 夜雨聆风
夜雨聆风
五月底,2026世界智能产业博览会在天津开幕。
在“智行天下 能动未来”的主题下,国家数据局局长刘烈宏的一番讲话,为人工智能产业的竞争风向给出了一个明确的指针。

在各界目光聚焦大模型、智能体和人形机器人时,刘烈宏把话题拉回到一个更深层的问题上——这场竞赛的焦点正在从“拼模型”转向“拼数据”。
他在致辞中明确指出,当前人工智能发展呈现出鲜明的“数据驱动”特征,“数据的规模、质量、结构,深刻影响模型的智能水平和应用边界。从数据的角度看,AI就是数据的精炼厂。”
这番话为何值得关注?因为它回答了一个长期被忽略的问题:当大模型能力日趋同质化,决定竞争胜负的关键变量到底是什么。
一、两个“到哪里”:AI的边界由数据划定
刘烈宏首先抛出了一组数据。2025年,我国数据生产总量达到52.26泽字节(ZB),占全球的27.44%;用于人工智能训练和推理的数据总量为199.48艾字节(EB),同比增长42.86%。其中,推理数据量首次超过了训练数据量,达到101.34艾字节(EB)。
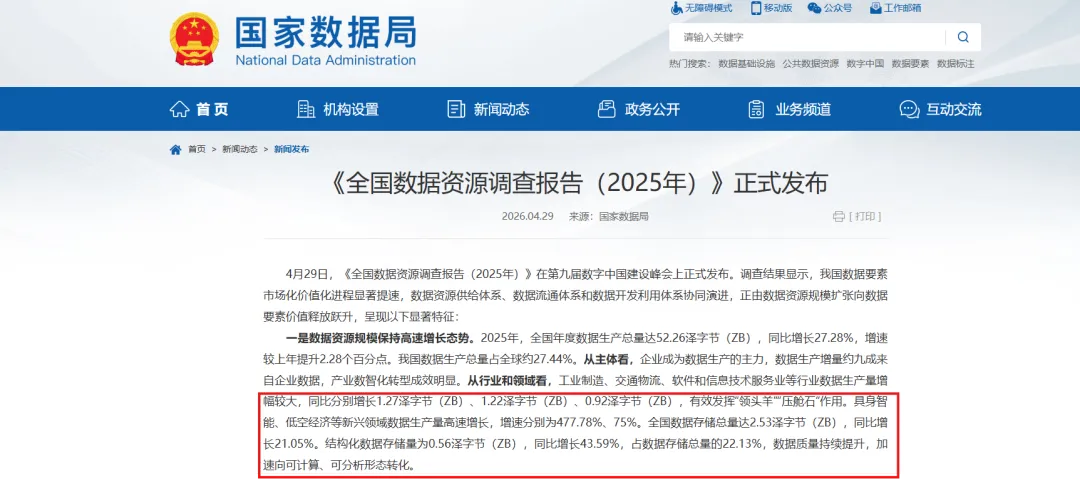
这组数字传递了一个清晰的信号:人工智能正在从“训练驱动”向“训练与推理双驱动”加速演进,在各行业的渗透和应用呈爆发式增长。
基于这一判断,刘烈宏提出了两个导向性的原则:
一是“人工智能发展到哪里,数据工作就跟进到哪里”;
二是“人工智能赋能行业发展到哪里,行业高质量数据集建设和服务就跟进到哪里”。

他特别指出,这两个“到哪里”已形成广泛社会共识。
这句话的深层含义在于:AI的能力边界,将由数据的边界决定。
模型本身只是骨架,数据才是肌体。
二、三大战场:数据如何重塑AI
刘烈宏围绕数据赋能人工智能创新发展,从三个维度勾勒了高质量数据集的战略价值。
制造业:数据就是“工业机理的翻译官”
刘烈宏指出,高质量数据集是先进制造业智能化升级的基础资源和创新引擎。人工智能在制造业的应用,已深入到研发设计、生产制造、质量检测等关键环节。

