 夜雨聆风
夜雨聆风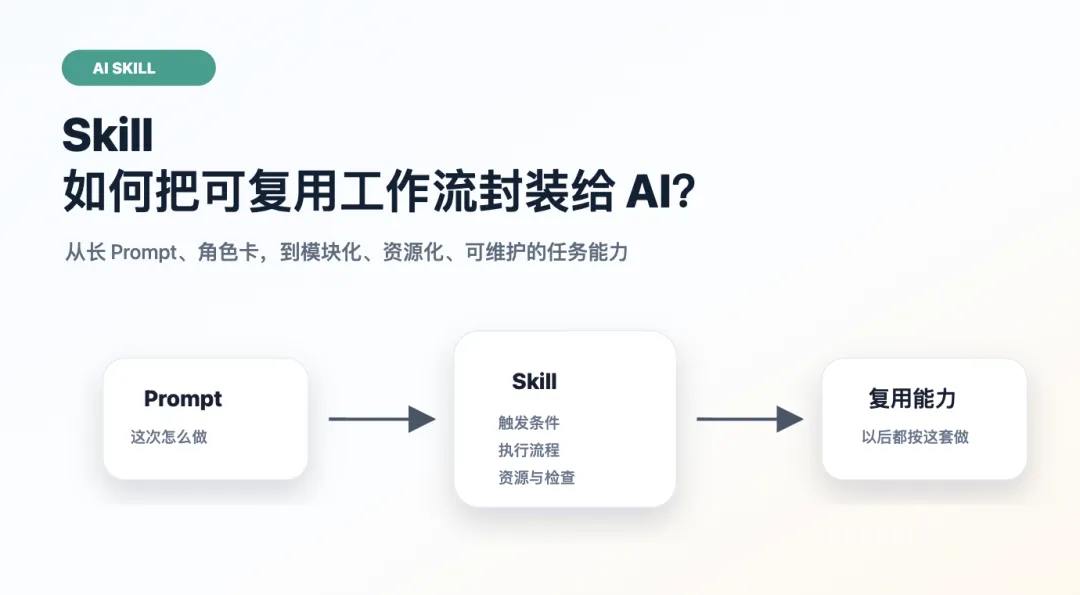
你可能已经有过这种体验:
第一次让 AI 整理技术笔记时,你要告诉它:
先看目录结构。 不要动原始资料。 文章要问题驱动。 标题要编号。 文本流程图要改成真实图片。 练习要放在正文里。 最后检查图片路径和代码块。
第二次让它整理另一篇笔记,你又要讲一遍。
第三次,你发现自己已经在复制粘贴同一大段要求。
这时候就会出现一个很自然的问题:
能不能把这些稳定要求封装起来,下次直接复用?
这就是 Skill 想解决的问题。
Skill 可以理解为:
一种把稳定工作流、执行标准、可用资源和检查清单打包起来的 AI 能力模块。
它不是模型训练,也不是模型参数发生了变化。它更像是把“我希望 AI 怎么做这类任务”写成一份可复用的工作说明书。
1. 为什么会出现 Skill?
大模型很擅长根据上下文完成任务,但它有一个天然问题:如果你不把标准说清楚,它就会按自己的默认理解来做。
比如你说:
帮我把这篇笔记整理一下。这句话太宽了。
AI 可能会:
写成摘要。 写成提纲。 写成知识卡片。 改写成教程。 新建一堆辅助文件。 忘记检查图片路径。
它不是完全不会做,而是不知道你真正想要的“整理”是什么。
如果你每次都写一个超长 Prompt,当然可以改善结果。但长 Prompt 用久了会有三个麻烦:
重复:每次都要复制一遍。 遗漏:内容太长时,模型可能忽略某些要求。 难维护:标准变化后,旧 Prompt 到处散落,不知道该改哪一份。
Skill 的出现,就是为了把这类稳定、重复、可检查的任务要求沉淀下来。
所以,Skill 不是为了替代 Prompt,而是为了解决 Prompt 重复、松散、难维护的问题。
一句话:
Prompt 更像“这次怎么做”,Skill 更像“这类任务以后都按这套方法做”。
2. Skill 和 Prompt 到底有什么区别?
很多人第一次听 Skill,会觉得:
这不就是一个更长、更复杂的 Prompt 吗?
