 夜雨聆风
夜雨聆风AI 漏洞猎手(六):攻防验证怎么做才不越界
一句话核心观点:安全验证的目标不是教会别人复用攻击,而是在授权边界内证明风险、帮助修复、留下可审计证据。
本文是“AI 漏洞猎手”系列第 6 篇,聚焦攻防验证边界。很多内部文档容易走偏:为了说明问题,写成了可复制攻击步骤。本文的主张是,PoC 应该回到证据工程。
重要说明:本文只讨论授权环境中的最小化验证、证据整理、影响判断和修复回归。不提供真实目标攻击步骤、可复制 exploit payload、绕过技巧、批量扫描脚本或武器化利用链。
目录
先给结论:验证不是攻击教程
证据阶梯:从代码线索到可关闭工单
边界:可以写什么,不写什么
实战用例一:权限问题如何证明风险
实战用例二:异常终止如何判断安全影响
报告解剖:一份合格验证报告长什么样
影响评估:不要只看“能不能复现”
落地清单:验证报告至少检查 10 项
五个常见问题,直接给答案
内部文档能不能写更细?
PoC 是否一定不能写?
研发说“不复现不修”怎么办?
AI 适合写验证报告吗?
最容易被忽略的边界是什么?
最后的判断
专业术语注释
先给结论:验证不是攻击教程
漏洞验证需要具体,否则研发很难修;但具体不等于把利用链写成教程。一个合格的验证材料,应说明授权范围、触发条件、观察到的影响、已有补偿控制、修复建议和回归结果。
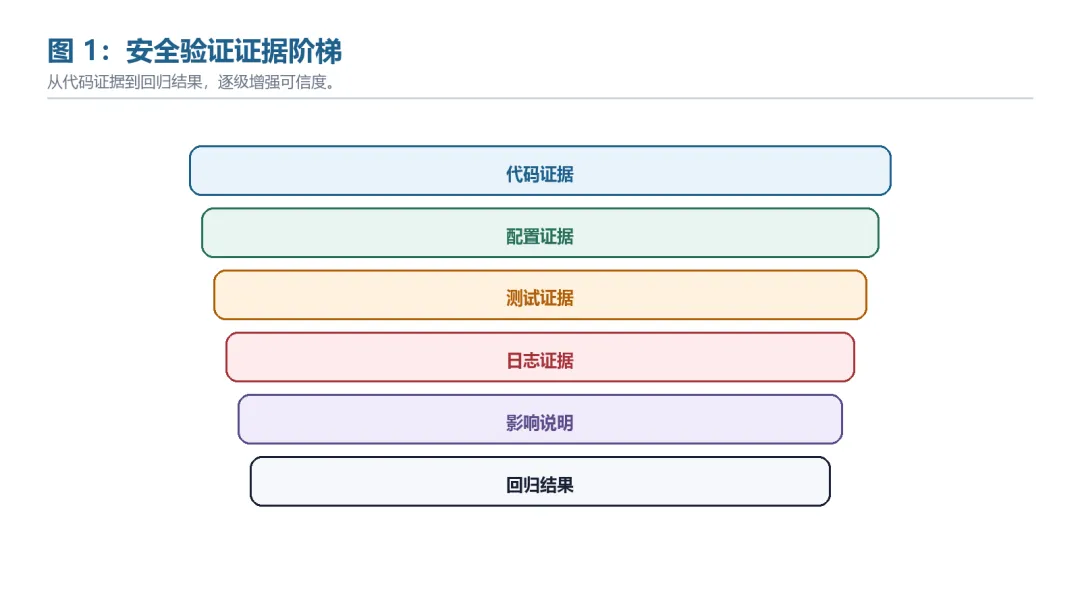
图 1:安全验证证据阶梯
核心要点:越接近实操的内容,越要问一句:这段材料是为了修复,还是会帮助复用攻击?
