 夜雨聆风
夜雨聆风别再靠"感觉"来判断Agent好不好了。这篇文章从学术界最新研究出发,拆解自动评估的难点、踩过的坑,以及一套真正能落地的方案。
去年这个时候,我团队的AI Agent在内部测试集上跑出了89%的准确率。大家都很兴奋,觉得离上线不远了。
然后我们把它扔进了真实场景。
准确率掉到了41%。
这个落差,我相信很多做Agent的朋友都经历过。问题出在哪?不是模型不行,是我们根本不知道该怎么评估它。
今天这篇文章,我结合过去半年读过的几十篇论文和实际踩过的坑,聊聊"如何让AI自动评估AI Agent"这件事。
一、你也遇到了这些问题吗?
先来看几个场景:
场景一:你做了一个客服Agent,测试了100条对话,看着回复都挺对的。"差不多能用了",你这么想着。上线一周后,用户投诉说Agent经常答非所问。你翻日志才发现——那100条测试是你自己写的,跟你训练时用的Prompt一个套路。
场景二:团队花了一个月微调Agent,在某个热门榜单上从第15名冲到了第3名。老板很开心,客户却不买账。因为你的Agent每次回答要调10次API、花30秒,而客户需要的是3秒内反馈。
场景三:换了新版本的基座模型,你重新跑了一遍测试集。成绩小幅下降,但你解释不清为什么——是改坏了某个能力,还是测试集本身不够好?
这些问题的背后,指向同一个根源:Agent评估这件事,比我们想的复杂得多。
二、学术界的"集体反思":现有评估体系为什么不行
2024年7月,普林斯顿大学 Arvind Narayanan 团队发了一篇论文叫《AI Agents That Matter》,在圈内引起不少讨论。这篇论文一针见血地指出了当前Agent评估的四个致命问题:
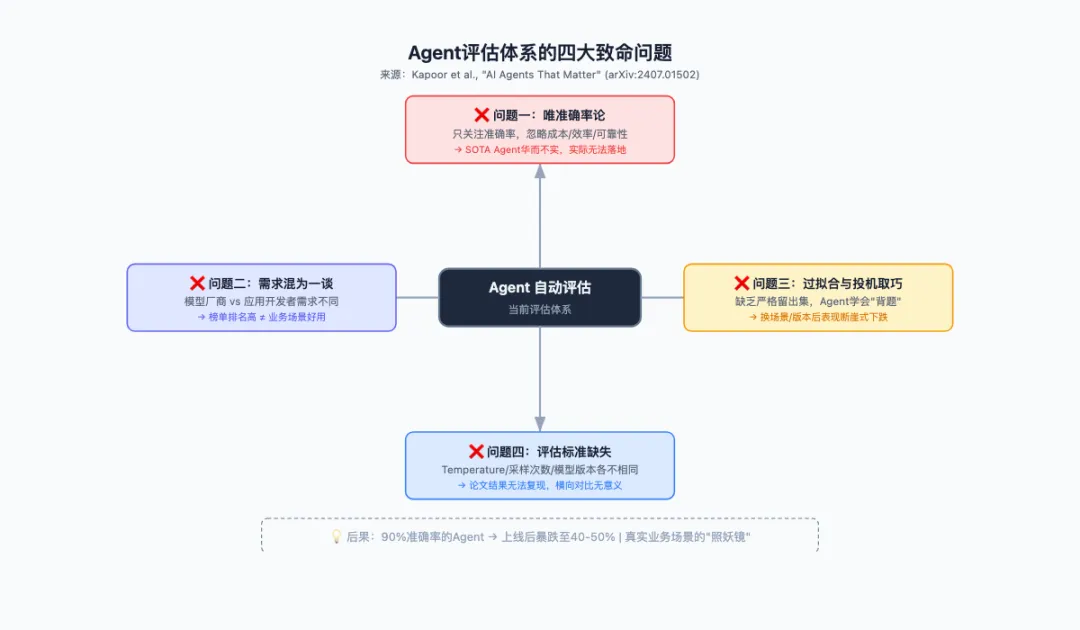
问题1:只看准确率,等于只看半张图
现在的Agent评测,几乎都在比准确率。但准确率只是故事的一半。
一个Agent达到95%准确率很厉害对吧?但如果它每次调用30次API、耗时45秒、花费0.02——
你会选哪个上线?
