 夜雨聆风
夜雨聆风聆机阁 · 透过科技事件看本质
一家不写代码的AI公司凭什么融144亿元?
144亿元不是研发经费,是建厂钱
当AI可以自己做实验、自己发现新材料时,科学探索将从少数天才的灵感火花变成系统化的工程流程。
聆机 · 写于 2026年6月4日

一家不写代码的AI公司凭什么融144亿元?这是一家成立不到三年的公司,要融144亿元——它不写代码、不画图、不做聊天机器人。如果你还在用“AI等于聊天机器人”的框架理解这件事,那才是真正错过了重点。144亿元不是在融研发经费,而是在融建厂钱——一个AI从数字世界跨入物理世界的信号。
你可能会想:AI做实验,跟我有什么关系?关系很大。如果Lila的假设成立,你未来吃的新药、用的电池、穿的衣服纤维,背后的研发成本都会大幅下降。当你需要一种新药时,它被开发出来的时间可能不再是10年,而是2到3年。
一个融资数字,藏着三个被误读的信号
2026年6月3日,彭博社独家报道:总部位于马萨诸塞州剑桥市的AI初创公司Lila Sciences正在洽谈约144亿元的新一轮融资,投前估值约612亿元。距离上一轮融资仅过去不到8个月,估值翻了6.5倍。投资人名单里包括Nvidia旗下NVentures、Flagship Pioneering、General Catalyst,以及Cathie Wood的ARK Invest。
看起来又像是一条“AI公司融了大钱”的新闻。但这种表层的理解恰恰掩盖了真正重要的东西。
Lila Sciences不是又一家AI药物发现公司。它不做预测、不做筛选、不做老药新用。它做的事情可以用一句话概括:把整个科学实验室——实验设计、假设验证、试剂调配、数据采集、结果分析——交给AI自主运行。
这是一个从数字世界跨入物理世界的尝试。生成式AI处理的是文本、图像和代码——这些东西的边际复制成本趋近于零。但Lila的AI每做一个实验,都要消耗实打实的试剂、能源和时间。144亿元不是在融研发经费,而是在融建厂钱。
大多数人在这件事上有三个误读。
第一个误读:它只是一家AI药物公司。实际上Lila横跨生命科学、材料科学和化学三个领域,同时在做mRNA序列优化、新型抗体筛选、非铂族金属催化剂开发、工业碳捕获材料。AI药物只是它的一条业务线。
第二个误读:612亿元估值是泡沫,因为公司还没产品。实际上Lila已经展示了可验证的成果——mRNA构建效率是现有技术的3倍,非铂催化剂性能等效于铂、成本仅为千分之一。只是还没有全部经同行评审公开。
第三个误读:竞争对手很多,它只是一家普通AI公司。Lila真正的护城河是闭环实验数据——互联网上有海量文本,但没有任何公开数据集可以训练一个科学家级别的实验AI。Lila每做一个实验,就在积累竞争对手无法复制的独家数据。

图:三个被误读的信号
AI做实验的底层逻辑:三层闭环飞轮
要理解Lila的价值,必须回到第一性原理问一个问题:AI的能力边界到底在哪里?
