 夜雨聆风
夜雨聆风
OpenAI 的项目,最近发布了一个新的模型openai/privacy-filter。
专门识别文本里的个人身份信息,也就是 PII,然后把这些字段脱敏掉。
官方给它的定位很清楚:一个可以本地运行、开放权重、面向高吞吐数据清洗流程的隐私过滤模型。
看完官方介绍,感觉这东西对做企业 AI、日志分析、数据清洗的人来说,可能比很多大模型发布都更实用。
它处理的是许多团队天天都会撞上的真实麻烦:
1. 客户对话能不能拿去分析?
2. 错误日志能不能丢给 LLM 帮忙排错?
3. 公司内部数据能不能进训练集?
这些问题最后都会卡在同一个点:里面有没有手机号、邮箱、姓名、地址、账号、密钥?
◆一、先看效果:一段日志进去,敏感字段被标出来
直接看一个最简单的例子。假设你有一段客服或日志文本:
Please contact Alice Chen at alice.chen@example.com or 138-0013-8000. Her account number is 6228-4801-2345-9090. The deploy token is sk-prj-9KX8a2lQzZ4y7vWmT.经过 Privacy Filter 处理,结果大概会变成这样:
Please contact [private_person] at [private_email] or [private_phone]. Her account number is [account_number]. The deploy token is [secret].第一,它会结合上下文看格式。邮箱和电话用正则也能抓出来,Alice Chen 这种人名、sk-prj-... 这种密钥,就必须放回句子里判断。
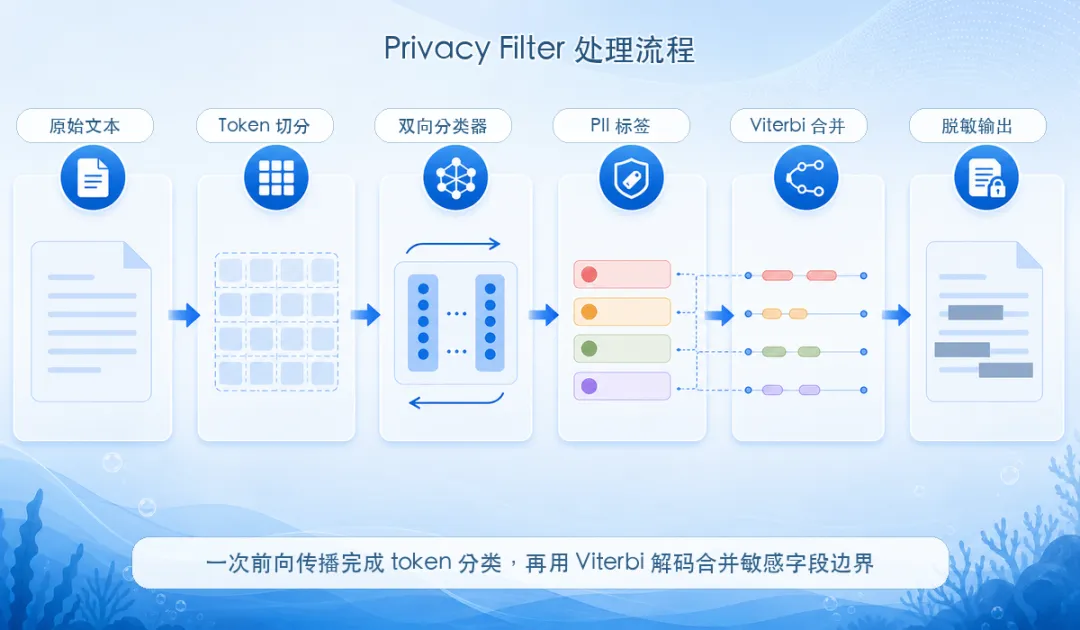
第二,它输出的是 token 级别的分类结果。简单说,就是输入一整段文本,模型给每个 token 打标签,再把连续标签拼成一个完整的敏感字段。
第三,它可以在本地环境里运行,也能在浏览器里通过 WebGPU 跑。对隐私场景来说,这一点很关键:脱敏前的数据可以完全不离开你的机器。
◆二、为什么这件事过去一直不好做

你可能觉得,脱敏不就是写正则吗?
