 夜雨聆风
夜雨聆风AI 审稿 · 编辑部排序权
一份完整的 AI 审稿意见,可能正是编辑部最难处理的稿件现场
AI 能把问题列满,但编辑部必须判断哪一个问题真正改变论文命运。
核心判断
能把退修清单写满的,不一定是审稿人;能对问题排序并承担后果的,才是编辑部不能交出去的权力。
编辑部最难处理的,往往不是空白审稿意见。
空白意见至少暴露得很直接:审稿人没有进入论文,编辑可以补审,可以换人,也可以把这份意见从决策链里剔出去。
更难的是另一种意见。它很长,分点清楚,语气克制,先肯定贡献,再列出方法、实验、图表、参考文献、语言表达上的问题。作者看了觉得“老师很认真”,编辑看了也很难马上说它不合格。
但真正的问题藏在后面:这份意见到底有没有抓住影响结论的缺陷?所谓“创新不足”,有没有和已有文献对上?十几条修改建议里,哪些是必须回应的重大问题,哪些只是顺手写下的格式意见?
PRISM 这篇新论文,正好把这个现场摊开了。
论文题名是《PRISM:面向大语言模型审稿人的多维评测基准》。作者把五个 AI 审稿系统放到同一张桌上:TreeReview、Reviewer2、SEA、DeepReview、CycleReviewer,再拿人类审稿人作基线,评测材料来自 ICLR、ICML、NeurIPS 的论文和评审材料。
结果有点刺眼。
在“关键缺陷召回”上,Reviewer2 得分 0.591,人类是 0.343;在“建设性反馈”上,DeepReview 得分 0.634,人类是 0.566;在“新颖性评估”上,SEA 得分 0.833,人类是 0.787。
原文证据 01
表 2 把争议放到了台面上:AI 在若干单项超过人类基线
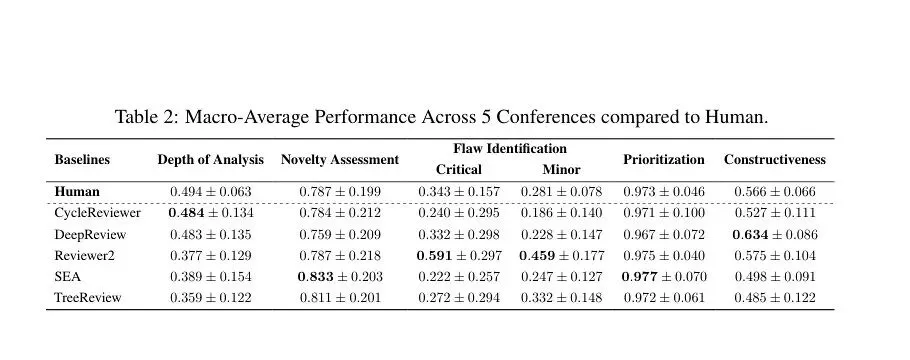
PRISM 论文表 2:五类 AI 审稿系统与人类审稿人在多维指标上的宏观平均表现。
也就是说,在若干单项上,AI 不只是“像审稿人”,还超过了人类基线。
可论文并没有把它们推上审稿席。作者给出的建议是“定向组合部署”,把这些系统作为人类主导流程里的“专项副驾驶”,而不是让它们成为“自主审稿人”。
读论文时最关键的一处转折
单项胜出并不等于获得审稿权。PRISM 的真正价值,是把“AI 审稿人”拆回一组可以被编辑部管理的审稿动作。
这个反差,才是科技期刊编辑部真正该看的一点:AI 已经能把问题列满,甚至能扫出更多关键缺陷,但编辑部更需要重新拿回排序权和责任权。
01 · 现场进入
别再问它写得像不像审稿人
PRISM 最有价值的地方,是它拒绝把审稿意见当成一段普通文本来打分。
论文明确反对用 ROUGE、BLEU 这类表层相似度指标评价 AI 审稿,也反对笼统地让另一个大模型给一份审稿意见打总分。原因并不复杂:这些做法容易把“语言流畅”和“科学严谨”混在一起。
流畅,不等于严谨。
编辑部对这件事并不陌生。一份意见可以写得非常顺:摘要准确,优点客气,不足分条,建议具体。可是,语言一顺,风险反而会被盖住。它可能把“实验设计不足”写成一句空话;可能把“创新性不够”写成没有文献支撑的判断;也可能在一堆表达建议里,轻轻带过真正影响结论的方法漏洞。
所以 PRISM 没有问“这份意见像不像人写的”。它把审稿质量拆成四个维度:分析深度、新颖性评估、缺陷识别与重大问题排序、多维建设性。
