据。
3、安全训练与系统约束
实际应用中的 GPT 类模型还需要遵守安全边界。
例如:
• 不编造来源
• 遇到高风险问题要谨慎
• 遇到危险请求要拒绝
• 不泄露隐私
• 按指定格式回答
从通俗角度看:
• 预训练让 GPT 会说话
• 指令微调让 GPT 会办事
• 模型对齐让 GPT 更可靠、更安全、更符合人类期望
七、GPT 与 BERT 的区别
GPT 和 BERT 都基于 Transformer,但设计目标不同。
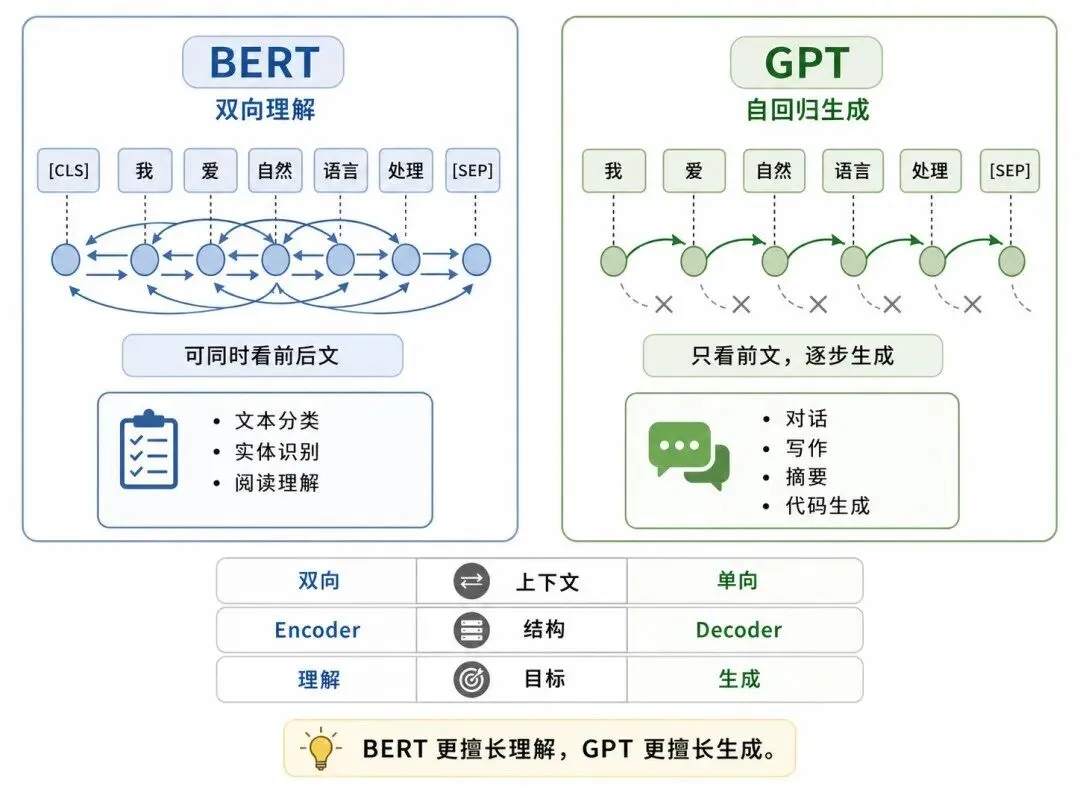
图 3:BERT 与 GPT 的区别
1、BERT:双向理解
BERT 使用 Transformer Encoder,可以同时看左侧和右侧上下文。
它适合理解类任务,例如:
• 文本分类
• 情感分析
• 命名实体识别
• 阅读理解
• 句子匹配
可以概括为:BERT 看完整输入,理解文本。
2、GPT:单向生成
GPT 使用 Transformer Decoder,通过因果掩码从左到右预测下一个 token。
它适合生成类任务,例如:
• 对话
• 写作
• 摘要
• 翻译
• 代码生成
• 开放式问答
可以概括为:GPT 根据前文,继续生成。
3、核心区别
• BERT:更像阅读理解模型
• GPT:更像文本生成模型
更具体地说:
• BERT 的核心是双向编码
• GPT 的核心是自回归生成
• BERT 常用于编码与判别
• GPT 常用于生成与对话
从通俗角度看:
• BERT 擅长“读懂一段话”
• GPT 擅长“接着写一段话”
八、GPT、LLM 与 ChatGPT 的关系
GPT、LLM 和 ChatGPT 经常被混用,但它们不是完全同一个概念。
1、GPT 是一种模型路线
GPT 指生成式预训练 Transformer 这一类模型思想。
它强调:
预训练 + Transformer Decoder + 自回归生成
2、LLM 是更大的类别
LLM 是 Large Language Model,即大语言模型。
GPT 类模型是 LLM 的重要代表,但 LLM 并不一定都叫 GPT。
可以概括为:GPT 是 LLM 的一种典型路线。
3、ChatGPT 是对话型应用
ChatGPT 是基于 GPT 类模型能力构建的对话式 AI 应用。
它不仅包含基础模型,还包括:
• 对话界面
• 指令遵循
• 安全策略
• 工具调用
• 记忆或上下文管理
• 多模态能力
• 系统提示与产品规则
从通俗角度看:GPT 更偏模型技术概念,LLM 是模型类别。ChatGPT 是面向用户的对话产品形态。
九、GPT 的优势、局限与常见误解
1、GPT 的主要优势
GPT 最大的优势是强大的生成能力和任务统一能力。
它可以:
• 自然对话
• 生成文章
• 总结文本
• 翻译语言
• 编写代码
• 解释概念
• 处理复杂提示词
• 执行多步骤任务
• 调用工具完成外部操作
从通俗角度看:GPT 让许多任务都可以通过自然语言接口来完成。
2、GPT 的主要局限
GPT 也有局限。
首先,GPT 可能产生幻觉。
它生成的是概率上合理的文本,不等于每个事实都经过核验。
其次,GPT 对上下文依赖很强。
如果提示词不清楚、材料不完整或上下文太长,模型可能误解任务。
再次,GPT 的知识可能受训练数据限制。
对于最新信息、实时数据、企业内部资料,应结合检索或工具。
此外,GPT 不一定擅长所有精确任务。
例如复杂数学计算、严格事实核验、法律判断、医疗诊断等高风险任务,需要工具、来源和人工审核配合。
3、常见误解
误解一:GPT = 搜索引擎
不对。GPT 是生成模型,不是天然的实时搜索系统。
误解二:GPT 输出流畅,就一定正确
不对。流畅只说明语言生成自然,不代表事实可靠。
误解三:GPT 会生成文字,所以等于真正理解世界
不准确。GPT 学到的是语言和知识模式,是否具备真实世界理解要结合任务、数据和外部环境判断。
误解四:GPT 只会聊天
不对。GPT 类模型可以用于写作、编程、总结、分析、问答、工具调用和智能体系统。
