夜雨聆风
夜雨聆风Garden 插件更新:每月 1 亿 Token 免费额度,一键接入国内外强力模型
主要更新说明
这次 Garden 插件更新信息如下:
1. 免费翻译模型大提额
每个注册用户每月 1 亿 token 的免费模型用量。之前测试了近半年的免费 GPT 资源,这次正式升级,额度拉满。
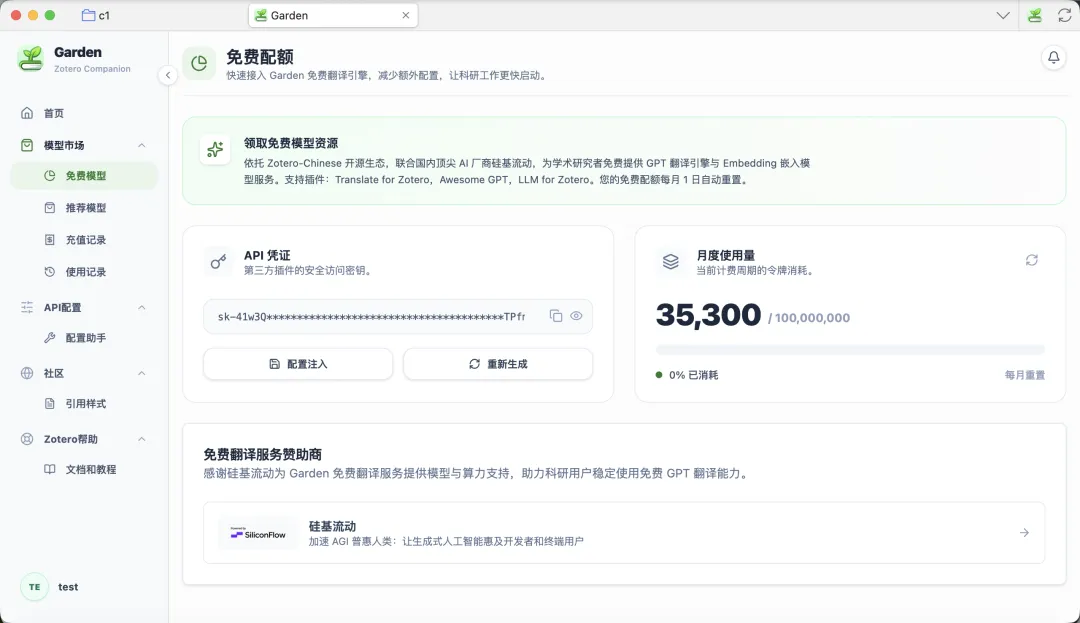
免费模型与免费配额界面
2. 新增推荐模型,一键接入顶尖模型
现在可以在 Garden 里直接接入国内外主流模型:DeepSeek、智谱、MiniMax、Gemini、GPT、Claude 各家。DeepSeek 系列官方原价,其他模型价格也压得很实惠。不用再到处找 API KEY,在 Zotero 里就能一键调用强力模型(点击注释配置即可)。Garden用户注册或首次充值任意金额即可赠送5元。
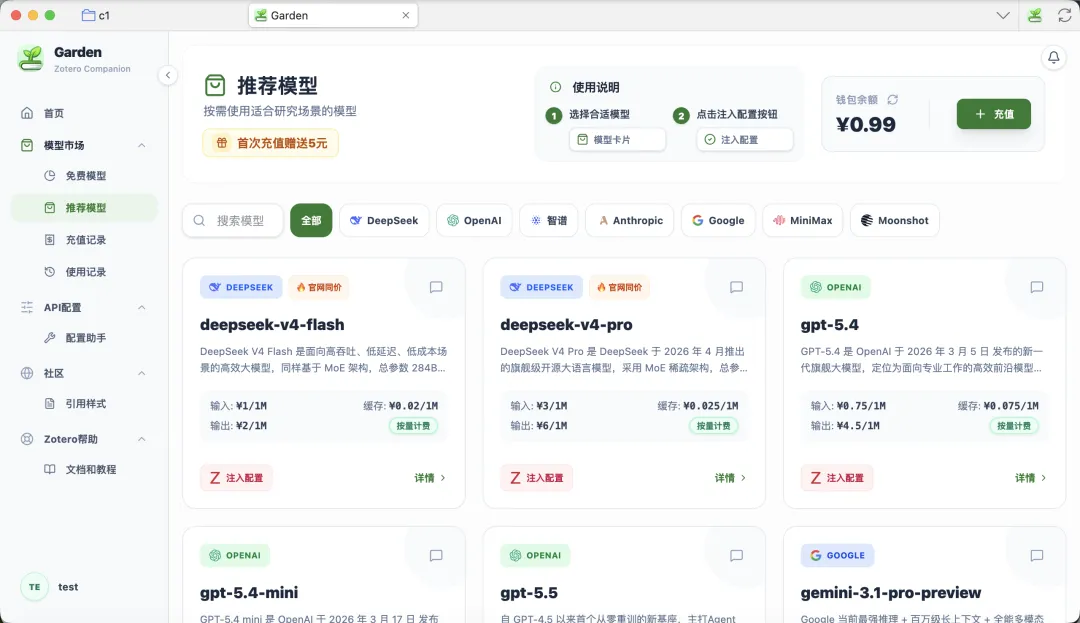
Garden 模型市场入口
3. UI 界面重调,配置更清晰
配置助手单独归到「API 配置」下,一级菜单更简洁。功能不变,但找起来更方便了。
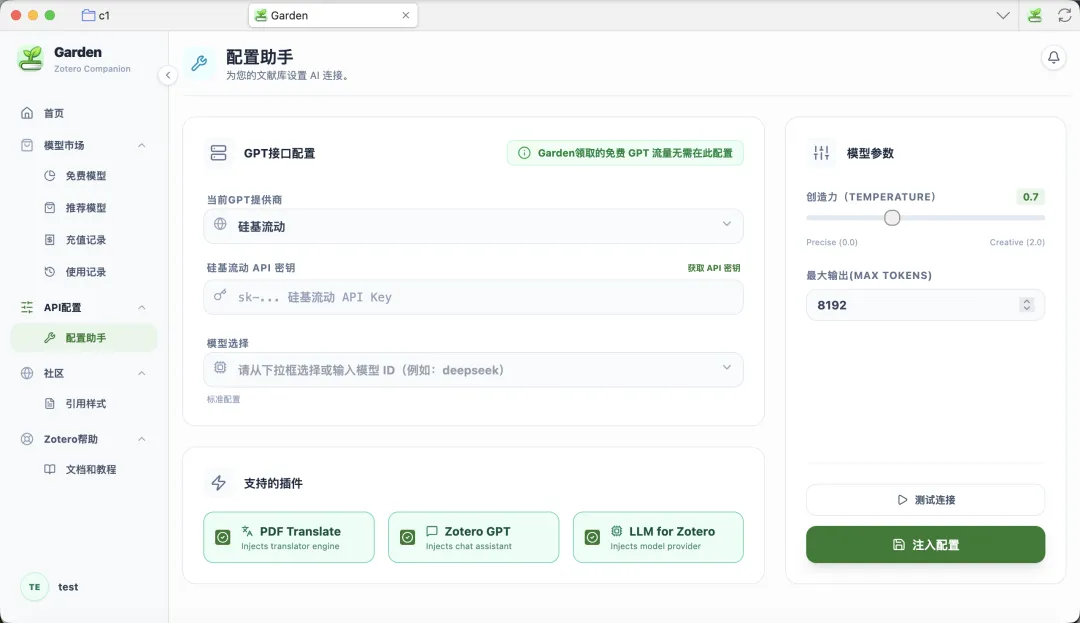
Garden 配置助手
4. Zotero内自动登录