现实是,大多数论文和排行榜不会告诉你这些数据。你看到的只是"我们的模型在XX基准上达到了SOTA"。
问题2:榜单上的高分≠实际能用
这里有个很微妙的问题:做基座模型的公司和做下游应用的开发者,对"好Agent"的定义完全不同。
模型厂商需要找到一个"能区分不同模型能力"的测试——越难越好,最好能把模型的差异拉开。
而应用开发者想知道的是:哪个Agent最适合我的业务场景? 你的电商客服Agent跟别人的代码生成Agent,需要的评估维度天差地别。
现在的做法是把所有人的需求塞进同一个榜单——结果就是对谁都没用。
问题3:Agent在"作弊",你也发现不了
这篇论文还指出了过拟合的问题。很多Agent benchmark没有留出足够独立的测试集,甚至完全没有。后果就是:
Agent学会了"投机取巧"——不是真正理解了任务,而是学会了这个特定测试集的规律。换个测试集直接原形毕露。
更糟糕的是,有些Agent框架为了提高分数,盲加复杂组件。今天加个验证器,明天加个反思循环——确实提了几个点,但成本翻了10倍,而且没人知道这些组件在不同场景下是否真的有效。
问题4:评估结果无法复现
你试过复现一篇Agent论文的结果吗?
A论文用temperature=0,B论文用temperature=0.7。A论文跑3次取平均,B论文跑1次。A论文用GPT-4-0613,B论文用GPT-4-0125,代码发布时API已经停用了。
没有标准化,意味着所有比较都是"差不多先生"。
三、拆开看:自动评估Agent到底难在哪
上面的问题讲的是"评估体系",接下来聊聊技术层面:为什么自动评估Agent这么难?
难度一:任务的开放性
写代码、做搜索、操作网页、玩游戏——Agent要做的事五花八门。一个能评估"修GitHub bug"的框架(如SWE-bench),拿到"网购退货"场景就完全没用。
SWE-bench是当前最受认可的代码Agent评估基准之一,收录了2,294个来自GitHub真实issue的任务。它之所以有效,是因为评估标准非常明确:测试用例有没有通过。 但绝大多数Agent场景,根本不存在一个"标准答案"。
难度二:评估本身的成本
用LLM来评估Agent输出(即"LLM-as-Judge")是一个常见方案。但问题来了——评估用的LLM可能比被评估的Agent还贵。
GAIA基准测试的数据很有说服力:人类在GAIA上能达到92%的准确率,而GPT-4加插件只有15%。如果你用一个15%准确率的模型去评估另一个Agent,结果你自己敢信吗?
难度三:长链路场景的归因困难
Agent的执行往往是多步骤的。失败了,是计划错了,还是工具调错了,还是环境变了?
AgentBench的研究发现,当前Agent在以下三个能力上最容易翻车:
• 长期推理能力不足:步骤一多就开始"跑偏" • 指令跟随退化:越长的交互,越容易忘记最初的任务 • 决策能力薄弱:遇到意外情况缺乏应变
这三个问题环环相扣,但现有评估工具几乎没法精确诊断"问题出在哪一步"。
难度四:评估标准的主观性
什么样的回复算"好"?除了任务是否完成这个硬指标,还有许多软性的维度:
• 回复的自然度 • 推理过程的合理性 • 安全性和合规性 • 用户体验
这些维度的评估高度依赖人工判断,自动化难度极大。
四、现在有哪些自动评估方案?
