 夜雨聆风
夜雨聆风这几天,我一直在试着用 AI 做公众号的封面图和一些内容插图。
中间也遇到过不少问题。
我后来发现,AI 画图最容易让人误会的地方,是我们总以为问题出在提示词。
有些图单独看还可以,但放进文章里就不太对。
有些图氛围是对的,但背景太暗,阅读不友好。
还有一些图,看起来像是完成了任务,但其实和正文关系很弱,只是在风格上凑了一个“配套”。
这让我想起前几年刚开始玩 AI 绘图时的状态。
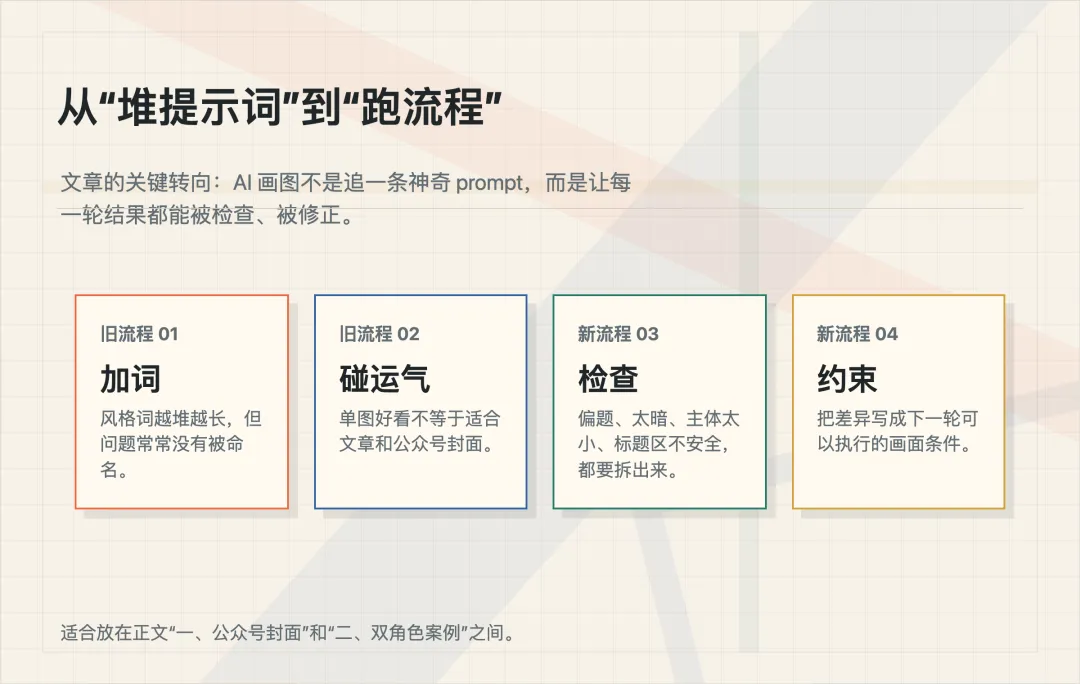
那时候我的流程很简单:
先写一段 prompt。
把风格词堆进去。
生成一张图。
不好看,就继续加词、换词、改词。
如果运气好,就能碰到一张还不错的。
但现在回头看,这个流程其实很靠运气。
它真正缺的,可能不是一个更厉害的提示词。
而是一套能不断校正结果的流程。
一
事情的起点其实是公众号封面。
最近刷公众号的时候,我发现很多人的封面图,已经明显是用 AI 定制出来的了。
有些不一定多复杂,但它和文章主题是贴着的。
而我以前做封面,更多还是去网上找图。
这样虽然也能解决问题。
但它有两个麻烦。
一方面,是版权风险。
另一方面,是找图本身也很耗时间。
你要找一张主题合适、气质合适、比例合适、还能放进公众号封面里的图,其实并不轻松。
当然,用 AI 做封面也不一定更省时间。
甚至很多时候,它一样很耗时间。
但我还是想试一试。
我根据自己的经验和理解,做了一个内容生图的 Skill。
它会先理解文章,再判断应该做封面、文内图,还是别的视觉资产。
后面再进入生成、检查和修改。
这个 Skill 也放在了我的 skills 仓库里:
https://github.com/fxbin/skills它现在也不是一个已经完全定型的东西。
我还在根据每次生成封面、文内图和内容卡片时遇到的问题,不断调整里面的判断规则和质量门禁。
我想通过真实发布,把这套东西继续跑实。
以后如果写 AI 工具、写工作流,也不只是转述别人的方法,而是能有一点自己的体感。
同时也是希望让发布出去的内容,阅读体验更好一点。
封面和插图不是文章的核心。
但它确实会影响读者打开、停留和理解这篇文章的方式。
所以这件事看起来是在做图。
但往深一点说,其实是在试着把内容表达的最后一公里,也交给一个更稳定的流程。
二
我后来看到一个案例,觉得很有意思。
它的做法不是让一个 AI 一次性猜出完美 prompt。
而是设计了两个角色。
一个 AI 负责看图,然后反推提示词。
另一个 AI 负责用这个提示词生成图片,再拿生成图和原图做比较。
它不负责夸。
它只负责挑差异。
比如:
人物是不是太小了?
