 夜雨聆风
夜雨聆风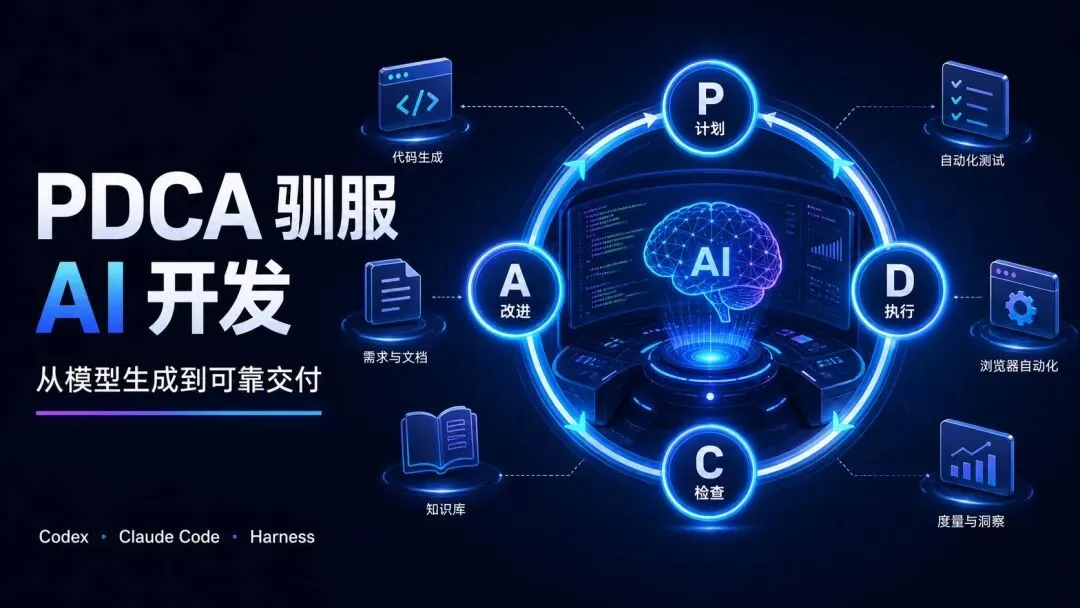
适用场景:AI 编程、AI 文档撰写、AI 自动化测试、复杂任务拆解、团队 AI 开发流程建设。
核心工具:Codex、Claude Code。核心方法:PDCA + TDD + Harness Engineering。
核心观点:AI 的输出是概率性的,但真实交付需要确定性;PDCA 是人类管理 AI 工作过程的最小闭环,Harness 是让这个闭环可执行、可验证、可沉淀的工程系统。
如果你已经开始用 Codex、Claude Code 或其他 AI 编程工具,大概率会遇到一个矛盾:AI 生成很快,但你不敢直接信;AI 看起来懂了,但真正交付时仍然需要人反复兜底。
这篇文章想解决的不是“怎么写一个更花哨的 prompt”,而是回答一个更底层的问题:如何用一套人类已经验证过的持续改进方法,把 AI 从一次性生成工具,变成可控、可验收、可复用的交付系统。
一、Why:先讲清楚 PDCA 到底是什么
在讨论 AI 开发之前,必须先把 PDCA 讲清楚。否则后面所有“用 PDCA 管 AI”的说法,都容易变成管理学口号。
PDCA 常被称为戴明环,也常被放在质量管理和持续改进语境中讨论。更严格地说,它与 Shewhart 的质量改进循环和 Deming 对质量管理思想的传播有关;在工程实践中,大家通常把 PDCA 当作“计划—执行—检查—改进”的闭环方法来使用。本文不做学术考据,重点讨论它在 AI 开发里的工程化用法。
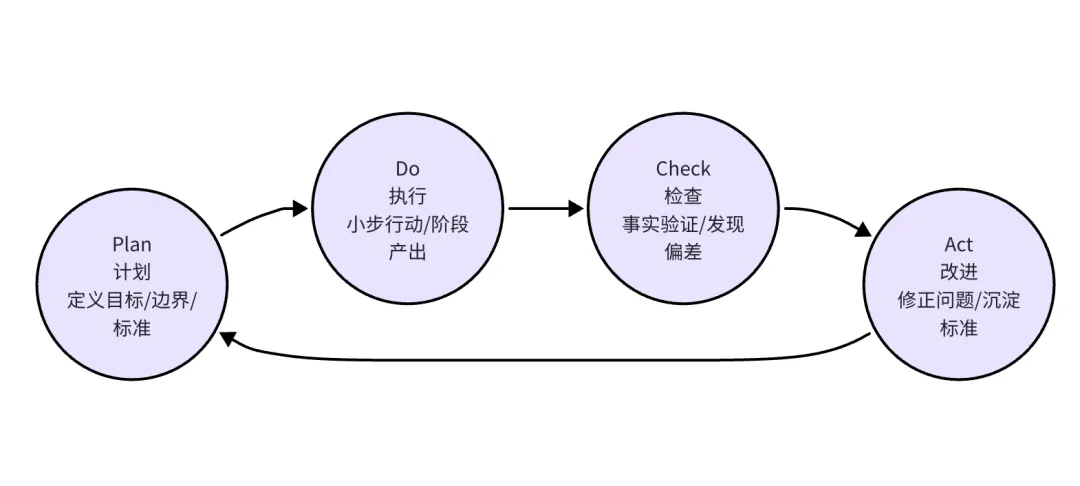
PDCA 把一个工作过程拆成四个连续环节:
图 1:PDCA 是一个持续循环,不是一次性线性流程。
P:Plan,计划D:Do,执行C:Check,检查A:Act,处理与改进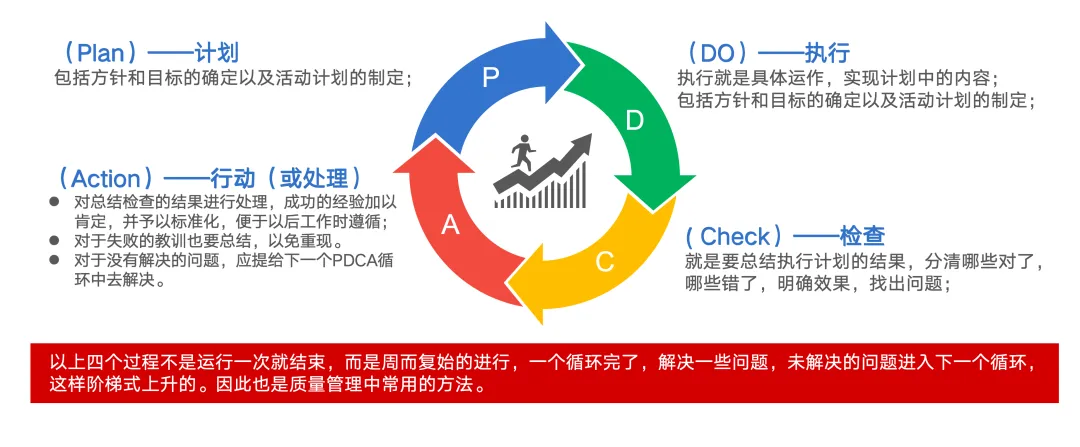
它的核心不是“做计划”这么简单,而是:用一个闭环,把目标、行动、验证和改进连接起来,让工作不是一次性完成,而是持续变好。
1. Plan:先定义目标、边界和标准
Plan 是计划阶段。它回答的是:
- 我们到底要解决什么问题?
