 夜雨聆风
夜雨聆风过去两年,不少企业在内部试点用大模型做数据查询。有个现象挺有意思:Demo阶段几乎没人说不满意。单表查询、标准问题、干净数据,准确率接近满分。IT觉得可以上线了,业务也觉得终于不用排队取数了。
然后呢?然后就开始出问题。
车间主任问“昨天A线跑得怎么样”,系统返回空。不是SQL写错了,是大模型不知道“跑得怎么样”在这家工厂的语境里对应的是良品率、日产量和设备利用率三个指标的组合。财务部问“上季度华东区新品毛利率”,出来的数字和手工报表差了几个百分点。排查半天,发现大模型不知道这家公司财务部和运营部对“毛利率”用的是两套不同的计算口径。最麻烦的一次,审计部门要求出示某次查询的完整追溯记录,IT负责人沉默了很久——大模型生成SQL的过程是个黑箱,拿不出任何东西。
Gartner在2026年4月发布了一项覆盖全球782名I&O领导者的调研,数据与这些现场感受高度吻合:仅有28%的AI用例能完全成功并达到预期ROI,超过三分之一的失败项目根因指向数据质量差或数据可用性有限。Gartner进一步预测,到2026年底,60%的AI项目将因缺乏“AI就绪数据”而被放弃。
这些数字揭示了一个被反复验证但少有人愿意正视的事实:Demo里跑得通,和“生产环境扛得住”,中间差着好几道工程化的坎。这篇文章,就是想把这几道坎拆开看清楚。
一、大模型的三个软肋
通用大模型从底层来说是个概率系统。它不是在“知道”答案,而是在计算哪个答案看起来最像真的。这种特性在消费场景里不是问题——写首诗、润色个文案,多个版本反而更好。但到了企业场景里,它就成了麻烦的根源。
软肋一:概率性 vs 确定性——你永远不知道它什么时候会“编”
Gartner将模型幻觉列为2026年企业AI落地的首要技术风险。行业公开数据也印证了这个判断:NL2SQL在单表查询上可以做到85%到90%的准确率,看起来不差。但只要涉及三张表以上的关联查询,准确率直接掉到不足70%。复杂嵌套查询更低,在65%到70%之间。
这不是某个模型的问题,而是概率系统在复杂推理场景中的天然局限。对于企业来说,一个“可能对、也可能错”的AI,放在财务对账、库存盘点、合同审核这类零容错场景里,基本等于不可用。

软肋二:通用知识 vs 行业深度——它听不懂你们公司的“黑话”
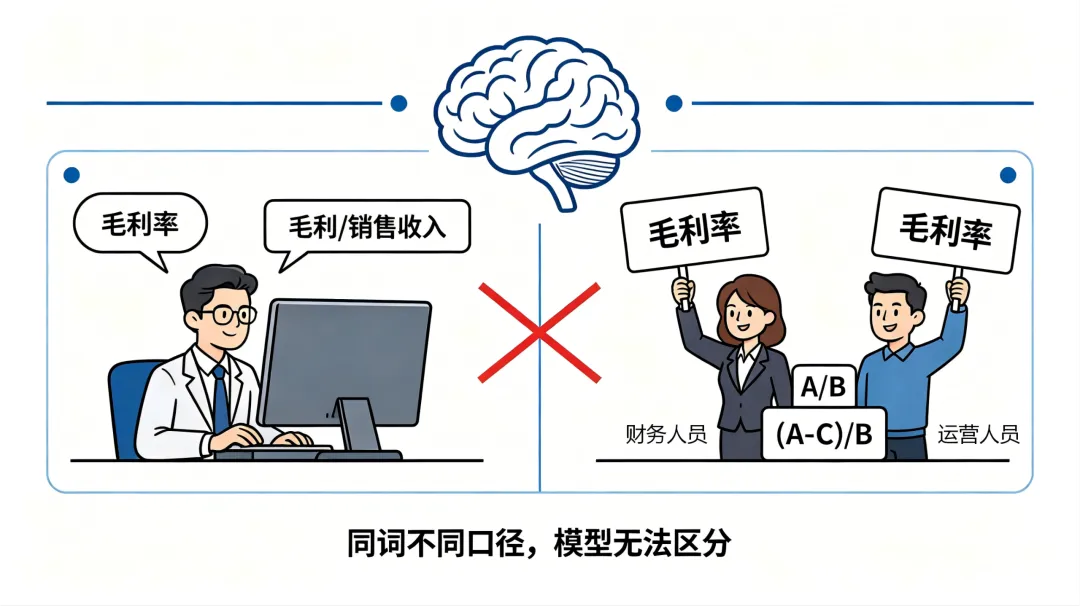
通用大模型的知识来自公开语料训练。它能准确解释“毛利率”的标准定义,但不知道在你们公司里,财务部和运营部对同一个词用的是两套完全不同的计算公式。它能写出语法标准的SQL,但听不懂车间主任嘴里的“爬坡”、采购员说的“在途”、财务讲的“回款”。
