 夜雨聆风
夜雨聆风
假设需要回答一个问题:“花旗银行成立那年,谁是美国总统?”
一种做法是依赖现成的检索系统。系统先根据“花旗银行”返回若干相关文档,其中某篇文档指出花旗银行成立于 1812 年;随后再检索“1812 年的美国总统”,得到答案:詹姆斯·麦迪逊。
另一种做法是直接面对原始语料。智能体需要在大量未排序的文本中自行查找:先定位所有提到“花旗银行”的文档,再继续筛选与“成立年份”相关的内容。由于原始档案通常按存储顺序排列,而不是按相关性排序,最权威的文档未必会最先出现,结果也可能受到无关材料的干扰。
第一种方式是当前主流 AI 搜索系统的典型架构:依赖预先构建的检索引擎,由检索器筛选候选文档。第二种方式则是本文所讨论的方向:让 AI 直接操作大规模原始文本,通过精确搜索、过滤和组合信息来获得答案。
这两种方式各有优势。论文的核心发现是:当一个小型 AI 模型掌握了直接检索原始文本的能力后,它在多个任务上可以超过依赖高性能检索引擎的系统,尤其是在需要多步推理的复杂问题上表现突出。
现有搜索 AI 的瓶颈
过去几年,大语言模型(LLM)的搜索能力显著提升。它们能够围绕知识密集型问题进行多轮推理和信息检索。但大多数系统采用相似的架构:模型提出查询,检索引擎从预建索引中返回排名靠前的文档。
这个索引通常在检索之前生成。每篇文档会被转换成数学表示,即向量,并存入数据库。用户发起搜索时,检索引擎也会将查询转换成向量,再在数据库中寻找距离最近的文档,这就是通常所说的语义检索。它的优势在于能够捕捉近义表达。例如,查询“汽车”时,系统也可能找到包含“轿车”的文档,因为二者在语义空间中距离较近。
但这种机制也带来一些问题。
语义检索具有模糊性。 它通常会将文档压缩为向量表示,细节信息可能被弱化。如果一篇文档同时提到母公司 “Oberoi Group” 和子公司 “EIH Ltd”,语义检索可能难以准确区分问题所指的是哪一个实体。
语义检索粒度较粗。 它通常返回整篇文档或文本片段,而不是精确到某一行、某个短语。许多问答任务所需的信息可能只出现在一句话中的局部位置。
索引是预计算且相对固定的。 文档在检索前已经完成切分、编码和存储。用户或智能体很难临时调整搜索策略,也无法对检索结果进行灵活的二次处理,只能在检索器返回的候选文档中继续选择。
这类似于在图书馆中只能通过目录卡查找书籍,而不能直接进入书架翻阅。目录卡能够提示哪些书大致相关,但无法保证定位到具体页面或具体句子。
因此,一个自然的问题是:能否让 AI 像程序员在代码仓库中使用 grep 一样,直接在原始文本上进行灵活且精确的搜索?
让 AI 直接操作原始文本
GrepSeek 的目标正是解决这一问题。
它的核心思路是:不预建向量索引,也不依赖中间检索器,而是让 AI 直接对原始文本执行 shell 命令。类似于程序员使用 rg "Oberoi Group" 在代码库中搜索字符串,GrepSeek 的智能体可以在包含 2100 万篇文档的语料库上执行命令,搜索关键词、过滤结果、截取内容,并逐步逼近答案。
例如,问题是:“Oberoi 家族所属的酒店公司总部位于哪个城市?”