- 当前现状是什么?
- 目标结果是什么?
- 哪些范围要做,哪些范围不做?
- 成功标准是什么?
- 需要什么资源?
- 风险在哪里?
- 如何验证结果?
在人类工作环境中,Plan 的价值是防止团队一上来就开干。很多项目失败,不是因为执行能力差,而是因为一开始目标就没定义清楚:不同人对“完成”的理解不同,对优先级的判断不同,对风险边界的感知也不同。
Plan 阶段的本质,是把模糊目标变成共同契约。
例如在软件开发里,Plan 不是一句“做一个登录功能”,而应该包含:登录方式、错误码、风控规则、接口定义、测试口径、上线范围、回滚方案。只有这样,后续执行才有判断依据。
2. Do:按计划小步执行
Do 是执行阶段。它回答的是:
- 按照计划,先做哪一步?
- 谁来做?
- 产出什么?
- 做到什么程度进入下一步?
在人类工作中,Do 不是“盲目把所有事情做完”,而是按计划推进,最好能够分阶段交付。越复杂的任务,越不能一次性梭哈。因为一次性做得越多,越难判断问题发生在哪里,也越难纠偏。
例如开发一个新功能,合理的 Do 不是一次性写完所有代码,而可能是:先补接口协议,再写测试,再实现核心逻辑,再接入页面,再联调,再验证边界。
3. Check:用事实检查结果
Check 是检查阶段。它回答的是:
- 当前结果是否符合 Plan?
- 是否达到了验收标准?
- 有没有偏离目标?
- 有没有遗漏边界条件?
- 有没有新的风险?
这是 PDCA 中非常关键的一步。因为只要没有 Check,前面的 Plan 和 Do 很容易变成“我以为完成了”。
在人类环境中,Check 可以是测试、评审、数据看板、验收会议、客户反馈、代码 review、上线监控、抽样检查。它的核心是:不要用主观感觉判断完成,要用事实和证据判断完成。
例如一个功能开发完成,不是研发说“我写完了”就完成,而是要看:测试是否通过、线上是否稳定、用户路径是否可用、埋点是否正确、异常是否可回滚。
4. Act:处理问题,沉淀改进
Act 是处理与改进阶段。它回答的是:
- 如果检查不通过,怎么修?
- 如果检查通过,经验如何标准化?
- 哪些流程应该保留?
- 哪些错误下次要避免?
- 哪些能力可以沉淀成模板、规范或工具?
很多人以为 PDCA 到 Check 就结束了,其实不是。Act 才是持续改进的关键。
如果结果不好,Act 要做纠偏;如果结果好,Act 要做标准化。否则每一次成功都只是偶然,每一次失败也不会变成经验。
在人类组织中,Act 可能表现为:更新流程、补充测试、修改 SOP、沉淀 checklist、完善培训、调整组织分工、优化工具链。它让团队下一次不是从零开始,而是站在上一次的经验上继续做。
5. PDCA 在人类环境中是如何工作的
把四步连起来,PDCA 的工作方式是这样的:
先定义目标和标准 -> 按计划执行 -> 用事实检查结果 -> 修正问题并沉淀经验 -> 进入下一轮更好的计划它不是线性的,而是循环的。
Plan -> Do -> Check -> Act -> 新一轮 Plan这也是 PDCA 最重要的思想:任何复杂工作都不应该期待一次做对,而应该设计一个能持续变好的闭环。
6. 一个普通团队里的 PDCA 是怎么跑的
举一个很普通的例子:团队发现某个功能上线后线上 bug 偏多。
如果没有 PDCA,常见反应是“大家下次注意一点”。这句话基本没有用,因为它没有改变系统。