ChatGPT的知识来自互联网文本——这是人类已经写出并公开的内容。AlphaFold的知识来自蛋白质数据库——这是人类已经解析的结构。它们都在学习人类已知的东西。
但科学发现的核心是未知的探索。地球上的新材料、新药物、新催化剂尚未被发现,因此也没有现成的训练数据。这是AI在科学领域面临的根本障碍——没有数据源。
Lila的突破在于:不用等人类提供数据,而是自己生成数据。
它的核心机制是一个“实验→学习→改进实验”的闭环飞轮,分三层运行。
第一层是知识层。 AI模型不仅训练于所有已发表的科学文献和专利,还会吸收每一次自家实验的全部结果记录——包括成功和失败的数据。科学实验中的失败往往比成功更有价值,因为它排除了一个可能性。传统的论文发表有发表偏倚——只有阳性结果才会被发表。Lila的模型没有这个偏见,它记录所有的阴性结果。
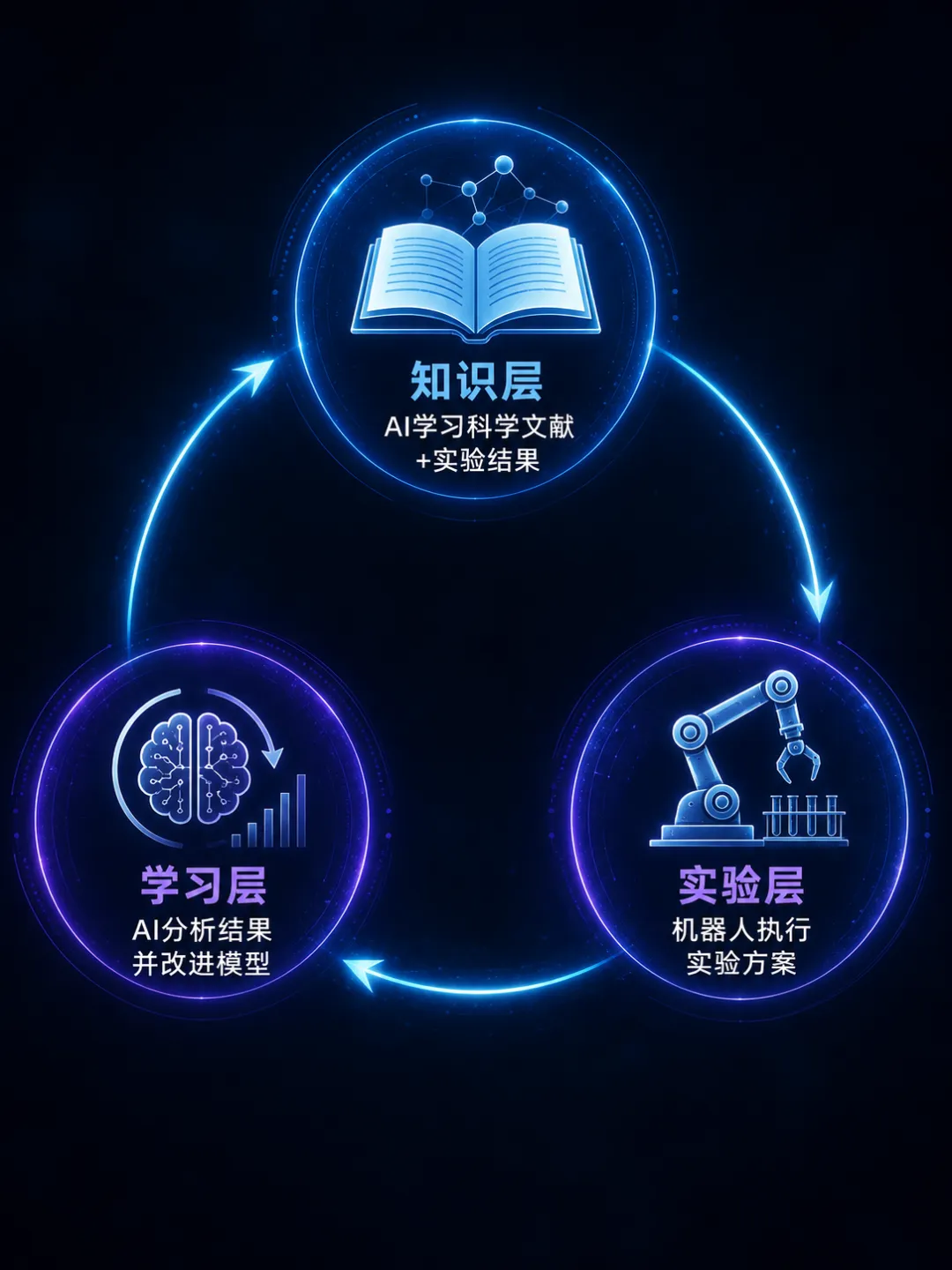
图:三层闭环飞轮
第二层是实验层。 机器人操作系统将AI提出的实验方案转化为具体的操作指令——分配试剂、控制温度、测量输出、记录结果。这里的瓶颈不是AI的大脑,而是机器人的手:机械臂的精度、液体处理器的速度、传感器的灵敏度。传统实验室中,一个博士生一天最多能做5到10个平行实验。Lila的一个自动化实验室一天可以做几百个实验。机器人不会累、不会分心、不会手抖——实验的可重复性远高于人类。
第三层是学习层。 实验结果反馈回AI模型,更新它的科学假设,生成下一个实验的设计。这就是主动学习的核心:AI不是被动地分析已有的数据,而是主动地选择最值得做的下一个实验。人类倾向于在已知领域深耕,因为失败的成本高。AI倾向于探索未知空间,因为它的探索成本远低于人类——跑一个额外实验只需要分配机器时间。
