 夜雨聆风
夜雨聆风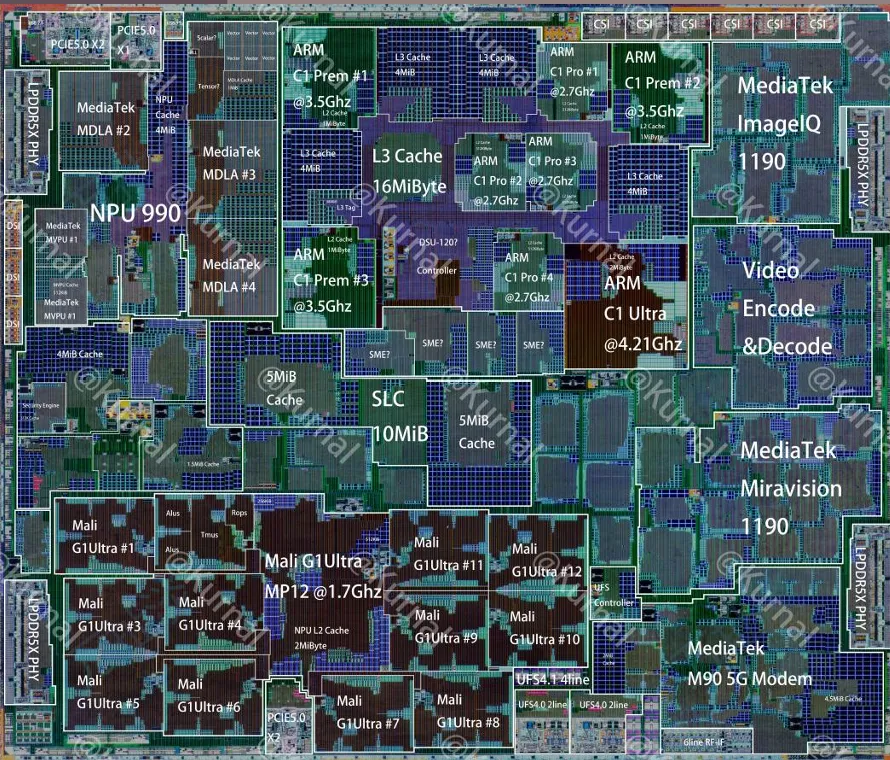
天玑9500发布的芯片架构图 from kurnal-insights
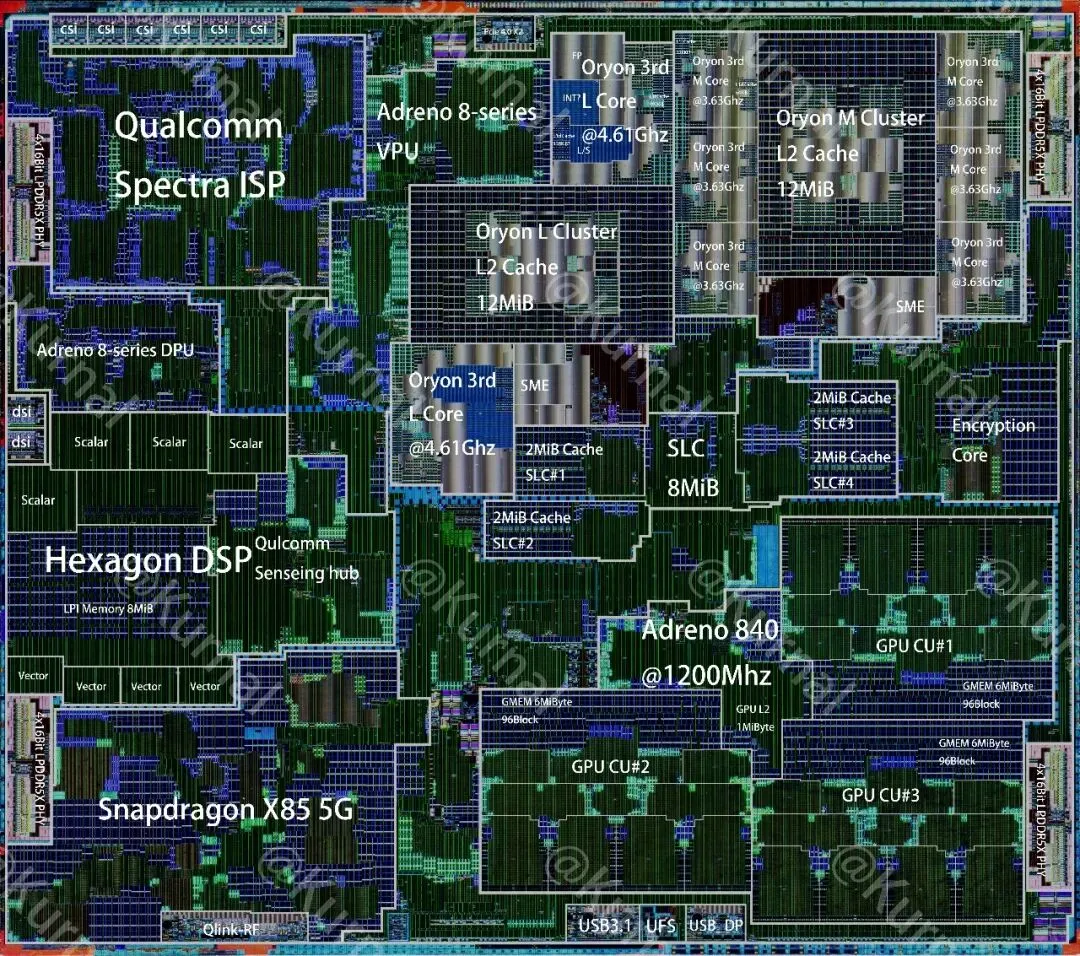
高通骁龙8 Elite Gen 5的芯片架构图 from kurnal-insights
🏆 芯皇登场:两种截然不同的设计哲学
高通骁龙8 Elite Gen 5与联发科天玑9500,同为台积电N3P工艺,却代表了两种芯片设计哲学的巅峰:
高通路线:垂直整合,自研优先。自研Oryon CPU + Adreno GPU + Hexagon NPU,强调峰值性能与生态控制。
联发科路线:Arm全家桶,能效优先。首发Arm最新C1系列全大核 + Mali-G1 Ultra GPU,用架构革新换取能效比。
🔍 SoC顶层架构全景:芯片内部长什么样?
我们绘制了两款芯片的模块级架构图,一眼看清内部布局差异:
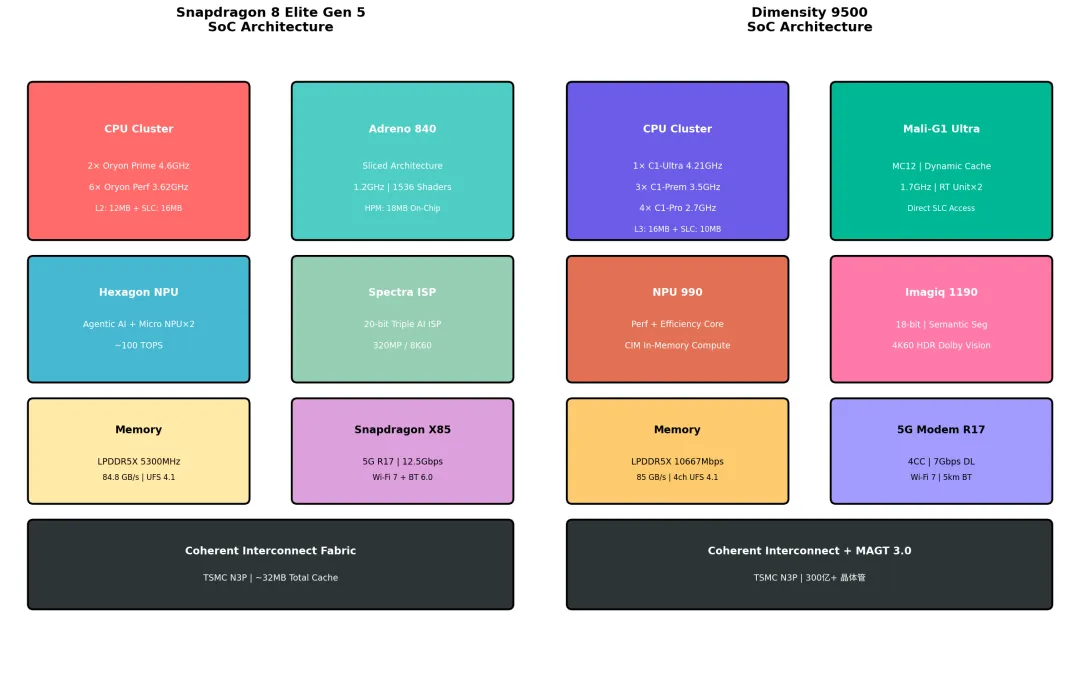
架构设计核心差异
| 设计维度 | 骁龙8 Elite Gen 5 | 天玑9500 |
|---|---|---|
| 晶体管规模 | 300亿+ | |
| CPU设计哲学 | ||
| 缓存策略 | ||
| GPU显存 | 18MB HPM片上显存 | |
| NPU架构 | ||
| 闪存接口 | 首发4通道UFS 4.1 |
⚡ CPU微架构深度拆解:Oryon vs C1
骁龙8 Elite Gen 5:第三代自研Oryon
核心配置:2× Oryon Prime 4.6GHz + 6× Oryon Performance 3.62GHz
缓存层级设计:
L1缓存:每核心192KB(64KB I-Cache + 128KB D-Cache)
L2缓存:Prime双核共享12MB,Performance六核共享12MB
系统级缓存(SLC):16MB,服务整个SoC的CPU/GPU/NPU一致性
总计片上缓存:约32MB+
架构亮点:高通彻底抛弃小核,采用"2+6"全大核设计。Oryon Prime核心频率冲上4.6GHz,创安卓手机芯片历史。自研架构意味着高通可以自主控制流水线深度、分支预测器和执行单元宽度,单核IPC(每时钟周期指令数)极高。