文字层级有没有跑掉?
视觉重心是不是偏了?
背景是不是太暗?
某个关键元素是不是缺了?
然后再把这些差异,变成下一轮提示词里的约束。
一轮不行,就再来一轮。
直到它足够接近,或者达到提前设好的停止条件。
我看到这里的时候,其实会想起前阵子做的那个内容生图 Skill。
它不是只保存一组封面 prompt。
它更像是把“内容理解、视觉生成、质量检查”拆成了几个前后相接的环节。
其中最重要的一点,也是让不同角色做不同的事。
一个角色负责把文章转成图。
另一个角色负责回头检查:
它有没有偏题?
文字区域安不安全?
背景会不会太暗?
缩小到公众号封面以后,还能不能看清?
所以外部案例给我的,并不是一个完全陌生的新方法。
它更像是帮我确认了一件事:
我之前做 Skill 时,那种让生成和判断分开的思路,确实是对的。
这个机制也让我把原来有些模糊的体感说清楚了。
AI 生图的问题,很多时候不是“它不知道怎么画”。
而是我没有给它一个可以反复校正的系统。

三
所以这个案例最打动我的地方,不是它最后得到了一段多完整的 prompt。
而是它把“改图”这件事,从感觉里拆了出来。
以前我改图,很容易只停在几个模糊判断上:
这张不够好看。
这个风格不太对。
这版好像差点意思。
但这些话其实很难指导下一轮生成。
因为它没有说清楚到底哪里出了问题。
每一轮到底改了什么?
为什么要这么改?
上一版的问题有没有被解决?
新版本有没有引入新的问题?
这些东西如果没有被拆出来,所谓“优化”,就很容易变成一种凭感觉的乱调。
一开始你想要的是封面图。
改着改着,可能变成了一张挺炫但不能用的图。
或者它单独看还不错,但放到公众号封面里,标题被压住了,主体也看不清。
这也是我觉得那个案例有价值的地方。
它不是把提示词写得更长。
而是把“哪里不像”“哪里不对”“哪里还不能用”,拆成了可以执行的反馈。
四
回到我自己的公众号配图流程里,我会更谨慎地说:
我现在做的这个内容生图 Skill,已经有了这套思路的雏形。
它目前能做的,主要是前半段。
先理解文章。
判断这篇文章更适合做封面、文内图,还是内容卡片。
再根据不同场景,生成对应的视觉方案。
生成之后,也会有一层质量检查:
内容有没有跑偏?
中文标题是否清楚?
标题区是否干净?
画面会不会太暗?
缩小到公众号封面以后,还能不能看清?
如果不合格,就回到前面的环节重试,或者切换成工程化渲染。
这已经比单纯写一句 prompt 稳定很多。
但它还没有完全变成一个自动化的“双 Agent 对比闭环”。
它现在更像是:
内容理解 -> 视觉生成 -> 质量门禁 -> 人工判断后再调整。
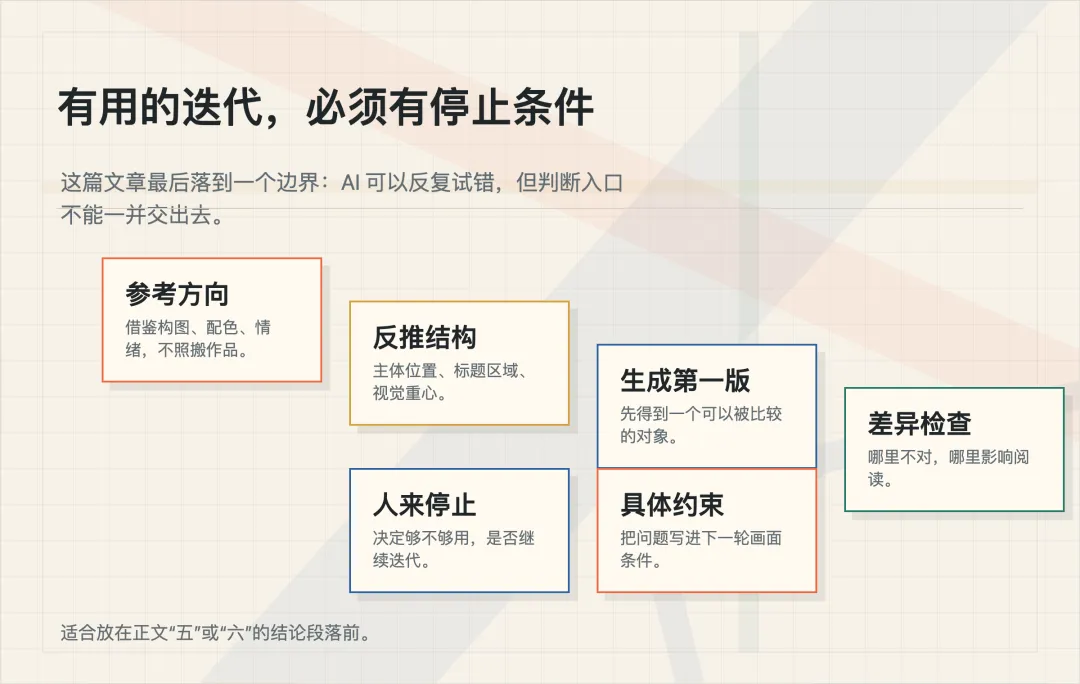
而我接下来真正想补的,是中间那段更细的反馈回路。
比如,先让人选一张参考图。
但这一步不是为了照搬。
而是为了确定视觉方向:
我到底想借鉴它的什么?