十、Python 示例
下面给出几个简化示例,帮助理解 GPT 的基本思想。
示例 1:逐 token 生成的直观过程
tokens = ["人工智能", "正在"]next_token_map = {"人工智能 正在": "改变","人工智能 正在 改变": "世界","人工智能 正在 改变 世界": "。"}for _ inrange(3):context = " ".join(tokens)next_token = next_token_map.get(context)if next_token is None:breaktokens.append(next_token)print("生成结果:", "".join(tokens))
这个例子展示了 GPT 生成文本的直观过程:
已有上下文 → 预测下一个 token → 加入上下文 → 继续生成
真实 GPT 不是查字典,而是通过神经网络输出概率分布。
示例 2:下一个 token 概率分布
import torchimport torch.nn.functional as F# 待预测的 token 列表tokens = ["改变", "发展", "影响", "推动"]# 模型输出的原始分数(logits)logits = torch.tensor([3.0, 2.0, 1.0, 0.5])# 应用 softmax 将 logits 转换为概率分布probs = F.softmax(logits, dim=-1)# 输出每个 token 对应的概率for token, prob in zip(tokens, probs):print(token, float(prob))
这个例子说明:GPT 生成时通常会得到候选 token 的概率分布。
模型可以选择概率最高的 token,也可以按采样策略生成更多样的结果。
示例 3:贪心解码
import torch# token 列表tokens = ["改变", "发展", "影响", "推动"]# 模型输出的概率分布probs = torch.tensor([0.60, 0.25, 0.10, 0.05])# 贪婪采样:选择概率最大的 token 索引selected_index = torch.argmax(probs).item()print("选择 token:", tokens[selected_index])
贪心解码每次选择概率最高的 token。它通常更稳定,但可能缺少变化。
示例 4:采样生成
import torch# token 列表tokens = ["改变", "发展", "影响", "推动"]# 模型输出的概率分布probs = torch.tensor([0.60, 0.25, 0.10, 0.05])# 按概率分布随机采样一个 token 的索引(不放回)sampled_index = torch.multinomial(probs,num_samples=1 # 采样 1 个).item()print("采样 token:", tokens[sampled_index])
采样生成会按照概率随机选择 token。它可以增加多样性,但也可能带来不稳定。
示例 5:提示词影响输出
prompts = ["解释什么是机器学习。","请面向小学生解释什么是机器学习。","请用教材风格解释什么是机器学习,并举一个例子。"]for prompt in prompts:print("提示词:", prompt)
这个例子说明:同一个模型在不同提示词下,可能生成不同风格、深度和结构的回答。
GPT 的实际使用效果,很大程度上取决于提示词、上下文和任务约束。
GPT 是生成式预训练 Transformer,核心思想是根据已有上下文预测下一个 token,并通过自回归方式逐步生成文本。它基于 Transformer Decoder,适合对话、写作、摘要、翻译、代码生成和开放式问答等生成任务。对初学者而言,可以把 GPT 理解为:一个先通过大量文本学会语言规律,再根据提示词逐步生成回答的预训练语言模型。