GrepSeek 的智能体可能会按如下步骤执行:
第一步:搜索包含 “Oberoi family” 的文档,并进一步用 “hotel” 过滤。
第二步:从结果中发现相关公司名为 “The Oberoi Group”。
第三步:搜索 “The Oberoi Group” 与 “head office”。
第四步:定位到答案:新德里。
每一步都是一条 shell 命令。智能体可以检查命令结果,反思当前信息是否充分,再决定下一步操作。这与传统 RAG 系统存在根本差异。传统系统通常是“查询 → 检索器 → 文档列表”的流程,而 GrepSeek 采用“思考 → 执行命令 → 观察结果 → 再思考 → 再执行”的交互循环。搜索不再只是黑盒排序,而成为一系列可控、可解释的文本操作。
这一思路并非完全新颖。程序员长期使用 grep 和 ripgrep 在代码仓库中进行精确定位。也有同期工作探索了相近方向,但通常依赖 Claude 等大型闭源模型,并在推理时通过提示词编排搜索过程,回答一个问题可能需要较长时间。GrepSeek 的目标则是:将这种能力训练进一个仅有 90 亿参数的小模型,使其既高效又具有较强效果。
如何让 AI 学会检索原始文本
让一个小模型学会使用 shell 命令搜索大规模语料库,并不容易。
一种直观方法是直接使用强化学习(RL):让模型自由探索,正确则奖励,错误则惩罚。但实验表明,直接强化学习很容易失败。模型可能发出过于宽泛的命令,例如直接 cat 整个语料库,从而检索出大量无关文本,填满上下文窗口,甚至导致训练过程无法继续。即使系统配置了 1024GB 内存,也难以承受这种无约束探索。
问题在于初始策略过弱。如果模型尚未掌握基本的 shell 检索方法,它很难知道应该从哪些关键词或过滤条件开始。缺乏基础能力时,直接强化学习会产生大量低质量探索。
因此,GrepSeek 采用两阶段训练方案:先通过示范数据教会模型基本检索方式,再通过强化学习进一步优化策略。
第一阶段:构造示范数据
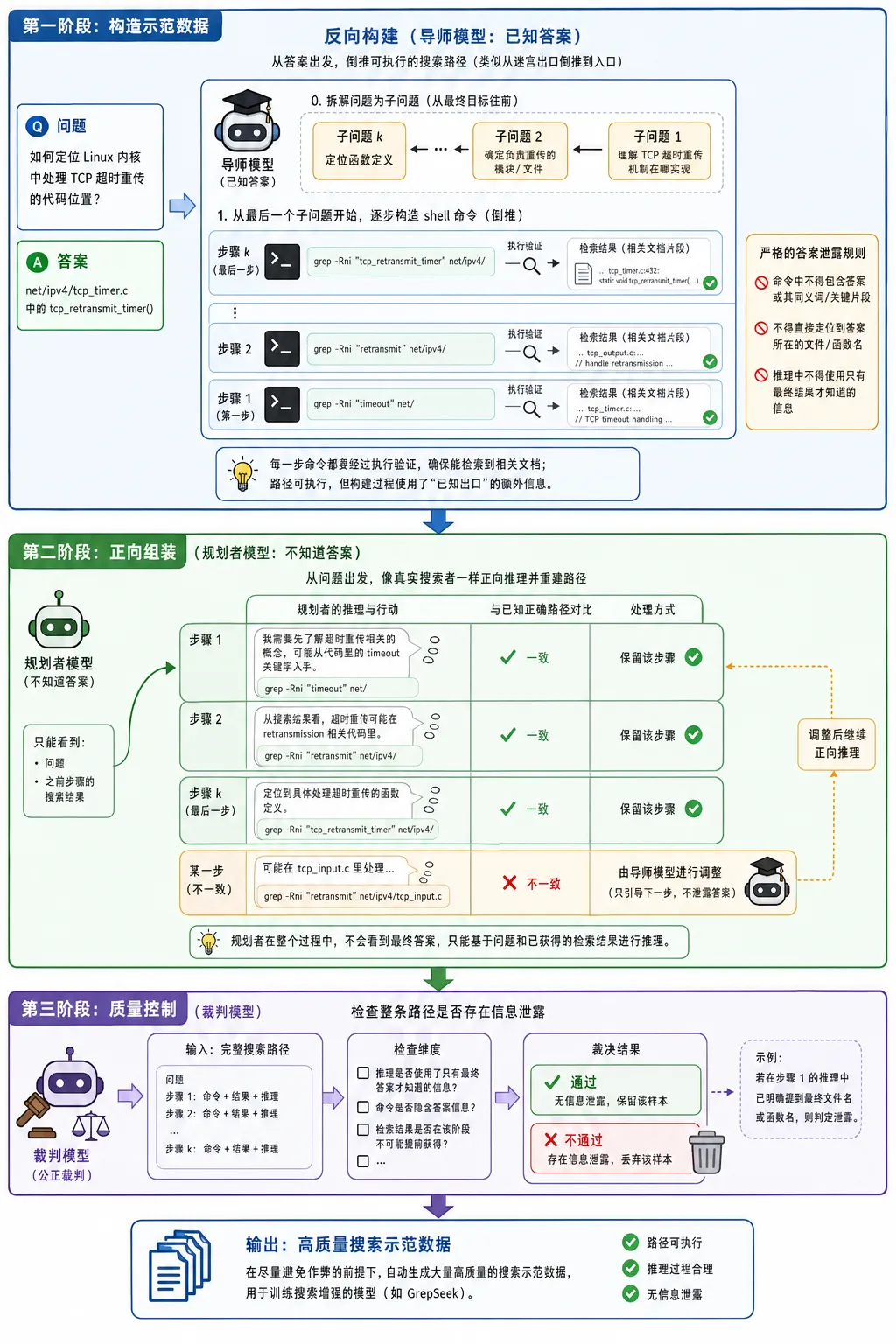