但要使行业大模型和智能体真正理解工业机理、适配工业场景,需要把真实产线、设备运行和质量检测等数据系统采集、治理和利用起来。
在他的阐述中,国家数据局正支持工业制造领域的链主和先行先试单位,围绕汽车制造、船舶工业、轨道交通、有色金属等重点细分方向建设行业高质量数据集,目前已形成约2.8PB的数据规模。
具身智能:数据工程决定机器人的“智商”
刘烈宏强调,高质量数据集是具身智能“感知—决策—执行”的重要基础。具身智能在真实环境中的自主适应与任务执行能力,依赖视觉、触觉、音频等高质量、多模态训练数据的支撑。

他特别以今年4月19日举办的第二届“北京亦庄半程马拉松暨人形机器人半程马拉松”比赛为例。这场比赛首次设置了“自主导航组”,相比2025年首届比赛中机器人主要依赖遥操作,本届自主导航参赛队伍占比已达38%。取得优异成绩的企业有一个共同特点:以完善的数据工程驱动具身智能的发展,不仅布局了真机遥操、仿真合成、人类视频等数据产线,还打造了面向具身智能的新一代多模态数据平台。
刘烈宏总结说:“具身智 能的竞争,也是数据体系能力的竞争。”
AI for Science:打通基础研究到产业落地的“最后一公里”
科学研究对数据准确性、规范性、可信性要求更高。刘烈宏指出,高质量数据集不仅是支撑科学领域模型训练、规律发现和成果验证的基础底座,更是推动基础研究走向产业应用、实现AI for Science真正落地的关键支撑。
三、政策工具箱:六大行动与“模数共振”
如果说上述三点指明了方向,那么接下来的一系列政策部署,则构成了实现路径。
刘烈宏透露,2026年被确定为“数据要素价值释放年”。
国家数据局将推出《关于推进行业高质量数据集建设行动的实施方案》,围绕强基扩容、标注攻坚、提质增效、应用赋能、管理服务、价值释放等六大行动,聚焦人工智能赋能产业发展需求,“以产业应用牵引数据供给、以数据驱动产业智能发展,推动各行各业‘数据飞轮’更好转起来”。
具体来看,这六项行动的目标很明确:
强基扩容:聚焦重点领域和创新领域,解决“有什么”的问题;
标注攻坚:发展人机协同智能化标注,解决“怎么加工”的问题;
提质增效:打造满足AI-Ready要求的数据集,解决“好不好用”的问题;
应用赋能:打造“场景牵引数据、数据驱动模型、模型赋能应用”的数据飞轮,解决“怎么用”的问题;
管理服务:构建全生命周期管理体系,解决“怎么管”的问题;
价值释放:探索以词元为基础的数据价值体系,培育“为高质量数据付费”的市场共识,解决“如何释放价值”的问题。
此外,工业和信息化部与国家数据局近期联合印发了《关于联合实施2026年“模数共振”行动的通知》,推动人工智能模型与数据资源协同互促、同频共振,目标到2026年底基本形成“数据—模型—场景应用”良性互促的循环。
在产业分析人士看来,在大模型能力持续攀升对高质量训练数据提出更高要求的当下,“模数共振”行动被视为打通“模型—数据—应用”正向循环的关键一步。
四、市场化信号:让数据从“包袱”变成“资产”
政策驱动之外,市场化机制同样在快速跟进。
一个值得关注的新动向是“词元交易”。
根据国家数据局印发的相关方案,未来将推动商业模式从基础数据包销售向API调用、模型化解决方案及全栈服务梯次跃升,探索以词元为基础、可量化、可定价的数据集价值体系。
这意味着高质量数据集正被纳入可交易资产的范畴,商业模式和定价机制正在从摸索走向制度化。