这个理解有一半是对的。
因为 Skill 的核心确实也是文字说明。它也会告诉 AI:
什么任务要做。 按什么步骤做。 输出成什么样。 遇到什么情况要注意。
但如果只把 Skill 理解成“更长的 Prompt”,就会漏掉它最重要的部分:模块化和可维护性。
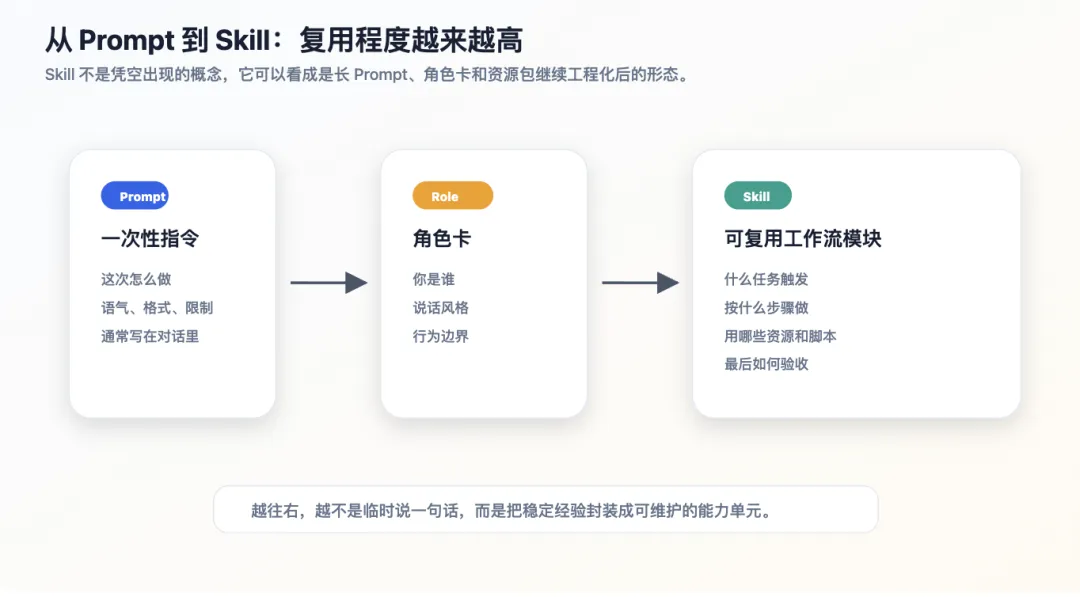
2.1 Prompt 是一次性指令
Prompt 通常存在于一次对话里。
比如:
请用通俗语言解释这段代码,并给出三个例子。它适合表达当前任务的临时要求。
如果任务结束了,这段 Prompt 也就结束了。
当然,你可以把常用 Prompt 保存下来,但它本质上仍然是一段文本片段,需要你每次主动复制、修改、粘贴。
2.2 Skill 是可复用工作流
Skill 不只是告诉 AI “这次怎么回答”,而是定义一类任务的处理方式。
比如技术博客 Skill 可以规定:
先读取原文和目录结构。 找文章的中心问题。 不要先罗列知识点。 发现流程和架构时要画图。 标题要编号。 练习要能验证前文知识。 最后检查图片路径、SVG、代码块和编号。
这已经不是一句提示词了。
它更像一个可复用流程。
2.3 二者的核心差异
所以,Skill 可以看成 Prompt 的工程化升级。
但它不是简单变长,而是从“文本指令”变成了“任务模块”。
3. Skill 和角色卡有什么区别?
你提到一个很好的类比:以前 ChatGPT 或其他 AI 工具里,经常有“角色卡”。
比如:
你是一名资深 Python 工程师。你说话简洁,擅长解释复杂技术。你会先指出问题,再给出代码。这种角色定义确实和 Skill 有点像。
它们都在给 AI 增加一段稳定上下文。
但它们的关注点不同。

3.1 角色卡解决“你是谁”
角色卡更关注身份、风格和行为边界。
它回答的是:
你扮演什么角色? 你说话是什么风格? 你面对问题时有什么习惯? 你不能做什么?