这个飞轮的关键指标是闭环速度——从提出假设到验证假设的时间。传统模式是:人类做实验→记录数据→训练AI→AI做预测→人类验证预测。一个循环以周甚至月为单位。Lila的模式是:AI设计实验→机器人执行→AI分析结果→AI改进模型→AI设计下一个实验。这个循环以小时或天为单位。
这种效率差距在案例中已经显现。2025年,3个非专业人士(不是科学家)用Lila的平台,在4个月内发现了比现有疫苗技术mRNA效率高3倍的序列。传统制药公司一个类似的mRNA构建优化项目通常需要12到24个月。4个月对12到24个月——这是量级级别的差距。
商业逻辑上,Lila的差异化也很清晰。它的商业化路径是“科学即服务”——企业客户付费获取AI科学平台的访问权限。Lila保留知识产权,通过许可和合作将成果商业化。这有点像Arm的IP授权模式:不是卖产品,而是卖发现能力。
Nvidia投资Lila的逻辑更是值得深挖。黄仁勋不是在投资一家科学公司,而是在播种未来的算力需求。如果AI科学工厂成功,它需要的算力可能远超生成式AI——因为每个物理实验的模拟和数据分析都需要大量的GPU计算。Nvidia不是在赌Lila的成功,而是在赌“AI做实验”成为一个新的大规模计算场景。
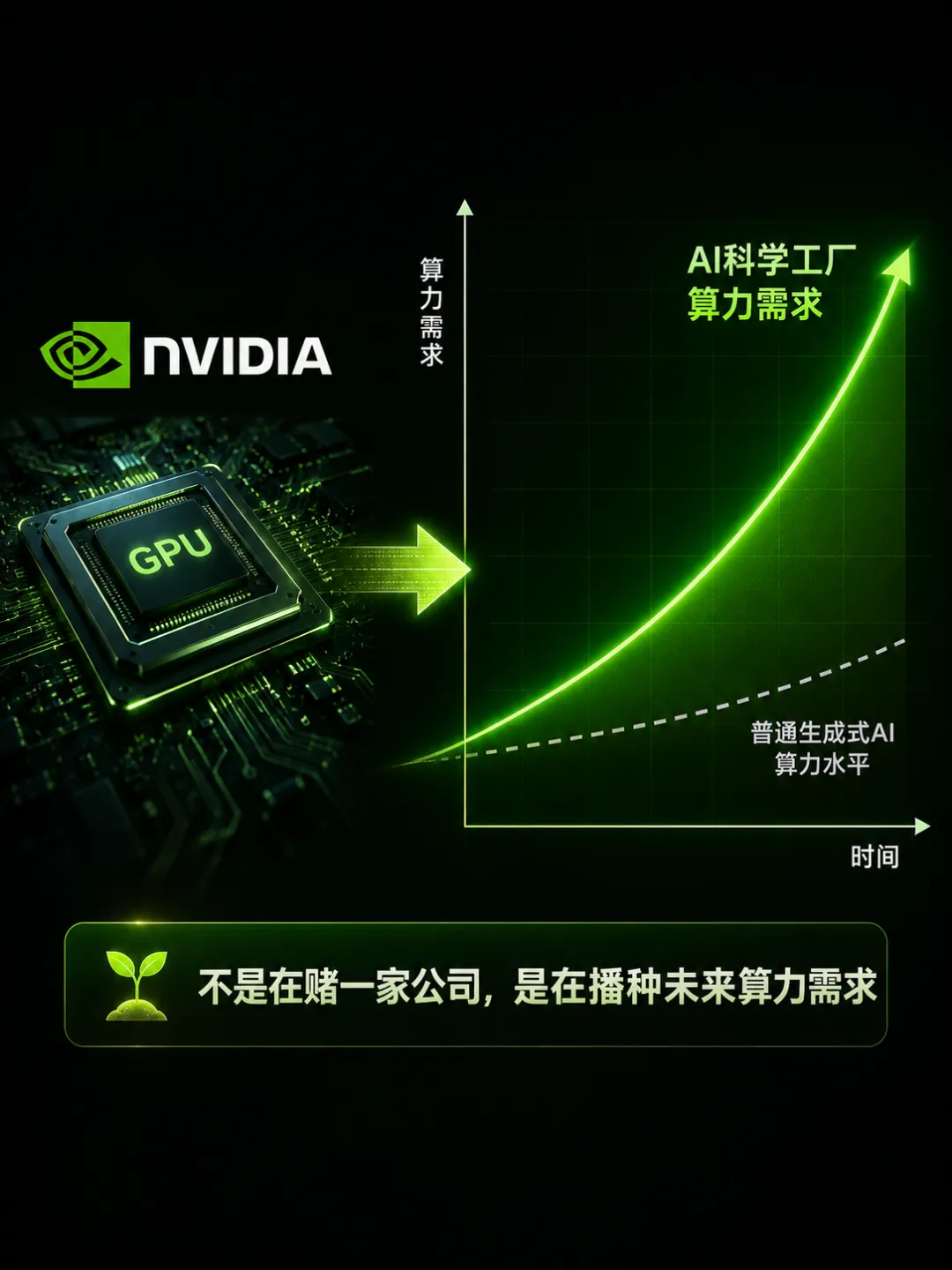
图:Nvidia的算力赌注
这场变革,正在重写三张账单