证据阶梯:从代码线索到可关闭工单
安全团队经常遇到两种极端:一种报告只有“疑似漏洞”,研发无法修;另一种报告给了过多可复用细节,扩散后风险更高。证据阶梯可以把二者区分开。
阶梯 | 证据类型 | 说明 | 是否足以定性 |
1 | 代码证据 | 入口、危险操作、缺失校验 | 通常不足 |
2 | 配置证据 | 认证、权限、功能开关 | 增强可信度 |
3 | 测试证据 | 授权环境中的最小化测试 | 可支持定性 |
4 | 日志证据 | 服务端观察到的副作用 | 支持影响判断 |
5 | 影响说明 | 数据、权限、可用性或业务影响 | 支持优先级 |
6 | 回归结果 | 修复后测试和规则通过 | 支持关闭 |
AI 可以帮助把材料整理到这个阶梯上,但不能为了“证明更充分”而输出危险操作细节。
边界:可以写什么,不写什么
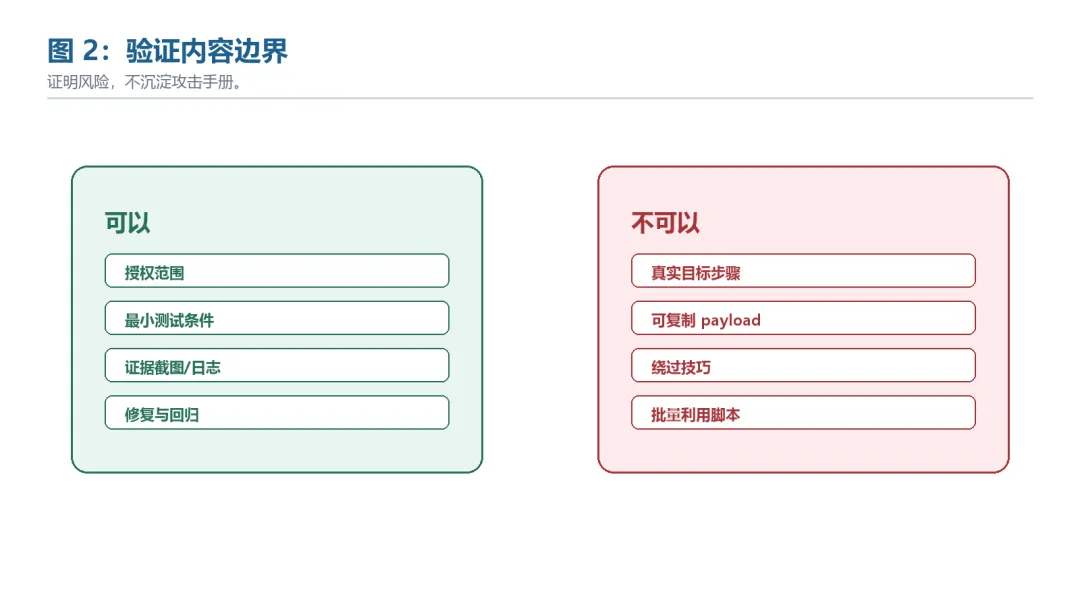
图 2:验证内容边界
内容类型 | 可以写 | 不写 |
授权范围 | 系统、版本、环境、账号、时间窗口 | 未授权目标和第三方资产 |
复现条件 | 抽象条件、最小测试前提、观察结果 | 可直接复制的 payload |
影响证明 | 数据越权、权限绕过、程序异常或业务错误 | 提权、持久化、横向移动步骤 |
修复建议 | 权限检查、输入校验、边界约束、补测试 | 绕过修复或对抗检测技巧 |
报告交付 | 证据链、风险等级、回归结果 | 批量利用脚本 |
核心要点:内部文档也会流转,越具体的验证材料越要有边界。
实战用例一:权限问题如何证明风险
假设审计发现一个对象归属检查缺失。验证材料不需要写成外部攻击教程。更合适的写法是:在授权测试环境中,用两个测试身份和两条测试数据证明权限边界未生效;记录服务端日志、返回差异和业务影响;给出修复点和回归断言。
验证环节 | 应写内容 | 目的 |
授权环境 | 测试系统、测试账号、数据范围 | 说明边界 |
最小条件 | 需要两个主体和一个跨主体对象 | 说明触发前提 |
观察结果 | 权限边界未被拒绝或副作用发生 | 证明风险 |
影响说明 | 哪类数据或动作受影响 | 支持定级 |
修复回归 | 增加对象归属检查和回归测试 | 关闭问题 |
这足以让研发修复,也足以让管理层理解风险,但不会把材料变成可滥用步骤。
实战用例二:异常终止如何判断安全影响
异常终止类问题也需要边界。报告应该写清组件、版本、授权测试环境、异常类型、重复性、可能影响和修复建议。对于输入材料,只保留修复所需的抽象结构和最小化说明,不沉淀可直接滥用的内容。
判断维度 | 需要回答 | AI 可辅助 |
重复性 | 是否稳定触发同一根因 | 汇总重跑结果 |
影响范围 | 影响单进程、服务可用性还是数据安全 | 解释日志和栈 |
可达性 | 生产是否会调用该解析路径 | 关联配置和调用图 |
补偿控制 | 是否有输入限制、隔离或限流 | 整理控制项 |
修复验证 | 修复后是否重跑通过 | 生成回归说明 |