人工逐条编写示范数据成本过高,因此 GrepSeek 设计了一个自动化流程来生成训练样本。
关键挑战在于:需要生成从问题出发、逐步搜索、最终找到答案的完整路径。但如果生成模型已经知道答案,它可能会在推理过程中利用答案信息来构造搜索命令,而不是真正通过检索发现答案。
GrepSeek 采用了“反向构建 + 正向组装”的策略。
反向构建:让一个知道答案的“导师”模型从答案出发进行倒推。它先将问题拆解成子问题,再从最后一个子问题开始,逐步构造 shell 命令。每一步命令都需要经过执行验证,确保确实能够检索到相关文档。同时,命令本身不得包含答案信息,并受到严格的“答案泄露”规则约束。
这类似于在已知迷宫出口的情况下,从出口倒推到入口,标记出一条可行路径。路径本身是可执行的,但构建路径时使用了“已知出口”的额外信息。
正向组装:随后,让一个不知道答案的“规划者”模型从问题出发,尝试正向完成搜索路径。它只能看到问题和前序步骤的搜索结果,必须像真实搜索者一样进行推理。如果其推理与已知正确路径一致,则保留该步骤;如果不一致,则由导师模型调整推理过程,使其自然导向正确的下一步命令,同时避免泄露答案。
最后,还有一道质量控制环节:由“裁判”模型检查整条路径是否存在信息泄露。如果推理中出现搜索者在该阶段不可能提前知道的信息,该样本会被丢弃。
这套流程的作用在于:在尽量避免作弊的前提下,自动生成大量高质量的搜索示范数据。
第二阶段:强化学习优化搜索策略
完成示范训练后,模型已经具备基本的原始文本检索能力。但示范数据有限,且未必覆盖所有可能场景。因此,GrepSeek 进一步使用 GRPO(Group Relative Policy Optimization)进行强化学习。
在这一阶段,模型面对真实问题,自由尝试搜索策略,并根据最终答案的正确性获得奖励。由于第一阶段已经建立了基本能力,模型通常不会再采用极端宽泛的检索方式,而是在合理范围内探索更优路径。
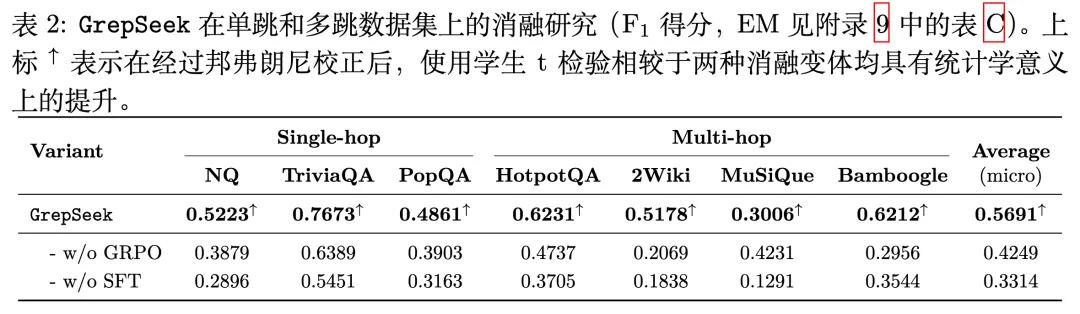
消融实验显示,两阶段训练各自具有重要作用:
• 去掉 GRPO,即只保留示范训练,平均 F1 从 0.5691 降至 0.4249。 • 去掉 SFT,即直接进行强化学习,平均 F1 下降至 0.3314。
