夜雨聆风
夜雨聆风
2026 年 2 月,Anthropic 的 Judy Hanwen Shen 和 Alex Tamkin 发布了一篇很值得软件工程团队认真读的论文:《How AI Impacts Skill Formation》。它问了一个看似简单、但对所有 AI 编程实践都很关键的问题:
当开发者借助 AI 完成一个自己不熟悉的任务时,他们到底是在"边做边学",还是只是把任务外包给了 AI?
这篇论文的结论并不乐观:在一个随机对照实验中,使用 AI 助手完成新 Python 库任务的开发者,后续知识测验成绩显著下降。具体来说,AI 组在概念理解、代码阅读和调试能力上都更弱,测验分数比无 AI 组低约 17%,相当于 两个等级分,效应量 Cohen's d=0.738,p=0.010。
更有意思的是,AI 并没有带来显著的平均提速。也就是说,在这个实验里,AI 既没有明显让大家更快,反而让不少人学得更少。
[图1: 论文总体结果示意。左侧显示 AI 组在新库相关知识测验中明显低于无 AI 组;右侧展示六类 AI 使用模式,其中只有保持认知参与的三类模式能较好保留学习效果。]
一、问题不是"AI 会不会写代码",而是"人还会不会看代码"
过去几年,关于 AI 编程助手的研究,大多聚焦在生产力:Copilot 能不能让开发者更快提交 PR?Claude、ChatGPT 能不能帮咨询顾问、客服、律师提升产出?
已有研究确实给出了很多积极结果。例如:
一、AI 对呼叫中心员工平均提升约 15% 的问题处理量。
二、咨询顾问使用 AI 后平均多完成 12.2% 的任务。
三、GitHub Copilot 实验中,开发者完成任务速度提升 55.5%。
四、大型软件公司场景中,AI 代码补全带来约 26.8% 的生产力提升。
但这篇论文切换了视角:AI 帮你完成任务之后,你自己有没有变强?
这在软件工程里尤其关键。因为未来很多代码可能由 AI 生成,但上线前仍需要人类工程师做 review、debug、架构判断和安全把关。如果开发者从一开始就依赖 AI 学习新工具,那么他们是否还有能力监督 AI?
可以把 AI 想象成一台自动驾驶汽车。它可以帮你开很远,但如果你从未真正学会判断路况、控制方向盘,一旦自动驾驶犯错,你可能连哪里不对都看不出来。
编者注: 这其实是 AI 时代工程管理的核心矛盾之一。组织想要短期交付效率,但专业能力的形成依赖"慢变量":踩坑、调试、读文档、建立心智模型。AI 很擅长绕过这些痛苦环节,但那些痛苦恰恰是人成长的材料。
二、实验设计:让开发者学习一个陌生 Python 异步库 Trio
研究者选择了 Python 的 Trio 库作为实验对象。Trio 是一个用于异步并发和 I/O 处理的 Python 库,比标准库 asyncio 更小众一些,但概念足够清晰,适合观察"学习新库"的过程。
参与者都满足几个条件:
一、有超过一年 Python 经验;
二、每周至少使用一次 Python;
三、之前使用过 AI 编程助手;
