一、为什么数仓数据治理需要 AI ?
数据仓库作为企业数据资产的核心载体,其治理水平直接决定了数据能否被有效消费。然而,传统数据治理在面对 PB 级规模、数百个业务系统、数千张表的时候,正在暴露出越来越明显的瓶颈。
先看三个典型痛点:第一,元数据分散且难以维护,一张核心业务表的"订单金额"字段,财务口径和运营口径可能不同,人工梳理元数据的效率远远跟不上表结构变更的速度;第二,数据质量规则依赖人工编写和维护,新增一张表就要手写几十条校验规则,治理团队疲于奔命;第三,数据血缘依赖人工记录或基础的 AST(抽象语法树)解析,一旦上游链路变更,下游影响范围很难快速评估。
大模型的出现改变了这个局面。它具备强大的自然语言理解能力、代码生成能力和模式识别能力,可以充当数据治理的"智能助手",将大量重复性、规则化的治理工作自动化。根据 DAMA(Data Management Association)的定义,数据治理包含数据质量管理、元数据管理、数据安全管理、数据标准管理等多个领域。AI 并非要取代治理体系本身,而是在每个领域提供提效手段,让治理团队把精力放在更高价值的决策上。
核心判断:AI在数仓数据治理中的价值不是"替代人",而是把人从"写规则、查血缘、对口径"等低附加值的重复工作中解放出来,聚焦在制度设计、跨部门协调、业务价值挖掘上。二、AI 驱动的数仓数据治理总体架构
整体架构遵循"分层解耦、AI 嵌入治理流程"的设计原则,参考 DAMA-DMBOK 和 DCMM(数据管理能力成熟度评估模型)两大行业标准体系。
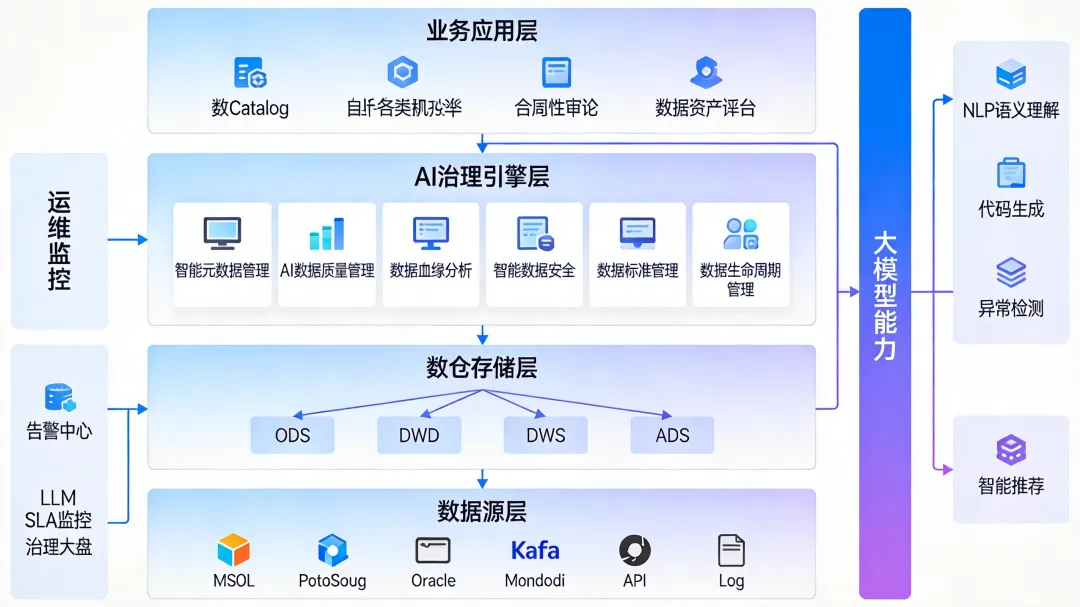
一个可落地的AI +数仓数据治理架构,应该从下到上分为四层,并在关键层级嵌入 AI 能力:
数据源层:覆盖关系型数据库(MySQL、PostgreSQL、Oracle)、消息队列(Kafka)、NoSQL(MongoDB、HBase)、日志系统、API接口等异构数据源。这一层的核心任务是通过CDC(Change Data Capture)和批量抽取,将数据统一接入数仓。数仓存储层:按照ODS(Operational Data Store,原始数据层)、DWD(Data Warehouse Detail,明细数据层)、DWS(Data Warehouse Summary,汇总数据层)、ADS(Application Data Service,应用数据层)的经典分层模型组织数据。每一层有明确的职责边界和数据流转规则。AI治理引擎层:这是核心层,包含六大治理模块——智能元数据管理、AI数据质量管理、数据血缘分析、智能数据安全、数据标准管理、数据生命周期管理。大模型能力(NLP语义理解、代码生成、异常检测、智能推荐)以服务化方式嵌入到每个模块中。业务应用层:面向终端用户提供数据资产目录、自助分析、合规审计、数据资产看板等应用。设计原则:架构设计遵循以下三个原则—— (1)治理与计算分离:元数据分析、血缘解析、质量规则管理等治理操作以旁路审计的方式运行,不嵌入 ETL 执行链路,避免影响数仓正常的数据加工性能; (2)AI 能力可插拔:大模型支持 API 调用(适用于非敏感场景)和私有化部署(适用于金融、政务等强监管场景)两种接入方式,可独立升级和替换; (3)渐进式治理:先从元数据和数据质量两个高频场景切入,再逐步扩展到安全、标准、生命周期管理等领域。 |