现在只需要你注册成功,即可自动绑定到 Zotero 账号,实现自动登录,不需要再进行登录操作。
更新说完了,下面聊聊具体怎么用。假如你遇到以下场景:
你刚收了十几篇 PDF,想让 AI 帮你快速过一遍。
免费模型丢进去,吐出来三句话——像没睡醒的读书笔记:能看,但真不够用。(是否,我真的发现许多同学用免费的模型进行总结,效果太差了)
这种情况,我建议还是要挑选合适的模型,把适合的模型放到合适的使用场景中。
免费模型有它适合的位置,但不该被当成主力总结模型。这次更新真正好用的地方,是把不同模型放到不同环节里:免费模型负责翻译扫读,DeepSeek Flash 负责粗略总结,DeepSeek Pro 或其他强模型负责深入问答。
免费模型:别急着总结,先拿来翻译
说实话,免费模型拿来总结文献,输出结果会非常简单,真就是超精简总结。
如果期待它把研究问题、方法设计、实验逻辑和局限性都讲清楚,那就不太可能。
我更建议把 Magic 免费对话模型当翻译引擎用。两个地方可以用上(注意我们翻译引擎是开放的,可对接到其他类似插件中):
全文翻译:配合 Magic Zotero 的全文翻译插件,做前期 PDF 快速浏览。
划词翻译:同样可以接入翻译插件里,替代之前很多人用的知网翻译引擎。用过知网翻译的同学应该都遇到过——翻着翻着突然提示”使用异常”,频率一高就罢工。换成 Magic 免费模型之后,这个问题就不存在了,而且翻译质量比机器翻译更自然,读起来顺得多。