天玑9500:Arm C1系列全家桶
核心配置:1× C1-Ultra 4.21GHz + 3× C1-Premium 3.5GHz + 4× C1-Pro 2.7GHz
缓存层级设计:
L1缓存:较上代提升100%(具体容量未公开,预计256KB+)
L2缓存:C1-Ultra独享2MB,C1-Premium各1MB,C1-Pro各512KB
L3缓存:16MB(较上代提升33%)
系统级缓存(SLC):10MB
总计片上缓存:约19MB CPU高速缓存 + 10MB SLC
架构亮点:天玑9500采用三丛集全大核,没有小核。C1-Ultra基于Arm v9.3-A指令集,支持SME2矩阵运算指令集,这对端侧AI和图形计算至关重要。联发科通过精细的缓存分级,让不同负载匹配不同核心,避免"大马拉小车"的功耗浪费。
CPU架构结论:高通胜在自研自由度和单核峰值频率;联发科赢在缓存层级精细化和多核能效调度。
🎮 GPU架构对决:Adreno 840 vs Mali-G1 Ultra
Adreno 840:Sliced架构 + 片上HPM显存
高通Adreno 840采用Sliced GPU架构,核心规格:
1536个着色器,3组Pipeline,主频1.2GHz
算力:3686.4 GFLOPS
18MB HPM(High Performance Memory):这是Adreno 840的杀手锏——在GPU核心旁集成独立高速显存,降低fetch延迟,减少DRAM访问
这意味着重载游戏时,Adreno 840可以在片上完成大量纹理和帧缓冲操作,功耗效率提升显著。配合Snapdragon Elite Gaming,支持硬件级光追和VRS(可变速率着色)。
Mali-G1 Ultra:Dynamic Cache + SLC直通
联发科Mali-G1 Ultra MC12采用Dynamic Cache动态缓存架构:
12核心,主频1.7GHz
动态缓存:根据寄存器压力实时调整线程数量,减少寄存器浪费,让GPU长时间保持满载
SLC直通:GPU可直接读取10MB系统缓存,在《绝区零》等游戏中可节省600MB/s内存带宽,降低60mA电流和1℃温度