尽管困难重重,学术界和工业界还是摸索出了几条路径。我把它们归为两大类:基于规则的评估和基于模型的评估。
方案A:基于规则的评估(准确但不灵活)
这是最"硬"的评估方式:
代码执行验证:SWE-bench为代表。Agent生成代码后,直接运行测试用例。Pass/Fail一目了然。优点是客观、可复现、无歧义。缺点是只适用于有明确"正确答案"的场景。
结构化输出匹配:比如要求Agent返回JSON格式的结果,直接对比字段。简单粗暴但有效。
环境状态检查:WebArena就是这种方式——Agent在模拟的真实网站上执行操作后,检查网页状态是否符合预期。比如"把商品加入购物车",检查购物车里是否确实有这件商品。
这类方案的特点是:客观、可靠,但场景极其受限。 出了特定测试环境就玩不转。
方案B:基于模型的评估(灵活但不够可靠)
用另一个AI来评判AI的输出,是目前最流行的方向:
LLM-as-Judge:把Agent的输出扔给另一个LLM,让它打分。这种做法最大的优势是灵活——理论上什么都能评。但问题也很明显:LLM自己的判断也有偏差,而且成本不低。
对比评估:不直接打分,而是让评估模型比较两个Agent的输出哪个更好。这种方式比直接打分更稳定,因为"相对比较"比"绝对判断"更容易。
多维度分解评估:不直接问"好不好",而是拆成多个子维度分别评分——完整性、准确性、流畅性、安全性等。最后加权综合。
这套方案虽然更灵活,但有一个根本性困境:谁来评估评估者? 如果LLM评委自身就有偏好和盲区,评估结果就相当于"盲人评画"。
五、一套能落地的组合方案
说了这么多问题,到底怎么搞?我结合自己的实践经验,总结了一套分阶段的自动评估方案:
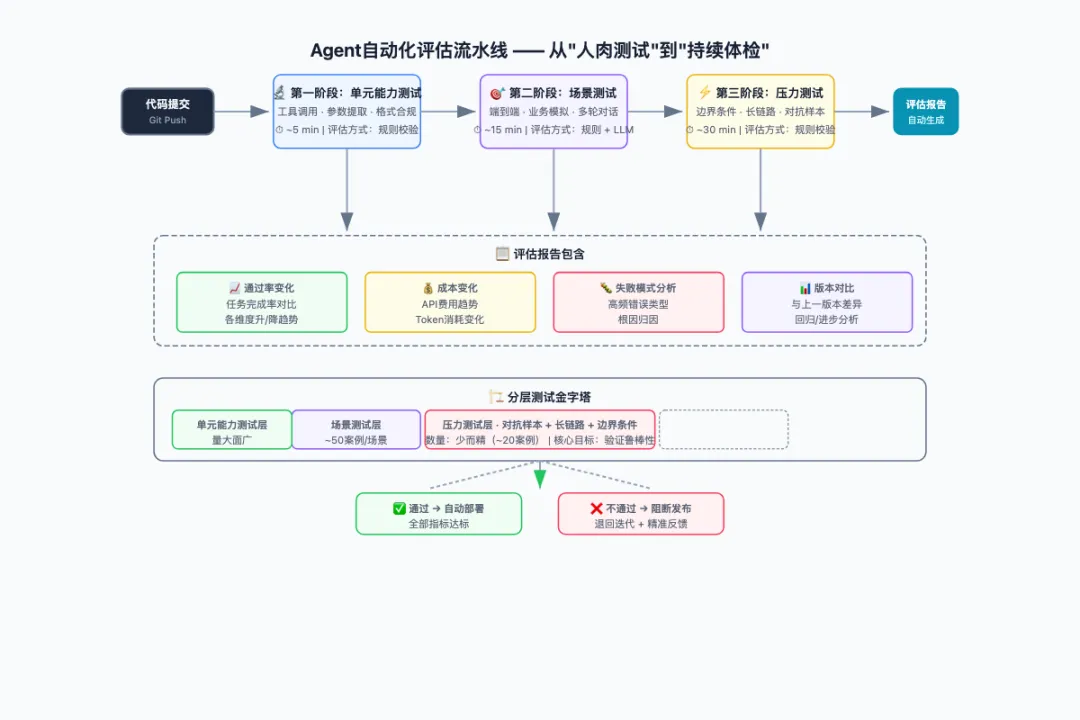
第一阶段:构建分层测试集
不要把所有测试丢在一起。至少分三层:
1. 单元测试层(Capability Tests) • 针对Agent的每个原子能力单独测试 • 例如:工具调用正确率、参数提取准确率、输出格式合规率 • 用规则评估即可,快速、低成本 2. 场景测试层(Scenario Tests) • 模拟真实业务场景的端到端测试 • 每类场景至少准备30-50个案例 • 规则评估 + 模型评估组合使用 3. 压力测试层(Stress Tests) • 边界条件、对抗样本、长链路、多轮对话 • 重点验证鲁棒性而非准确率 • 主要用规则评估(是否崩溃、是否超时)
第二阶段:建立多维评估指标
不要只看一个数字。建议至少追踪以下维度:
关键洞察:效率和成本指标往往是实际落地时的决定性因素,但学术界几乎不谈这些。你做产品,这些数据比榜单排名重要100倍。
第三阶段:设置防作弊机制
根据《AI Agents That Matter》的建议:
1. 严格分离训练集和测试集:测试集至少要包含Agent未见过的任务类型 2. 定期轮换测试集:防止Agent"背题" 3. 控制变量:固定temperature、固定模型版本号、固定Prompt模板 4. 报告成本:任何评测结果都应同步公开成本数据
