 夜雨聆风
夜雨聆风鲁迅先生说,科研创新平台是个好东西,值得我好好研究,然后分享给你们。
你的研究所,是不是这样?
- • 花了几百万买了大模型一体机,科研人员还是用 Word 写报告
- • 数据存了几十个 TB,但每个课题组各自为政,数据“孤岛”比太平洋还大
- • 采购了各种 AI 工具,但没人用、不会用、不想用
- • 领导问“AI 赋能科研的成果在哪”,你只能拿出几个 PPT
这不是你的问题。这是整个科研行业的问题。
问题的根源在于:我们把 AI 当成“工具”来买,而不是当成“能力”来建。
2026 年,斯坦福大学《AI 指数报告》显示,各自然科学领域提及 AI 的论文比例已达 6%-9%,超 8 万篇学术论文涉及 AI。但报告同时指出——“经实验证实的 AI 科研发现仍寥寥无几”。
AI 喊得响,落地却难。问题出在哪?
二、破局:从“三层架构”看 AI 原生化平台
先看一张架构图:
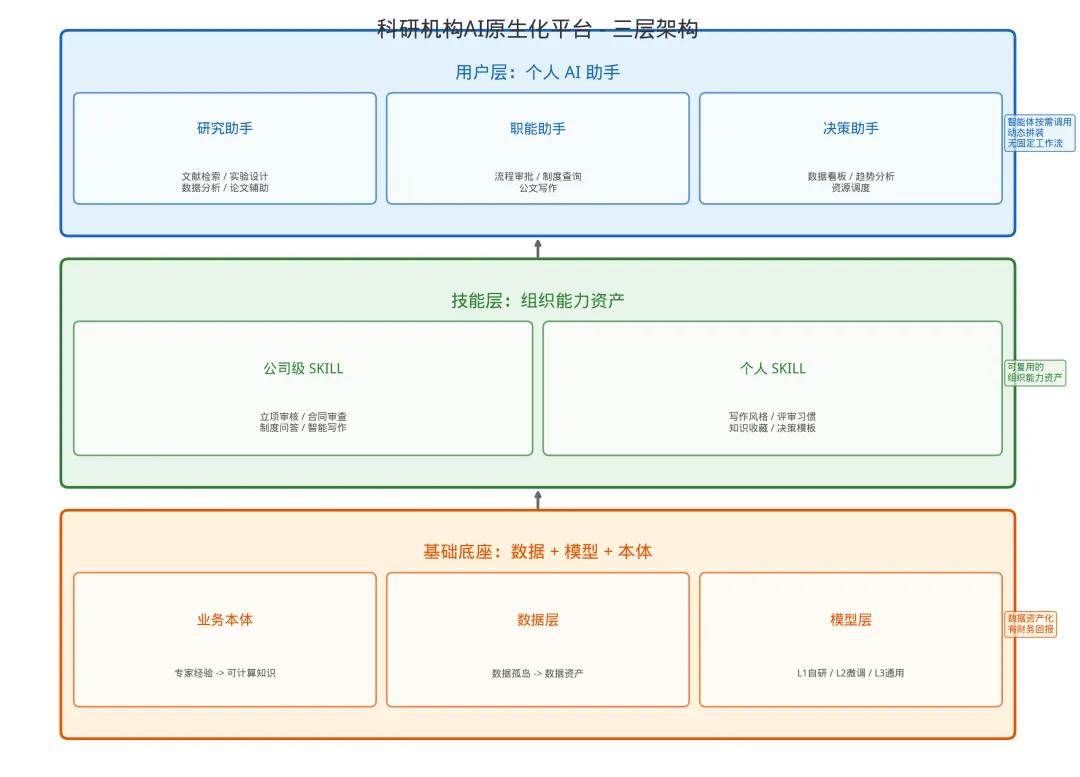
这套架构的核心思想是“本体 + 技能”双轮驱动——员工配个人助手,组织沉淀可复用技能,数据资产化有实打实的财务回报。
下面逐层拆解。
三、第一层:基础底座——数据资产化是前提
很多科研机构一上来就谈“大模型”,却忽略了最基础的数据工作。
数据不是成本,是资产。
某大型科研机构的数据资产入表试点显示:1151 万元数据资产,直接增利 511 万元。这不是画饼,是实打实的财务回报。
科研机构的数据底座建设,需要做好三件事:
1. 业务本体:把“专家经验”变成“可计算的知识”
科研机构最大的财富不是设备,不是论文,而是专家脑子里那些“只可意会不可言传”的经验。
- • 项目评审规则
- • 实验操作规范
- • 论文审稿标准
- • 成果转化流程
这些经验需要被结构化、数字化,形成业务本体——一个网状关联的知识体系,把专家智慧、管理规则、科研项目、知识库、数据资产全部串联起来。
2. 数据层:从“数据孤岛”到“数据资产”
- • 建立统一的数据目录和标准
- • 打通各课题组的“数据烟囱”
- • 实现“群 + 表+会”过程沉淀——数据来自日常业务流,不是额外采集
- • 推进数据资产入表,让数据变成可量化的资产
3. 模型层:三层模型策略
不要追求“一个模型打天下”。成熟的策略是三层组合:
| 层级 | 定位 | 选型建议 |
|---|---|---|
| L1 自研组件 | 特定场景专用 | OCR、智能路由、格式转换 |
| L2 行业微调 | 科研领域专精 | 基于开源模型 LoRA 微调 |
| L3 通用底座 | 基础能力支撑 | DeepSeek/Qwen/Kimi等 |
核心原则:通用模型做基座,行业微调做专精,自研组件做补位。
四、第二层:技能层——这才是真正的“组织能力”
很多科研机构建了 AI 平台,结果就是“一个聊天机器人”。
真正拉开差距的,是“技能层”。
什么是“技能”?
