 夜雨聆风
夜雨聆风如果只把黄仁勋在GTC Taipei 2026上的演讲理解成“英伟达又发了几款新硬件”,其实就低估了这场发布会的信号。
Vera Rubin全面投产,RTX Spark进入PC,Vera CPU面向Agent工作负载,Nemotron服务长程推理,Cosmos和Isaac GR00T指向物理AI。看起来是很多分散的产品,但它们背后其实指向同一个判断,
这可能才是未来十年计算产业最重要的变化。
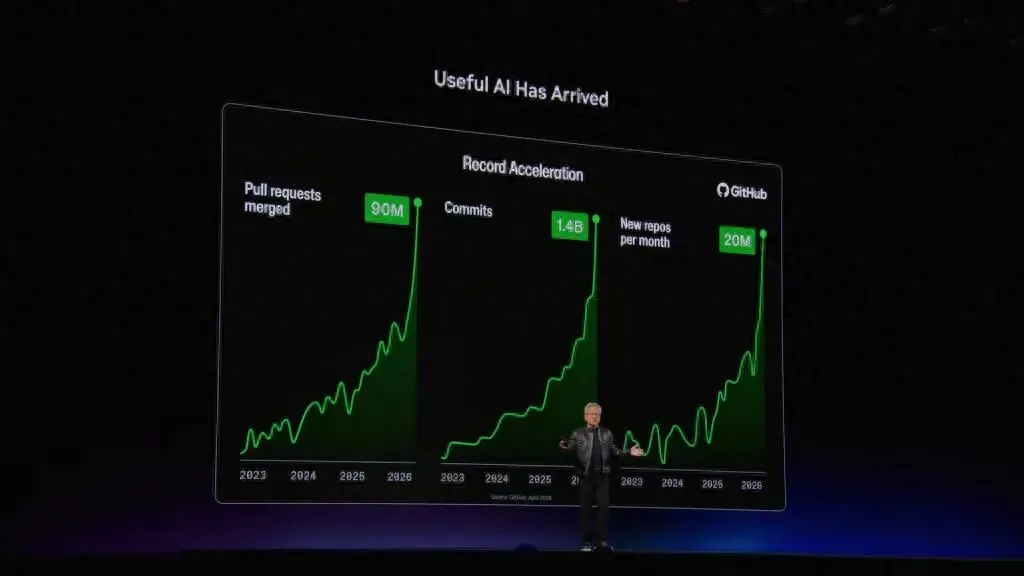
一、为什么黄仁勋一直在讲Token?
这次演讲里,黄仁勋反复强调一个逻辑:Token正在变成利润单位。
过去我们理解AI,常常停留在模型层面:参数量多大,榜单多少分,生成效果有多好。但到了产业侧,真正决定企业能不能长期使用AI的,不只是模型聪不聪明,而是一次请求能不能快速响应,同样成本下能不能生成更多有效结果,复杂任务能不能稳定跑完,每瓦电能产生多少Token,每美元成本能换来多少可交付的智能。
这就是“Token经济学”

二、PC正在被重新定义
RTX Spark的意义,不只是英伟达进入PC市场,更重要的是,它在重新定义PC本身。
过去40年,个人电脑的基本交互逻辑没有发生本质变化:人打开软件,人点击菜单,人输入指令,人保存文件。哪怕软件越来越复杂,本质上仍然是人在操作工具。
但Agent时代的PC不一样。
黄仁勋讲的“新PC”对技术人员尤其关键,因为过去很多Agent项目卡住的地方,不是Demo不酷,而是无法真正落到主力设备上,云端Agent有成本和隐私问题;浏览器Agent有权限和稳定性问题;企业Agent有安全和审计问题;本地Agent又受制于算力、内存和系统级调用能力。
所以RTX Spark背后的核心,不是“AI PC”这个营销词,而是本地Agent的基础设施问题。

三、Agent时代,CPU重新变重要了
过去几年,外界看英伟达,几乎只看GPU,但这次Vera CPU的出现,说明Agent时代的计算瓶颈不只在GPU。
传统AI推理中,GPU负责大规模矩阵计算,CPU更多承担调度和支撑角色。但Agent工作流不一样,Agent会频繁进行工具调用、环境管理、代码执行、检索、数据搬运、上下文维护、多任务编排和安全策略检查。
这些工作不是单纯靠GPU堆算力就能解决的,一个典型Agent系统,可能同时运行大量独立环境:有的在跑代码,有的在调用API,有的在执行测试,有的在做检索,有的在管理上下文,有的在等待外部系统返回结果。
这就要求CPU具备更高的并发管理能力、更强的内存带宽、更低的延迟,以及与GPU之间更紧密的数据共享。
Vera CPU的定位,正是为Agent和强化学习场景服务。它不是传统意义上“给服务器配一颗CPU”,而是为大规模Agent系统准备的协调中枢。
这也是技术人员需要注意的变化:
未来AI系统的性能,不再只看模型和GPU,而要看完整系统的吞吐、延迟、内存、网络、存储、安全和调度能力。
模型只是Agent的大脑之一,真正决定它能不能工作的是整个系统。