由此可见,示范训练为模型提供了基础能力,强化学习则进一步提升其策略质量。二者缺一不可。
检索能力之外,执行效率同样重要
让 AI 在 2100 万篇文档上执行 shell 命令,可能带来明显的效率问题。如果每条命令都需要从头到尾扫描 14GB 文本,实际应用成本会很高。
为此,GrepSeek 设计了一个分片并行执行引擎:将语料库划分为多个分片,每条命令在不同分片上并行执行,随后合并结果。关键在于,这种并行执行能够保证逐字节等价,即结果与串行执行完全一致,只是速度更快。
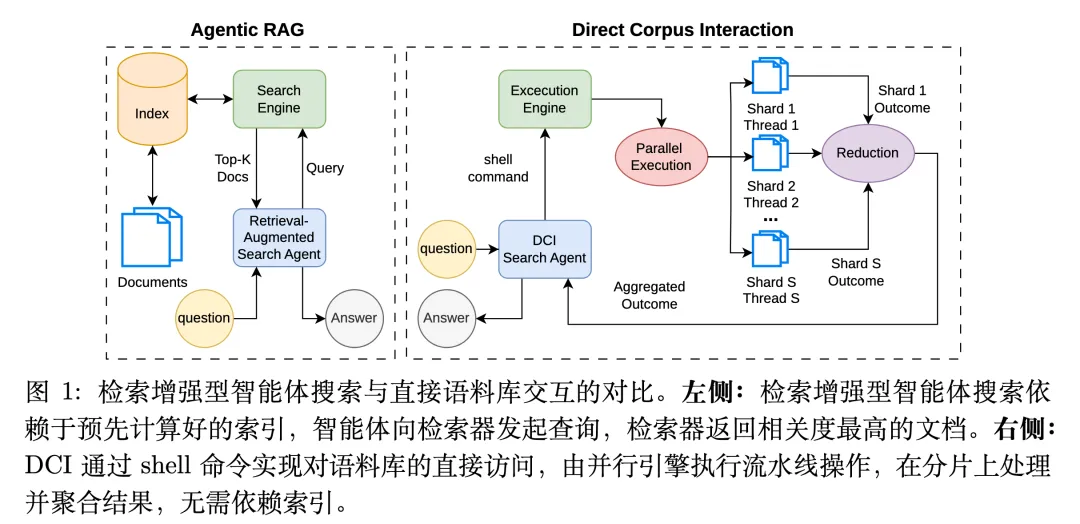
实验显示,该执行引擎最高实现 7.6 倍加速。同时,它的运行时内存占用明显低于密集检索系统,因为后者通常需要将完整向量索引加载到内存中。GrepSeek 也不需要额外花费时间和算力预先构建索引。
实验结果:精确搜索的优势
GrepSeek 在 7 个开放域问答基准上进行了评估,覆盖单跳问答和多跳问答两类任务。所有基线方法使用相同的大语言模型骨架,主要区别在于检索方式。
核心结果如下:
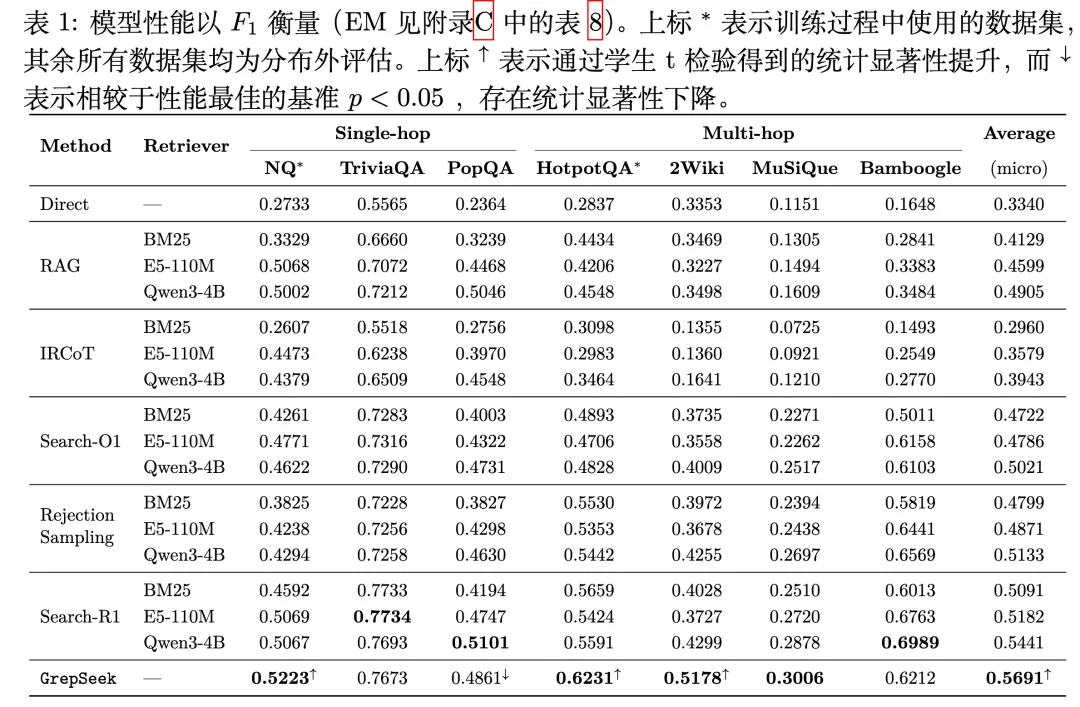
GrepSeek 在 4 个基准上取得最佳成绩,其中 3 个基准的提升具有统计显著性。其总体微平均 F1 为 0.5691,显著优于最强的密集检索基线。
尤其值得关注的是多跳推理任务上的表现。在 HotpotQA、2Wiki 和 MuSiQue 上,GrepSeek 明显优于所有密集检索基线。原因在于,多跳推理往往要求每一步都准确匹配实体,不能混淆母公司与子公司,也不能将同名实体误认为同一对象。精确文本匹配在这类场景中具有明显优势。
论文中给出了一个例子:问题是 “The Joggers 乐队的男主唱是一位美国化学家的儿子,这位化学家获得了最高的什么?”
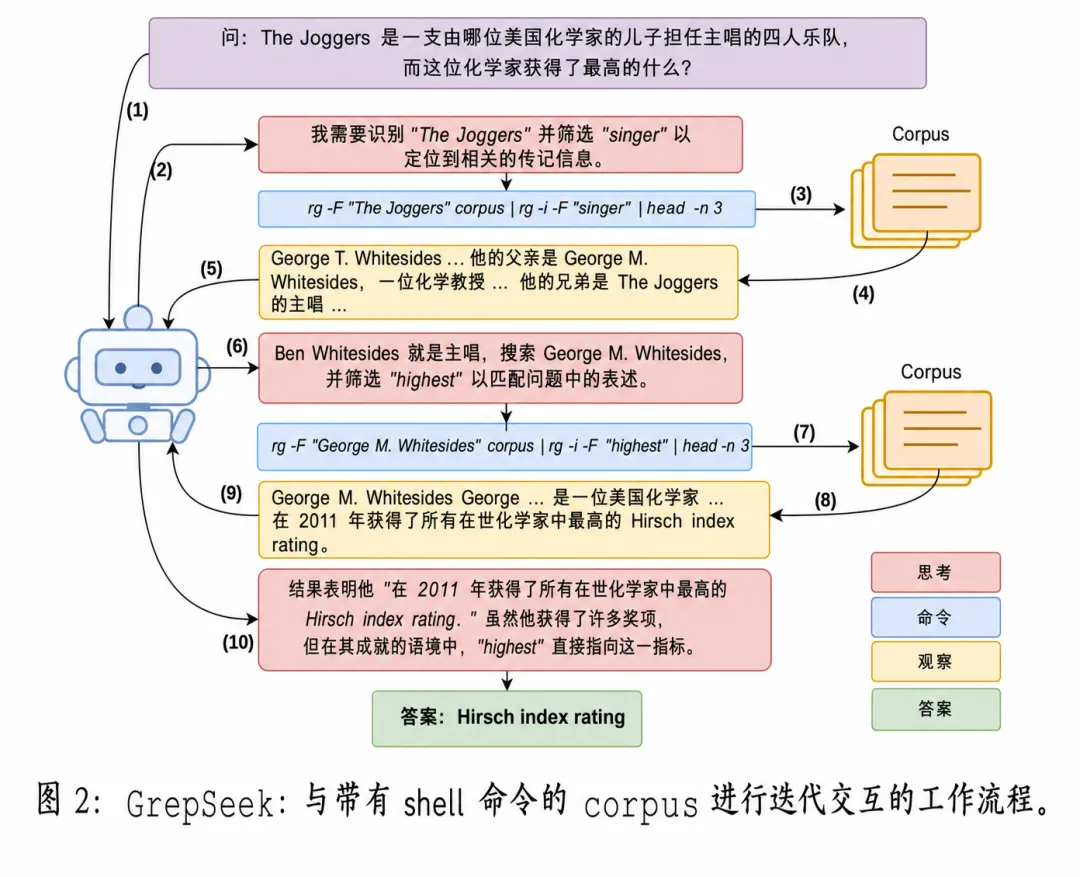