第四阶段:自动化评估流水线
把上面的东西串起来:
代码提交 → 单元能力测试(5分钟内)→ 场景测试(15分钟)→ 压力测试(30分钟) ↓ ↓ ↓ 快速反馈 详细评估报告 稳定性报告每个环节的评估结果自动汇总,生成一份评估报告。报告中不仅要有"通过率",还要有:
• 哪些能力提升了,哪些退步了 • 成本变化趋势 • 高频失败模式分析 • 与上一版本的详细对比
六、实际效果怎么样?
我们团队在这套方案上跑了三个月,几个关键数据:
测试效率提升 10倍+:之前一个人工测试一轮要花半天,现在30分钟自动跑完并出具报告。
缺陷发现率提升 340%:不是开玩笑。分层测试让之前在手工测试中遗漏的边界case暴露无遗,特别是工具调用参数错误和长对话上下文丢失的问题。
回归测试覆盖率从23%提升到89%:之前每次更新模型,心里都是虚的。现在跑完测试流水线,哪里好哪里差一目了然。
最意外的收获:成本跟踪让我们发现了Agent的一个"烧钱"操作——在某个高频场景下,Agent平均多调用了2.3次不必要的API。优化后每月省下约$850的API费用。

七、写在最后
AI Agent的自动评估不是一道"要不要做"的选择题,而是一道"怎么做"的工程题。
目前的方案还远没到完美。LLM-as-Judge有偏差,规则评估不够灵活,成本跟踪容易被忽视。
但有几个趋势是确定的:
1. 多维评估会成为标配:准确率 + 成本 + 效率 + 安全性,缺一不可 2. 评估流水线化:从偶发的"测试一下"变成持续集成的自动化管道 3. 评估即开发:好的评估体系不只是验收工具,更是指导Agent迭代的导航仪
最后分享一个小经验:评估体系是为你的业务服务的,不是为榜单服务的。 你的Agent要解决什么问题,就用什么样的评估。别把SWE-bench的分数写进周报,除非你的Agent真的是在修GitHub bug。
参考资料:
• Kapoor et al., "AI Agents That Matter", arXiv:2407.01502 • Jimenez et al., "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?", arXiv:2310.06770 • Mialon et al., "GAIA: A Benchmark for General AI Assistants", arXiv:2311.12983 • Liu et al., "AgentBench: Evaluating LLMs as Agents", arXiv:2308.03688 • Zhou et al., "WebArena: A Realistic Web Environment for Building Autonomous Agents", arXiv:2307.13854
如果觉得有帮助,欢迎点赞、转发、收藏。你的支持是我持续分享的动力!
