 夜雨聆风
夜雨聆风《Nano-vLLM 源码解读》第 14 篇 · RMSNorm 与残差融合
nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇介绍了 Qwen3 的骨架:embed_tokens → 28×Qwen3DecoderLayer → final RMSNorm → lm_head,并讲了贯穿其中的残差流——一条宽度恒 1024 的主干,每个子层在它的归一化副本上算增量、加回主干。当时留了个伏笔:这个「加」被融进了下一个 norm,所以 residual 要在层间显式传递。
本篇展开介绍 RMSNorm 这个黑盒,讲清两件事:它内部怎么算,以及那个「加」怎么和归一化融成一步 add_rms。
2. 总览
RMSNorm 是一个类、两种调用。forward 按有没有传 residual 分流:
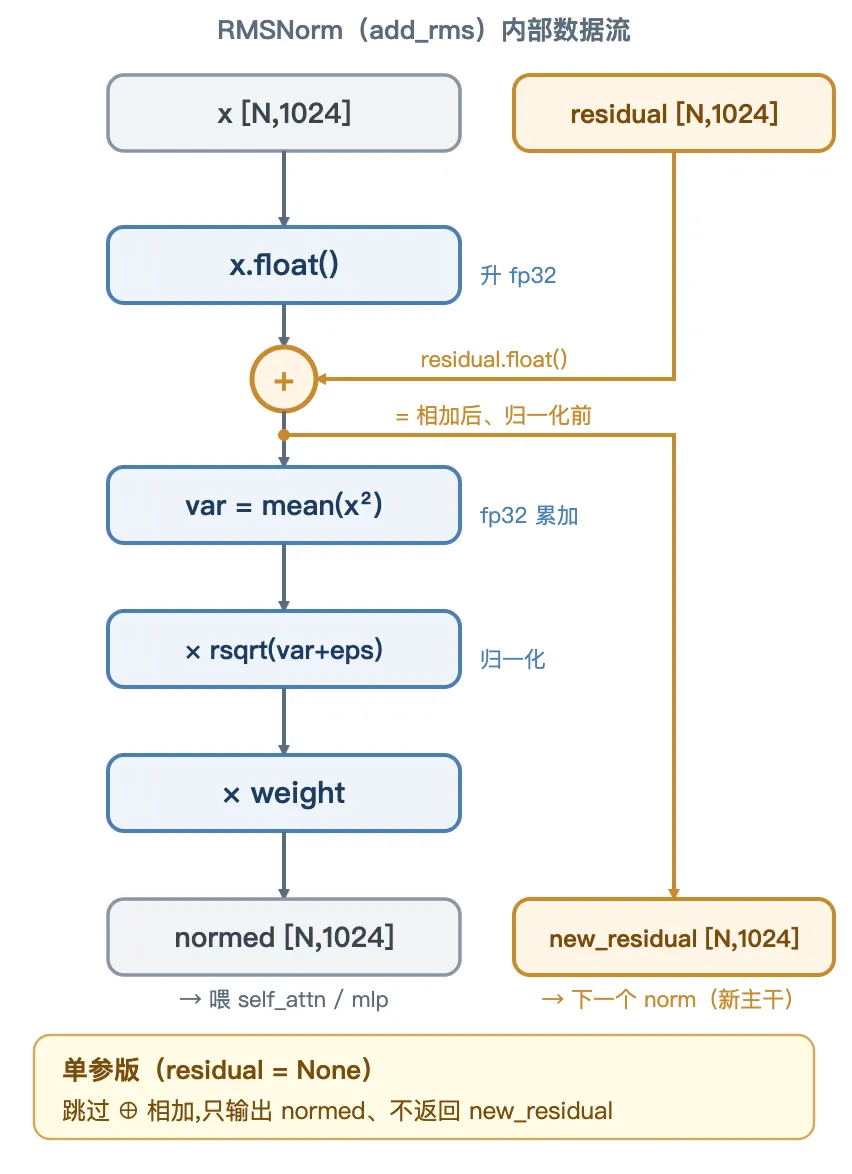
• 单参版 rms_forward(x):只做归一化(图中跳过 ⊕ 相加、不返回 new_residual)。• 两参版 add_rms_forward(x, residual):先把x + residual融成新主干,再归一化,返回(normed, new_residual)两个量。
骨架里三处用到它:
input_layernorm | ||
input/post_attention_layernorm | ||
norm |
3. 标准 RMSNorm
单参版 rms_forward 是不带残差的纯归一化,骨架首层用的就是它。
import torch
# 这里抽成函数看清逻辑,weight/eps 即 self.weight/self.eps
defrms_forward(x, weight, eps=1e-6):
orig_dtype = x.dtype # 记下入参精度(bf16)
x = x.float() # 升 fp32 再算(精度关键,见 3.1)
var = x.pow(2).mean(-1, keepdim=True) # 每个 token 的均方
x = x * torch.rsqrt(var + eps) # ×1/√均方 = 归一化
return x.to(orig_dtype) * weight # 收回原精度,× weightRMSNorm(均方根归一化)
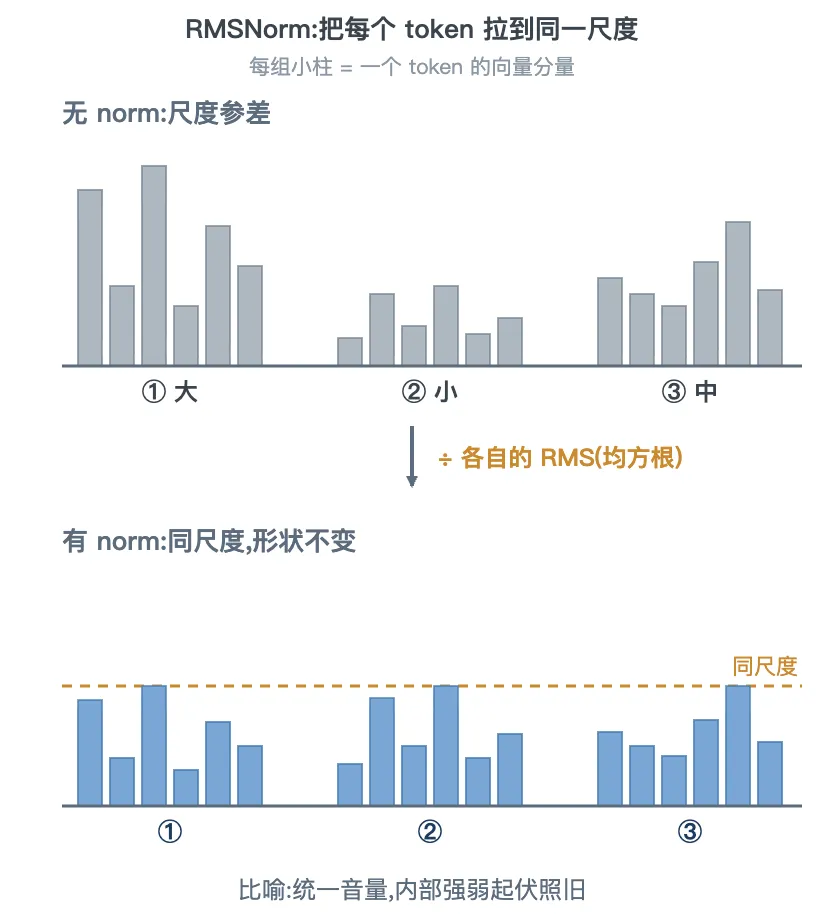
把每个 token 的 [1024] 向量,除以它自己的均方根(RMS = √各分量平方的均值),再乘一份可学习的 weight。
打个比方:像给一段段响度参差的录音统一音量——都拉到同一基准,但每段内部的强弱起伏原样保留。
为什么需要:28 层堆叠,每层输出的数值尺度会逐层漂移,不归一化会让后续计算数值不稳。
解决了什么:把每层输入拉回统一尺度,稳住深层堆叠。
怎么解决:x / sqrt(mean(x²) + eps) × weight。比 LayerNorm 少了减均值这一步——实践表明 Transformer 里这步并非必要,省一次规约更快。
3.1 为什么要先 .float()