四、从未使用过 Trio。
主实验共有 52 名参与者,随机分成两组:
一、AI 组:可以使用聊天式 AI 编程助手,底层模型是 GPT-4o,助手能看到当前代码,并且可以直接生成完整正确答案。
二、无 AI 组:不能使用 AI,只能依赖任务说明、示例和常规 web search。
实验流程分三步:
一、热身任务:所有人完成一个普通 Python 小题,不涉及异步概念,用来校准 Python 熟悉度。
二、Trio 编程任务:最多 35 分钟,完成两个使用 Trio 的任务。
三、知识测验:不能使用 AI,回答关于 Trio 的概念、代码阅读和调试问题。
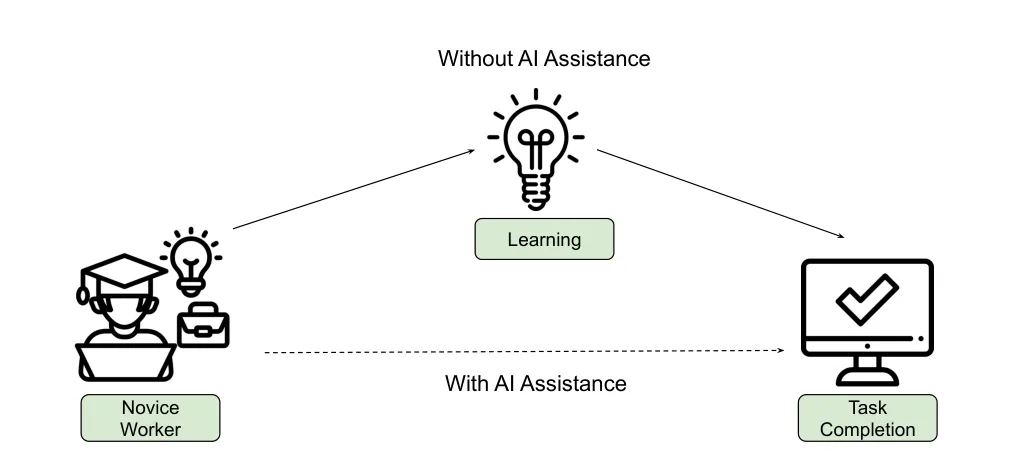
[图2: 实验框架示意。无 AI 路径中,开发者通过完成任务经历学习过程;AI 路径中,开发者可能跳过一部分学习,直接到达任务完成。]
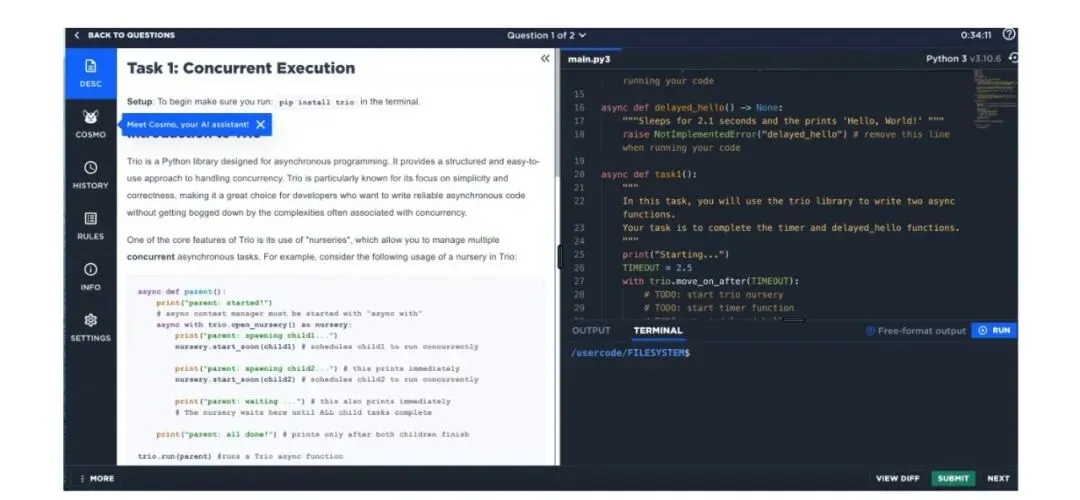
[图3: 实验界面示意。左侧是任务说明,右侧是代码编辑器;AI 组额外拥有聊天式 AI 助手入口。]
两个 Trio 任务分别是:
一、写一个计时器,在其他函数运行时每秒打印一次,涉及 nursery、并发启动任务等概念。
二、实现一个记录检索函数,处理缺失记录错误,涉及错误处理和 memory channel。
后续测验覆盖 7 个 Trio 核心概念,包括 async/await、启动 Trio 函数、错误传播、coroutine、memory channel、nursery 的打开关闭,以及顺序执行与并发执行的区别。最终测验共 14 题,27 分。