光追单元较上代翻倍,3DMark Solar Bay Extreme光追测试跑出2773分,提升119%。
GPU架构结论:高通Adreno靠片上HPM赢峰值帧率;联发科Mali靠Dynamic Cache+SLC直通赢持续能效和光追。
🧠 NPU与AI模块:Agentic AI时代
| 模块 | 骁龙8 Elite Gen 5 | 天玑9500 |
|---|---|---|
| NPU型号 | ||
| 架构 | 超性能核 + 超能效核 | |
| 特色技术 | CIM存算一体 | |
| AI算力 | ||
| 端侧AI |
高通Hexagon在传感器中枢额外集成两个Micro NPU和两个始终启用的ISP通道,用于语音、环境监测、手势识别等轻量级连续感知任务,不唤醒主NPU即可维持端侧智能。
联发科NPU 990的"超能效核"采用CIM(Compute-In-Memory)存算一体架构,将计算直接放在存储单元完成,避免数据搬运功耗,同性能下AI功耗降低56%。
📸 ISP影像模块:20-bit vs 18-bit
| ISP模块 | 骁龙Spectra | 天玑Imagiq 1190 |
|---|---|---|
| 位宽 | 20-bit Triple AI ISP | |
| 最大像素 | 320MP单摄 | |
| 视频 | ||
| 特色 |
高通的20-bit ISP在动态范围和色彩精度上占优,联发科则强调RAW域处理引擎和4K60 HDR杜比视界的实时渲染能力。
📡 基带与连接:X85 vs 集成R17
| 连接模块 | 骁龙X85 | 天玑集成5G R17 |
|---|---|---|
| 制式 | ||
| 下行峰值 | 12.5 Gbps | |
| 载波聚合 | 4CC四载波聚合 | |
| Wi-Fi | ||
| 蓝牙 | 蓝牙6.0 |
高通X85作为独立基带方案,峰值速率更高;联发科集成基带强调5km蓝牙直连(无需蜂窝网络)和四载波聚合的稳定性。
💾 内存子系统:带宽与延迟的暗战
| 内存参数 | 骁龙8 Elite Gen 5 | 天玑9500 |
|---|---|---|
| 内存类型 | ||
| 等效频率 | 10667 Mbps | |