rms_forward 第一步就把 x 升到 fp32 才算 var。var = mean(x²) 要把 1024 个平方值累加再平均;若在 fp16 里做,1024 项累加很容易超出 fp16 能表示的范围(最大约 6.5 万)。升 fp32 累加、归一化完再收回原精度,几乎不增显存却保住了数值。
import torch
torch.manual_seed(0)
# 一个量级偏大的 hidden(1024 维,存成 fp16)
x16 = (torch.randn(1024) * 30).half()
sq = x16.pow(2) # 每个分量的平方(fp16),仍在 fp16 范围内,未溢出
# 源码做法:升 fp32 再累加求均方
var_fp32 = sq.float().mean().item()
# 对照:全程 fp16 累加(每加一步都 round 回 fp16)
acc = torch.zeros((), dtype=torch.float16)
for s in sq:
acc += s
var_fp16 = (acc / 1024).item()
print("fp32 累加 var :", var_fp32) # ≈ 900,正常
print("fp16 累加 var :", var_fp16) # 累加到几十万,溢出 → inffp32 累加 var : 950.9798583984375
fp16 累加 var : inffp16 连这个累加和都存不下,直接溢出成 inf;升 fp32 才稳稳算出 ≈900。这就是 rms_forward 第一行 x.float() 的意义:归一化的中间统计量必须在 fp32 里算,算完再收回原精度。
4. add_rms 融合
两参版 add_rms_forward 在归一化之前,先把传入的 residual 加到 x 上。
# add_rms:归一化前先并入 residual
defadd_rms_forward(x, residual, weight, eps=1e-6):
orig_dtype = x.dtype
x = x.float() + residual.float() # ① 相加(fp32)= 新主干
new_residual = x.to(orig_dtype) # ② 存下新主干(相加后、归一化前)
var = x.pow(2).mean(-1, keepdim=True)
x = x * torch.rsqrt(var + eps) # ③ 归一化(同 rms_forward)
normed = x.to(orig_dtype) * weight
return normed, new_residual # (normed, new_residual)两参版返回两个量:
• normed:归一化结果,喂给紧接的self_attn或mlp。• new_residual:相加后、归一化前的x,也就是更新后的主干,继续往下传。
new_residual 取的是相加之后、归一化之前的值(代码 ② 在 ③ 之前)。归一化只是给子层喂一份标准化副本,主干本身要的是未经缩放的累加结果。
4.1 朴素写法与融合写法