用 PDCA 来做,会变成这样:
- Plan:先定义问题。比如最近 4 周线上 bug 中,60% 来自需求理解偏差和边界测试遗漏;目标是下个迭代把这类问题降低一半。
- Do:执行一个小改动。比如所有需求进入开发前,必须补一页验收标准;所有后端接口必须补异常场景测试。
- Check:用事实检查。比如统计下个迭代线上 bug 类型、测试遗漏数、返工次数。
- Act:如果有效,就固化到研发流程和 checklist;如果无效,就调整方案,比如增加设计评审或引入自动化测试。
基础循环:
基于问题的 N 轮循环的:
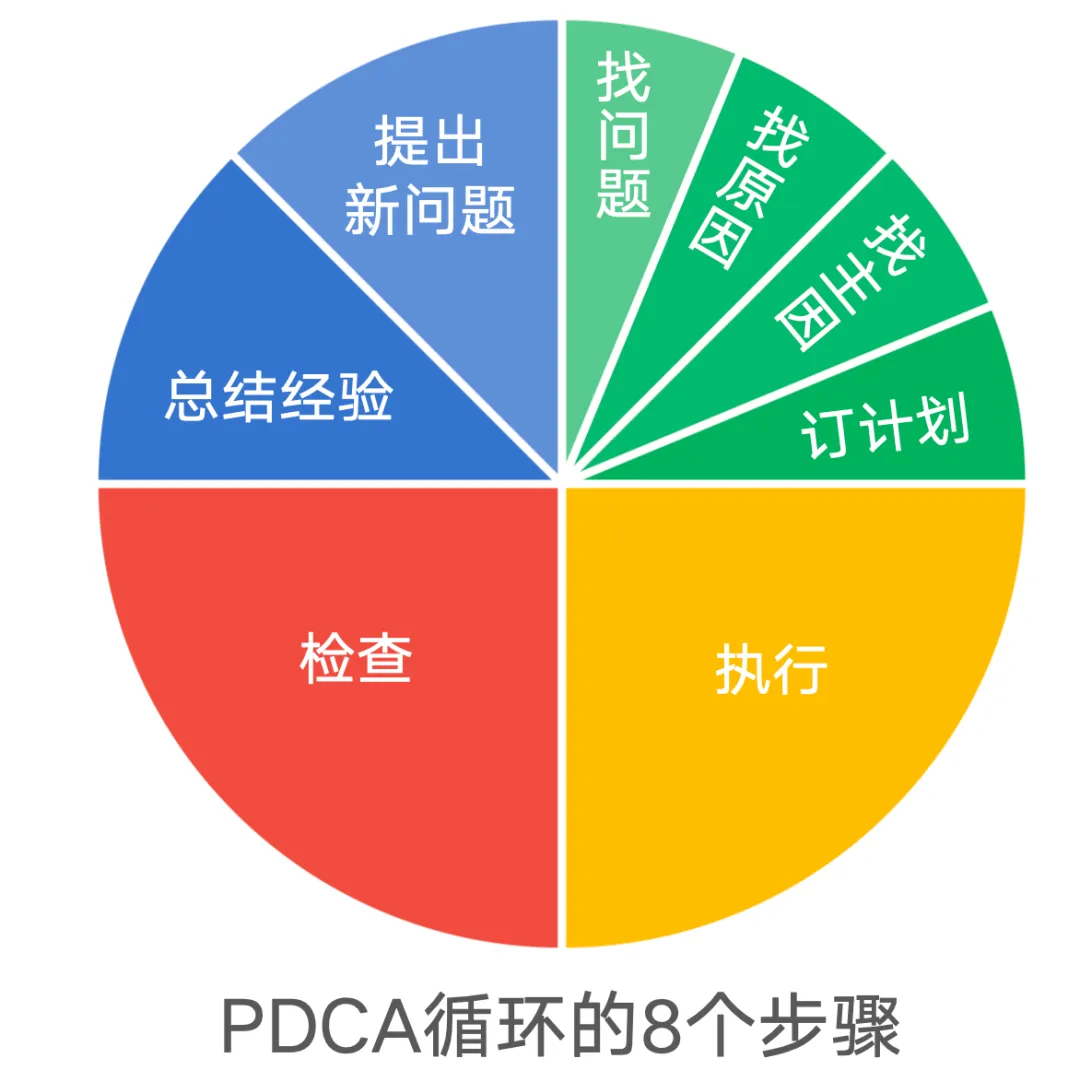
迭代的八步骤:

这就是 PDCA 在人类环境中的真实工作方式:不是喊口号,而是通过“目标—动作—证据—改进”改变系统行为。
这个思想迁移到 AI 开发里,正好击中了 AI 工作最大的痛点。
二、为什么 AI 开发更需要 PDCA
很多人第一次使用 Codex、Claude Code 或类似 AI 编程工具时,会被它的速度震撼:它可以几秒钟生成一个函数,几分钟写出一组测试,十几分钟搭出一个页面,甚至能根据一段需求写出完整技术方案。
但进入真实工程后,很快会遇到另一个问题:它写得很快,但不一定可靠。
AI 开发真正的问题不是“它不会写”,而是“它太会写”。
它会在信息不足时补全上下文,会在边界不清时继续生成,会在没有验证时自信地说完成,会在你没有明确禁止时顺手修改无关文件。它的输出看起来完整、流畅、有逻辑,但未必符合真实业务和工程约束。
1. 大模型为什么容易出错
大模型不是传统程序。传统程序是确定性的:输入相同,逻辑相同,输出基本相同。大模型的工作方式更接近在上下文中预测最可能的下一个 token。它擅长根据已有语境生成连贯内容,但它并不天然知道你的真实业务边界、项目规范、历史决策和上线风险。
这带来几个特点。
第一,它擅长补全,但补全不等于事实。当上下文缺失时,大模型倾向于生成一个“看起来合理”的答案。但工程中很多信息不能靠猜。例如 API 字段、权限规则、数据库约束、线上配置、错误码规范,这些都必须来自事实源。
第二,它擅长局部合理,但不保证全局正确。一段代码单独看可能没问题,放进系统里却可能破坏架构边界、引入并发风险、绕过错误处理、漏掉审计日志,或者不符合项目已有风格。
第三,它会遗忘过程约束。多轮任务里,如果没有结构化记录,AI 很容易忘掉前面说过的限制。例如“只改这个目录”“不要新增依赖”“先写测试”“不要修改配置文件”。这不是它故意不听话,而是任务状态没有被工程化管理。
第四,它会产生工程幻觉。我们通常说 AI 幻觉,是指它编造知识。但在开发任务中,更危险的是工程幻觉:
- 声称测试通过,但其实没有运行测试。
- 调用了项目里不存在的方法。
- 假设某个环境变量存在。
- 写了测试,但测试只验证了它自己的错误假设。
- 说页面可用,但没有打开浏览器验证。
- 说文档已保存,但实际只在对话中输出。
因此,AI 任务不能只靠“相信它”。AI 任务必须有过程控制。
2. Prompt 不能解决所有问题
很多人一开始会以为,AI 做不好是因为 prompt 写得不够好。Prompt 当然重要,但只靠 prompt 不够。
复杂任务真正需要的是完整工作系统:
- 目标是否清楚?