如果只是邮箱、手机号、身份证号,正则确实能管住一部分。但真实业务里的文本,往往没这么规矩。
比如客服对话里会有这种句子:
客户说可以联系小陈,上次留的是 138 0013 8000。也会有这种:
测试环境账号 user_13800138000 今天又报错了。前者大概率是手机号,后者可能只是个内部测试账号。正则看到数字模式,很难判断该不该抹掉。
再比如代码日志里常冒出这些东西:
token=abc123 request_id=abc123 password=abc123同样是 abc123,跟在 request_id 后面可能只是请求编号,放在 password 后面就必须处理。
这恰恰是传统规则方案最疼的地方:它只看字符形状,不看语境。
传统 PII 工具常依赖确定性规则,适合窄场景,但面对非结构化文本、上下文依赖的字段、模糊引用时,容易漏掉,也容易误伤。
Privacy Filter 换了个思路:让模型先理解上下文,再做 token 分类。
这里用模型,原因很实际:真实业务里的文本已经超过了简单规则的舒适区。
◆三、Privacy Filter 到底是什么模型
先把几个核心参数放清楚:
它支持识别的 8 类 PII:
account_number:账号、银行卡号等private_address:私人地址private_email:私人邮箱private_person:私人姓名private_phone:私人电话private_url:私人 URLprivate_date:私人日期secret:密码、API key、凭证等
3.1 它是分类模型,不走聊天生成路线
普通 LLM 通常一个 token 一个 token 生成答案。Privacy Filter 的工作方式更像检测器:把输入文本一次性读进去,在一次前向传播里给每个 token 输出标签概率。
所以它的形态更接近“专用检测器”。
这直接带来一个好处:吞吐更高、延迟更低,也更容易塞进数据流水线。
你可以把它放在日志入库前、训练数据清洗前、LLM API 请求前,让它在数据流里快速完成第一轮扫描。
3.2 1.5B 总参数,每个 token 只激活 50M
Privacy Filter 用的是稀疏 MoE 结构。总参数 1.5B,但每个 token 推理时只激活 50M 参数。具体实现是 128 个 experts,每个 token 走 top-4 routing。
对开发者来说,核心理解很简单:它有比较大的模型容量,推理成本接近一个小模型。这也是为什么官方会强调,它能在笔记本和浏览器里跑。
3.3 Viterbi 解码让边界更稳
PII 脱敏最烦的是边界准确性。
比如 Alice Chen,如果只抹掉 Alice,留下 Chen,就很尴尬;如果把旁边的普通单词也一起抹掉,下游分析又会丢信息。
Privacy Filter 使用受约束的 Viterbi 解码,把 token 标签组合成更连贯的跨度。这种做法比逐个 token 独立取最大概率更容易得到稳定边界。这类工程细节不显眼,但特别影响生产体验。
◆四、跑分怎么样:强,也要看边界
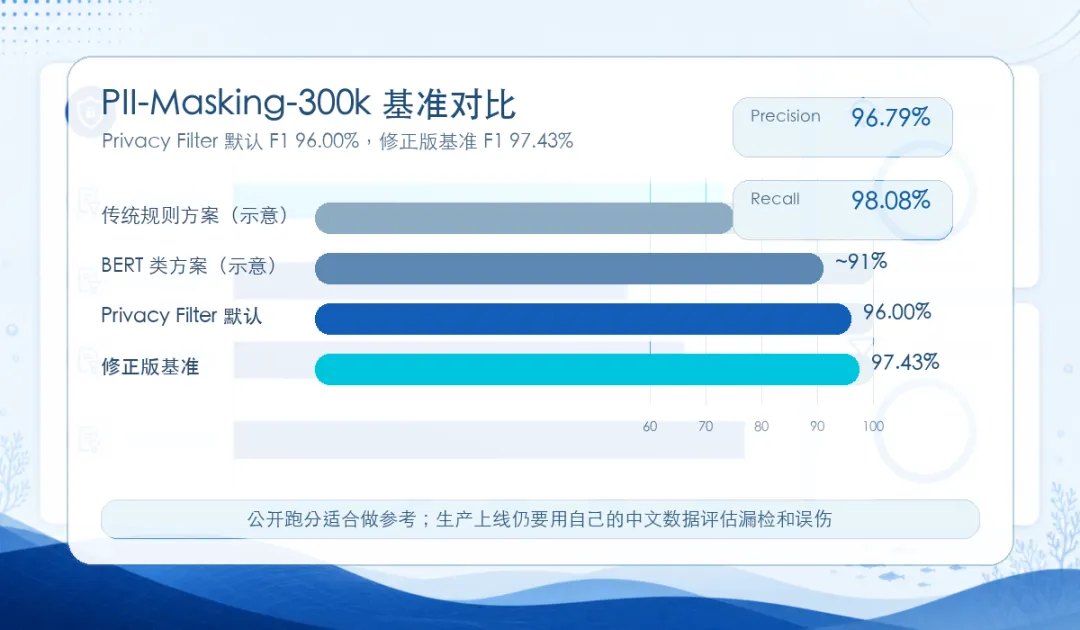
官方公布的数据里,Privacy Filter 在 PII-Masking-300k 基准上达到:
- F1:96.00%
Precision:94.04%
Recall:98.04%
OpenAI 后来还针对评估中发现的标注问题做了修正。在修正版基准上,结果是:
- F1:97.43%
Precision:96.79%
Recall:98.08%
另外,官方提到一个很实用的现象:在领域适配任务里,少量数据微调就能把 F1 从 54% 拉到 96%,接近他们评估的上限。
这说明默认模型已经不错。更大的价值,可能在“拿到你自己的业务数据之后做微调”。
如果你做金融、医疗、法务、政企项目,默认 8 类标签不一定能覆盖你的内部字段。病历号、保单号、工单号、内部客户编号,这些通常都需要你自己定义边界,再做领域微调。