标准 pre-norm Transformer,每个子层都这么写(朴素):
h = h + sublayer(norm(h)) # norm 读 h;加法 h+... 单独一步,写回 h每个子层一次独立的 +:读 h、读子层输出、写回 h——一整趟 [N,1024] 主干的读写。
nano-vllm 把这个 + 从子层里挪走,推迟到下一个 norm 一起做(融合):
normed, h = norm(prev_out, h) # norm 内部 h = prev_out + h(新主干),再归一化
cur_out = sublayer(normed) # 子层吃归一化副本;cur_out 先不加回 h好处来自访存,不是算力。add 和 RMSNorm 都是逐元素算子,算术量很小,真正的开销是把 [N,1024] 主干在显存(HBM)与计算核心之间搬运——属于「访存受限」。朴素写法主干要进出 HBM 两趟:相加 kernel 写一遍,归一化 kernel 再读一遍。融合后 @torch.compile 把相加、求均方、归一化编进同一个 kernel,主干读一次、写一次,中间量都在寄存器里流转。访存受限的算子,省下的 HBM 往返几乎直接等于省下的时间。
顺带还少一次 kernel 启动:朴素写法是「相加 kernel + 归一化 kernel」两次启动,融合成一个,启动开销也减半。
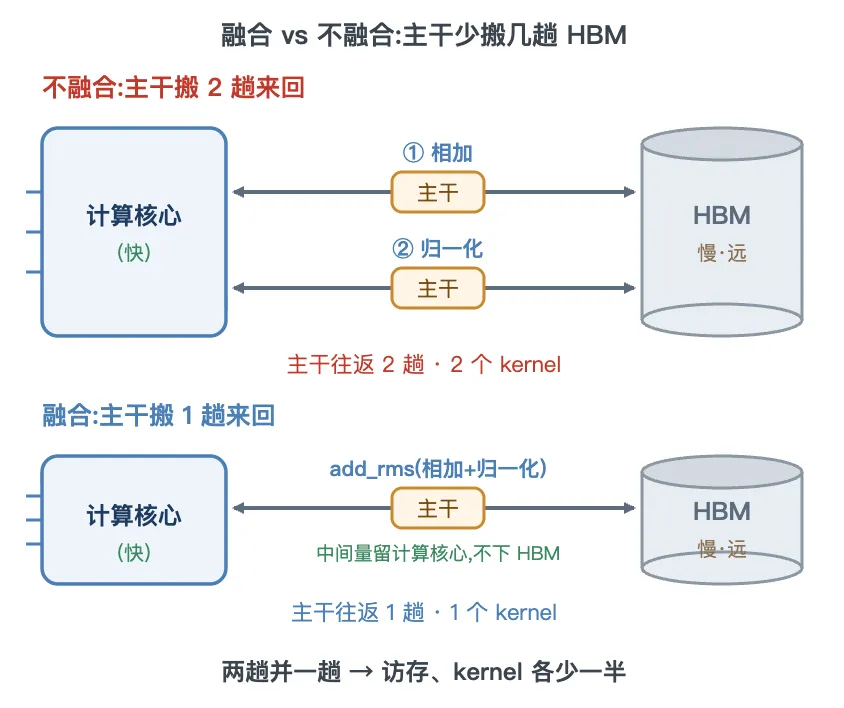
代价是主干 h 不再在子层内就地更新,得作为 (normed, h) 显式带出来。
打个比方:本该单独跑一趟把子层输出加回主干,如今改由下一个 norm 路过时顺手捎上——省掉这趟专程。
5. 集成验证
加载真实 Qwen3-0.6B,取第 0 层的 input_layernorm(一个真实 RMSNorm),喂一份真实 hidden 和一份主干,验证两件事:add_rms 返回的 (normed, new_residual) 与手写 fp32 相加 + 归一化逐元素一致;norm 进出宽度不变(主干恒 1024)。
import torch
import torch.distributed as dist
from modelscope import snapshot_download
from nanovllm.config import Config
from transformers import AutoTokenizer
from topic11_model_runner import ModelRunner # L11 教学版,加载真实权重
torch.cuda.set_device(0)
ifnot dist.is_initialized():
dist.init_process_group(
"nccl", "tcp://localhost:2335", world_size=1, rank=0)
model_path = snapshot_download("Qwen/Qwen3-0.6B")
config = Config(model_path, enforce_eager=True, max_model_len=4096)