比如:
你是一名严谨的代码审查者。你优先指出 bug 和风险。你不要过度夸奖。这类内容会影响 AI 的整体表现。
但它不一定告诉 AI 某个具体任务的完整流程。
3.2 Skill 解决“这类任务怎么做”
Skill 更关注任务流程。
它回答的是:
什么情况下使用这个能力? 接到任务后第一步做什么? 中间如何判断? 需要使用哪些资源? 输出应该是什么结构? 最后如何检查质量?
比如:
当用户要求把技术笔记改成技术博客时:1. 先读取原文。2. 找出中心问题。3. 检查逻辑断层。4. 重写正文。5. 为流程补图。6. 添加练习。7. 验证图片路径和代码块。这就不是简单的人设,而是一套执行方法。
3.3 角色卡和 Skill 可以同时存在
二者不是互斥关系。
一个 AI 可以同时有:
角色卡:规定它像什么样的人。 Skill:规定它如何完成某类任务。
比如:
角色卡:你是一名耐心、严谨、善于教学的技术作者。Skill:当你改写技术笔记时,必须使用问题驱动结构、配图和练习闭环。角色卡更像“人格和风格”。
Skill 更像“方法和流程”。
所以你说“角色定义感觉和 Skills 很像”,这个感觉是对的。
它们确实都属于“给 AI 稳定上下文”的方式。
区别在于:
角色卡偏身份设定,Skill 偏任务封装。
4. 一个 Skill 通常包含什么?
最小的 Skill 通常有一个核心说明文件,比如 SKILL.md。
复杂一点的 Skill 还可以附带参考资料、模板、图片、字体、代码脚本等资源。

可以把 Skill 拆成四部分。
4.1 元信息:让它能被找到
元信息通常包括:
name:Skill 的名字。description:它适合什么任务。
比如:
---name:technical-blog-transformerdescription:Transformtechnicalnotesintonumbered,diagram-richeducationalblogarticleswithexamplesandpracticeexercises.---这里最重要的是 description。
它不是普通简介,而是触发条件。
一个糟糕的描述:
description:Askillforwriting.太宽了。
它没有说清楚:
写什么? 输入是什么? 输出是什么? 什么场景应该用?
一个更好的描述:
description:Transformtechnicalnotes,rawdocumentation,orimportedknowledge-basematerialintoanumbered,diagram-richeducationalblogarticlewithexamples,pitfalls,andpracticeexercises.它更像一个清楚的入口:
当任务是“把技术材料改写成图文并茂的学习文章”时,就该考虑这个 Skill。
4.2 工作流:让它知道怎么做
这是 Skill 最核心的部分。
它不应该只写空泛原则:
写得专业一点。逻辑清晰一点。内容丰富一点。这种话很难执行。
更好的写法是步骤化:
1. 先读取目标文档。2. 判断文章中心问题。3. 找出逻辑断层。4. 重写正文结构。5. 遇到流程、架构、映射关系时生成图。6. 给标题编号。7. 添加练习和验收标准。8. 检查图片路径和代码块闭合。好 Skill 的核心不是“说得漂亮”,而是“能指导行动”。
4.3 资源:让它不仅会说,还能做
这也是 Skill 和长 Prompt 的重要差别。
Skill 可以携带资源。
比如:
references/ | ||
assets/ | ||
scripts/ |
如果只有 Prompt,你通常只能告诉 AI:
请按照我们的写作规范来写。但如果 Skill 附带了写作规范文件,它就可以在需要时读取规范。
如果 Skill 附带脚本,它甚至可以执行某些确定性步骤。
这就让 Skill 不只是“更长的提示词”,而是带有资源和工具的任务模块。
4.4 检查清单:让输出更稳定
Skill 最容易提升质量的地方,是检查项。
比如技术博客 Skill 可以要求:
是否有中心问题? 是否有逻辑断层? 是否还存在文本流程图? 图片路径是否有效? 标题编号是否连续? 练习是否能验证前文知识?