三、核心模块一,智能元数据管理
元数据是数据治理的基石。AI 在元数据管理中的核心价值在于:智能识别、智能补全、语义关联。
3.1 元数据的三层分类体系
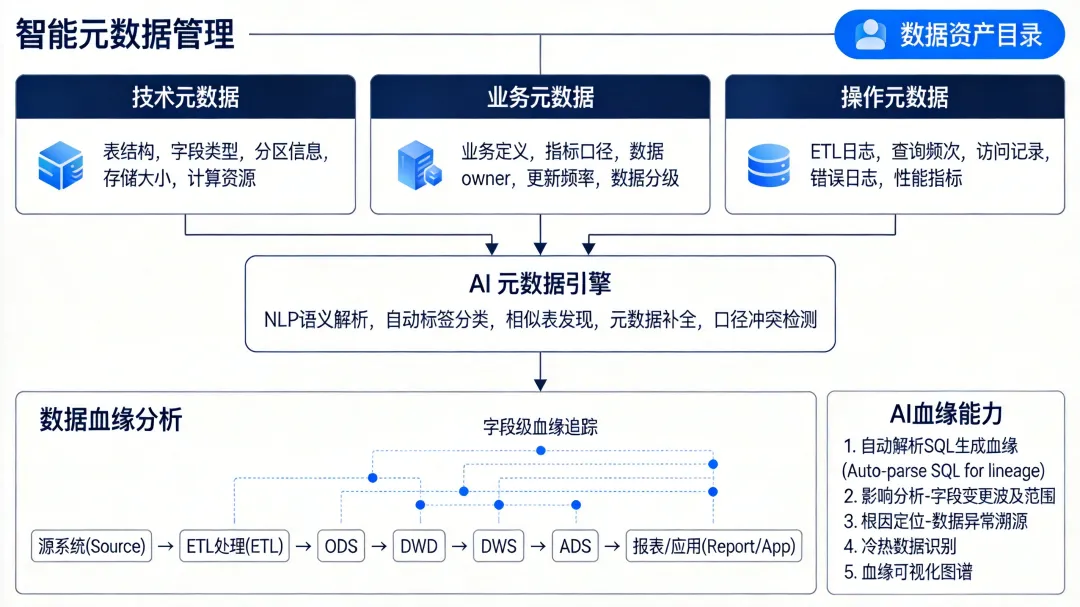
按照行业标准,元数据分为三类:
技术元数据:描述数据的物理和技术特征,包括表结构、字段类型、分区信息、存储大小、依赖关系、计算资源消耗等。这类元数据可以通过JDBC探针、SQL AST解析器(如Apache Calcite)自动采集。业务元数据:描述数据的业务含义和上下文,包括业务定义、指标口径、数据Owner、更新频率、数据分级分类等。这类元数据传统上需要人工维护,是AI可以发挥最大价值的地方。操作元数据:记录数据的使用情况,包括ETL执行日志、查询频次、访问用户、错误日志、性能指标等。这类数据是数据生命周期管理和资源优化的依据。3.2 AI 赋能的三个关键能力
自动标签分类:大模型通过分析表的字段名、注释、样本数据,自动推断表的业务域归属(如"用户域""订单域""商品域")和数据敏感级别(如将包含手机号的字段标记为高敏感级个人隐私数据)。实际落地中,建议先用人工标注200-500张表作为样本,再通过Few-shot Prompting(少样本提示)引导大模型进行分类推理。在业务域划分边界清晰的前提下,分类准确率通常可达到较高水平,但具体效果取决于业务复杂度和样本质量,建议以实际验证结果为准。智能元数据补全:数仓中大量表缺少注释或注释过时。大模型可以基于字段名(如、)、上下游表的注释、样本数据分布,自动生成字段的中文描述和业务含义,经人工确认后写入元数据中心。根据行业实践案例,元数据注释覆盖率通常可从较低水平(20%-50%,具体取决于企业现状和治理起点)提升到90%以上。口径冲突检测:当多张表的"GMV"(Gross Merchandise Volume,商品交易总额)指标出现不同数值时,大模型可以解析各表的计算逻辑,定位口径差异(如"是否含退款""是否含税费"),并生成差异报告。以人工排查为例,一张复杂报表涉及的口径差异排查通常需要30-60分钟,而AI解析可在秒级完成,排查效率显著提升。3.3 数据血缘的自动化构建
数据血缘是元数据管理的核心能力之一。传统血缘依赖人工维护或基础AST解析器提取,覆盖率和准确度有一定局限。AI 赋能后的血缘分析采用"AST 为主、大模型为辅"的技术路线:
标准SQL解析(AST为主):对于标准SQL语句(含子查询、JOIN、UNION、窗口函数等),使用AST解析器(如Apache Calcite、SQLGlot)提取表级和字段级血缘关系。AST解析的优势是确定性强、结果可复现,适合覆盖ETL任务和SQL脚本中的血缘提取。非标准场景解析(大模型为辅):对于存储过程、Shell脚本、Python脚本、硬编码逻辑等AST解析器难以覆盖的场景,大模型通过代码语义理解辅助提取血缘关系,弥补传统工具的盲区。影响分析:当一张源表发生变更(删字段、改类型)时,系统基于已构建的血缘图谱自动评估下游影响范围——哪些表、哪些报表、哪些业务流程会受到影响,生成影响评估报告。根因定位:当某个报表数据出现异常时,系统沿血缘链路向上追溯,快速定位问题出在哪一层、哪张表、哪个字段。加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!
四、核心模块二,AI 数据质量管理
数据质量是数仓治理的生命线。AI 的核心价值在于:自动生成规则、智能诊断、闭环修复。
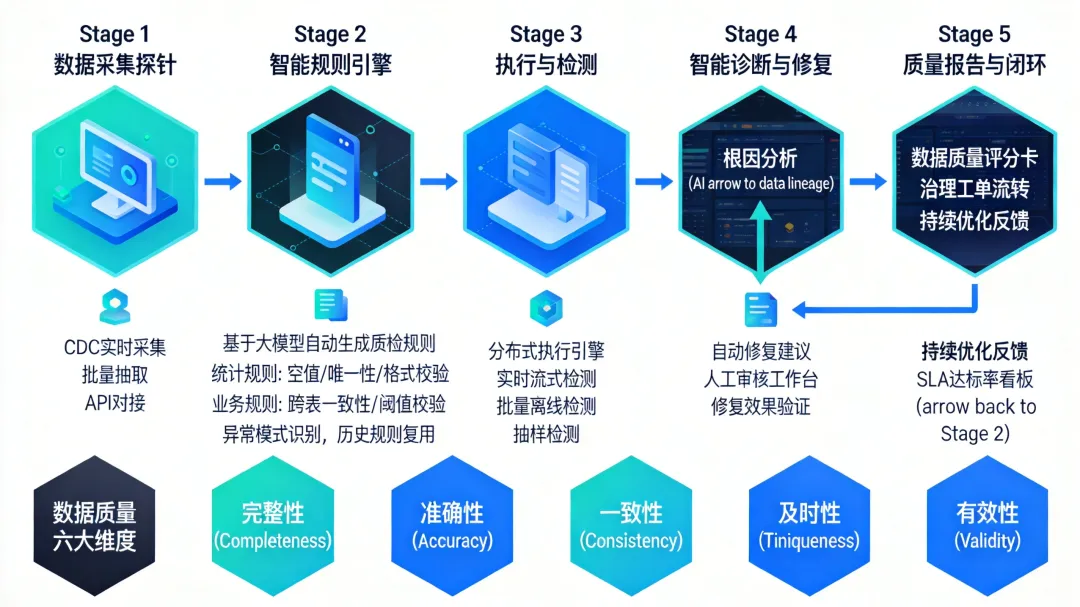
4.1 数据质量的六维度模型
参照 ISO 8000 和 DAMA 标准,数据质量评估覆盖六个维度:
维度 | 定义 | 典型规则示例 |
完整性 | 数据字段是否缺失或为空 | 订单表的 order_id 不允许为 NULL |
准确性 | 数据值是否正确反映真实业务事实 | 订单金额与支付系统流水核对,偏差不超过 0.01 元 |
一致性 | 跨表、跨系统的同一实体数据是否保持逻辑一致 | DWD 层 GMV = ODS 层各渠道 GMV 之和 |
及时性 | 数据是否在业务约定的 SLA 时限内产出 | ADS 层报表必须在每日 8:00 前就绪 |
唯一性 | 数据是否存在重复记录 | 用户表的 user_id 在该表内全局唯一 |
有效性 | 数据是否符合预定义的格式、类型和值域约束 | 手机号字段必须匹配 11 位数字格式 |
注:上述维度之间存在一定交叉。例如"订单金额不能为负数"既可归入有效性(值域约束),也可归入准确性(业务合理性)。治理团队应在规则定义阶段明确每条规则的归属维度,避免同一校验逻辑在多个维度下重复配置。
4.2 AI 赋能的智能质检规则引擎
传统数据质量管理最大的痛点是"规则编写成本高"。每接入一张新表,治理人员需要手动编写 10-30 条校验规则,费时且容易遗漏。
AI 改变了这个流程。治理人员只需将表的 DDL(Data Definition Language,建表语句)、样本数据、业务描述输入系统,大模型即可基于规则模板库和字段语义,自动生成一套初始质检规则,包括:
- 统计型规则:基于数据分布自动推断,如"某字段的空值率超过 5% 触发告警""某字段的值域出现新值触发告警"
- 业务型规则:基于字段语义和关联关系生成,如"订单金额 = 单价 x 数量的偏差率不超过 1%""用户年龄在 0-150 之间"
- 跨表一致性规则:基于血缘关系自动推断,如"DWS 层日活用户数不应大于 DWD 层当日活跃用户数"