三、核心发现:AI 组学得显著更少,但并没有显著更快
主实验结果很直接。
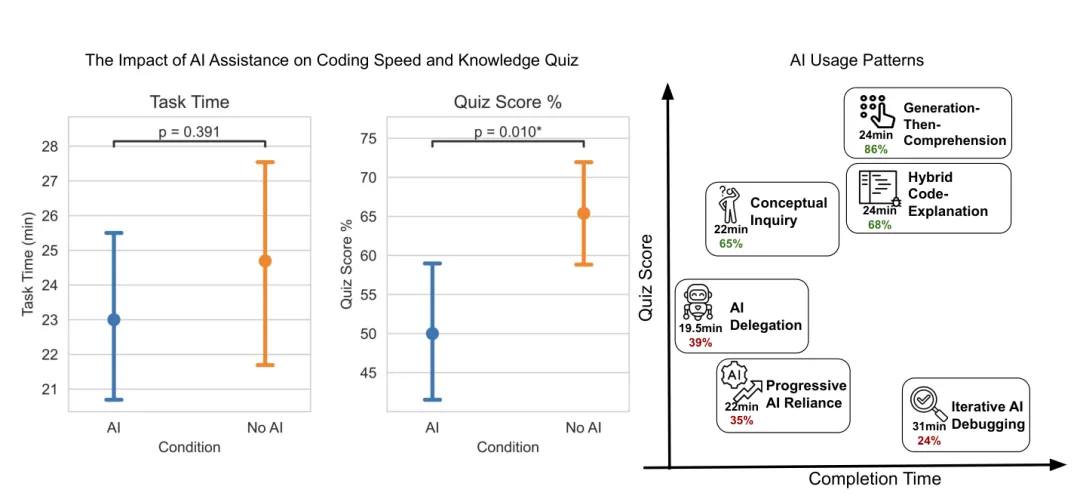
在任务完成时间上,AI 组平均更快一点,但差异不显著:
任务时间差异:p=0.391 结论:没有统计显著的提速效果
在知识测验上,AI 组显著更差:
测验分数下降约 4.15 分 总分 27 分,相当于约 17% 的差距 效应量:Cohen's d=0.738 显著性:p=0.010 控制热身任务时间后仍显著:Cohen's d=0.725,p=0.016
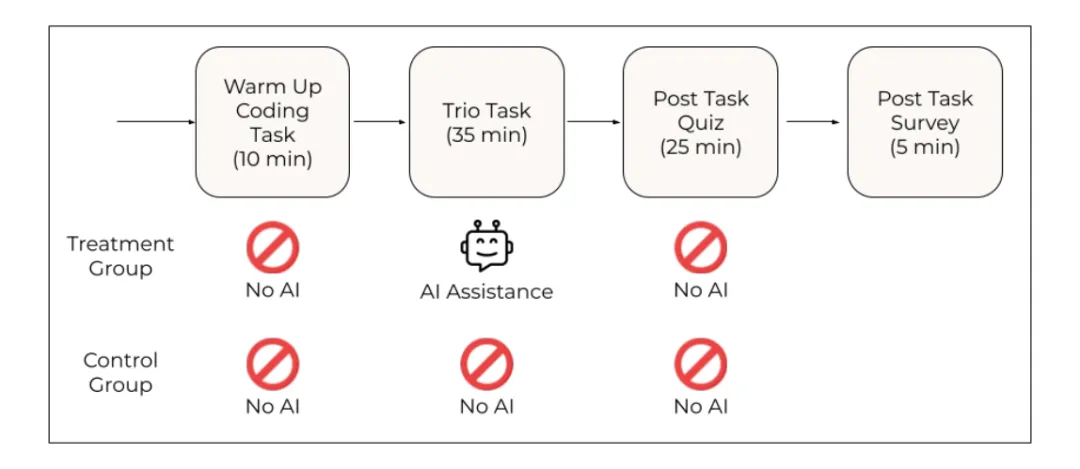
[图4: 实验流程图。所有参与者先完成无 AI 热身任务;随后进入 Trio 编程任务,AI 组可使用助手;最后所有人都在无 AI 条件下完成知识测验。]
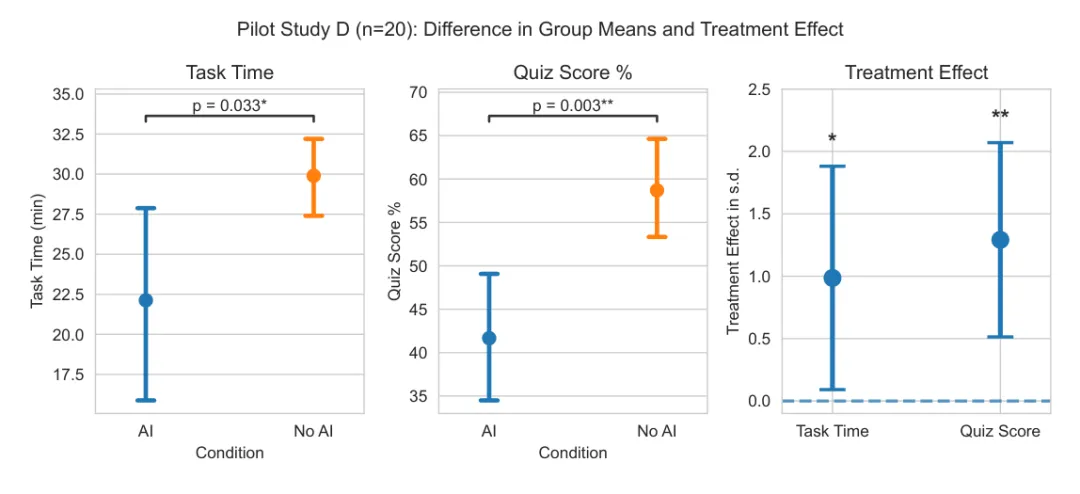
[图5: 试点实验 D 结果。AI 组完成任务显著更快,Cohen's d=1.11,p=0.03;但测验显著更差,Cohen's d=1.7,p=0.003。研究者随后调整任务,减少 Python 语法问题的干扰。]
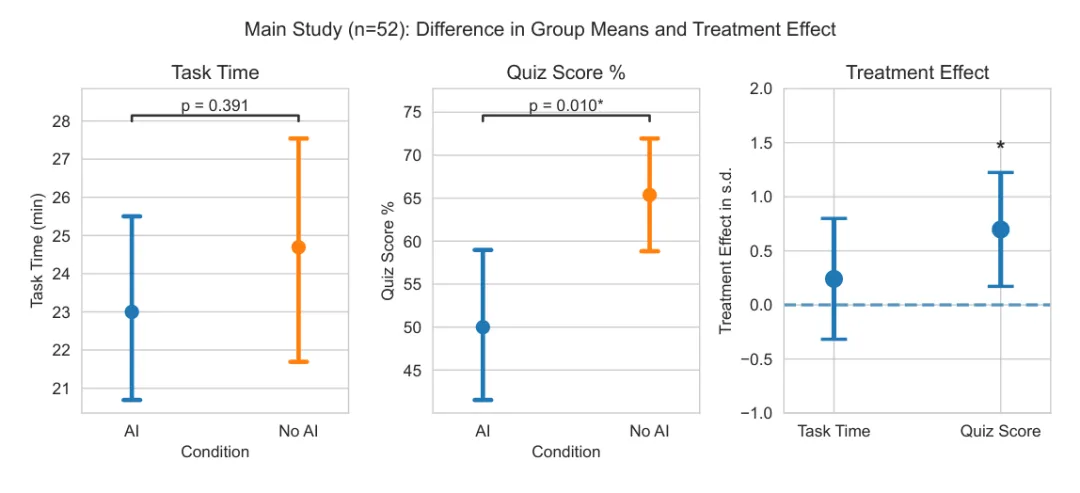