配套基础设施也在加速落地。4月29日,国家数据集管理服务平台发布并启动试运行,以数据集目录汇聚为基础,构建“物理分散、逻辑集中”的数据集管理体系。
从数据看,截至今年一季度,全国已建成高质量数据集超过11.6万个,总体量超过960PB;截至今年3月,我国日均词元调用量已超过140万亿。
五、地方响应:从工业大省到科创前沿
高质量数据集建设不只是国家层面的顶层设计,各地也在密集部署。
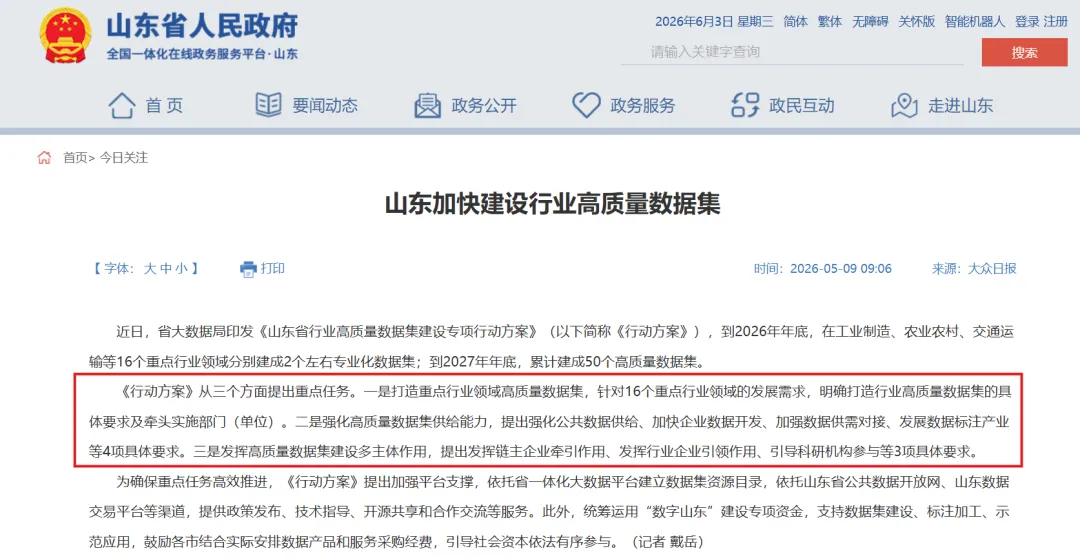
山东省大数据局印发的《山东省行业高质量数据集建设专项行动方案》明确提出,到2026年底在工业制造、交通运输等16个重点行业领域分别建成2个左右专业化数据集,到2027年底累计建成50个高质量数据集。
广东省政务服务和数据管理局联合广东省国资委正式启动了广东省国企高质量数据质效提升行动。
天津市也在博览会期间发布了50项需求清单,涵盖高速气象与地质灾害数据集、质量预测与工艺优化数据集等细分领域,指向精准、贴合产业实际。
可以看到,从山东到广东到天津,各地在高质量数据集建设上的布局已进入实操阶段,不再停留于概念层面。
六、产业趋势:数据正在成为决定胜负的“硬通货”
从市场规模看,这一趋势也有数据支撑。据埃森哲等机构统计,2025年全球AI训练数据集市场规模达457.1亿元,其中中国市场为122.9亿元,预计到2032年全球规模将达2127.5亿元,年复合增长率约28%。
在合成数据生成领域,2025年中国合成数据生成市场从2021年的9.5亿元增长至45.1亿元,年复合增长率约40%。

在具身智能领域,数据的稀缺性尤为突出。业内人士指出,当前全球高质量真实物理交互数据总量仅约50万小时,与实际需求存在巨大缺口。如何解决数据瓶颈,已成为具身智能商业化的核心课题。
过去几年,AI竞赛的主角是模型参数规模和算力。但随着参数竞赛的天花板逐渐显现,决定模型质量的关键变量正在向数据端迁移。谁的行业数据更丰富、更高质量、更贴合实际场景,谁就能在应用落地中占据先机。
具身智能的竞争,也是数据体系能力的竞争。”这句话的意义远不止具身智能——它适用于人工智能的各个领域。在这个意义上,数据不再只是模型的原材料,而是AI时代最核心的战略资源。
END


关注我们
翰联科技数据网
最了解你的科技网站

免责声明:我们尊重知识产权、数据隐私,只做内容的收集、整理及分享,发布于本平台的新闻、资讯、专访、行业洞察等相关内容,均不构成投资建议。报告内容来源于网络,报告版权归原撰写发布机构所有,通过公开合法渠道获得,如涉及侵权,请及时联系我们删除,如对报告内容存疑,请与撰写、发布机构联系,以上部分图片内容来自网络,如有侵权,联系删除获取更多行业资料请联系我司。
END
关注我们
翰联科技数据网
最了解你的科技网站