对AI产业来说,Lila这轮融资标志着AI投资重心的转移。标志性事件:Nvidia投资Lila,而不是投资又一家ChatGPT竞品。这说明黄仁勋认为AI的下一个大市场在科学发现,而不是内容生成。与此同时,竞争对手Periodic Labs(由前OpenAI和DeepMind研究员创立)也在洽谈约504亿元的融资。这意味着AI科学公司的估值已经和前沿模型公司处于同一量级。
对全球经济来说,如果AI科学工厂模式可行,将从根本上重塑研发密集型行业的成本结构。创新药的开发成本从187亿元可能降至数亿元;新材料从偶然发现变成定向合成;绿色氢能从催化剂成本问题中解放。全球研发行业等于被装了一个10倍加速器。
但硬币的反面:科学发现本身的商品化。如果AI可以自主发现新药,传统制药公司的研发优势将大幅削弱。那些依靠专利壁垒的商业模式将面临AI加速的创新竞争——你花10年建立的技术护城河,AI可能用1年就找到了绕路方案。
更深一层看,这还意味着科学人才的价值重定价。过去一个顶尖科学家能在实验室里带出5个PhD学生,他的影响力就被放大5倍。未来一个顶尖科学家如果能教会AI如何设计实验,他的影响力可能被放大1000倍。科学界的“超级个体”时代正在来临。
对个人来说,最直接的感受是:新药上市的速度加快,新技术产品的迭代周期缩短。但更深层的影响是——当AI开始自己做实验,科学家这个职业定义需要重新思考。未来10年,博士研究员可能和今天的程序员一样,面临AI的就业替代压力。
但这不必然意味着悲观。更可能的图景是:每一个受过训练的科学从业者都能用AI做更快的科学发现——就像今天每一个程序员都能用AI辅助写代码一样。门槛降低了,产出放大了。
普通人如何判断AI科学工厂的真伪?