四、Vera Rubin:AI工厂不是数据中心换皮
Vera Rubin是这次演讲里最重的基础设施信号。
它不是单台服务器,而是POD级AI超级计算系统。GPU机架负责高吞吐推理,CPU机架负责调度和环境管理,网络、存储和DPU负责互联、安全与多租户隔离,这套结构说明,英伟达眼里的AI基础设施已经不是“买GPU、插服务器、接网络”这么简单。
Agent工作负载有几个非常麻烦的特点:
第一,它链路长。一个任务可能有几十步、上百步甚至上千步。
第二,它状态多。Agent需要短期上下文,也需要长期记忆,还可能有多个子Agent协同。
第三,它调用频繁。模型、工具、数据库、文件系统、浏览器、IDE、仿真软件都可能被反复调用。
第四,它对延迟敏感。用户不是等一份离线报告,而是在和一个会工作的系统交互。
第五,它要求安全。Agent一旦能读文件、写代码、调用工具,就必须有身份、权限、沙箱、审计和策略控制。
所以Vera Rubin的核心价值,不只是算力更强,而是为Agent工作负载做系统级协同设计。
这也是黄仁勋为什么把“AI工厂”讲得越来越具体。
工厂的本质,是把原材料稳定转化为产品。AI工厂的原材料是数据、任务和电力,产品是Token、代码、视频、仿真结果、设计方案、决策结果和自动化动作。
当AI进入企业生产系统,数据中心就不再只是成本中心,而会变成产能系统。
谁能在同样电力下生成更多有效Token,谁就有更低的单位智能成本。
这就是“算力即收入,算力即利润”背后的产业逻辑。

五、真正的Agent工程,不是模型加Prompt
这次发布里,Nemotron、Agent Toolkit、OpenShell这些软件层同样重要。
很多人现在谈Agent,还是停留在“给大模型加工具调用”的阶段。但真正进入企业和工程场景后,Agent至少需要五层能力。
第一层是模型,负责理解、推理和生成。
第二层是编排,负责计划、记忆、工具调用、多步骤执行和子任务分解。
第三层是运行环境,负责沙箱、权限、隔离、策略和审计。
第四层是专业能力,也就是可调用的工具和技能,比如数据处理、代码执行、仿真、优化求解、物理建模等。
第五层是基础设施,负责算力、网络、存储、安全和部署。
这才是Agent工程化的完整形态。
英伟达这次强调OpenShell,就是因为Agent越能干,越危险。
一个只能聊天的AI,风险主要是回答错。一个能访问文件、写代码、运行命令、调用企业系统的Agent,风险就完全不同。它可能误删文件、泄露数据、调用错误接口、执行错误脚本,甚至在没有充分授权的情况下完成高风险操作。
所以未来Agent系统的竞争,不会只是谁的模型回答更像人,而是谁能在真实企业环境里做到:能干活,能被限制,能被追踪,能被审计,能被部署,能和现有软件栈兼容。
模型能力只是入场券,工程化能力才是长期壁垒。

六、物理AI才是更大的难题
如果说Agent是数字世界里的自动化员工,那么物理AI就是现实世界里的自动化行动者。
这也是Cosmos和Isaac GR00T的重要性。
训练语言模型,可以用互联网上大量文本。训练图像模型,可以用图片和视频。但训练机器人不一样。机器人需要理解空间、物体、动作、力、碰撞、遮挡、路径、环境变化和物理规律。
更麻烦的是,机器人需要第一人称视角的数据。
人类互联网上的大量视频,是第三人称拍摄的。它们能让模型理解“人做了什么”,但很难直接变成“机器人应该怎么做”。
所以物理AI最大的瓶颈不是模型结构,而是数据。
英伟达给出的路径是:远程操控采集示范数据,Omniverse做仿真,Cosmos生成和转换物理世界数据,再通过Isaac平台训练和部署到真实机器人。
这背后的逻辑是:
当现实数据太贵、太慢、太危险时,就用计算生成可训练的世界。
这场演讲对普通人的影响,是PC会变成个人Agent设备,AI会越来越像“能帮你干活的同事”,但对技术人员来说,更关键的变化有三个。
第一,AI开发的重心会从Prompt迁移到Workflow。
过去会写提示词就能做出一个不错的AI应用。未来不够了。你需要理解任务如何拆解,工具如何调用,状态如何保持,失败如何恢复,权限如何限制,结果如何验证。
第二,系统能力会比单点模型更重要。
一个企业不会只因为模型跑分高就大规模部署Agent。它会看成本、延迟、稳定性、合规、安全、可观测性、可维护性,以及与现有系统的集成难度。
第三,AI基础设施会变成新的产业分工。
模型公司、云厂商、芯片公司、软件平台、企业服务商、内容工具、机器人公司,都会围绕Agent工作负载重新定位。
未来几年,真正有价值的岗位和项目,很可能不只是“会用AI”,而是“能把AI接进真实生产流程”,这类工作不会因为AI出现而消失,反而会变得更复杂、更工程化。