报告解剖:一份合格验证报告长什么样
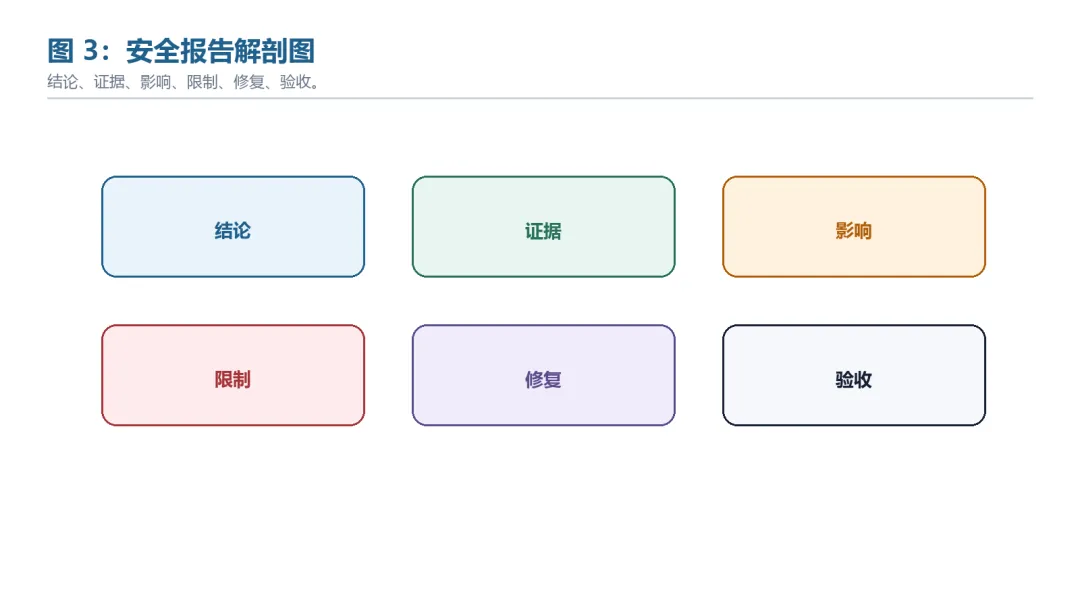
图 3:安全报告解剖图
模块 | 说明 | 验收标准 |
结论 | 问题类型、影响对象、严重性 | 结论明确但不过度夸大 |
证据 | 代码、配置、测试和日志 | 可复核 |
影响 | 权限、数据、可用性或业务后果 | 与证据一致 |
限制 | 未覆盖范围和不确定性 | 不隐藏假设 |
修复 | 建议改哪里、补什么测试 | 研发可执行 |
验收 | 回归测试和关闭条件 | 能关闭工单 |
图 4:攻防验证交接链路
影响评估:不要只看“能不能复现”
风险定级要看权限、数据、可用性、可达性、可重复性和补偿控制。AI 可以帮助整理维度,但不能替代安全负责人做最终判断。
图 5:影响评估矩阵
维度 | 低风险信号 | 高风险信号 |
权限 | 需要高权限或内部角色 | 普通用户可触达敏感动作 |
数据 | 无敏感数据或仅测试数据 | 涉及客户、财务、身份或密钥 |
可用性 | 单次失败影响有限 | 可导致核心服务不可用 |
可达性 | 仅开发环境或关闭功能 | 生产默认路径可达 |
可重复 | 偶发且条件苛刻 | 稳定可重复 |
补偿控制 | 有网关、限流、隔离 | 无有效控制 |
核心要点:能复现只是开始,能解释影响和修复才是结束。
落地清单:验证报告至少检查 10 项
编号 | 检查项 | 合格标准 |
1 | 授权范围 | 环境、账号、数据和时间窗口明确 |
2 | 最小化 | 只保留修复所需证据 |
3 | 不沉淀攻击材料 | 不写可复制 payload、绕过技巧和批量脚本 |
4 | 证据完整 | 代码、配置、测试和日志至少覆盖关键判断 |
5 | 影响一致 | 风险等级与证据匹配 |
6 | 限制说明 | 未验证范围和不确定性明确 |
7 | 修复建议 | 对应具体边界、校验或权限控制 |
8 | 回归测试 | 有明确关闭条件 |
9 | 人工复核 | 高危问题由安全负责人确认 |
10 | 流转控制 | 报告访问权限和脱敏规则明确 |
五个常见问题,直接给答案
内部文档能不能写更细?
可以写更细的证据、影响和修复,但不应该沉淀可复用攻击材料。内部文档也可能被转发、截图或进入知识库。
PoC 是否一定不能写?
在授权实验环境里可以有最小化验证思路和回归测试,但正式报告应避免可直接复制的攻击步骤和 payload。
研发说“不复现不修”怎么办?
给最小化证据、服务端日志、影响说明和回归断言,而不是给攻击教程。
AI 适合写验证报告吗?
适合整理证据、生成报告草案和修复建议,但高危结论必须由人复核。
最容易被忽略的边界是什么?
最容易忽略的是报告流转边界。验证材料需要访问控制、脱敏和最小化。
最后的判断
攻防验证的真正目标,是让组织更快修复风险,而不是让风险材料更容易传播。AI 可以让报告更完整、更清晰,但也必须被安全边界约束。
值得收藏的一句话:好的验证报告让漏洞更容易被修复,而不是让攻击更容易被复用。