为什么翻译这么重要?
因为文献阅读的第一步,很多时候不是”总结”,是”先看懂”。
当你拿到文献时,你只是想搞清楚三件事:
这篇和我的课题有没有关系?——不相关的,没必要继续花模型额度和脑力。
方法部分大概在做什么?——很多论文看摘要很像,真正差异藏在方法里。
结果和结论有没有值得追的点?——有,才值得上更强的模型;没有,直接过。
1 亿 token 的免费额度,你要是真用完了,你可以来找我,我赠送你一些付费模型的额度(希望有同学能完成这个挑战)。
注意,是”过一遍”,不是”让它替你做深度阅读”。
粗略总结:换 DeepSeek Flash 上
一篇论文通过了翻译扫读,下一步才是粗略总结。
这里我不建议继续用免费模型硬撑。
更合适的是 DeepSeek Flash。
它的定位很清楚:便宜、速度快、适合批量处理。给文献做第一轮结构化总结,正好。
你可以让它回答这几个问题:
这篇文章研究什么问题?——帮你判断它值不值得进重点阅读列表。
作者用了什么方法?——方法决定它能不能给你的实验或分析带来参考。
主要发现是什么?——只看摘要,经常会错过真正有用的结果。
有哪些明显局限?——局限往往决定你后面要不要追问。