◆五、5 分钟本地跑通
GitHub 仓库提供了本地 CLI,命令叫 opf。
5.1 安装
git clone https://github.com/openai/privacy-filter.git cd privacy-filter pip install -e .安装后,你就可以直接运行:
opf "Alice was born on 1990-01-02."默认情况下,opf 会优先找 OPF_CHECKPOINT 指定的模型路径,或者 ~/.opf/privacy_filter。如果本地没有,它会自动下载模型。
5.2 没有 GPU,也可以用 CPU
opf --device cpu "Alice was born on 1990-01-02."这类模型的优势就在这里:它在数据链路里快速扫描文本。很多日志、客服对话、表单备注,都可以先用 CPU 跑通最小可用的流程。
5.3 处理文件
opf -f /path/to/file也可以接 Unix 管道:
cat raw_chat_log.txt | grep "ERROR" | opf > sanitized_errors.log这条命令的意思是:先筛出错误日志,再把日志里的敏感信息脱敏,最后写入一个新文件。对工程团队来说,这比“打开一个 AI 平台手动上传文件”实用得多。它能进 cron,能进 CI,也能接在数据入库前。
5.4 在 Python 里调用
from transformers import pipeline classifier = pipeline(task="token-classification", model="openai/privacy-filter", ) classifier("My name is Alice Smith")如果你已经有数据清洗脚本,这种方式更容易集成。
5.5 浏览器里跑:Transformers.js + WebGPU
import { pipeline } from "@huggingface/transformers"; const classifier = await pipeline( "token-classification", "openai/privacy-filter", { device: "webgpu", dtype: "q4" }, ); const input = "My name is Harry Potter and my email is harry.potter@hogwarts.edu."; const output = await classifier(input, { aggregation_strategy: "simple" }); console.dir(output, { depth: null });这类用法特别适合“用户提交给云端之前先本地过滤”的产品。比如用户在网页里粘贴一段客服记录,你可以先在浏览器内把邮箱、手机号、token 抹掉,再把清洗后的文本发给后端或 LLM。
◆六、它适合放在哪些真实业务里
在我看来,Privacy Filter 最适合放进基础设施,成为数据进入下游系统之前的一层过滤。
6.1 LLM 请求前的隐私护栏
很多团队现在会把日志、工单、客服记录发给 LLM 做总结、分类、排错。问题是,这些文本里经常混着用户电话、邮箱、地址、订单号,甚至 API token。
比较稳的做法是:请求进入 LLM 之前,先过一遍 Privacy Filter。能本地处理的就在本地处理,能浏览器处理的就在浏览器处理。这一步的价值很明确:把敏感信息外发的概率降一大截。合规结论仍然要交给完整流程判断。
6.2 日志入库前清洗
日志系统很容易变成隐私黑洞。开发时大家会把 request、response、异常栈全打进去。上线后才意识到,里面有用户输入、手机号、身份证、内部 token。把 Privacy Filter 放在日志写入 ELK、Splunk、ClickHouse 之前,可以当作最后一道清洗层。