专业术语注释
AI:人工智能 / 让机器执行理解、生成、判断或决策等智能任务的技术统称。
PoC:概念验证 / 用最小示例证明某个风险或能力存在。
Exploit:利用 / 把漏洞变成可执行攻击效果的过程或代码。
Payload:载荷 / 触发某种行为或验证某个问题的输入内容。
参考资料
·[1] Google Project Zero, Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models https://projectzero.google/2024/06/project-naptime.html
·[2] Google Project Zero, From Naptime to Big Sleep https://projectzero.google/2024/10/from-naptime-to-big-sleep.html
·[3] Google Security Blog, AI-Powered Fuzzing: Breaking the Bug Hunting Barrier https://security.googleblog.com/2023/08/ai-powered-fuzzing-breaking-bug-hunting.html
·[4] OSS-Fuzz, LLM target generation https://google.github.io/oss-fuzz/research/llms/target_generation/
·[5] GitHub CodeQL Documentation https://codeql.github.com/docs/
·[6] GitHub CodeQL, Data flow and taint tracking https://codeql.github.com/docs/writing-codeql-queries/about-data-flow-analysis/
·[7] Semgrep Docs, Semgrep Code https://semgrep.dev/docs/semgrep-code/overview
·[8] DARPA, AI Cyber Challenge https://www.darpa.mil/research/programs/ai-cyber
·[9] MITRE CWE https://cwe.mitre.org/
·[10] NIST SP 800-218, Secure Software Development Framework https://csrc.nist.gov/pubs/sp/800/218/final
·[11] OWASP Top 10 for LLM Applications https://owasp.org/www-project-top-10-for-large-language-model-applications/