| 理论带宽 | 85 GB/s | |
| 闪存 | 4通道 UFS 4.1 | |
| 带宽优势 |
天玑9500首发4通道UFS 4.1,连续读取性能提升100%,大模型载入速度提升40%。这意味着安装大型游戏(如《原神》《崩坏:星穹铁道》)和加载AI模型时,天玑9500的存储IO更具优势。
📊 模块性能实测对比
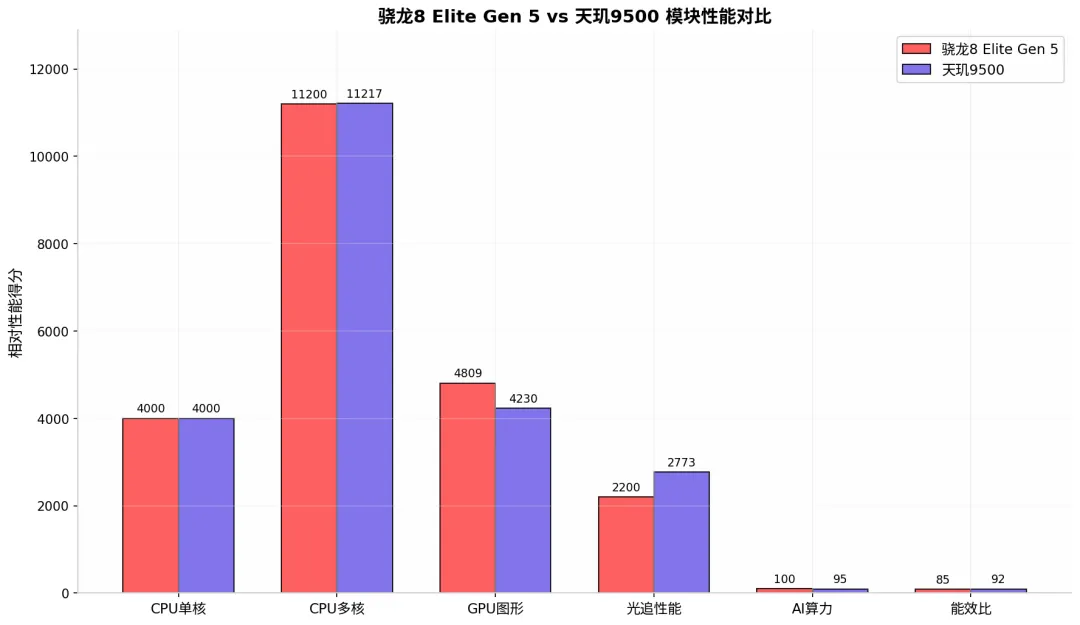
从实测数据看:
CPU单核:两者均突破4000分,几乎持平
CPU多核:天玑9500以11217分险胜骁龙11200分
GPU图形:骁龙Adreno 840在3DMark WLE中领先约13%
光追性能:天玑9500凭借翻倍光追单元,大幅领先约26%
能效比:天玑9500同性能功耗降低37%~42%,能效得分更高
🏭 工艺与封装:同为N3P,不同晶体管密度
两款芯片均采用台积电第三代3nm N3P工艺,但晶体管规模有差异:
天玑9500:300亿+晶体管,密度更高,集成度更强
骁龙8 Elite Gen 5:约290亿+晶体管,部分区域留给HPM显存和独立基带
联发科通过更高集成度实现全功能单芯片方案;高通则通过独立基带和片上HPM换取灵活性和峰值性能。
🏅 终极选购:架构视角下的选择
| 用户类型 | 推荐芯片 | 核心理由 |
|---|---|---|
| 手游电竞党 | ||
| 光追画质党 | ||
| AI重度用户 | ||
| 续航焦虑党 | ||
| 影像创作者 | ||
| 性价比旗舰 |
🔚 总结:两种架构哲学的巅峰碰撞
骁龙8 Elite Gen 5像一台美式V8肌肉车:自研Oryon大排量引擎(4.6GHz)、Adreno HPM独立油箱、Hexagon智能电控,追求极致单核爆发和峰值性能。
天玑9500像一台日式混动超跑:Arm C1三电机协同(全大核)、Mali Dynamic Cache智能配电、NPU CIM能量回收,用300亿晶体管的精密集成换取能效与光追的均衡。
2026年的安卓旗舰,没有绝对的"安卓之王",只有最适合你使用场景的芯片架构。高通守住了单核与峰值GPU的王座,联发科则用全大核和存算一体NPU证明了"发哥高端真成了"。
双雄争霸,最终受益的,还是我们消费者。