[图6: 主实验结果。AI 组任务时间没有显著改善,p=0.391;但测验成绩显著下降,Cohen's d=0.738,p=0.010。误差线为 95% 置信区间。]
这说明,在"学习新技能"的任务中,AI 的价值不像普通重复性编码任务那么稳定。它有时能帮你更快交付,但也可能让你跳过理解过程。
更细看不同经验水平,结果也很一致:不论参与者有 1-3 年、4-6 年还是 7 年以上编码经验,无 AI 组平均测验分数都更高。
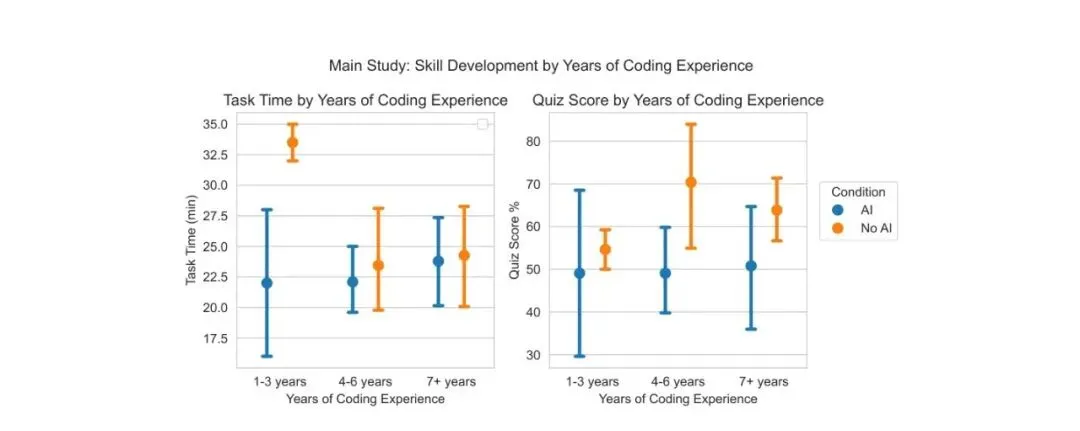
[图7: 按编码经验分组的任务时间和测验分数。不同经验水平下,无 AI 组测验平均分均高于 AI 组。]
四、最受影响的是调试能力:少踩坑,少长本事
研究者把测验题拆成三类:
一、Conceptual Understanding,概念理解;
二、Code Reading,代码阅读;
三、Debugging,调试能力。
结果显示,差距最大的是 Debugging 调试题,代码阅读题差距最小。
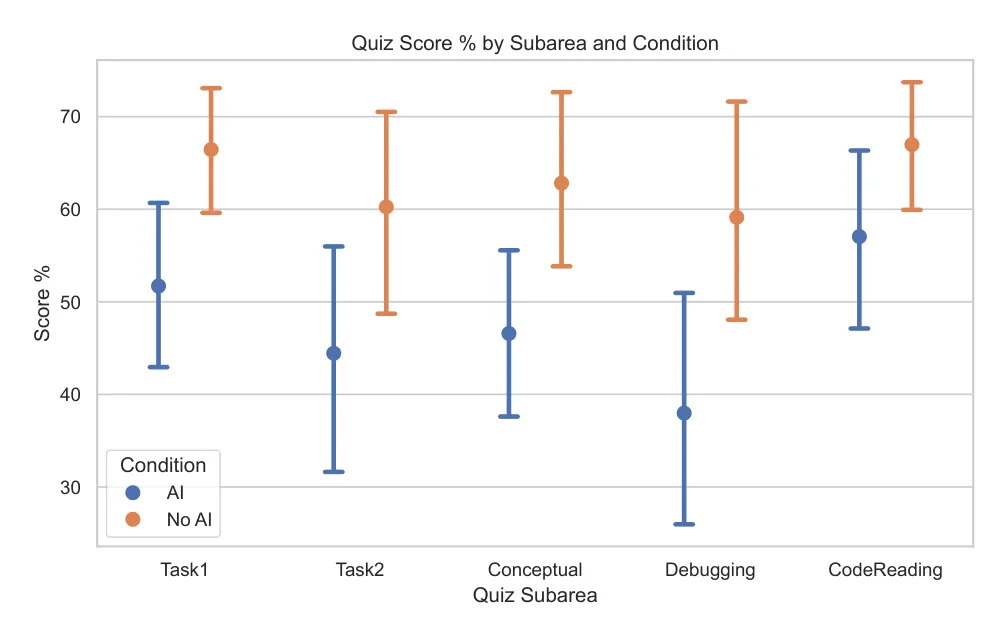
[图8: 按任务和题型拆分的测验成绩。AI 组在两个任务相关问题上均低于无 AI 组,其中调试题差距最大,代码阅读题差距最小。]
这很好理解。无 AI 组在完成任务时会遇到更多错误,需要自己判断错误信息、改代码、再运行。这个过程像健身里的"阻力训练":每一次报错都是一次负重。