面对“AI科学工厂”这股浪潮,普通人最需要的是判断标准,不是预测。这里有三把尺子,可以帮助你在未来几个月里自己判断这个赛道的真伪。
第一把尺子:看有没有实验室。不是所有AI科学公司都等于Lila。核心差异在于闭环物理实验——如果一家AI科学公司没有自己的实验室和机器人,它只是在做预测,不是在搞发现。未来12个月内,如果再有3到5家同类公司获得72亿元以上的融资,“AI科学工厂”这个赛道就可以确认是AI下一波的主战场。
第二把尺子:看成果有没有被独立复现。 科学的信条是可重复验证。Lila展示的催化剂千分之一成本、mRNA 3倍效率,需要经过独立实验室的重复验证才能确认。一个简单的判断方法:如果一家AI科学公司的成果只出现在自己的新闻稿里,而没有出现在学术期刊上,保持适度怀疑。
第三把尺子:算一笔比特与原子的账。数字AI公司的毛利率可达80%以上,因为API调用几乎没有边际成本。物理AI公司每做一个实验都要消耗试剂、设备折旧和能源。144亿元对于AI科学工厂来说只是入场券。
重资产模式意味着更低的毛利率和更长的回报周期。
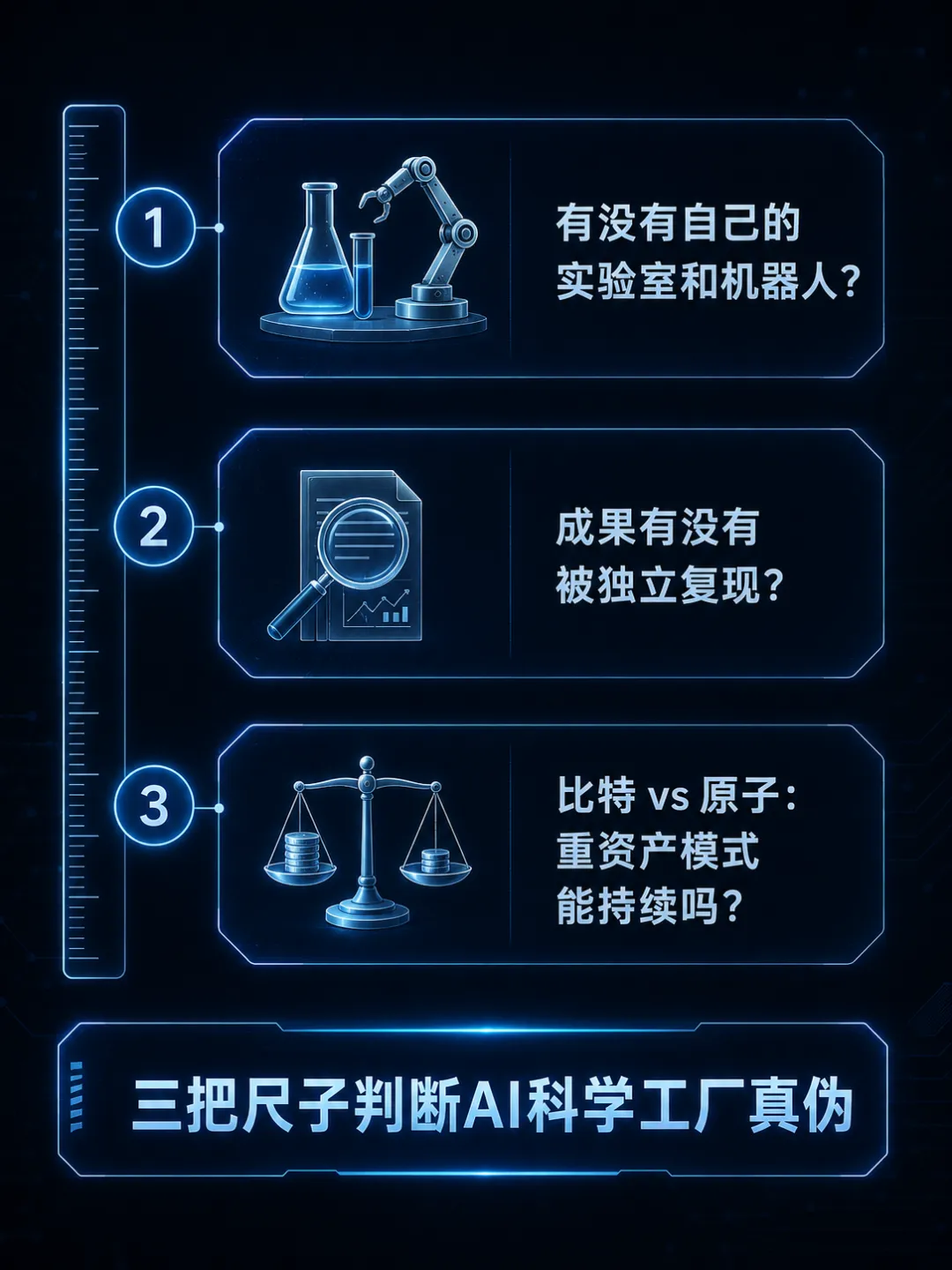
图:三把判断尺子
对科学从业者来说,未来5年,“AI加实验自动化”将成为科研标配。学习如何使用AI科学平台、如何设计可以被AI执行的实验,将和今天学习编程一样重要。这不是威胁,而是新工具——就像显微镜和PCR技术一样,是又一次科研工具的革命。
同时值得警惕的是:当一家公司宣布“AI发现了新药”或“AI找到了新材料”时,先问三个问题:有没有同行评审?有没有独立复现?有没有比现有方案真正的成本优势?如果三个答案都是否,那就先当作营销来看。
AI的下半场:从理解世界到改变世界
Lila Sciences的故事揭示了AI产业最深层的趋势:AI正在从理解世界走向改变世界。
第一波AI浪潮(生成式AI)改变了我们如何创造信息。从ChatGPT到Midjourney到Claude,它们处理的对象都是比特——数字世界的信息单元。这个时代的标志是:边际成本趋近于零,规模扩张是指数级的。