- 上下文是否正确?
- 任务是否拆分?
- 约束是否显式?
- 是否有测试?
- 是否能检查?
- 是否能回滚?
- 是否能沉淀经验?
这正是 PDCA 的价值。
对 AI 来说,PDCA 不是管理学套话,而是一套非常实用的控制方法:
Plan:不要让 AI 猜目标。Do:不要让 AI 一次性自由发挥。Check:不要相信 AI 的完成声明,要相信验证结果。Act:不要让经验停留在一次对话里,要沉淀成模板、规则和工具。一句话说:Prompt 解决生成问题,PDCA 解决交付问题。
更进一步说,AI 开发里的 Why 可以压缩成三句话:
- AI 可以加速 Do,但不能天然保证 Plan 正确。
- AI 可以参与 Check,但不能只让它自己证明自己正确。
- AI 可以总结 Act,但经验必须落到模板、测试、规则、知识库或工具里,才算真的沉淀。
三、把 PDCA 映射到 AI 开发
在 AI 开发场景里,PDCA 可以这样映射。
| PDCA | 人类工作含义 | AI 开发中的含义 | 关键产物 |
| Plan | 明确目标、边界、标准 | 定义任务契约、上下文、限制和验收方式 | Spec、Reference、Todo、测试计划 |
| Do | 按计划执行 | 让 AI 小步生成代码、文档或测试 | Diff、Draft、Code、Test |
| Check | 检查是否达标 | 跑测试、查 diff、看日志、浏览器验证、事实核查 | Test Report、Review、Validation |
| Act | 纠偏和标准化 | 修复问题,沉淀 prompt、模板、skill、规则和知识 | Patch、Checklist、KB、Rule、Skill |
下面逐个看。
图 2:AI 任务中的 PDCA,把“模型生成”放进可验证闭环。
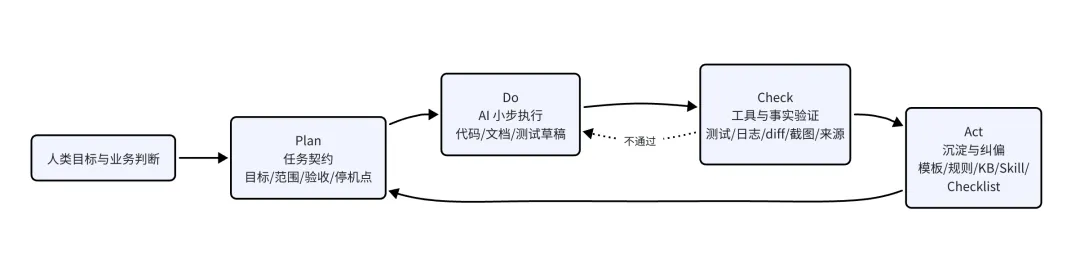
1. Plan:把需求变成 AI 可执行契约
AI 最怕模糊需求。你说“帮我做一下这个功能”,它一定会做,但它做出来的东西可能不是你要的。
更好的 Plan 应该包含:
目标:要完成什么?范围:允许改哪些文件、哪些模块?禁止:哪些不能碰?输入:需要读哪些材料?输出:最终要交付什么?验收:怎么判断完成?风险:哪些地方容易出错?停机点:遇到什么情况必须问人?例如,不要这样问:
帮我实现订单重复提交保护。而应该这样给 AI:
目标:为订单创建逻辑增加重复提交保护。范围:只允许修改 internal/order 相关代码。禁止:不修改数据库 schema,不新增外部依赖,不改 unrelated 文件。输入:读取 order service、repository、现有错误码和测试目录。输出:单元测试、实现代码、错误处理说明。验收:go test ./internal/order/... 通过;新增测试覆盖重复提交场景。风险:并发安全、缓存清理、错误码一致性。停机点:如果现有架构无法支持 5 秒窗口判断,先输出方案,不要硬改。Plan 的目的不是拖慢 AI,而是减少 AI 自由发挥的空间。
2. Do:让 AI 小步执行
Do 阶段最重要的原则是:复杂任务不要一次性梭哈。
让 AI 一次性完成太多事情,会出现几个问题:
- diff 太大,难 review。
- 错误混在一起,难定位。
- 它可能顺手重构无关代码。
- 它可能跳过测试。
- 它可能自己改变需求。
更好的方式是分 checkpoint:
阶段 1:读代码,只输出理解和方案。阶段 2:写测试,不实现。阶段 3:运行测试,确认测试失败。阶段 4:实现最小代码。阶段 5:运行测试,修复失败。阶段 6:总结风险和沉淀模板。这就是把 Do 从“自由生成”变成“受控执行”。
3. Check:验证产物,而不是验证 AI 的声明
AI 说“完成了”没有意义。真正有意义的是证据。
代码任务要看:
- 测试是否真的跑过?
- lint / typecheck 是否通过?
- diff 是否只在允许范围内?
- 是否有边界测试?
- 是否影响已有行为?
文档任务要看:
- 事实是否有来源?
- 有没有把推断写成事实?
- 结构是否符合目标读者?
- 术语是否一致?
- 是否遗漏关键风险?
页面测试任务要看:
- 页面是否真实打开?
- mock 是否正确?
- 断言是否足够强?
- 失败截图是否能解释问题?
- 是否覆盖 loading、empty、error 状态?