技能不是功能,不是 API 接口,而是可复用的组织能力资产。
打个比方:
- • 功能 = 给你一把锤子
- • 技能 = 教会你钉钉子,并且能反复用
公司级 SKILL(组织能力资产)
科研机构可以沉淀的典型技能包括:
| 技能类型 | 具体示例 | 价值点 |
|---|---|---|
| 项目管理 | 立项审核、进度追踪、结题验收 | 标准化流程,减少人工 |
| 知识管理 | 制度问答、智能写作、能力图谱 | 知识不流失,新人快速上手 |
| 合规风控 | 合同审查、资金审核、内审 | 降低风险,提升合规性 |
| 数据治理 | 数据资产盘点、质量稽核 | 数据可用、可控、可管 |
个人 SKILL(个体经验资产)
每个科研人员都有自己的“独门绝技”:
- • 写作风格
- • 评审习惯
- • 知识收藏体系
- • 决策模板
这些个人经验可以被 AI 学习、沉淀、复用,变成组织的数字资产。
公司级 + 个人级分离设计,既保效率又保隐私——这是这套架构最聪明的地方。
五、第三层:用户层——每个角色配一个 AI 助手
底座建好了,技能沉淀了,最后一步是让每个人都能用上。
三类核心助手
| 角色 | 助手 | 核心能力 |
|---|---|---|
| 科研人员 | 研究助手 | 文献检索、实验设计、数据分析、论文辅助 |
| 职能人员 | 职能助手 | 流程审批、制度查询、公文写作 |
| 管理层 | 决策助手 | 数据看板、趋势分析、资源调度 |
关键设计理念
智能体按需调用、动态拼装、无固定工作流
- • 不是给每个人装一个“固定 App”
- • 而是让 AI 助手根据任务需求,自动调用合适的技能
- • 科研人员说“帮我查一下这个方向的最近进展”,AI 自动检索文献、提取要点、生成综述
六、科研机构落地的三个关键动作
动作一:选对切入点
不要一上来就想“全平台覆盖”。建议从高频、低风险、价值显性的场景切入:
- 1. 科研文献助手:文献检索 + 摘要 + 综述生成(最容易见效)
- 2. 项目管理助手:立项审核 + 进度追踪 + 结题报告(管理价值高)
- 3. 制度问答助手:让新人快速了解所内制度(用户感知强)
动作二:建立“技能工厂”机制
- • 每个季度评选“最佳技能”
- • 鼓励科研人员把自己的工作流“技能化”
- • 建立技能质量评估标准
- • 技能可以跨课题组复用
动作三:数据资产化从小处着手
- • 选一个数据基础好的课题组做试点
- • 完成数据盘点→标准化→入表的全流程
- • 用数据说话:资产增值了多少?效率提升了多少?
七、避坑指南
❌ 常见错误
- 1. 重硬件轻软件:花大钱买算力,舍不得投数据治理
- 2. 重建设轻运营:平台建完没人管,半年后成摆设
- 3. 重技术轻业务:技术团队闭门造车,科研人员不买账
- 4. 追求大而全:一上来就想做“全平台”,结果哪个都没做好
✅ 正确姿势
- 1. 先治数据,再上模型——数据质量决定 AI 效果的上限
- 2. 先做技能,再做平台——技能是内容,平台是容器
- 3. 先让一部分人用起来——培养种子用户,用口碑带动推广
- 4. 先算账,再投入——每个 AI 项目都要有明确的 ROI 预期
八、写在最后
2026 年,AI 已经从“技术突破”阶段全面迈入“系统落地”阶段。
对于科研机构来说,AI 不是锦上添花的工具,而是重塑科研范式的核心引擎。
斯坦福的报告说“AI 科研发现仍寥寥无几”,但换个角度看——正因为大家都还在起跑线上,现在入场,就是先发优势。
建 AI 平台不是买一套软件,而是构建一个让 AI 能力持续生长、持续沉淀、持续复用的系统。
“本体 + 技能”双轮驱动,员工配个人助手,组织沉淀可复用技能,数据资产化有财务回报——这条路,已经有先行者走通了。
你的研究所,准备好了吗?
本文基于多个科研机构与大型企业的 AI 原生化平台建设实践总结而成。数据来源包括中国信通院《智能原生研究报告(2026 年)》、斯坦福大学《2026 年 AI 指数报告》、国家数据局国有企业数据效能提升行动公开信息等。
