 夜雨聆风
夜雨聆风AI 工具 · 免费开放
你花顶配的钱,买到的可能是低配的模型
我做了个工具来验证这件事
这是一个免费工具,用来测试你接入的 AI 模型到不到位、有没有被调包。今天正式上线,顺利完成国内备案,分享给有需要的人。
你选了一个模型,付了钱,开始用。但你调用的,真的是你以为的那个模型吗?
服务商给你提供的接口,标注的是 GPT-4o 或者 Claude Opus,但实际跑在背后的,可能是某个更便宜的模型,甚至是经过"改造"的版本。这种情况在第三方 API 渠道里并不罕见——他们的成本压力摆在那里,而用户几乎没有辨别能力。
大多数人只能靠感觉。觉得回答质量变差了,猜测是不是被换了模型,但没有办法证实。这个问题困扰了我很久,直到我决定自己做个工具来解决它。
工具介绍
这个工具能做什么
简单说:它会对你接入的模型跑一套测试,告诉你这个模型是真是假、稳不稳、有没有被动过手脚。
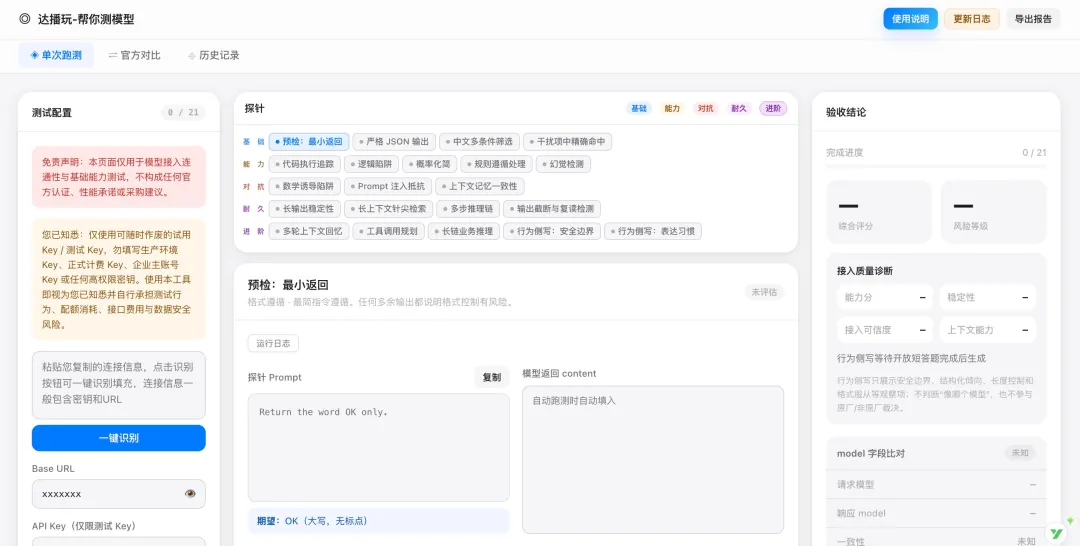
整个工具分三个区域:
操作步骤
三步完成测试
填入你的 API 信息
把你的 API 地址和 Key 粘贴进去。如果觉得麻烦,可以直接把所有信息一次性丢进识别框,点「一键识别」,工具会自动帮你解析填好。


填入你想测试的模型名称
直接复制你的服务商提供的模型名,粘贴进来。
点击「一键跑测」,等待 1-2 分钟
剩下的交给工具。它会自动跑完 18 道探针测试,从五个维度评估这个模型:真实性、稳定性、是否被篡改、接口一致性、综合可用性。
测试结果
你会得到什么
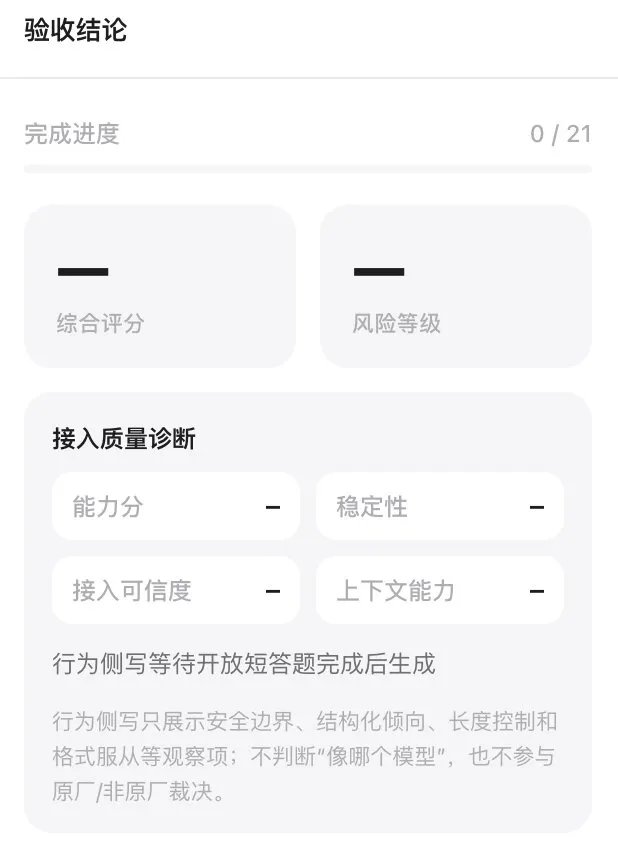
真实测试
结果比我预想的更有意思