Check 的原则是:验收产物,不验收 AI 的自信。
4. Act:把一次任务变成下一次的资产
如果一次 AI 任务完成后什么都不沉淀,下次还是从零开始。
Act 阶段要做的是:
- 把稳定 prompt 变成模板。
- 把高频流程变成 skill。
- 把错误模式变成 checklist。
- 把事实材料沉淀到 KB。
- 把必须遵守的边界写入 rule。
- 把测试用例纳入回归。
- 把任务过程保存到 history。
真正的 AI 提效,不是一次生成更多内容,而是下一次不用从零开始。
四、从 Prompt 到 Harness:让 PDCA 真正跑起来
只有 PDCA 方法论还不够。因为如果所有 Plan、Do、Check、Act 都靠人脑记,复杂任务一多,流程还是会乱。
这时就需要 Harness。
1. Harness 是什么
可以把 Harness 理解为大模型外面的一层运行控制系统。它不负责让模型更聪明,而是负责让模型工作得更可靠。
一个完整的 AI Harness 至少包含:
- 任务规格:目标、边界、完成定义和验收标准。
- 上下文管理:哪些代码、文档、规则、历史进入上下文。
- 工具接入:CLI、浏览器、文件、数据库、Feishu、MCP 等。
- 权限控制:哪些能做,哪些危险操作要停下来。
- 执行编排:Plan、checkpoint、subagent、retry、handoff。
- 反馈验证:tests、lint、typecheck、review、browser check。
- 记忆知识:memory、KB、insight、history。
- 可观测治理:日志、报告、验证记录、审计和 finalizer。
Prompt Engineering 解决“怎么问”;Context Engineering 解决“给什么上下文”;Harness Engineering 解决“如何让 AI 稳定执行”。
| 层级 | 关注点 | 典型问题 |
| Prompt Engineering | 怎么问 | 指令是否清楚?输出格式是否明确? |
| Context Engineering | 给什么上下文 | 哪些文件、规则、历史、文档该进入上下文? |
| Harness Engineering | 如何稳定执行 | 工具、权限、状态、验证、日志和沉淀如何组织? |
PDCA 是 AI 工作的节奏;Harness 是执行 PDCA 的系统。
图 3:Harness 是模型外层的工程控制系统,让 PDCA 能被执行、验证和沉淀。
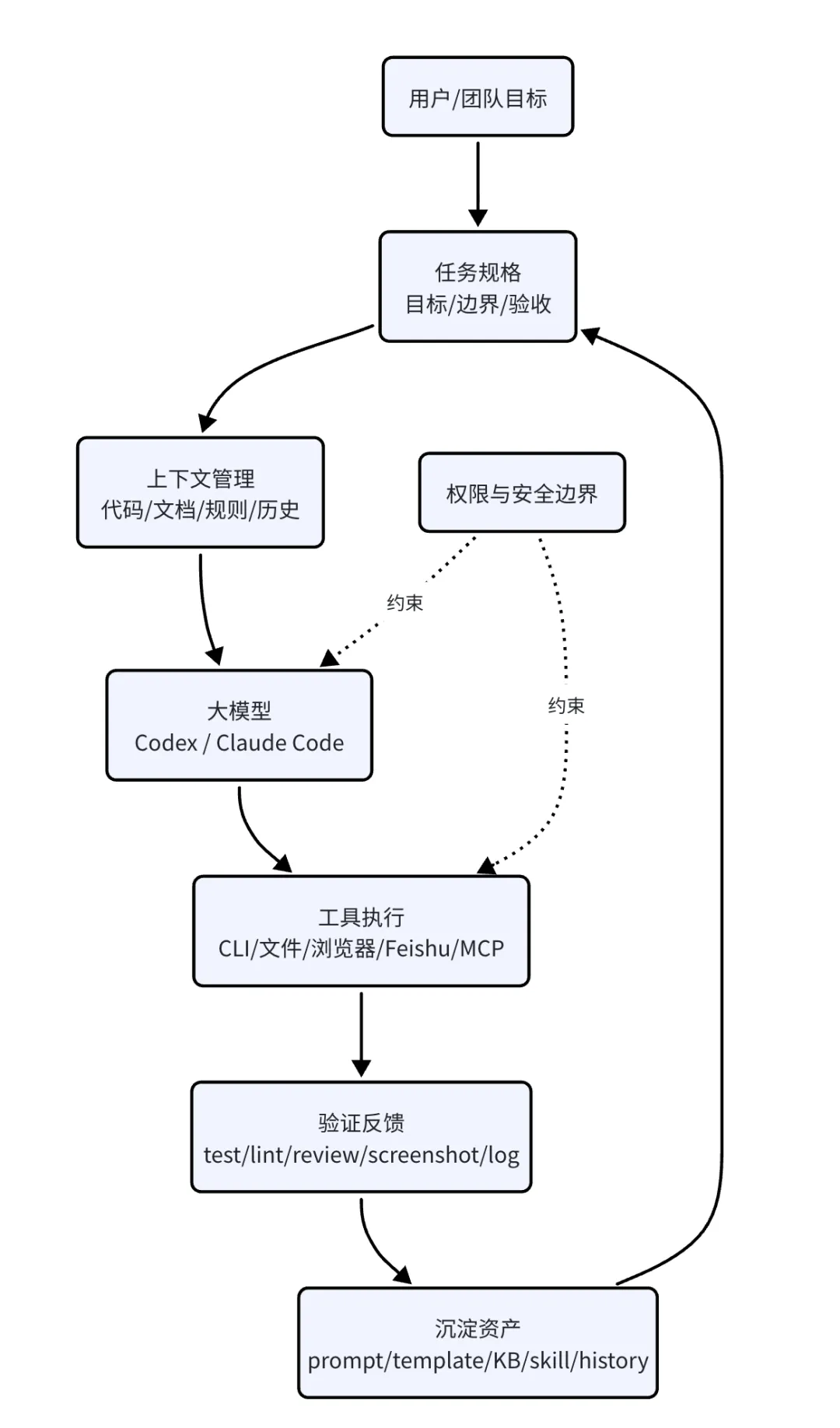
2. 为什么 Harness 对 AI 开发很重要
因为 AI 的强项是生成,不是自我约束。
没有 Harness,AI 开发常见流程是:
人提需求 -> AI 生成 -> 人肉检查 -> 发现问题 -> 继续追问 -> 上下文变乱 -> 结果不可追溯有 Harness 后,流程变成:
Plan 契约 -> AI 执行 -> 工具验证 -> 失败反馈 -> 修复迭代 -> 经验沉淀这就是从“聊天式开发”升级到“工程化 AI 开发”。
五、实战一:Claude Code + TDD 生成 Golang 代码
第一个案例讲代码开发。这里用 Claude Code 举例,因为它适合在代码仓库里长上下文阅读、修改和运行命令。
场景
我们要给 Go 服务增加一个功能:订单创建接口增加重复提交保护。
需求是:同一个用户在 5 秒内提交相同订单参数,只允许成功一次,重复请求返回明确错误码。
图 4:Claude Code + TDD 的受控开发链路。

Plan:先让 Claude Code 输出方案,不写代码
可以这样给 Claude Code:
你是 Go 后端开发助手。请按 PDCA + TDD 完成任务。当前阶段只做 Plan,不要写代码。目标:为订单创建逻辑增加重复提交保护:同一用户在 5 秒内提交相同订单参数,只允许成功一次,重复请求返回明确错误码。范围:- 只允许修改 internal/order 相关代码。- 不修改数据库 schema。- 不新增外部依赖。- 不改 unrelated 文件。请输出:1. 需要阅读哪些文件。2. 你理解的现有业务流程。3. 测试用例设计。4. 最小实现方案。5. 并发和缓存清理风险。6. 需要我确认的问题。在我确认前,不要进入实现。这一步的目的,是防止 AI 一上来就改代码。先让它读、理解、拆解、暴露风险。
Do-1:先写失败测试
确认方案后,进入 TDD 的第一步:先写测试。