生成的规则经治理人员审核确认后,纳入正式规则库执行。实际落地中,首期建议选取 50-100 张核心表作为试点,验证规则生成质量后再逐步推广。
4.3 闭环质量管理流程
数据质量管理不能止步于"检测",必须形成闭环。完整的闭环流程包括四个环节:
检测:规则引擎按调度计划执行质检任务,支持实时流式检测(针对Kafka等流数据)和批量离线检测(针对Hive/T+1数据)。检测频率根据数据重要性分级设置,核心业务表建议每小时检测一次(如交易明细),一般参考表每日检测一次。诊断:当检测到质量问题后,系统结合血缘图谱进行根因分析。例如"订单金额空值率突增",系统沿血缘向上追溯,发现是上游支付系统接口变更导致,直接定位到ODS层的源表和对应字段。修复:AI基于历史修复记录和规则模式,生成修复建议,推送到修复工作台。修复策略需根据数据场景区分:对于非核心度量字段(如用户昵称),可考虑使用历史均值或中位数填充;对于核心业务指标(如交易金额、库存数量),应优先定位上游数据问题并补跑ETL任务,不推荐使用统计填充。涉及数据修正的操作必须经过人工审批后执行,确保全程可追溯。验证:修复完成后自动重跑相关质检规则,验证修复效果。如果仍然不通过,升级为治理工单流转到相关数据Owner。落地建议:质检规则不要追求"一步到位"。先用 AI 生成基础规则覆盖 80% 的高频质量问题,再根据业务反馈逐步迭代优化。初期允许一定误报率,但漏报率必须控制在 5% 以内——漏报意味着问题数据流入下游,风险远大于误报。 |
五、核心模块三,数据标准与安全治理
5.1 数据标准管理的智能化
数据标准是企业数据"普通话"的制定和执行机制,包括命名标准、编码标准、指标标准、数据模型标准等。AI 在数据标准管理中的落地场景包括:
标准自动推荐:当新建一张表时,AI基于已有标准库和历史表的命名习惯,推荐字段命名、数据类型、注释模板。例如输入"用户手机号",AI自动推荐字段名,类型,注释"用户手机号码,需按脱敏策略管控"。标准合规检查:定期扫描数仓全量表的命名规范、类型规范、编码规范,生成不合规清单。例如发现某张新增表的字段命名使用了驼峰式()而非团队约定的下划线式(),自动生成整改建议。指标口径对齐:企业内不同部门对同一指标常有不同定义。AI通过解析各业务系统的指标计算逻辑,自动识别口径差异并生成对齐报告。例如"月活用户"在用户运营侧定义为"当月有登录行为",在风控侧定义为"当月有交易行为",AI识别差异后提示治理人员统一口径。5.2 智能数据安全管理
数据安全管理是监管合规的硬性要求,尤其在金融、医疗、政务等强监管行业。AI 在数据安全治理中的落地采用"规则优先、大模型辅助"的分层策略:
敏感数据识别:对于标准化的敏感类型(身份证号、手机号、银行卡号、邮箱地址等),采用正则表达式和命名实体识别(NER)模型进行结构化匹配,识别准确率高且确定性可控。对于需要上下文语义判断的复杂场景(如某自由文本字段是否涉及医疗隐私、某备注字段是否包含商业机密),大模型通过语义理解辅助识别,弥补规则方法的盲区。智能分级分类:将识别结果与国家标准(如GB/T 35273《个人信息安全规范》)、行业监管要求(如金融行业《个人金融信息保护技术规范》)进行映射,自动完成数据分级分类。分类结果写入元数据中心,作为后续脱敏、加密策略的依据。动态脱敏策略:根据数据分级和访问场景,自动推荐脱敏策略。动态脱敏的原理是:原始数据在存储层保持不变,在查询层根据访问者的权限等级实时脱敏。例如"手机号"字段在开发测试环境使用掩码脱敏(138****5678),在生产环境对非授权用户全脱敏,对授权用户展示原文。脱敏规则随数据分级自动联动更新。异常访问检测:基于用户操作元数据(查询频次、访问表范围、数据下载量),采用异常检测算法(如孤立森林Isolation Forest、局部异常因子LOF)建立用户行为基线。当出现异常行为(如非工作时间批量导出敏感数据、跨域访问非授权数据)时,自动触发告警并记录审计日志。大模型在此时承担异常行为的语义解读角色——将检测到的异常模式转化为可理解的告警描述,辅助安全人员快速判断。六、核心模块四,数据生命周期管理
数据生命周期管理的目标是让数据"从入仓到归档"的全过程可控、可度量、可优化。
该模块覆盖数据从创建、存储、使用、归档到销毁的完整过程,AI 在其中发挥三方面作用:
冷热数据智能识别:基于操作元数据(查询频次、最后访问时间、下游依赖数量),结合业务特征(数据时效性要求、业务周期),建立冷热数据评估模型。热数据保留在高性能存储层,温数据迁移至低成本存储层,冷数据归档至对象存储或离线存储。评估周期建议按月执行,阈值参数根据业务场景动态调整。存储资源优化:AI基于各表的存储大小、增长趋势和访问热度,预测未来存储资源需求,提前识别存储瓶颈。对于长期无人访问且无下游依赖的"僵尸表",自动生成清理建议,经数据Owner确认后执行归档或下线。合规留存与销毁:根据数据分级和监管要求(如《网络安全法》第21条要求网络运行日志留存不少于6个月,各行业另有具体的最低留存期限要求),自动计算每张表的最低留存期限。留存期满且无业务价值的表,系统生成销毁清单,经审批后执行安全销毁。七、实施路径与关键成功因素
7.1 三阶段实施路径
AI + 数仓数据治理的建设不能一蹴而就,建议采用"试点-推广-深化"的三阶段路径:
第一阶段,基建+试点:完成元数据自动采集和血缘解析的基础建设,选取一个业务域(如"交易域")的50-100张核心表作为试点。在这个阶段验证AI自动生成质检规则、自动补全元数据的效果,积累首批治理成果。第二阶段,推广+闭环:将治理范围扩展到全部业务域,建立数据质量管理闭环流程,上线数据资产目录。同时引入数据标准和安全管理模块,初步形成完整的治理体系。第三阶段,深化+价值运营:基于积累的治理数据,构建数据资产评估模型——从数据使用活跃度(查询频次、下游报表依赖数)、数据质量评分、业务覆盖度三个维度量化每张表的资产价值。同时实现冷热数据自动识别和生命周期管理,将治理指标(质量评分、覆盖率、SLA达标率等)纳入数据团队考核体系,形成常态化运营机制。阶段 | 核心目标 | 关键交付物 | 成功标志 |