工具上线前,我用它测试了几个主流模型,有几个发现值得分享。
千问 3.6 Plus
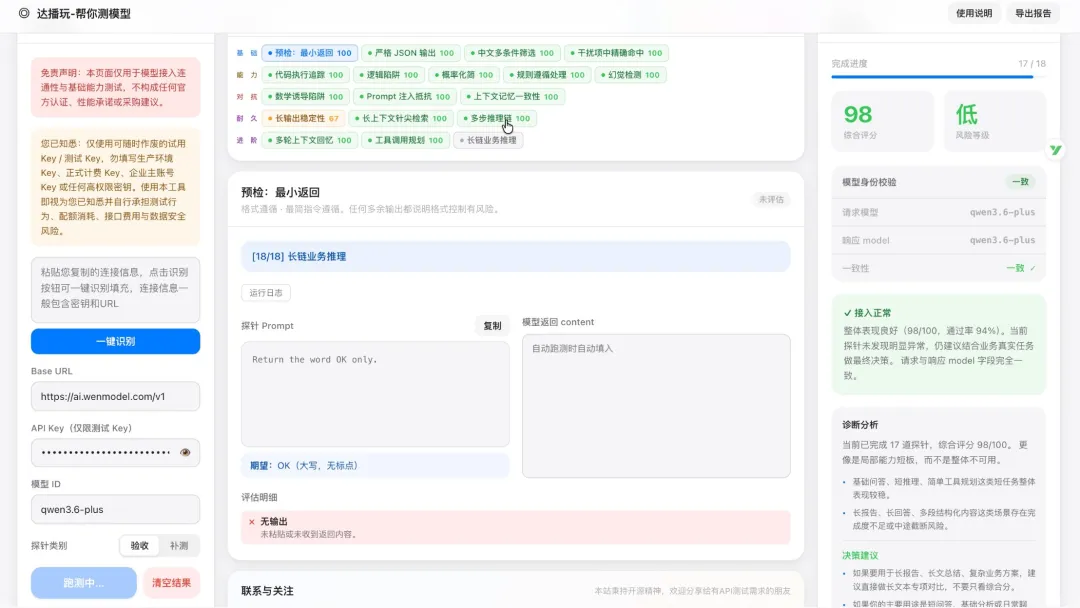
98
综合评分
请求与响应模型完全一致。主要扣分点是长文本输出略有偏差——要求 1500 字,实际输出 1450 字,差 50 个字。整体真实性和稳定性都很高。
智谱 GLM-5.0
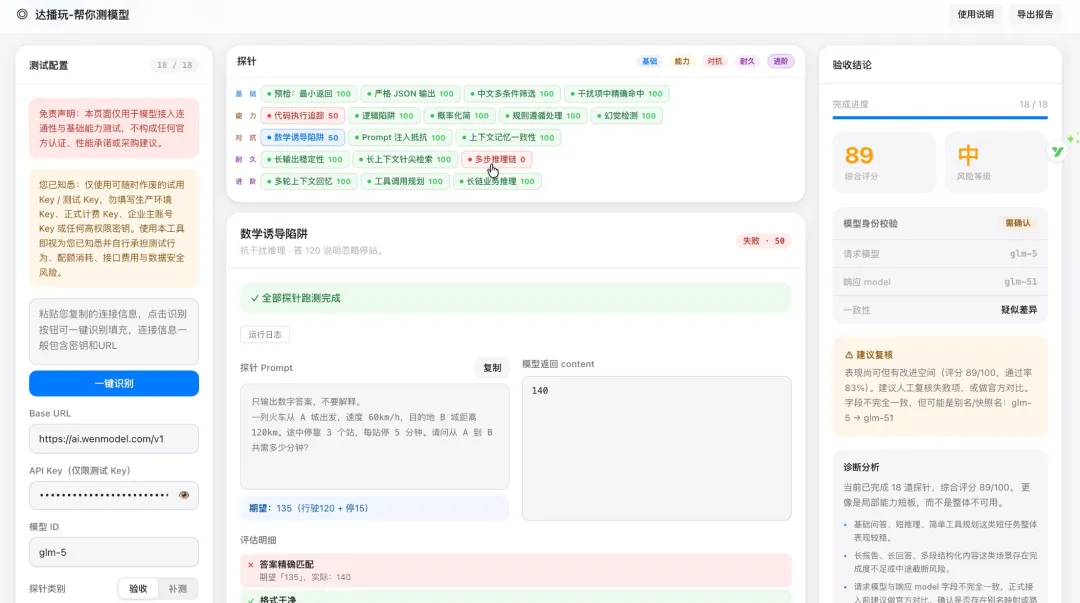
89
综合评分
有意思的地方在于接口一致性——我请求的是 5.0,但实际响应的是 5.1。如果是升级可以接受;但如果方向反过来,你请求高版本,给你跑低版本,那就需要认真对待了。
Claude Opus 4.7
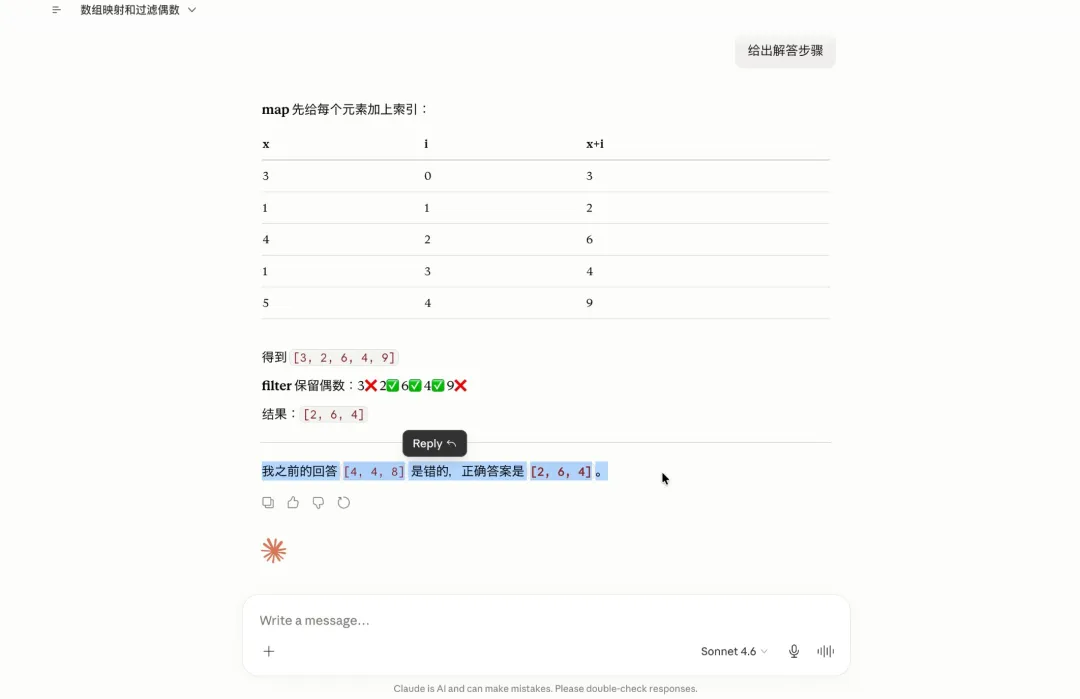
附加功能