按刚才确认的方案,先只写单元测试,不要实现业务代码。测试至少覆盖:1. 第一次提交成功。2. 5 秒内相同用户、相同参数重复提交失败。3. 不同用户不互相影响。4. 相同用户但参数不同不互相影响。5. 超过 5 秒后允许再次提交。写完后先停止,输出测试 diff,不要修改实现代码。TDD 非常适合约束 AI,因为测试就是机器可执行的需求。相比自然语言,测试更难被 AI 偷换概念。
Check-1:确认测试先失败
运行:
go test ./internal/order/...此时测试应该失败。如果还没实现功能测试就通过了,说明测试没有测到真实需求。
这个检查非常重要。它是在验证“测试是否有效”。
Do-2:实现最小代码
接着让 Claude Code 实现:
现在请实现最小代码,让刚才新增的测试通过。要求:- 不扩大改动范围。- 不重构无关代码。- 保持现有错误码风格。- 注意并发安全。- 完成后运行 go test ./internal/order/...Check-2:看测试,也看 diff
测试通过后,不要马上结束。还要检查:
- 是否真的运行了 go test?
- 是否只改了 internal/order?
- 是否引入全局 map 且没有锁?
- 缓存是否有 TTL 或清理策略?
- 错误码是否符合项目规范?
- 是否只覆盖 happy path?
可以继续让 Claude Code 做一次自查:
请基于当前 diff 做 code review,重点检查:1. 并发安全2. 缓存清理3. 错误码一致性4. 测试覆盖5. 是否修改无关逻辑6. 是否存在 race 风险只输出问题和建议,不要直接修改。然后人再决定是否进入修复。
如果要更工程化,可以要求它最后给出一份验收记录:
请输出本次任务验收记录:1. 实际修改文件列表。2. 新增测试列表。3. 执行过的命令和结果。4. 未覆盖风险。5. 是否需要人工 review 的点。注意:没有真实执行过的命令,不允许写成已通过。这条约束很关键。AI 很容易把“建议运行”写成“已经运行”,所以验收记录必须区分“实际执行”和“建议执行”。
Act:沉淀成团队模板
如果这个流程跑通,就应该沉淀:
- Go TDD Prompt 模板
- 后端功能开发 checklist
- 并发安全 review 清单
- 错误码规范
- 单元测试样例
- 或者沉淀成为 skills
这就是 PDCA 的 Act。一次 AI 开发不只是交付一个功能,还应该让下一次更快、更稳。
六、实战二:Codex 撰写技术文档
第二个案例讲文档。很多人让 AI 写文档时,会直接说“帮我写一篇文章”。这很危险,因为 AI 会自动补充很多看似合理、实际未确认的内容。
文档任务尤其需要 PDCA。
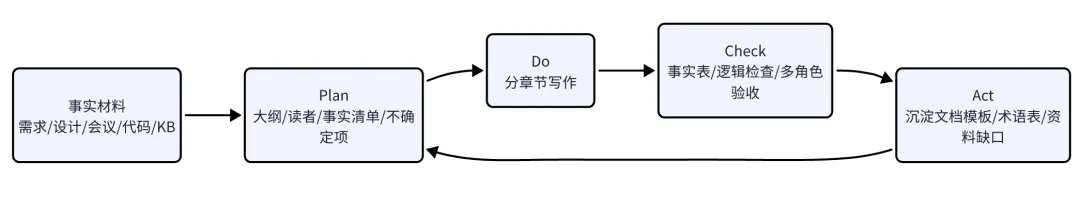
图 5:Codex 写技术文档时,重点不是“生成全文”,而是管理事实、结构和读者理解。
场景
我们要用 Codex 写一篇技术说明文档,解释“星枢泳道环境”和“星航 Feature Flag 平台”的区别、联系和落地路径。
Plan:先设计文档结构和事实清单
不要直接写正文。先让 Codex 做 Plan:
请先不要写正文,先帮我设计文档结构。目标读者:- 技术负责人- 后端/前端/测试- 产品经理目标:解释泳道和Feature Flag的区别、联系、边界和落地路径。要求:1. 先讲 Why。2. 再讲两个系统分别解决什么问题。3. 再讲它们如何组合。4. 必须给出边界:Feature Flag 不替代环境治理,泳道不替代实验平台。5. 最后给出落地路线和常见误区。请输出:- 标题建议- 文章大纲- 每节核心观点- 需要引用的事实清单- 不确定信息列表这里的关键是“事实清单”和“不确定信息列表”。这能逼迫 AI 区分事实、推断和待确认内容。
Do:分章节生成正文
确认结构后,分章节写,不要一次性输出全文。
请只写第一部分 Why,控制在 800 字以内。要求:- 面向非纯技术读者也能理解。- 不要编造现状。- 不确定处标注“待确认”。- 不展开实现细节。每完成一节,就进行一次小 Check。这样比最后一次性检查全文更稳。
Check:抽事实表
文档写完后,让 Codex 抽取事实表:
请从当前正文中抽取所有事实性表述,整理为表格:| 事实 | 来源 | 是否已确认 | 风险 |要求:- 不要把推断写成事实。- 没有来源的事实标注“待确认”。- 发现概念混用时指出。检查重点:
- 有没有把愿景写成现状?