GrepSeek 首先搜索 “The Joggers”,找到男主唱 Ben Whitesides,并进一步确认其父亲是 George M. Whitesides。随后搜索 “George M. Whitesides” 和 “highest”,直接命中 “received the highest Hirsch index rating” 这一精确表述。

相比之下,密集检索系统虽然也找到了相关信息,却在最后一步出现偏差。它将 “highest” 理解为某种最高荣誉或著名奖项,例如国家科学奖章,而不是原文中的 “highest Hirsch index rating”。语义检索在此将相近含义混合在一起,反而偏离了文本中的确切表达。GrepSeek 由于进行了精确匹配,因此给出了正确答案。
局限性:精确匹配的脆弱性
精确匹配具有明显优势,但也存在局限。它在需要严格匹配的任务中表现较好,但在需要语义泛化或处理变体表达的场景中容易失败。
论文指出了三个主要失败模式(来源于 Case Studies)。
第一,拼写和变体较为脆弱。 当问题询问 “Édouard Vaillant 出生在哪个城市” 时,GrepSeek 搜索 “Édouard Vaillant”。但语料库中相关文档标题为 “Edouard Vaillant”,没有重音符号。由于精确匹配无法匹配该变体,智能体未能定位正确文档,最终依赖模型自身知识给出了错误答案“巴黎”。密集检索系统则因为语义匹配对重音符号不敏感,能够找到正确答案 Vierzon。
第二,缺乏相关性排序。 Shell 命令返回结果通常按文件顺序排列,而不是按相关性排序。当搜索“花旗银行成立年份”时,最权威的花旗银行词条可能排在无关公司词条之后。结果智能体可能从间接提及的文档中看到 1863 年,并将其误认为成立年份。事实上,1863 年是花旗银行前身获得特许的年份,而正确答案应对应 1812 年成立时的美国总统詹姆斯·麦迪逊。
第三,长尾实体覆盖不足。 PopQA 专门考察罕见实体,这些实体名称往往包含特殊拼写、变体或歧义。在这类查询上,GrepSeek 出现了统计显著的性能下降。