换成编辑部语言,就是四个检查口:有没有进入方法和证据;有没有把新颖性判断放进已有文献;有没有找出关键缺陷并排好主次;有没有给作者一条能执行的修改路径。
坦白讲,这个拆法比很多“AI 审稿能不能替代人类”的讨论更实用。因为编辑部每天面对的不是抽象的人机竞赛,而是一份份需要判断是否可用、是否可信、是否能进入退修意见的文本。
问题不在于 AI 能不能写。
问题在于,写出来之后,谁来判断它说的哪一句真正重要。
02 · 证据冲突
最冲击编辑的,不是建设性,而是关键缺陷召回
论文表 2 里最容易让编辑停顿的数字,是 Reviewer2 的关键缺陷召回。
0.591,对人类的 0.343。
这个差距不能被解释成“AI 更会审稿”。但它足以提醒编辑部:某些 AI 系统已经很像一台高敏感度扫描仪,能把稿件里可能被人类审稿人在时间压力下漏掉的问题扫出来。
这件事有现实意义。
现在很多编辑部真正头疼的,不是完全没有审稿意见,而是意见质量不稳定。有的审稿人能抓住方法和证据链条,有的审稿人只盯文字和图表;有的意见很短,却击中要害;有的意见很长,却没有主问题。编辑要在这些意见之间重新辨认:哪些关系到录退,哪些只关系到退修表达。
Reviewer2 这类系统如果放在送审前、外审意见返回后,做一轮缺陷预扫描,是有价值的。它可以提醒编辑:这篇稿件是否还有没有被提到的关键漏洞;现有审稿意见有没有过于轻描淡写;退修清单里是否缺了真正需要作者回应的问题。
但扫描仪不是审稿人。
论文也给了边界。Reviewer2 的幻觉率约 3.3%,CycleReviewer 约 18.5%。好消息是,这些幻觉只集中在次要问题上,论文没有发现系统凭空编造致命方法学缺陷。
原文证据 03
虚假问题没有变成致命缺陷,但仍会污染退修清单
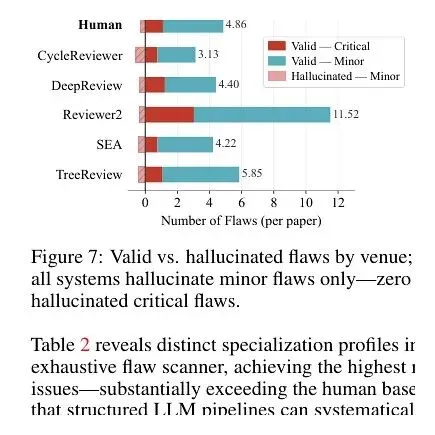
PRISM 图 7:不同系统提出的有效缺陷与虚假缺陷数量,虚假缺陷主要集中在次要问题。
这当然让人松一口气。
可次要问题也不是无害的。一个错误的小问题如果进入退修意见,会让作者多写一段无效回应;十个错误的小问题叠在一起,就会改变整份退修意见的重心。编辑部不能因为“没有编造致命缺陷”,就默认每一条小问题都可以发给作者。
AI 能多扫,不代表编辑可以少判。
03 · 文献裁量
“更有文献支撑”,不等于更懂原创性
SEA 的结果更容易被误读。
在新颖性评估上,SEA 得分 0.833,人类是 0.787。这个数字看上去很像一句诱人的结论:AI 比人类更会判断创新性。
PRISM 自己没有这么说。
它衡量的是审稿意见中的新颖性判断,能否和检索到的已有文献证据对上。换句话说,它看的是“这条新颖性判断有没有可检索文献支撑”,不是在宣布系统真正理解了论文的原创贡献。
更微妙的数字在图 5。SEA 对“具有新颖性”的认可比例是 79%,人类是 59%。这意味着 SEA 更容易认可作者的新颖性主张。它可能更擅长为一个判断找到支撑材料,却未必更擅长主动拆穿“看起来很新”的贡献。
原文证据 02
SEA 的高分不能简单理解为“更懂原创性”
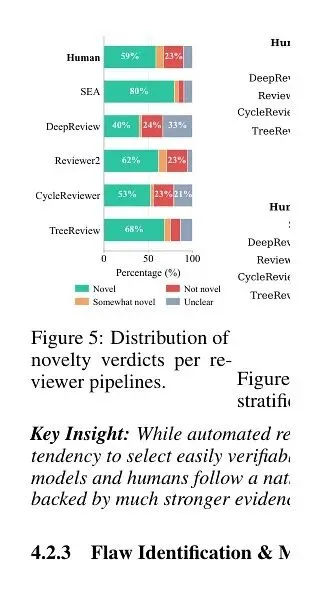
PRISM 图 5:不同系统对“新颖性”的判断分布,SEA 对新颖性的认可比例高于人类审稿人。
这对科技期刊很关键。