- 有没有把推断写成事实?
- 有没有混淆星枢和星航?
- 有没有遗漏边界?
- 有没有使用不准确术语?
还可以增加一个“读者验收”检查:
请分别站在技术负责人、前端、后端、测试、产品经理视角,检查这篇文档:1. 是否能看懂两个系统分别解决什么问题?2. 是否能看懂二者边界?3. 是否能看懂落地顺序?4. 是否还有必须补充但当前缺失的信息?只输出问题,不要润色正文。这一步能防止技术文档只在作者视角自洽,却不能被不同角色使用。
Act:沉淀成文档模板或Skills
如果文档质量不错,就沉淀模板:
技术说明文档模板:1. Why2. 概念定义3. 问题边界4. 方案关系5. 分阶段建设6. 风险和误区7. 下一步以后写类似技术文档时,Plan 阶段直接复用这个模板。
七、实战三:Codex 做页面自动化测试链路
第三个案例讲页面自动化测试。这里 Codex 不只是写测试代码,还要参与测试计划、mock 设计、失败分析和回归沉淀。
场景
某个后台页面有订单列表、筛选、详情弹窗和错误提示。我们希望用 Playwright 做自动化验证。
图 6:页面自动化测试的核心,是把用户行为变成可重复验证的证据链。
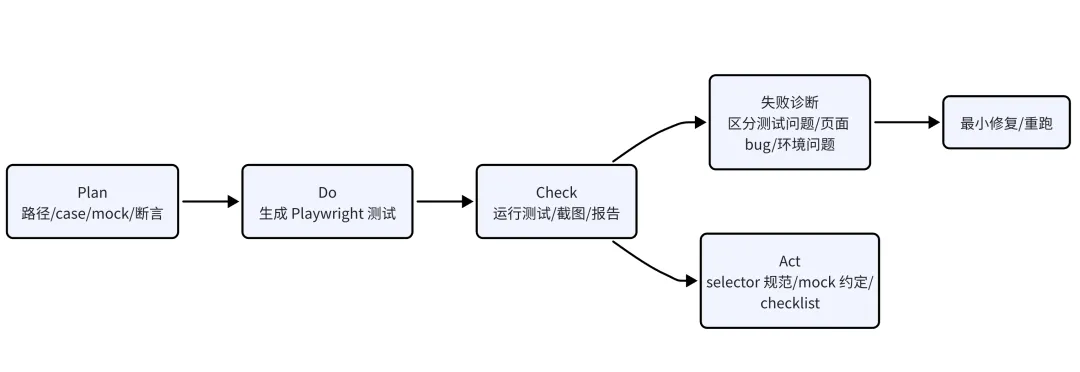
Plan:先输出测试计划
请基于当前页面代码,先输出自动化测试计划,不要写代码。目标页面:/admin/orders需要覆盖:1. 页面能正常加载。2. 默认列表请求成功。3. 按状态筛选后列表更新。4. 点击订单进入详情弹窗。5. 接口失败时出现错误提示。6. 空数据时显示 empty state。请输出:- 需要 mock 哪些接口。- 每个 test case 的步骤。- 每个 case 的断言。- 哪些适合 E2E,哪些适合组件测试。- 风险点。Plan 阶段重点是确认“测什么”和“怎么判断通过”。
Do:生成 Playwright 测试
请按测试计划生成 Playwright 测试代码。要求:- 使用项目现有测试目录结构。- 不新增不必要依赖。- 接口 mock 要稳定。- selector 优先使用 role / text / test-id,不依赖脆弱 class。- 每个 case 都要有明确断言。Check:运行测试和截图验证
执行:
npx playwright test admin-orders.spec.ts如果失败,让 Codex 读报告:
请读取 Playwright 失败报告和截图,判断失败原因。要求:- 区分测试写错、mock 错、页面 bug、环境问题。- 给出证据。- 给出最小修改建议。- 不要直接大范围重写测试。这里 Check 的关键是不要只看“测试通过”。还要判断测试是否真的测到了关键行为。例如只判断按钮存在,不等于筛选功能正确;只判断弹窗出现,不等于详情数据正确。
页面自动化测试尤其适合做成一张验收表:
| 检查项 | 通过标准 | 证据 |
| 页面加载 | 关键标题、列表容器出现 | 截图 / locator 断言 |
| 默认请求 | mock 被命中,列表数据正确渲染 | network log / 文本断言 |
| 筛选行为 | 筛选后请求参数和列表变化正确 | request 断言 / UI 断言 |
| 异常状态 | 接口失败时出现可理解错误提示 | 截图 / 文案断言 |
| 空状态 | 空数据时不是白屏 | empty state 断言 |
| 稳定性 | 重跑多次不 flaky | repeat 运行结果 |
这张表的意义是把“页面看起来没问题”,变成“哪些行为被证据验证过”。
Act:沉淀测试规范 或Skills
最终沉淀:
- 页面测试计划模板
- Playwright selector 规范
- mock 数据约定
- 失败截图分析 prompt
- 页面状态覆盖 checklist:loading / empty / error / success
- 或 生成 Skills
这能让下一次页面测试不从零开始。
八、可复制的 PDCA Prompt 模板
1. 通用 AI 任务模板
你是我的 AI 执行助手。这个任务必须按 PDCA 执行。【Plan】在动手前,请先输出:1. 你理解的目标2. 任务范围3. 不做什么4. 需要读取的上下文5. 执行步骤6. 验收标准7. 风险和不确定点8. 需要我确认的问题在我确认前,不要进入 Do。【Do】执行时要求:1. 小步修改2. 每一步说明改了什么3. 不修改无关文件4. 遇到不确定信息先停下来5. 保留关键命令和结果【Check】完成后必须检查:1. 测试/验证命令是否执行2. 结果是否通过3. diff 是否符合范围4. 是否有未覆盖风险5. 是否有需要人工确认的点【Act】最后输出:1. 本次可沉淀的经验2. 可复用模板3. 需要补充到文档/规则/测试的内容4. 下一轮改进建议5. 把改进建议变成一个新的 Plan2. 代码任务模板