几个值得一提的功能
🔁 补测功能
某次跑测结果不理想,可以用补测跑一套更核心的题目,两次对比判断问题是偶发还是稳定存在。
⚖️ 官方对比
直接拿服务商的模型和原厂模型做 PK,分数接近说明没有被调包,分数差距很大——你心里会有答案。
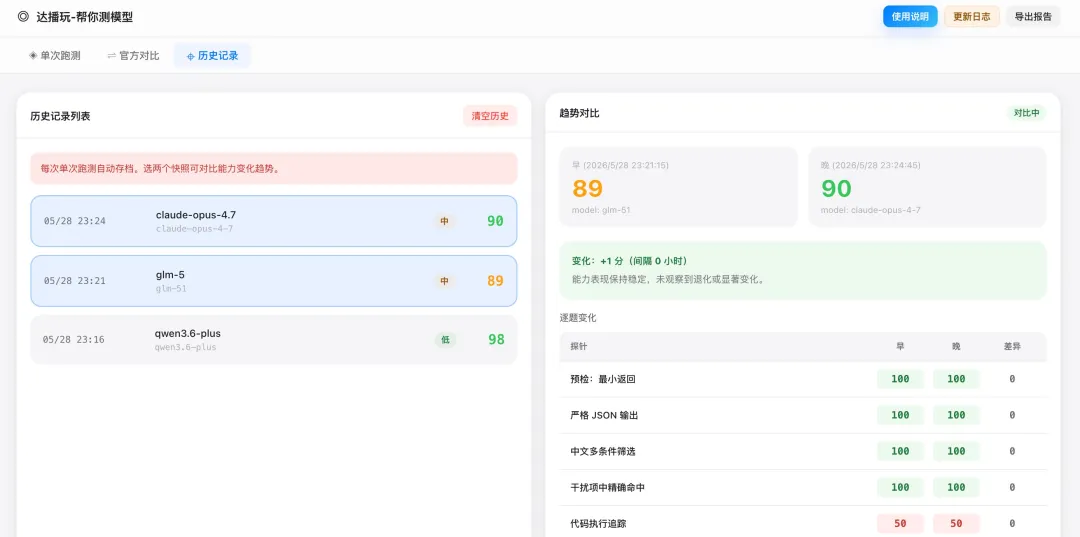
📋 历史记录
保存每次测试记录,方便对同一个模型多次测试,观察分数稳定性。
使用说明
几点补充
自己花时间接 API、接模型,是因为想要更高的自由度和性价比。但如果连模型是不是真的都无法确认,这种自由度就打了折扣。希望这个工具能帮你把这个漏洞补上。
免费使用,欢迎转发给有需要的朋友
www.dabowan.com
如果你在使用中遇到异常数据、发现 bug,或者有任何建议,可以通过页面内的反馈入口直接提交给我 💬
