 夜雨聆风
夜雨聆风一条请求发给大模型,几秒钟后吐出一段答案。用户看到的是文字,云厂商看到的是账单:GPU 占用、显存占用、网络传输、延迟,还有那串越来越敏感的cost per token。
过去两年,AI 基建最显眼的词是训练集群。谁能买到更多 GPU,谁能把更大的模型训出来,谁就更容易拿到牌桌上的座位。现在,资本的视线开始往另一处挪:推理芯片、推理云、内存带宽、CXL、KV cache。
这个变化,可以从两条融资线索看出来。
一条是 Groq。它在 2025 年 9 月官方宣布完成 7.5 亿美元新融资,投后估值 69 亿美元;到了 2026 年 5 月,TechCrunch 转述 Axios 称,Groq 又在向现有投资人筹集 6.5 亿美元,用来继续推进 inference cloud 业务。
另一条是韩国芯片创业公司 XCENA。TechCrunch 在 5 月 29 日报道,它刚完成 1.35 亿美元融资,赌的方向很直接:AI 最大的卡点,会越来越多地出现在内存。
这两家公司做的事并不一样。Groq 更靠近“怎么把推理跑得更快、更便宜”;XCENA 更靠近“怎么把内存、带宽和数据搬运这件事重新设计”。但它们一起指向了同一个问题:AI 应用真正大规模跑起来以后,瓶颈不只在模型训练,也在每一次调用的成本。
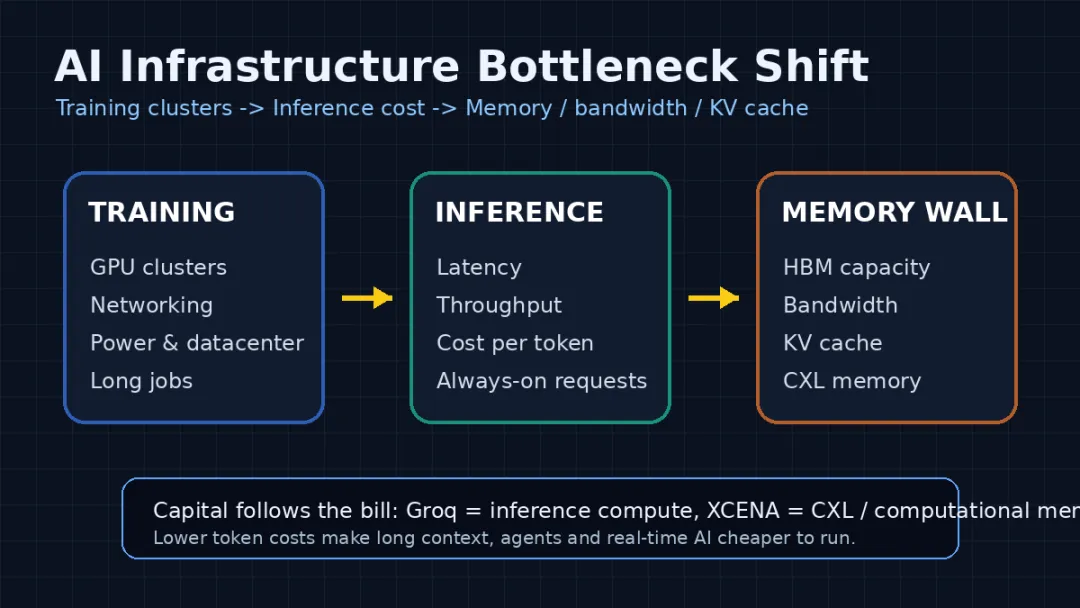
训练烧的是大工程,推理烧的是每一笔小账
训练和推理,听起来都是“跑模型”,但压力点不太一样。
训练更像修一座大坝。它需要长时间占用 GPU 集群,需要高速网络,需要供电、机房、散热和调度。成本很高,但项目是阶段性的:训完一个版本,接着评测、对齐、发布。
推理更像城市里的自来水管。模型上线后,每个用户的每一次提问、每一段语音、每一张图片分析、每一次 Agent 调工具,都会持续消耗算力和内存资源。
这也是 Groq 这类公司的机会。Groq 的 LPU 架构从一开始就强调低延迟推理。它官方新闻稿里把自己定位为 AI inference 基建,并提到其服务已经覆盖超过 200 万开发者和财富 500 强企业。TechCrunch 那篇报道里,Groq 被描述为继续押注 inference neocloud:给开发者和企业托管那些“推理饥渴”的应用。
这里的关键词不是“又一家公司做芯片”。更关键的是,AI 产品从 demo 变成日常工具后,推理会变成一张水电费账单。
一次调用贵一点,普通聊天还能忍;如果是企业客服、代码助手、实时语音、视频理解、后台 Agent,每天调用几十万、几百万次,差距就会被放大。
推理成本为什么绕不开内存
很多人直觉上会以为,AI 慢,就是算力不够。这个说法只对了一半。
大模型推理时,GPU 或专用芯片当然要做矩阵计算,但它还要不断读写模型权重、中间状态和 KV cache。上下文越长、并发越高、多轮对话越多,显存容量和带宽压力越明显。
KV cache 可以简单理解为模型在生成过程中留下的“上下文记忆”。它让模型不用每生成一个新 token 都把前面的内容彻底重算一遍。但代价也很直接:上下文越长,缓存占用越大。一个用户聊长文档还好,一万个用户同时聊长文档,内存压力就会变成系统问题。
NVIDIA H100 官方资料里能看到一组很直观的数字:H100 SXM 形态的显存带宽可到 3TB/s,NVLink 可到 900GB/s,PCIe Gen5 是 128GB/s。它的 FAQ 也把推理 TCO 的核心指标写得很直白:cost per token,也就是实际交付出来的价格性能。