第二波AI浪潮(AI科学工厂)将改变我们如何创造物质。它处理的对象是原子——物理世界的基本构成单元。这个时代的标志是:每一个实验都有真实的成本,但科学发现的速度可能从年变成月。
比特和原子有根本性的不同。数字世界的AI可以无限复制;物理世界的AI每做一步都要消耗实打实的资源。但这恰恰意味着:真正有价值的科学发现,其商业护城河也更深。数字世界的AI公司之间的竞争是模型和数据的竞争;物理世界的AI公司之间的竞争是实验数据积累速度的竞争——这是更难逾越的壁垒。

图:从理解到改变世界
Lila的144亿元融资不是一个公司的融资新闻,它是一个历史时点的坐标。它告诉我们:AI的第二个时代,不再是关于人类已有的知识,而是关于人类尚未发现的知识。 在这个时代,最值钱的不是计算能力,不是算法,甚至不是数据——而是能够自主生成未知知识的能力。
当AI可以自己做实验、自己纠正假设、自己发现新材料时,科学探索将从少数天才的灵感火花变成系统化的工程流程。对人类社会来说,这可能意味着更快的药物、更便宜的材料、更清洁的能源。
科学民主化的时代,也许比我们想象的更近。而Lila Sciences的144亿元融资,只是这个时代的第一张入场券。
如果20年后回看2026年6月,我们可能会发现:今天所谓的“AI科学工厂”概念,就像2007年人们谈论智能手机一样——当时每个人都觉得它只是“能上网的手机”,很少有人预见到它会重塑餐饮、出行、支付、社交等一切行业。同样,现在我们把Lila理解为“AI做的实验室”,但20年后它可能成长为一个完全不同的东西——一个从科学发现到产品落地的完整系统。
正如第一波AI浪潮催生了万亿市值的公司,第二波AI浪潮——从比特到原子的跨越——可能催生出我们今天无法想象的产业格局。谁在建造通往这个新世界的实验室,谁就在定义未来20年的科学边界。
AI的第二个时代不再是关于人类已有的知识,而是关于人类尚未发现的知识——谁在建造通往新世界的实验室,谁就在定义未来20年的科学边界。