检查项的价值在于,它把“好不好”变成了“能不能验收”。
没有检查项时,AI 可能写完就停。
有检查项时,它会更倾向于回头检查结果。
5. Skill 是怎么被使用的?
Skill 通常不会一开始就把所有内容全部塞进上下文。
因为如果所有 Skill 都完整加载,上下文很快就会被无关信息挤满。
更合理的方式是渐进式加载。
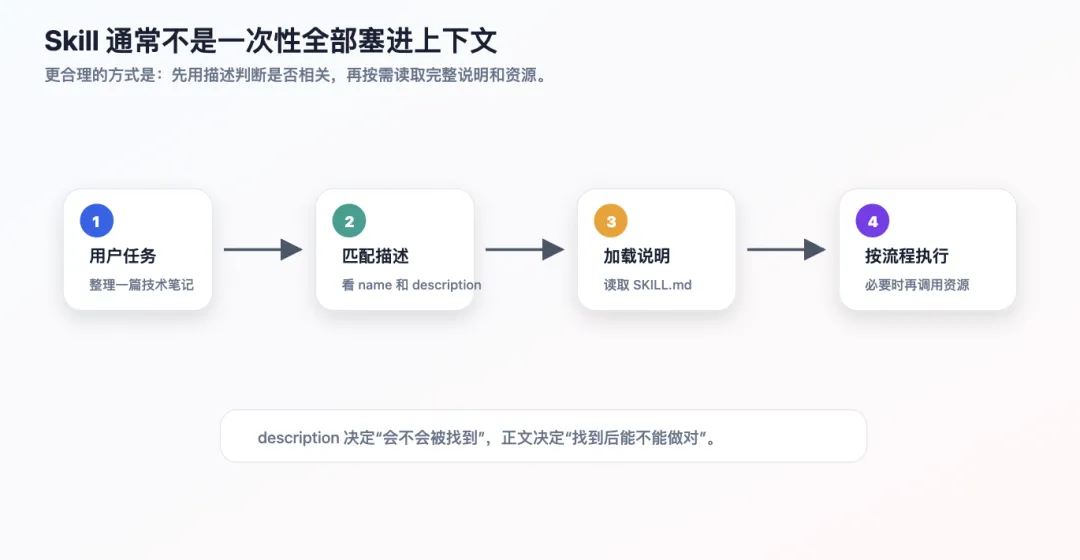
可以理解成四步。
5.1 第一步:用户提出任务
比如:
把这篇并发笔记改写成技术博客。这个请求没有把完整流程写出来。
5.2 第二步:系统根据描述判断是否相关
系统会先看可用 Skill 的名字和描述。
如果有一个 Skill 描述中写着:
Transform technical notes into diagram-rich educational blog articles...它就很可能与当前任务相关。
5.3 第三步:读取 Skill 正文
匹配上以后,才读取 Skill 的完整说明。
这一步会得到:
执行流程。 输出标准。 资源位置。 检查清单。
5.4 第四步:按流程执行
最后,根据 Skill 去完成任务。
比如:
读取原文。 找中心问题。 补逻辑断层。 重写正文。 生成图。 检查路径。
所以 Skill 的使用过程不是神秘机制。
它就是:
先用短描述判断要不要用,再按需加载详细说明和资源。
6. Skill 像不像面向对象?
你的这个类比很有启发。
Skill 确实有点像面向对象。
当然,它不是严格意义上的代码类,但它和面向对象有相似的封装思想。
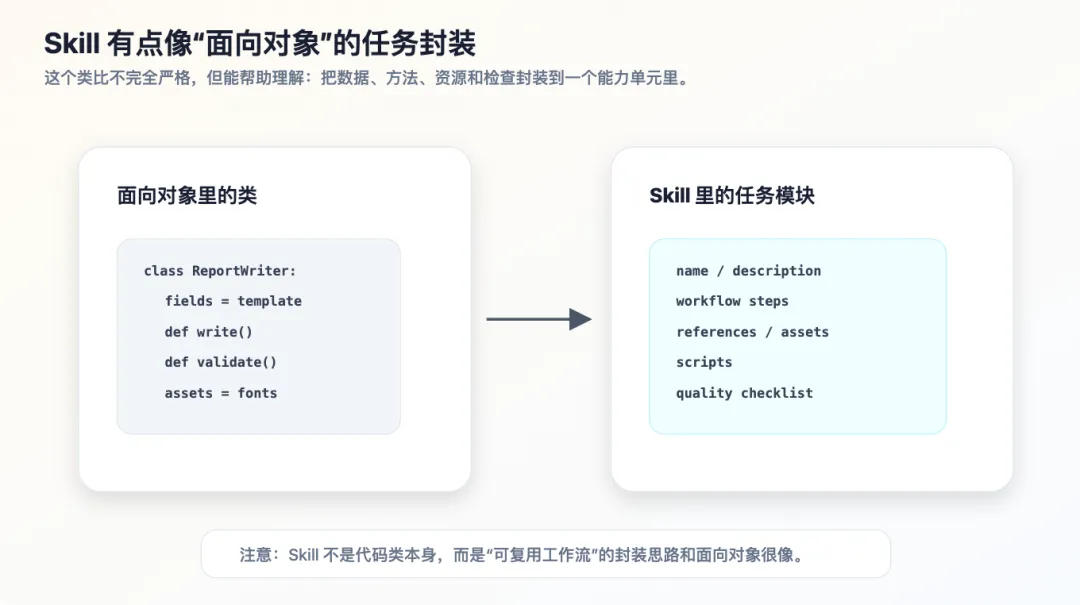
6.1 类把数据和方法封装在一起
在面向对象里,一个类可能包含:
属性。 方法。 初始化规则。 内部约束。
比如:
classReportWriter: template = "report.docx"defwrite(self, data): ...defvalidate(self, report): ...这个类不是某一次具体报告,而是一类报告写作能力的封装。
6.2 Skill 把任务经验封装在一起
Skill 也类似。
它可能包含:
触发条件。 执行流程。 参考资料。 模板资源。 可执行脚本。 质量检查。
比如:
technical-blog-transformer description: 技术笔记 -> 技术博客 workflow: 阅读、分析、重写、配图、练习、检查 resources: 写作规范、示例文章 scripts: 图片检查、Markdown 检查 checklist: 是否有中心问题、是否有图、是否有练习它也不是某一次具体输出,而是一类任务能力的封装。
6.3 这个类比哪里成立?
成立的地方在于:
都在做封装。 都把相关信息放在一起。 都提高复用性。 都减少重复书写。 都让复杂任务有明确边界。
所以你可以把 Skill 理解为:
面向 AI 任务的“工作流对象”。
6.4 这个类比哪里不成立?
也要注意,它不是严格的代码对象。
Skill 通常不会像类一样被实例化、继承、多态调用。
它更像:
一份任务说明书。 一个资源包。 一套执行规范。 一个可复用能力单元。
所以“像面向对象”可以帮助理解,但不要过度类比。
更准确的说法是:
Skill 借用了类似封装的思想,把一类任务的做法收拢到一个模块里。
7. Skill 是复杂 Prompt 的封装吗?
可以这么说,但要补充一句:
Skill 是复杂 Prompt 的模块化、资源化、可维护版本。
如果一个 Skill 只有 SKILL.md,没有脚本、没有资源,那它确实很像一个结构化长 Prompt。
但即使如此,它也比普通 Prompt 多了几个特点:
有稳定名字。 有触发描述。 有集中维护位置。 有固定结构。 有检查标准。
如果再加上资源和脚本,它就明显超过普通 Prompt。
比如:
普通 Prompt:请帮我生成一份报告,风格专业。Skill:当用户要求生成报告时:1. 读取数据表。2. 使用指定报告模板。3. 调用脚本生成图表。4. 按公司写作规范组织结论。5. 渲染文档并检查版式。这时 Skill 已经不是“更长”而已。
它变成了一个带流程、资源和执行能力的任务包。
所以可以分三层理解:
短 Prompt:告诉 AI 这次做什么。 长 Prompt / 角色卡:告诉 AI 长期怎么表现。 Skill:告诉 AI 一类任务如何稳定完成,并能携带资源和工具。
8. 什么内容适合做成 Skill?