是构图,还是配色?
是情绪,还是信息层级?
是人物占比,还是标题区域?
然后让 AI 不只是提取风格词,而是反推结构:
画面比例是多少?
主体在左边还是右边?
文字区域留在哪里?
视觉重心在哪里?
背景是干净的,还是复杂的?
有没有不能被遮挡的区域?
再往后,是生成第一版。
第一版不一定要好。
它的价值,是给后面的比较提供一个对象。
有了第一版,另一个 AI 才能去看:
它和参考方向差在哪里?
它作为公众号封面,哪里会影响阅读?
它和这篇文章的主题有没有偏掉?
下一轮最应该先改哪三件事?
最后,再把这些反馈改成具体约束。
不是写“更高级一点”。
也不是写“更有设计感一点”。
而是写:
左侧保留一块干净的标题区域。
主体只占右侧三分之一。
背景不要太暗。
主体和背景之间要有明确层次。
封面缩小后,主元素仍然能看清。
这些才是可以被执行的约束。
五
写到这里,我反而觉得,这件事最有意思的地方,已经不只是生图了。
它其实是在提醒我:
很多 AI 工作流变好用,不是因为某一次回答特别聪明。
而是因为我们给它设计了反馈回路。
一个负责生成。
一个负责判断。
中间有对比。
有评分。
有约束。
也有停止条件。
这就和单纯“问 AI 要一个答案”不一样了。
如果只让 AI 给答案,我们很容易被它带着走。
它给出什么,我们就从里面挑什么。
但如果先把判断标准放进去,事情会反过来。
AI 生成的东西,开始接受人的标准检验。
它不是替我判断。
它是在我的判断框架里不断试错。
我觉得这个差别很重要。
所以我现在不太想把提示词看成某种神秘咒语。
它当然重要。
但它不是全部。
更重要的,是提示词前后的东西。
前面,是人先判断自己想要什么。
后面,是用反馈把结果一点点推近目标。
这也是为什么,我觉得那个内容生图 Skill 值得继续沉淀下来。
我希望它以后在做公众号封面、文章插图,甚至别的视觉内容时,能更稳定地走向这样一条链路:
先确定参考方向。
再反推结构。
生成第一版。
对比差异。
把差异变成约束。
迭代几轮。
最后由人来决定停在哪里。
不是追求百分百复刻。
也不是把别人的作品照搬过来。
而是学习一张图背后的设计语言,再把它转成适合自己内容的表达。
六
这件事也让我重新理解了“会用 AI”这句话。
会用 AI,不只是知道怎么提问。
也不是收集很多厉害的 prompt。
更重要的是,能不能把自己的判断,放进 AI 的工作流程里。
我以前会把 AI 当成一个很强的生成器。
现在我更愿意把它看成一个可以被组织起来的小系统。
它可以生成、比较、修正,也可以在另一个角色里帮我挑问题。
但前提是,人要先给它一个可以工作的结构,也要知道最后停在哪里。
说到底,我真正想复刻的,可能不是一张封面图。
而是一套让 AI 不断接近目标的流程。
这套流程里,最值钱的也不是那句最终提示词。
而是人有没有把判断、反馈和停止条件放进去。
如果这些东西还在自己手里,AI 就不是替我做决定的人。
它更像一个愿意反复试错的搭档。
而我需要做的,是别把自己的判断入口,也一起交出去。
这篇文章的触发点,来自我看到 Bridge Wang 在 X 上分享的一个逆向文生图提示词案例。这里不展开复述原帖,只记录它给我的启发。
https://x.com/qc777qc/status/2057327056774648108


如果对你有帮助
欢迎点赞、关注、分享呀~
感谢阅读