我们在处理投稿时,经常会看到作者把“应用对象换了一个场景”“指标组合做了一次调整”“模型套到一个新数据集”包装成创新。审稿意见如果只是说“有一定创新性”,还给了几篇相关文献作陪衬,表面上更完整,实际可能放过了最该追问的问题:这项工作相对已有研究,到底新增了什么不可替代的知识?
所以笔者更愿意把 SEA 的高分理解为一种辅助能力:它能帮助编辑检查新颖性判断有没有文献锚点。
但原创性裁量,不能交出去。
更有文献支撑,不等于更懂原创性。这句话要写进编辑部的 AI 使用边界里。
04 · 排序权
格式问题写得越认真,越可能淹没方法问题
PRISM 里最像编辑部日常的一处细节,是 TreeReview 的“表层陷阱”。
论文提到,TreeReview 约 24% 的工作量放在格式问题上。它不是没有工作,它很努力;问题是努力错了位置。格式、呈现、文字组织被写得太多,方法学严谨性被挤到了后面。
这太像很多真实审稿意见了。
前半页是图表编号、参考文献格式、英文表达、章节结构;中间夹着一句“实验设计还需加强”;后面又回到术语、排版和文字。作者拿到这样的意见,最自然的反应是改格式、润色语言、补几句说明。真正需要补实验、重算数据、重写方法的地方,反而被淹没了。
AI 会把这个问题放大。
人类审稿人写格式意见,有时还会显得零散;AI 写格式意见,可以写得很整齐,很完整,很像一份成熟的退修清单。清单越漂亮,编辑越要小心。
因为退修意见不是问题堆叠,而是问题排序。
PRISM 把“缺陷识别”和“重大问题排序”放在同一维度,正是抓住了这件事。找出多少问题,只是第一步;把重大问题放在小问题前面,才决定作者会怎样理解这轮退修。
论文表 2 里,各系统和人类在“优先级排序”上都很接近:人类是 0.973,Reviewer2 是 0.975,SEA 是 0.977,其他系统也在 0.97 左右。放到当前评测里,“把重大问题排在前面”已经不是最能拉开差距的地方。
真正拉开差距的,是系统找到了什么问题,又漏掉了什么问题。
编辑部要盯住这一点。AI 生成的长清单,只能作为材料;能否进入退修意见,要经过人工重排。
05 · 责任边界
会给方案,不等于能裁决
DeepReview 的建设性分数也很值得看。
0.634,对人类的 0.566。再看更细的“解决方案提供”维度,DeepReview 是 0.784,人类是 0.470。
原文证据 04
会提供修改方案,是沟通能力,不是裁决能力
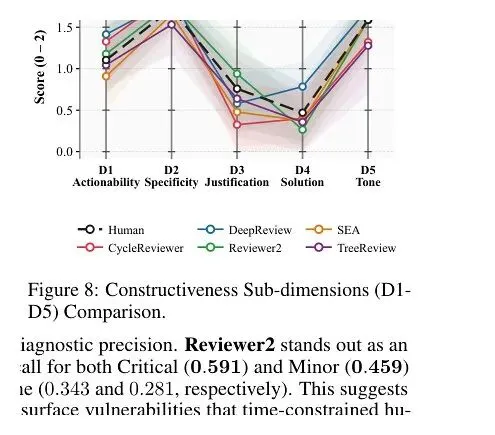
PRISM 图 8:建设性反馈的五个子维度,DeepReview 在行动性和解决方案提供上表现突出。
这组数字有点扎心。很多人类审稿意见确实擅长指出“不足”,但不擅长告诉作者“怎么改”。“理论阐释不充分”“实验还需补充”“创新性有待加强”,这些话单独放在退修意见里,作者很难知道下一步该做什么。
DeepReview 的优势,恰恰在这里。它更会把批评翻译成行动:补哪个对照实验,解释哪个变量,重写哪一段论证,把哪类文献纳入比较。对编辑部来说,这是一种很实际的能力。
尤其在退修前,编辑经常要把几位审稿人的意见重新整理成一封可执行的决定信。AI 可以帮忙把零散批评改写成清单,把重复意见合并,把模糊要求具体化,把语气调整到专业而不过度刺激作者。