不是所有要求都适合做成 Skill。
Skill 适合这类任务:
经常重复。 步骤稳定。 质量有标准。 需要检查。 可能需要资源或脚本。
比如:
技术笔记改写。 代码审查。 论文精读。 文档生成。 表格分析。 PPT 制作。 知识库整理。
这些任务都有一个共同点:
不是只问一个问题,而是要按一套方法完成一个工作。
8.1 不适合做成 Skill 的情况
下面这些通常不需要 Skill:
只做一次的临时任务。 简单事实查询。 用户偏好还不稳定。 每次流程都完全不同。 只是单句润色。
比如:
帮我解释一下这个词。这不需要 Skill。
但如果你长期要求:
所有技术术语都要按“概念、例子、误区、练习”的结构解释。这就可以考虑做成 Skill。
9. 一个好 Skill 应该怎么写?
一个好 Skill 不是越长越好。
它要让 AI 在真正执行任务时少犯错。
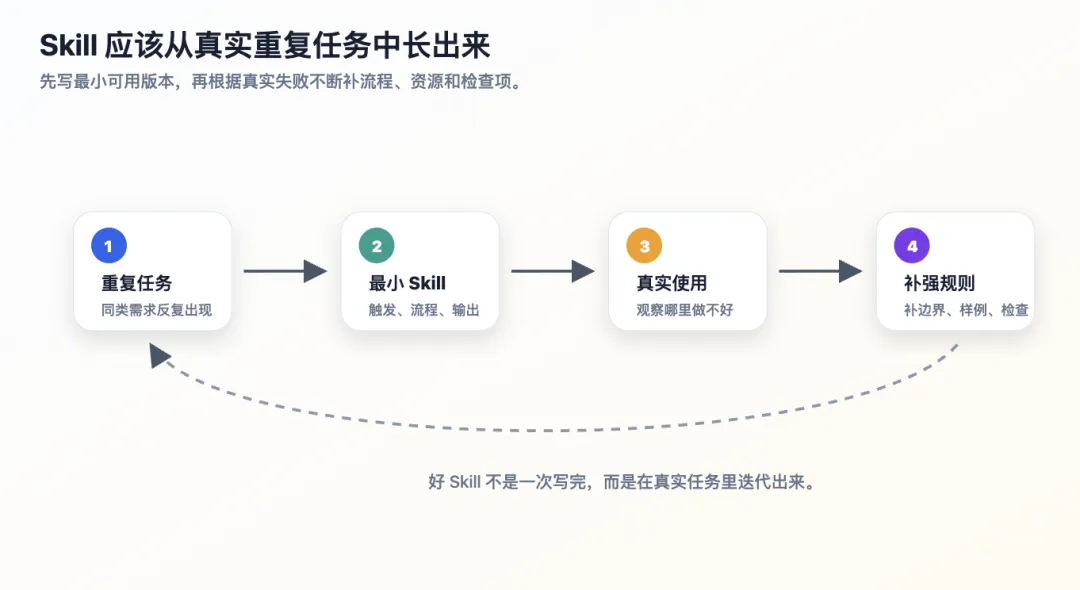
9.1 从真实重复任务开始
不要凭空设计 Skill。
最好的来源是你已经重复做过多次的任务。
比如这次我们沉淀技术博客 Skill,就是因为你连续多次反馈:
不要新建冗余知识卡。 要优化原文。 文章要有深度。 要用图解释。 标题要编号。 练习要形成学练闭环。 不能只套形式,要补逻辑断层。
这些反馈积累起来,就自然变成 Skill。
9.2 description 要像入口,不要像广告
坏的描述:
description:Helpswithwriting.这个描述太泛。
好的描述应该说清:
输入是什么。 输出是什么。 什么场景使用。 有什么关键质量标准。
例如:
description:Transformtechnicalnotesorrawdocumentationintonumbered,diagram-richeducationalblogarticleswithconcreteexamples,pitfalls,andpracticeexercises.它不是在夸自己,而是在告诉系统:
什么任务该用我。
9.3 工作流要可执行
不要只写:
写得更好。内容更完整。逻辑更清晰。这类要求太虚。
要写成动作:
1. 先读源文档。2. 找中心问题。3. 找逻辑断层。4. 重写缺失解释。5. 生成关键图。6. 加练习。7. 检查路径和格式。9.4 检查项要能判断对错
检查项不要写:
质量要高。表达要好。这没法验收。
更好的检查项:
是否还有文本流程图?图片链接是否能打开?标题编号是否连续?是否先解释概念再使用 API?练习是否能验证前文知识?Skill 质量提升,往往就来自这些具体检查项。
10. Skill 的常见误区
10.1 误区一:Skill 会让模型真正学会新知识
不会。
Skill 不等于训练模型。
它不会改变模型参数。
它只是给模型提供一套可复用上下文、资源和执行规范。
更像是:
不是把知识刻进大脑,而是把操作手册放到手边。
10.2 误区二:Skill 越大越好
不是。
Skill 太大,会变成杂货铺。
一个好 Skill 应该围绕一类任务。
比如:
技术博客写作 Skill。 代码审查 Skill。 论文精读 Skill。 表格分析 Skill。