AI 组则经常直接拿到更接近正确的代码,或者让 AI 帮忙排错。任务完成了,但"错误—假设—验证—修正"的循环少了。调试能力正是在这个循环里长出来的。
论文记录了参与者遇到的错误数量:
AI 组每人错误数中位数:1.0,四分位区间 0.0-3.0 无 AI 组每人错误数中位数:3.0,四分位区间 2.0-5.0
其中一些错误与 Trio 的关键概念直接相关,比如:
一、RuntimeWarning:coroutine 没有被 await;
二、TypeError:Trio 函数拿到了 coroutine object,而不是 async function。
这些错误不是简单拼写错误,而是在逼开发者理解异步模型。无 AI 组遇到更多这类 Trio 相关错误,因此也更可能真正掌握相关概念。
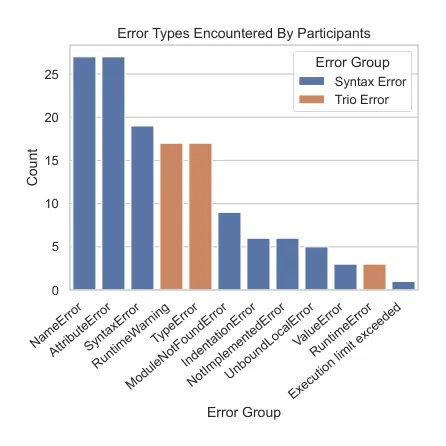
[图14: 所有参与者遇到的错误类型统计。NameError、AttributeError 等通用错误较多,但 RuntimeWarning、TypeError 等与 Trio 概念相关的错误对学习尤其关键。]
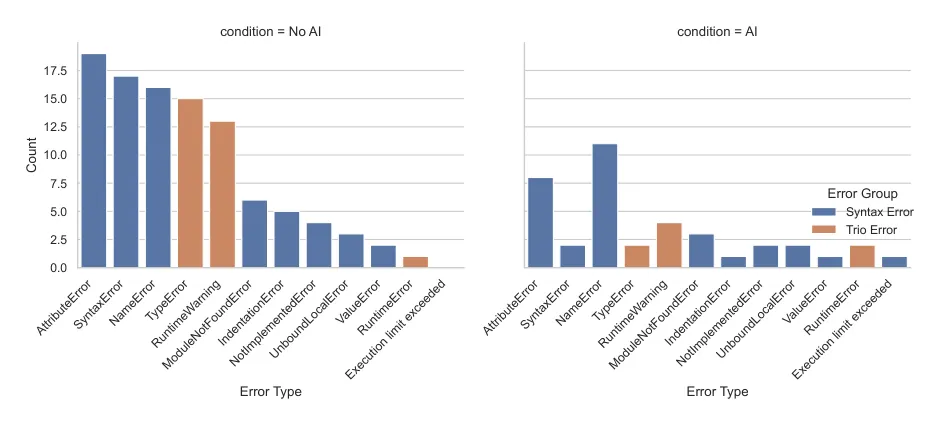
[图15: 按 AI/无 AI 条件拆分的错误统计。无 AI 组遇到更多与 Trio 核心概念相关的错误,因此获得了更多调试训练。]
编者注: 很多团队把"减少错误"视为纯收益,但从培养新人角度看,错误并不全是浪费。可控范围内的错误,是工程师形成判断力的训练样本。AI 如果把所有错误都提前消掉,可能也把学习机会一起消掉了。