这不是小事。
但它仍然不是裁决。
会给方案,说明它适合草拟建设性反馈;会把意见写得温和、具体、可执行,说明它适合帮助编辑沟通。它不能据此获得录退判断权,也不能直接决定哪些方案必须由作者执行。
一个能写出好退修建议的系统,仍然可能不懂这篇稿件是否值得退修。
这条边界,编辑要守住。
06 · 流程收束
未来的 AI 审稿,不该是一个按钮
读完 PRISM,笔者更愿意把它理解为一张流程拆解图,而不是一张模型排行榜。
Reviewer2 适合做缺陷扫描。DeepReview 适合做退修建议草拟。SEA 适合做新颖性文献支撑核查。CycleReviewer 和 DeepReview 在分析深度上接近人类,人类仍以 0.494 高于 CycleReviewer 的 0.484 和 DeepReview 的 0.483。
没有一个系统可以把这些位置全部坐稳。
这也是论文结论中“定向组合部署”的意思:不是挑一个“最强 AI 审稿人”,而是在人类主导的流程里,把不同系统放进不同辅助岗位。
对国内科技期刊来说,真正可操作的入口并不神秘。
送审前,可以做材料完整性和明显缺陷预扫描,帮助编辑判断外审重点。审稿中,可以把多份意见拆成问题单元,归并为方法、数据、理论、实验、表达、格式等类别,并标出冲突意见。退修前,可以把审稿意见转成作者可执行清单。涉及新颖性争议时,可以用检索增强工具检查某条判断是否有相似研究支撑。
但这些动作都必须有护栏。
未经授权的保密稿件不能随意上传。AI 输出不能自动进入录退建议。给作者的正式意见必须由编辑人工复核。涉及重大方法缺陷、伦理风险、学术不端线索的判断,不能由模型单独完成。编辑部还要记录:谁触发了 AI,输入了什么,输出保存在哪里,哪些内容被采纳,哪些内容被删除。
如果这些问题说不清,AI 就会从助手变成隐性审稿人。
更麻烦的是,出了问题时,没有人能说清责任在哪里。
07 · 结尾判断
编辑部真正要接住的是排序权
PRISM 没有给 AI 审稿发通行证。
它更像是在提醒编辑部:审稿已经被拆成一组更细的动作。找缺陷、查文献、排优先级、写建议、控语气、做裁决。前面几个动作,AI 会越来越强;有些动作,已经在特定评测里超过人类基线。
这不是坏消息。
但它会改变编辑的工作重心。过去编辑更多是在“找审稿人”;以后还要判断“哪些审稿动作可以让机器预处理,哪些判断必须由人留下来”。过去编辑担心意见不够;以后还要担心意见太满、太顺、太像正确答案。
一份完整的 AI 审稿意见,最容易让人放松警惕。它把问题写满了,把建议写顺了,把语气调好了,看起来已经替编辑完成了很多工作。
可审稿最难的部分,从来不是把清单写长。
而是知道哪一个问题真正改变论文命运。
能把退修清单写满的,不一定是审稿人;能对问题排序并承担后果的,才是编辑部不能交出去的权力。
参考来源
1. PRISM: A Multi-Dimensional Benchmark for Evaluating LLM Peer Reviewers
https://arxiv.org/abs/2605.26730
2. PRISM 项目页
https://prism-benchmark.github.io/
3. PRISM arXiv HTML 版本
https://arxiv.org/html/2605.26730v2