试点期 | 验证 AI 治理效果 | 元数据中心 + 质检规则引擎 + 试点域治理报告 | 试点域数据质量评分(百分制)从基线 60-70 分提升至 80 分以上 |
推广期 | 建立治理闭环 | 数据资产目录 + 闭环工单系统 + 安全分级 | 全量表元数据覆盖率 > 90% |
深化期 | 数据价值运营 | 资产评估模型 + 生命周期管理 + 考核体系 | 治理 SLA 达标率 > 95% |
7.2 关键成功因素
基于行业实践,AI + 数仓数据治理项目能否成功,取决于以下五个因素:
组织保障:数据治理是"三分技术、七分管理"。必须有明确的数据治理委员会(通常由CDO或CTO牵头),定义数据Owner、数据管家等角色职责。没有组织保障,再好的技术方案也落不了地。数据基础:AI治理的前提是数仓基础架构具备基本的规范性,分层模型清晰、命名规则统一、ETL流程可追溯。如果数仓当前处于缺乏分层和规范的初级阶段,建议先完成基础规范化建设,再引入AI治理能力。模型选型:大模型选型需同时考虑效果、成本和数据安全合规。对于元数据补全、规则生成、口径解析等场景,企业需根据自身数据安全等级选择部署方式:敏感数据不出域的企业应优先考虑私有化部署(如基于Qwen、GLM、DeepSeek等开源模型本地化部署),非敏感场景可考虑通过API调用云厂商模型服务。模型选型需在安全性、效果和成本之间取得平衡,而非简单选择"最强"的模型。人工审核:AI生成的规则和建议必须经过人工审核才能正式生效。这一步不能省——大模型存在幻觉(Hallucination)问题,直接将AI输出写入生产环境存在风险。建议设立"AI建议→人工审核→生效执行"的标准流程。度量体系:没有度量就没有改进。必须建立治理成效的度量体系,包括数据质量评分、元数据覆盖率、标准合规率、安全审计通过率等指标,定期复盘并持续优化。八、总结与展望
AI + 数仓数据治理的核心逻辑是:用大模型的语言理解和代码生成能力,将传统治理中大量依赖人工经验的工作自动化,实现显著的效率提升。但需要明确的是,AI 是工具而非目的,数据治理的本质依然是组织建设、流程规范和制度执行。
从落地节奏上看,建议企业从"元数据管理 + 数据质量"这两个最痛的场景切入,在试点域验证治理成效后再逐步扩展到全域。技术选型上,大模型以可插拔方式嵌入现有治理平台,支持 API 调用和私有化部署两种模式,保持架构的可替换性和可演进性。
展望未来,随着大模型能力的持续增强和治理数据的持续积累,数据治理将从"被动治理"走向"主动治理",系统能够在数据入仓之前就预判潜在问题,在数据产生价值之前就完成质量保障,真正实现"治理即服务"的终极目标。
如果你觉得这篇文章有启发,欢迎点赞 + 在看 + 转发,让更多数据同行看到!
更重要的是——点个关注【华哥聊数据】,追更不迷路!
博主留言:
加入我们,内部VIP社群知识星球,获取更多数据仓库、AI与大数据内容与干货!
我们不止讲概念,更输出可落地的解决方案。
下期见
 夜雨聆风
夜雨聆风