上次那篇《我用 DeepSeek 总结文献,算了一笔 token 账》里实测过一次。
27 篇文献,每篇分别跑 DeepSeek Flash 和 DeepSeek Pro,总共 54 次调用,按当时价格重算,总成本约 1.17 元,平均每篇约4分钱。
如果只看 Flash,更便宜:平均每篇约 1分钱, DeepSeek Pro 是 5 分钱一篇。
所以粗略总结不一定要省到用免费模型。Flash 已经便宜到适合批量跑,总结质量也通常比免费模型更适合做科研笔记。
深入问答:再切 DeepSeek Pro 或其他强模型
粗略总结跑完,你会筛出一小部分真正重要的论文。
这时候才该上更强的模型。
比如 DeepSeek Pro,或者 Garden 模型市场里的 OpenAI GPT、Gemini、Claude 模型。
这些模型,我留给更贵但更值的任务:
追问方法细节——关键论文不能只看到一句”使用了某某方法”,你得知道它为什么这样设计。
比较多篇文章的差异——综述和开题最难的地方,不是读单篇,是把几篇文章放到一张图里看。
挖局限和后续方向——这部分才可能变成你的实验设计、讨论段落,甚至课题切入点。
做全文答疑——读到一半卡住了,问一个具体问题,比让模型重新总结全文有用得多。
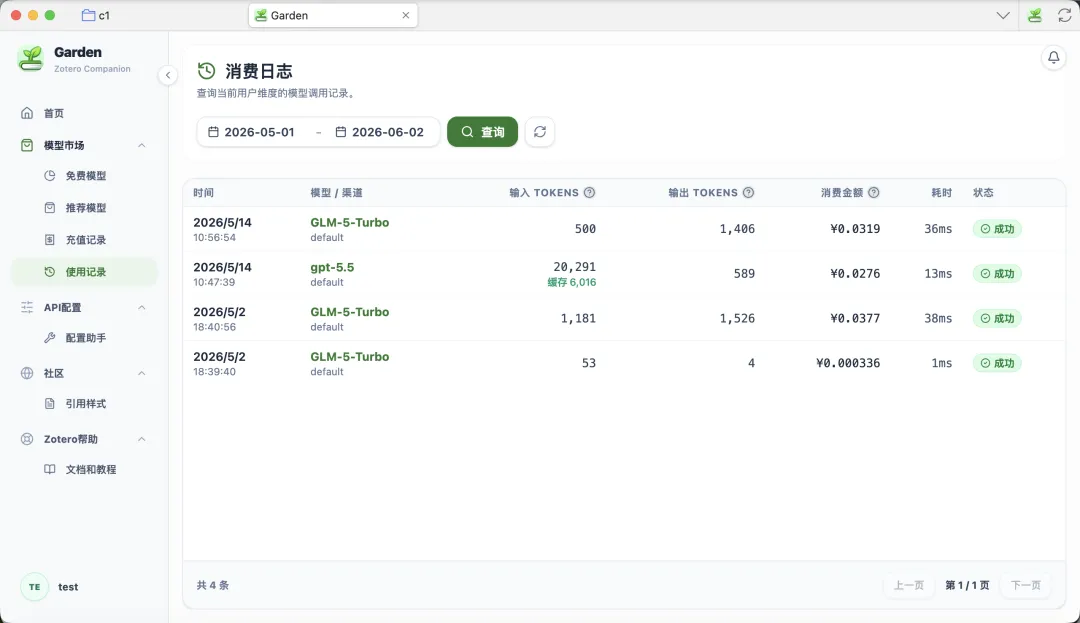