runner = ModelRunner(config)
model = runner.model # Qwen3ForCausalLM(权重 bf16)# 造真实 hidden:prompt → ids → 查 embed(VocabParallelEmbedding 无需 context)
tokenizer = AutoTokenizer.from_pretrained(model_path)
text = tokenizer.apply_chat_template(
[{"role": "user", "content": "你是谁"}],
tokenize=False, add_generation_prompt=True, enable_thinking=False)
ids = torch.tensor(tokenizer(text).input_ids, device="cuda")
with torch.inference_mode():
hidden = model.model.embed_tokens(ids) # [N,1024] bf16,当作子层输出 x
residual = torch.randn_like(hidden) # 造一份主干
norm = model.model.layers[0].input_layernorm # 一个真实 RMSNorm
normed, new_res = norm(hidden, residual) # 两参版 add_rms
# 手写对照:升 fp32 相加 → 存主干 → 归一化 → ×weight
x = hidden.float() + residual.float()
ref_res = x.to(hidden.dtype)
var = x.pow(2).mean(-1, keepdim=True)
ref_normed = (x * torch.rsqrt(var + norm.eps)).to(hidden.dtype) * norm.weight
print("进出宽度 :", hidden.shape[-1], "→", normed.shape[-1]) # 1024 → 1024
print("new_res = 手写值 :", torch.equal(new_res, ref_res)) # True
print("normed 与手写一致:", torch.allclose(normed, ref_normed, atol=1e-3)) # True进出宽度 : 1024 → 1024
new_res = 手写值 : True
normed 与手写一致: True6. 小结
RMSNorm 是均方根归一化:x / sqrt(mean(x²)+eps) × weight,比 LayerNorm 省去减均值;中间统计量在 fp32 里算,算完收回原精度。
它一个类、两种调用:单参版纯归一化;两参版 add_rms 把残差相加 + 归一化融成一步,返回 (normed, new_residual)。融合把加法编进归一化 kernel、省一遍主干读写,减少了 kernel 启动和显存读写次数。
下一篇介绍 RoPE 原理和实现。