五、为什么 AI 没有显著提速?因为"问 AI"本身也很耗时
论文的一个有趣发现是:AI 助手虽然能直接生成正确代码,但很多参与者并没有因此明显变快。
原因在于他们花了不少时间和 AI 互动。研究者逐一观看屏幕录像并标注行为,发现部分参与者:
一、最多问了 15 个问题; 二、总共花了最多 11 分钟 与 AI 交互; 三、有些人花了接近 6 分钟 构思单个 query; 四、有人把超过 30% 的任务时间用在写 prompt 上。
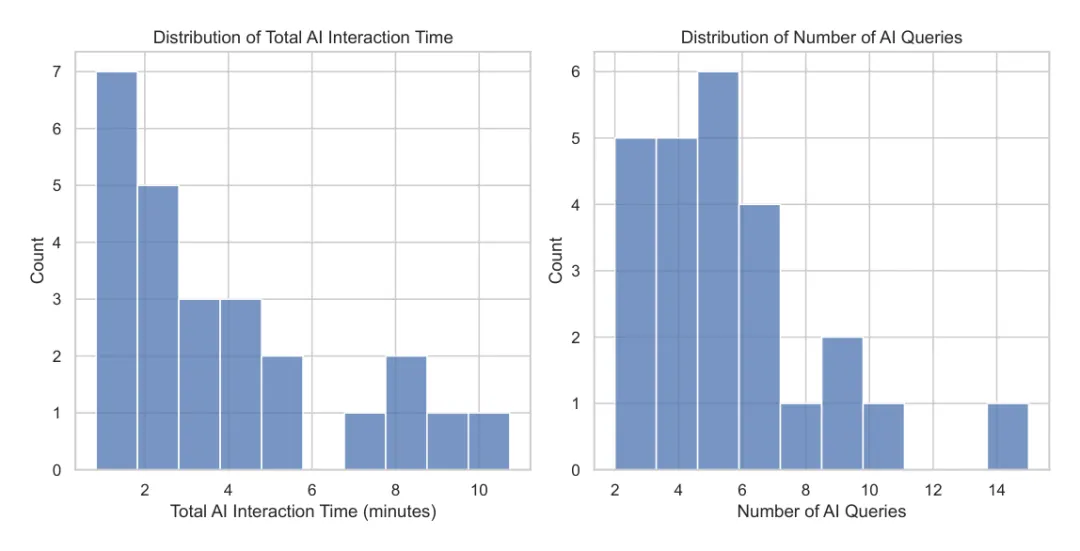
[图12: AI 组交互时间和提问次数分布。一些参与者在 35 分钟任务中花费超过 6 分钟与 AI 互动,解释了为什么 AI 组整体没有显著更快。]
从生产力角度看,这是开销;但从学习角度看,写问题有时也是思考。一个人为了问清楚问题,会重读说明、重构自己的困惑、比较不同表达。这种"把问题说清楚"的过程,本身就有学习价值。
论文也提醒:如果换成更自动化的 agentic coding tool,用户甚至不需要花时间写 prompt,那么认知卸载可能更严重。也就是说,未来 AI 工具越丝滑,学习损失可能越隐蔽。
六、六种 AI 使用人格:真正的分水岭是"有没有动脑"
研究者根据参与者如何使用 AI,总结出六种交互模式。这个部分非常适合团队培训时拿来讨论。
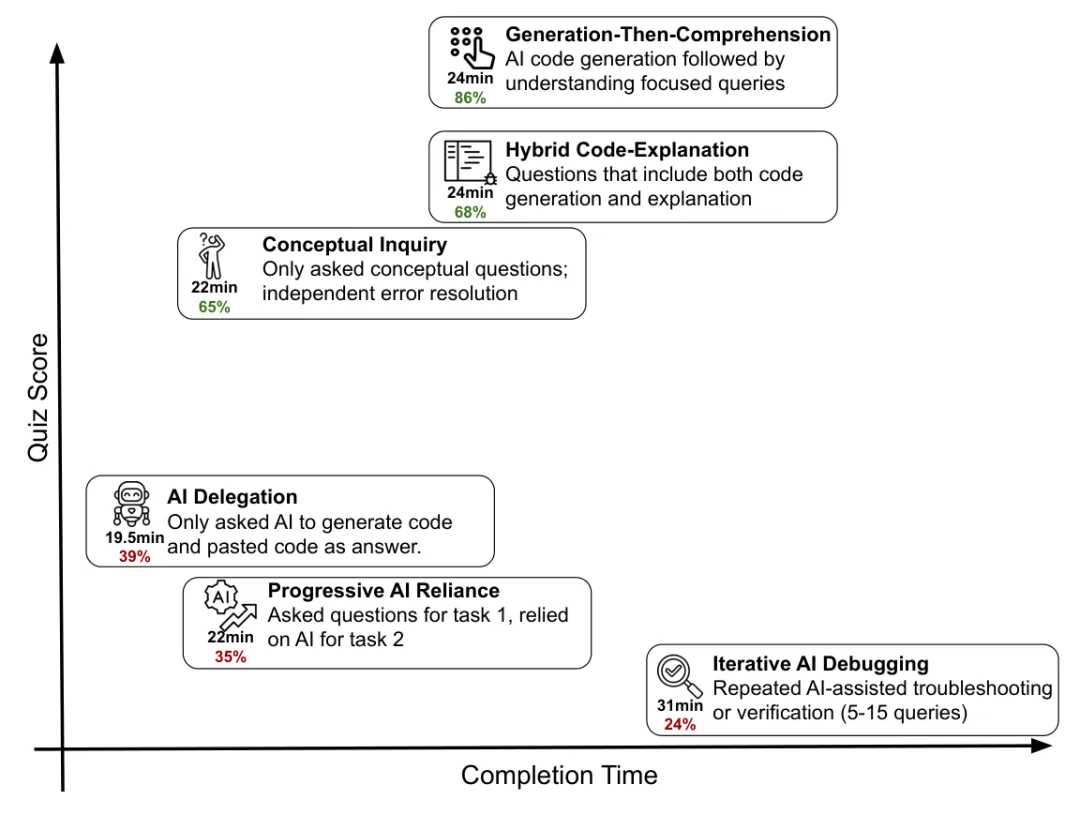