这些局限具有共同根源:纯文本匹配缺乏语义理解能力。它无法自动判断 “Édouard” 与 “Edouard” 指向同一人,也无法识别排序靠前的结果是否真正最相关,更难处理不同表述之间的语境差异。密集检索系统在这些方面具有天然优势,因为它们会将文本映射到语义空间,使相似表达能够相互关联。
启示:精确检索与语义检索的互补
GrepSeek 的意义并不在于完全取代现有检索系统,而在于展示了另一条值得关注的技术路径。
长期以来,AI 搜索研究主要围绕构建更好的索引、训练更强的嵌入模型、设计更精细的排序算法展开。这一路线已经取得了显著进展。GrepSeek 则表明,除了改进检索器本身,也可以让智能体直接与原始文本交互,通过精确操作替代部分黑盒排序过程。
这一方向具有实际优势:无需预先构建昂贵的向量索引,无需在运行时加载大型向量数据库,执行成本更低,部署更灵活。在某些任务中,尤其是需要严格实体匹配和多步推理的场景中,它还可能获得更高准确率。
但其局限同样明确:对拼写变体敏感,缺乏语义泛化能力,在长尾知识和表达变化较大的问题上容易出错。
因此,更自然的未来方向并不是在精确检索和语义检索之间二选一,而是进行融合。一个理想的搜索智能体应当既能使用 shell 命令进行“手术刀式”的精确检索,也能调用语义检索器进行“广角镜式”的相似性搜索。在需要实体精确匹配时使用精确检索,在需要语义泛化时使用向量检索。论文作者也指出,混合检索架构是后续工作的重点方向之一。
从更广的角度看,GrepSeek 反映出一个重要趋势:AI 系统正在从单纯使用工具,转向学习如何操作和优化工具使用过程。传统检索系统通常是固定的黑盒,AI 只能学习如何提出更好的查询。而在直接语料交互的范式下,AI 学到的不只是“问什么”,还包括“如何查找”。这使其在复杂任务中具备更强的自主性、可控性和可解释性。
理想的搜索系统不应只返回“相关程度较高”的文档,而应在需要精确时足够精确,在需要灵活时具备语义泛化能力。如何让 AI 掌握这种取舍,可能是未来搜索系统发展的重要方向。
paper:https://arxiv.org/abs/2605.29307
code:https://github.com/alirezasalemi7/grepseek
