 夜雨聆风
夜雨聆风我曾经遇到一家客户,以工作时长衡量员工绩效,以代码行数衡量程序员成果。你可以想象,这些指标会如何被大家轻易扭曲,并与企业的价值创造完全脱节。
今天,如果你用Token用量来评价AI项目的成功,就跳进了一模一样的陷阱。你最终会发现,token成本剧增,但大家的工作效率却没提升。
强如微软都没法避免这个陷阱,疏于管理的企业就更难躲开了。
二:以“裸奔”的Agent证明AI无效
试想,你打电话给一个经验丰富的数字化顾问,让TA立刻提出对当前ERP系统的三点改进意见——你不能因为顾问无法在五分钟内给出具体方案就认为这个顾问不专业。
道理是相通的,LLM的原生知识只有公开的训练数据。你的OpenClaw不会因为连上了Opus4.8就突然懂得了你的业务,也就是我们常说的“企业记忆”。
如果你问它这批物料该选哪个供应商,却不给他任何数据库权限,它就只能在训练数据里搜肠刮肚,给你吐出来个似是而非的错误答案。
三:没有harness的Agent
把任何Agent通过MCP或CLI接到企业系统都是危险的,特别是在集群Agent盛行的今天。如果不加harness的约束,你永远不知道哪个subagent会改掉哪个物料的Effectivity,而最终让你的CEO去向客户登门道歉。
这不是模型的失败,而是整个Agent治理团队的失败。
无论是Anthropic还是OpenAI的产品手册,实际上都在告诉你:效率的代价是质量。因为效率意味着Agent集群并行完成大量工作,你必将失去预测和审计的可能性,把任务质量交到了随机数手上。
在实际工作中,你会发现最安全的手段仍然是工作流而不是Agent集群。你在任何一步添加校验节点(Gate),都在为准确的结果牺牲效率。
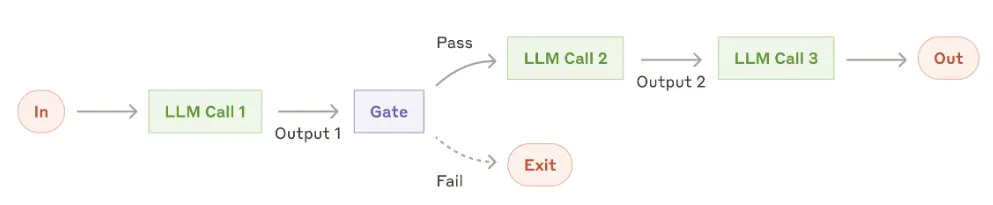
上图来自Anthropic研究:
https://www.anthropic.com/engineering/building-effective-agents
四:“自动化原教旨主义”改造
在工业软件圈,自主代理、自我治理、代替人类的思潮已经持续数年,但无论是PLM、CAD还是CAE,落地仍然缓慢,更不用提深入现场的MES和ERP。问题不在AI的任务成功率,而在于失败的责任归谁。
你看到了,责任问题永远在技术问题之前。时至今日,MRP运算错误都难以追责,更不用提毛手毛脚的Agent。
今天,在业务外围打转的Agent或工业软件服务商无论再怎么摇旗呐喊,都解不了这个生产关系的难题。
五:忽略结构化数据之外的“企业记忆”
睡眠的一大作用是整理记忆,给每一份记忆打上各种标签:时间、人物、地点、系统……
所以只要给你一点线索,你就能轻松把各种回忆穿起来,比如哪个供应商在什么时候用微信还是邮件给你了一份初步报价。
我们还能从这份报价的字里行间识别出对方的积极性、成本弹性、还价空间。制造业的利润都是微薄的,正是这些信息让我们可以在竞争激烈的市场勉力生存。
这是人类的优势,也是AI无法逾越的短板。你心里清楚,真正有用的数据都在微信、邮件、会议纪要里,你80%的决策依据都来自这些数据。
那么如果你还想拥抱AI,要么给AI这些数据的权限,要么就改变自己的工作流,把有用的数据随时喂到那些结构化的数据源里。如果你给它的权限只是录入最终报价的SRM数据库,它就永远没法真正帮到你。