这里的账已经细到了 token 级:每百万 token 花多少钱、每个用户能拿到多少 tokens per second、同样预算能撑住多少并发。
内存的麻烦在于,它既影响速度,也影响成本。数据搬来搬去,芯片再快也会等;显存装不下,就要分页、换卡、拆请求、降低 batch,最后都体现在延迟和账单上。
XCENA 代表的是另一条解法
XCENA 的官网介绍很清楚:它做的是基于 CXL 的智能内存方案,面向 AI、大数据、向量数据库、DNA 分析等大规模数据处理场景。它的产品里有 MX1 CXL Computational Memory,也有配套 SDK,强调让应用在不大改架构的情况下使用 CXL computational memory。
CXL 全称 Compute Express Link,可以把 CPU、加速器和内存设备之间的连接做得更统一。CXL Consortium 官网显示,CXL 4.0 规格把带宽从 64GT/s 提到 128GT/s,并增强了内存 RAS 等能力。
这类技术听起来不如 GPU 型号刺激,但对 AI 推理很要紧。因为推理服务真正跑起来以后,系统里有大量数据要被搬运、缓存、复用、扩展。只靠把计算芯片做得更猛,并不能解决所有问题。
XCENA 这个故事吸引资本的地方,就在这里:它没有讲一个替代 GPU 的故事,而是在尝试把内存变成更主动的计算和调度资源。对长上下文、向量数据库、检索增强生成、企业知识库这类任务来说,内存不再只是被动存东西的仓库。
如果说 Groq 的叙事是“把推理跑得更快”,XCENA 的叙事更像“别让数据在路上堵死”。
成本下降以后,应用才会变得大胆
我觉得推理成本这件事,最容易被低估的地方,是它会改变产品经理的胆子。
当一次调用很贵,产品会变得小心:少给上下文,少开实时能力,少让 Agent 自动跑,最好让用户点一下才触发。
当成本降下来,产品会完全换一种设计方式。
客服可以把更长的历史订单、聊天记录、知识库一起塞进上下文;代码助手可以常驻在工程里,反复读仓库、跑测试、改补丁;语音助手可以一直听、一直理解,不用每次被唤醒后才匆忙启动;企业里的数据分析 Agent 可以在后台慢慢查表、比对、生成报告。
这不是简单的“AI 更聪明”。很多时候,模型能力已经够用,差的是能不能用得起、能不能稳定跑、能不能在延迟上让用户不烦。
所以资本重新看推理芯片和内存,不是因为训练不重要了。训练仍然是大模型公司的入场券。但应用层真正铺开以后,推理会变成每天都要付的房租。
房租降下来,商铺才敢开得更大。
接下来要看整张账单
这轮 AI 基建竞争,很可能会从“谁有最多 GPU”继续走向更细的指标:
每百万 token 成本;
单用户 tokens per second;
长上下文下的 KV cache 管理;
HBM 容量和带宽;
CXL 内存扩展;
多租户调度和利用率;
能耗、散热和数据中心交付速度。
这些指标看起来枯燥,却决定了 AI 应用能不能从“偶尔用一下”变成“全天候挂着”。
Groq 的融资传闻,需要继续按媒体报道看,不能当成官方公告。XCENA 的 1.35 亿美元融资,也要继续关注它后续产品落地和客户验证。芯片创业公司从融资到大规模部署,中间隔着供应链、软件生态、客户迁移成本和数据中心采购周期,不是一轮钱就能跨过去。
但方向已经很清楚:AI 基建的新瓶颈,正在从训练集群外溢到推理系统,再往内存和带宽深处走。
如果后面 AI 应用真的变成长期在线的工作流,最值钱的可能会落到那张没人愿意细看的推理账单上。
谁能把这张账单压下去,谁就能让更多应用从“能演示”走到“敢上线”。