Garden 模型使用记录
不是让你每一步都用最贵的模型,而是让你知道每一步该用什么模型。
免费模型翻译扫读 → DeepSeek Flash 粗总结 → DeepSeek Pro 或其他强模型深挖。这个分工,比”一把梭”省钱,也更符合真实的阅读节奏。
配置插件:把合适的模型放到适合的地方
翻译插件(全文翻译 / 划词翻译)→ 接免费翻译模型。翻译调用频率最高,用免费额度最划算,而且再也不用担心知网翻译那种”使用异常”的提示了。
Awesome GPT / LLM for Zotero → 默认接 DeepSeek Flash。适合做快速总结、段落解释和初步阅读辅助。全文答疑需要模型理解细节,这里再切换到 DeepSeek Pro,别在这里省错钱。
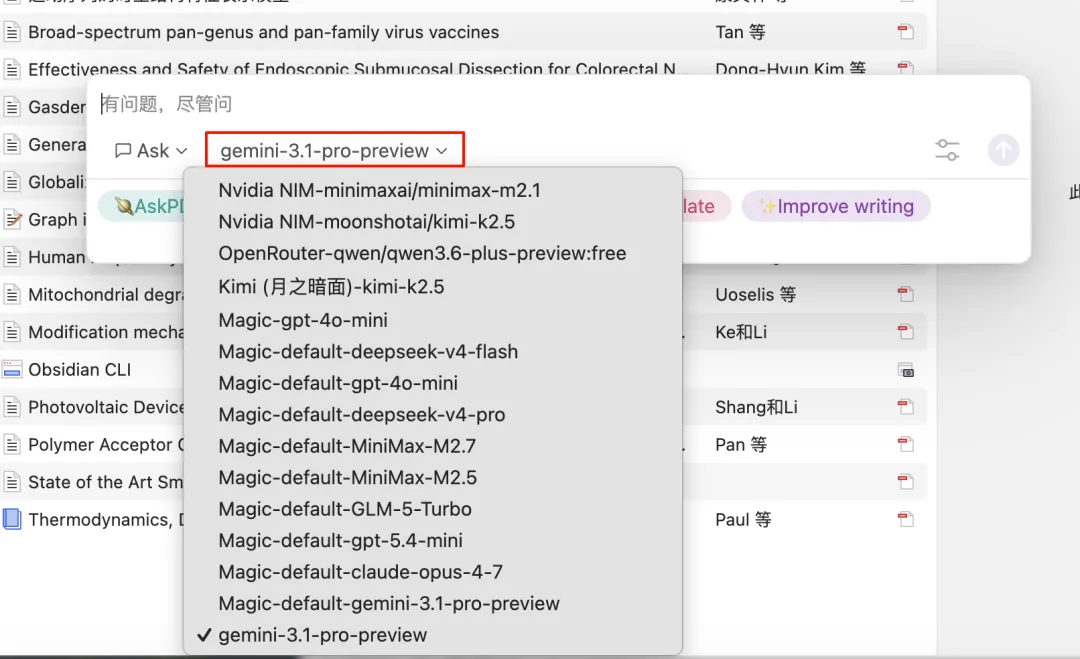
Awesome GPT插件模型切换窗口
当然,这不是唯一配法。如果你已经有自己购买的 API KEY,也可以继续在配置助手里填进去,再把模型对应到不同 Zotero 插件里。Garden 模型市场的好处,是让免费模型、推荐模型、自有 API KEY 都能在一个地方管理。
我的工作流建议
如果今天新收 20 篇 PDF,我不会每篇都拿强模型总结。
我会这么处理:
先用翻译插件配合免费模型,把 PDF 快速翻一遍。读的过程中随手划词翻译,遇到关键段落直接看懂。这一轮只判断相关性,不需要模型写得多漂亮。
挑出值得继续看的,用 DeepSeek Flash 做结构化粗总结。Flash 成本低,适合批量把文献变成可比较的笔记,也可搭配 Magic Zotero 文献矩阵功能,快速输出多篇文章不同维度的总结结果,方便对比。
遇到真正关键的论文,再切 DeepSeek Pro、OpenAI GPT、Gemini 或 Claude 做深入问答。深读阶段的问题更细,模型能力差距也更明显。
这个流程听起来多了一步,其实更省事——免费模型不再承担它不擅长的总结任务,强模型也不用浪费在一堆没用的 PDF 上。而且翻译这个最高频的需求,免费额度完全够用,不用再被知网翻译的”异常提示”打断节奏。
你今晚可以先试一个很小的版本:找 5 篇 PDF,用免费模型翻译扫读(全文翻译加划词翻译都试试),再拿 DeepSeek Flash 总结其中 2 篇,看看效果如何。
最后
以上提供的各个模型,均可用于兼容 OpenAI 接口的程序,可以借助 CC-switch 搭配 Claude Code 和 Codex 使用。
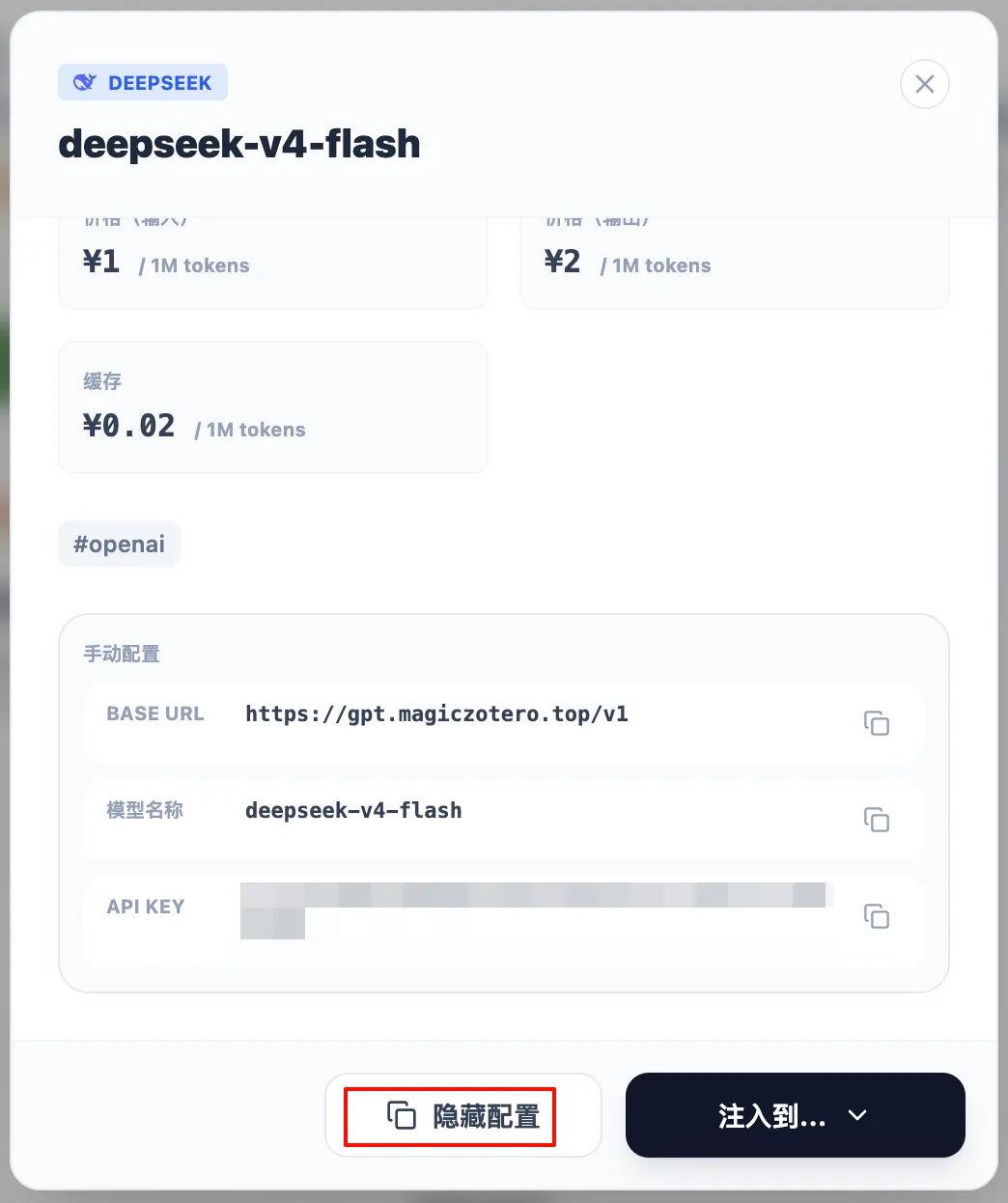
只需要点开感兴趣的模型右下角的详情页面,点击配置信息,即可看到完整的配置参数。