6.3 训练数据预处理
如果你要用公司内部语料微调模型,脱敏应该发生在训练前。模型一旦在训练阶段记住了敏感字段,后面再补救会非常麻烦。Privacy Filter 可以先把训练集里的 PII 替换成标签,比如 [private_email]、[private_phone],既保留文本结构,也降低泄露风险。
6.4 数据标注和审核后台
很多审核、标注、质检系统里,会有人类操作员查看原始文本。如果业务不需要他们看到完整的手机号或邮箱,就可以先做部分脱敏,再进入后台。这样可以减少内部越权查看的风险。
◆七、上线前必须知道的几个限制
这部分建议认真看。Privacy Filter 很实用,它仍然只是隐私方案中的一层。
7.1 它只是脱敏助手,合规证明另有流程
Privacy Filter 是 redaction 和 data minimization aid。匿名化、合规证明、安全保证这些事,还需要额外流程来承担。
换成容易理解的话就是:它能帮你做脱敏和数据最小化;完全匿名化、法务签字和安全担保,需要额外流程承担。
7.2 默认标签是固定的
它默认只识别前面说的 8 类 PII。
如果你的业务里有行业专属标识,比如病历号、保单号、航班会员号、内部客户编号,默认模型未必会按你的规则处理。
官方建议是做微调。运行时动态配置标签策略,目前还不现实。
7.3 中文和非拉丁文本要自己评估
模型元数据里写的是:主要语言是英文,并报告了部分多语言鲁棒性评估。
中文场景是否能直接上生产,需要靠本地评估判断。你至少要拿自己的中文客服记录、日志、表单备注跑一轮评估,看看漏检和误伤分别集中在哪些字段。
7.4 密钥格式变化很快
今天的 API key 是一种前缀,明天内部系统又发明一种新的 token 格式。Privacy Filter 能识别很多上下文里的 secret;
项目特有、格式很新的凭证仍可能漏掉。所以工程上最好是组合拳:Privacy Filter 负责上下文识别,传统 secret scanner 负责已知规则和高熵字符串,两边互补。
◆八、我会怎么在团队里落地
我会先把它放到旁路里评估,再逐步接入现有脱敏系统。
拿历史数据做离线评估。准备几百到几千条真实样本,人工标一版 PII 边界,看看默认模型漏了什么、误伤了什么。 把它接到低风险链路。比如先处理开发环境日志、测试客服记录、内部 demo 数据,不碰正式交易数据。 根据业务字段做微调。尤其是中文姓名、地址、行业编号、内部账号这些字段,最好用自己的数据补一轮。 再决定接入生产链路。生产里也不要只靠它一个模型,应该保留规则、审计、人工抽检、异常回滚。
很多 AI 工具刚出现时,团队最容易犯的错是急着把它放到最敏感的地方。隐私脱敏这种能力,就应该从边缘链路开始打磨。
◆九、写在最后:小模型也能很有价值
Privacy Filter 把一个很具体、很脏、很工程化的问题,做成了一个能本地跑、能进流水线、能微调、许可证宽松的工具。
大模型行业经常喜欢讲宏大的东西。对很多团队来说,真正卡住 AI 落地的,往往是这些小事:
1. 数据能不能出域?
2. 日志能不能给模型看?
3. 客户信息会不会混进训练集?
4. 上线前安全评审怎么过?
Privacy Filter 给开发者提供了一个很实在的起点,先把最明显的泄露风险挡在入口处。
如果你在做 ToB AI、数据平台、客服系统、日志分析、模型训练,我建议这周就找一小批真实文本跑一下。先看它在你的真实数据里漏掉什么、误伤什么,再决定放到哪条链路。
这类工具用好了,AI 系统会少很多后患。
资料链接:
官方介绍:openai.com/index/introducing-openai-privacy-filter
GitHub 仓库:github.com/openai/privacy-filter
Hugging Face 模型:huggingface.co/openai/privacy-filter
在线 Demo:huggingface.co/spaces/openai/privacy-filter