不要把所有规则都塞进一个万能 Skill。
10.3 误区三:Skill 只是角色卡
不是。
角色卡偏“你是谁”。
Skill 偏“这类任务怎么做”。
如果一个 Skill 只有身份设定和语气要求,那它更像角色卡,不像真正的 Skill。
10.4 误区四:Skill 只是长 Prompt
也不完全是。
没有资源和脚本的 Skill,确实像结构化长 Prompt。
但它仍然有模块化、触发描述、集中维护和检查清单。
带资源和脚本后,它就更接近一个可复用任务包。
11. 实战练习
11.1 练习一:把重复 Prompt 改造成 Skill
目标:理解什么内容适合沉淀成 Skill。
任务:
找一段你复制过三次以上的 Prompt。 标出其中哪些是临时要求,哪些是长期规则。 把长期规则整理成 description、工作流和检查项。
验收标准:
description能说明什么时候触发。工作流至少有 5 个可执行步骤。 检查项能判断输出是否合格。
复盘问题:
哪些内容应该继续留在 Prompt? 哪些内容应该放进 Skill? 这个 Skill 是否只解决一类任务?
11.2 练习二:区分角色卡和 Skill
目标:理解“身份设定”和“任务流程”的区别。
任务:写两段内容。
第一段是角色卡:
你是谁?你说话风格是什么?你有哪些行为边界?第二段是 Skill:
什么任务触发?先做什么?中间怎么判断?输出什么?最后检查什么?验收标准:
角色卡不写具体任务流程。 Skill 不只写身份和语气。 二者可以配合,但职责不混。
复盘问题:
如果只有角色卡,会缺什么? 如果只有 Skill,会缺什么? 哪些内容最容易被误放?
11.3 练习三:用面向对象方式理解 Skill
目标:建立 Skill 的封装思维。
任务:选一个任务,例如“论文精读”,写出:
Skill 的名字。 Skill 的触发条件。 Skill 的工作流。 Skill 需要的资源。 Skill 的检查项。
验收标准:
能说明它封装的是哪一类任务。 能说明哪些内容类似“方法”。 能说明哪些内容类似“资源属性”。
复盘问题:
这个 Skill 是否足够聚焦? 有没有把多个不相关任务混在一起? 哪一步最需要后续迭代?
12. 总结
Skill 的本质不是模型学会了新知识,而是:
把一类任务的稳定经验、流程、资源和验收标准,封装成可复用的 AI 能力模块。
它和 Prompt、角色卡的关系可以这样记:
Prompt:这次怎么做。 角色卡:你像谁一样做。 Skill:这类任务以后按什么方法做。
它确实有点像复杂 Prompt 的封装。
但更准确地说:
Skill 是复杂 Prompt 的模块化、资源化、可维护版本。
它也有点像面向对象。
因为它把任务名称、触发条件、执行方法、资源和检查项封装到同一个能力单元里。
不过它不是严格的代码对象,而是面向 AI 任务的工作流封装。
如果你不知道某段要求该不该做成 Skill,就问一个问题:
这是不是一个稳定、重复、有标准、需要检查的任务?
如果答案是是,它就很适合被沉淀成 Skill。
13. 参考
OpenAI Help:Skills in ChatGPT OpenAI Academy:Using skills