蚂蚁数科AI技术负责人曾公开指出,NL2SQL落地时最核心的挑战之一,就是“理解模糊多义的人类口语”与“解析复杂的数据库结构与关联”之间的鸿沟。劳埃德银行的实践数据也量化了这一点:他们仅在数据库Schema中添加同义词、缩写和已验证的示例查询,准确率就从80%提升至86.1%。有意思的是,这个提升幅度比直接换用更新版本的大模型还要大。
大模型缺的不是“更聪明”,而是“更懂你们公司”。
软肋三:孤立对话 vs 系统协同——它不知道调用哪个系统、也留不下审计记录
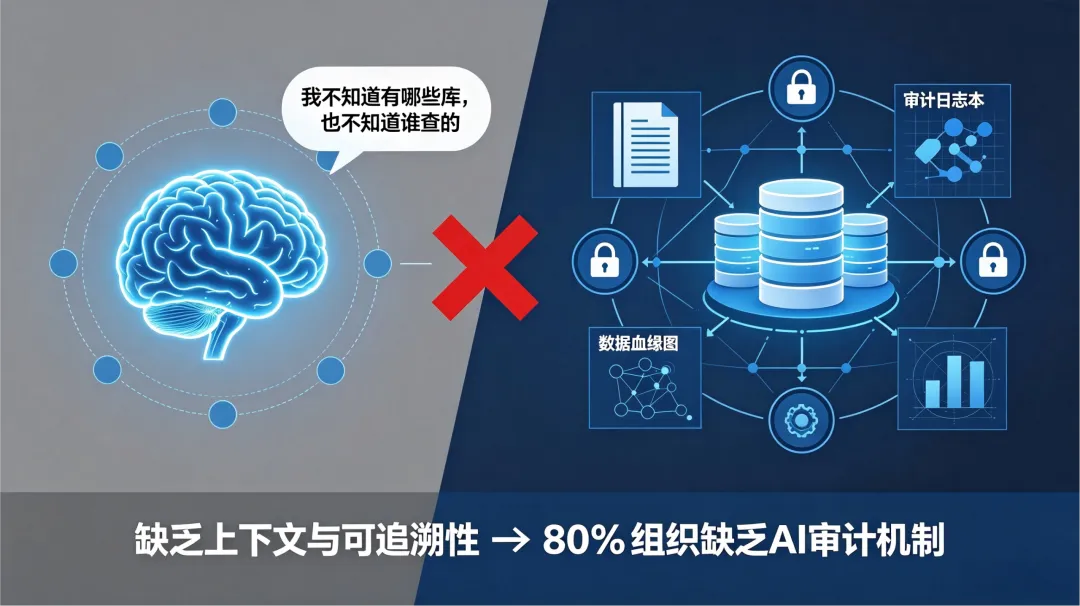
通用大模型本质上是一个“单机版大脑”。它能回答你的问题,但不知道你们公司有几套数据库、每套库里有什么表、表之间怎么关联、哪些数据涉及权限控制。它也不会主动记录每次查询生成的原始SQL是什么、什么时候执行的、谁发起的。
德勤发布的《2026全球企业AI状况报告》覆盖了来自24个国家的3235名信息技术与业务领导者,结论指向一个明确的缺口:仅有21%的企业建立了成熟的AI智能体治理框架,约80%的受访组织缺乏实时监控与审核追踪机制。当合规审查要求出示AI查询的完整审计记录时,裸调的大模型无法提供任何东西。
二、填补软肋的三个工程化组件
既然通用大模型在企业场景里出问题,根子在于它既是一个概率系统、又是一个孤立大脑,那么解决思路就很明确——不是在“换更强的模型”上较劲,而是“在模型外围加一套工程化组件”。这套组件,大致可以拆成三层。
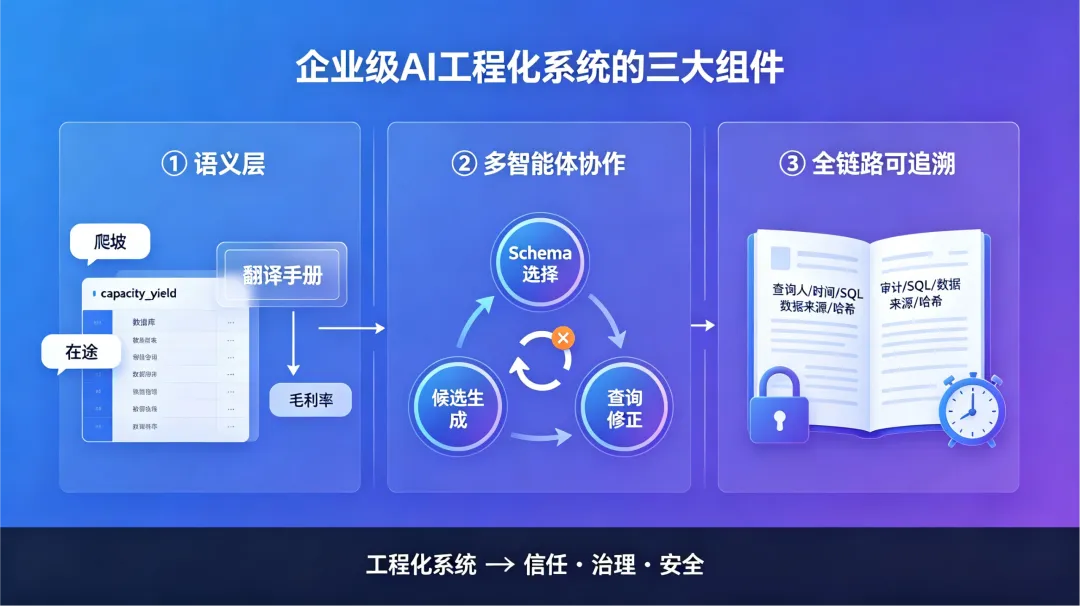
组件一:语义层——把业务语言翻译成数据语言
语义层要解决的核心问题,是把企业内部的口语化表达、行业术语、跨部门各有定义的概念,与数据库中的字段、表、计算逻辑之间建立确定性的映射关系。不再靠模型去猜,而是靠事先约定好的“翻译手册”。
劳埃德银行那个+6.1%的案例,就是语义层价值的直接证明。但语义层不止是加同义词。它还得处理一个更棘手的情况:同一个口语在不同语境下指向不同指标时,系统该听谁的?“爬坡”在产线A的语境下是产能爬坡,在质检组的语境下是良率爬坡。这就需要把静态词典升级为能感知业务上下文的语义模型,根据提问者的部门归属、历史提问记录、当前业务场景,自动判定他说的是哪一种“爬坡”。
BlazesQL在2026年NL2SQL技术指南里有一句话把这件事说得很透彻:“一个普通模型配上高度富化的语义层,会轻易地超越一个在真空中运行的顶尖模型。”
组件二:多智能体协作——从一次生成到多轮验证
单靠一个大模型一次生成SQL,出了错只能等用户自己发现。多智能体协作的思路完全不一样:把任务拆开,让几个各有分工的智能体一起干,生成的和检查的互相校验,形成多轮反馈闭环。