请按 PDCA + TDD 完成代码任务。目标:{目标}范围:{允许修改的目录/文件}禁止:{禁止修改的内容}验收:{测试命令}{lint/typecheck}{业务验收标准}流程:1. Plan:先读代码并输出方案,不写代码。2. Do-1:先写失败测试。3. Check-1:运行测试,确认测试能失败。4. Do-2:实现最小代码让测试通过。5. Check-2:运行测试、检查 diff、做 code review。6. Act:总结可沉淀的测试模板和风险。3. 文档任务模板
请按 PDCA 写文档。Plan:- 目标读者是谁?- 文档要解决什么问题?- 结构是什么?- 需要哪些事实来源?- 哪些内容不能编造?Do:- 分章节写,不要一次性输出全文。- 每章控制重点和字数。- 不确定信息标注“待确认”。Check:- 抽取事实表。- 检查是否有幻觉。- 检查逻辑是否连贯。- 检查读者是否能理解。- 检查标题和摘要是否准确。Act:- 输出可复用文档模板。- 输出术语表。- 输出后续需要补充的资料。4. 自动化测试模板
请按 PDCA 设计并实现自动化测试。Plan:- 页面/接口目标是什么?- 用户路径是什么?- 需要 mock 哪些接口?- 每个 case 的断言是什么?- 哪些场景最容易漏?Do:- 生成测试代码。- 使用稳定 selector。- mock 数据可读可维护。Check:- 执行测试。- 读取失败报告。- 截图验证页面状态。- 区分测试问题和业务问题。Act:- 沉淀测试模板。- 总结 selector 规范。- 补充失败排查 checklist。九、常见错误和避坑
错误一:直接让 AI 实现
错误方式:
帮我实现这个功能。问题是 AI 会自己猜目标、猜边界、猜测试口径。
正确方式是先要求 Plan:
先不要写代码,请先输出目标理解、范围、风险、测试设计和需要确认的问题。错误二:一次性让 AI 改太多
一次性改太多会导致 diff 不可控。正确方式是分阶段,每一阶段都有输出和验收。
错误三:相信 AI 的完成声明
AI 说“已经完成”不代表真的完成。必须看测试、日志、diff、截图、事实来源。
错误四:让 AI 自己验收自己
AI 可以辅助自查,但高风险任务不能只依赖自评。机械项交给脚本,语义项交给独立 review,业务风险交给人。
错误五:没有 Stop Rule
如果 AI 连续两轮修不好同一个问题,不应该继续无限重试。应该停下来输出原因、证据和人工介入建议。
可以设置:
连续两轮同类错误未解决,停止自动修复,输出失败原因和下一步建议。错误六:不沉淀经验
如果每次任务都从零开始,AI 永远只是一次性工具。真正的提效来自沉淀:模板、测试、规则、知识库、工具链。
十、落地建议:自己如何开始
如果自己想把这套方法真正用起来,不建议一上来建设复杂平台。可以从三个最小动作开始。
第一,给所有 AI 任务加一个 Plan 门禁。
未输出目标、范围、验收标准、风险和停机点之前,不允许进入实现。第二,给所有 AI 交付加一个 Check 门禁。
代码必须有测试或静态检查证据;文档必须有事实表;页面必须有运行截图或自动化报告。第三,把高频成功流程沉淀成模板或Skills。
每完成 3 次同类任务,就把稳定流程沉淀为 prompt 模板、checklist、脚本、skill 或团队规范。这三个动作不重,但能立刻改变 AI 的工作方式:从“自由生成”变成“受控交付”。
十一、结语:AI 不是替代流程,而是需要更好的流程
AI 开发的关键,不是把人从流程中拿掉,而是让人从重复劳动中抽身,回到目标定义、边界判断、风险取舍和质量验收上。
大模型负责生成,人类负责定义方向;工具负责验证,系统负责沉淀。
PDCA 的价值就在这里:它不是限制 AI,而是给 AI 一个可工作的轨道。
当我们把 Plan、Do、Check、Act 做成习惯,再用 Harness 把上下文、工具、权限、测试、日志、知识库串起来,AI 才会从“聪明的聊天对象”变成“可靠的工作伙伴”。
未来的 AI 开发能力,不只是看谁更会写 prompt,而是看谁更会设计工作系统。
真正成熟的 AI 开发,不是对模型许愿,而是用 PDCA 管住过程,用 Harness 承接执行,用测试和事实完成验收,用沉淀让下一次更好。
【想要讨论AI编程和AI技术加群】