2026年行业里几个前沿方向都在走这条路。EvoAgent-SQL提出了进化多智能体框架,把用户反馈和反思性自适应机制融进了NL2SQL流程。NL2SQLBench首次将NL2SQL系统标准化拆解为Schema Selection、Candidate Generation、Query Revision三个核心模块,为系统化评估提供了基准。SQLFixAgent在BIRD基准上实现了超过3%的执行准确率提升。
这些探索指向同一个方向:让AI从“一次生成、碰运气”,变成“多次验证、可纠错”,从概率输出走向确定性推理。
组件三:全链路可追溯——让每次查询经得起审计
Gartner将“数字溯源”列为2026年十大战略技术趋势。全链路可追溯要回答三个问题:业务术语到数据库字段的映射过程,有没有留下可查的记录?数据从源头到计算结果的路径,能不能完整追溯?每次查询的原始SQL、语义版本和执行时间戳,有没有完整记录?
这套追溯能力确保AI输出的数据能经得起外部审计和内部合规审查。这是企业级AI与消费级AI最本质的区别——前者必须为结果负责,后者只需要让用户觉得好用。
三、三个维度,企业可以自己评估
基于以上分析,企业在评估AI方案时,不用记太多技术名词,盯住三个维度就够了。
第一,语义层——它能不能听懂我们内部的话?如果方案只是裸调大模型,没有建立企业内部的术语映射机制,那业务部门用自己习惯的方式提问,大概率会出问题。
第二,验证机制——它查完了,能不能自己发现错了?如果方案只有一个模型一把梭,没有多轮验证和纠错机制,多表关联场景下的静默错误就会持续累积,直到对账或审计时才暴露。
第三,可追溯性——它能拿出审计记录吗?如果方案不支持查询日志审计、语义映射追溯和数据血缘追踪,企业就背着一堆合规风险——每次AI输出的数据,都可能是审计时的一颗雷。
这三个维度,分别对应大模型的三个软肋,也分别对应工程化系统的三个组件。它们构成了一个最简化的企业级AI能力评估框架。
在B端,真正的分水岭不是“谁家的对话更流畅”,而是“谁先完成了从裸调大模型到工程化系统的跨越”。企业引入AI时,选的不应该只是一个聪明的模型,而应该是一套靠得住、经得起审计的系统。
Gartner在2026年十大战略技术趋势中指出:信任、治理与安全,将成为企业AI规模化应用的三大支柱。而工程化系统,正是这三根支柱底下的地基。

我们的团队在部署中反复验证过一个结论:大模型能写对SQL,但回答不了“为什么是这个结果”。企业真正需要的,是一套覆盖语义层、多智能体验证与全链路审计的工程化底座。
如果你正在评估智能问数方案,我们可以做一次免费的系统能力诊断,看下当前方案在语义层、验证机制和可追溯性三个维度到底到了什么水平。感兴趣可以扫码加好友。