[图11: AI 组中的六类交互模式及其平均完成时间和测验分数。低分模式包括 AI Delegation、Progressive AI Reliance、Iterative AI Debugging;高分模式包括 Generation-Then-Comprehension、Hybrid Code-Explanation、Conceptual Inquiry。]
一、低分模式:把 AI 当外包
1. AI Delegation:完全委托
这类人只让 AI 生成代码,然后粘贴答案。
样本数:n=4 平均完成时间:19.5 分钟 平均测验分数:39%
他们确实最快,但学得很少。像是请别人替你跑完马拉松,奖牌拿到了,心肺没练到。
2. Progressive AI Reliance:逐步依赖
一开始还问一两个问题,后来直接把任务交给 AI。
样本数:n=4 平均完成时间:22 分钟 平均测验分数:35%
这类人尤其在第二个任务上没有建立概念模型。
3. Iterative AI Debugging:反复让 AI 调试
不断把错误或代码丢给 AI,让 AI 检查、修复、确认。
样本数:n=4 平均完成时间:31 分钟 平均测验分数:24%
这是最糟糕的一类:既慢,又学得少。论文还发现,调试类 query 占比越高,完成时间越长,测验分数越低:
调试 query 占比与完成时间相关:r=0.43,p=0.033 调试 query 占比与测验分数相关:r=-0.41,p=0.043
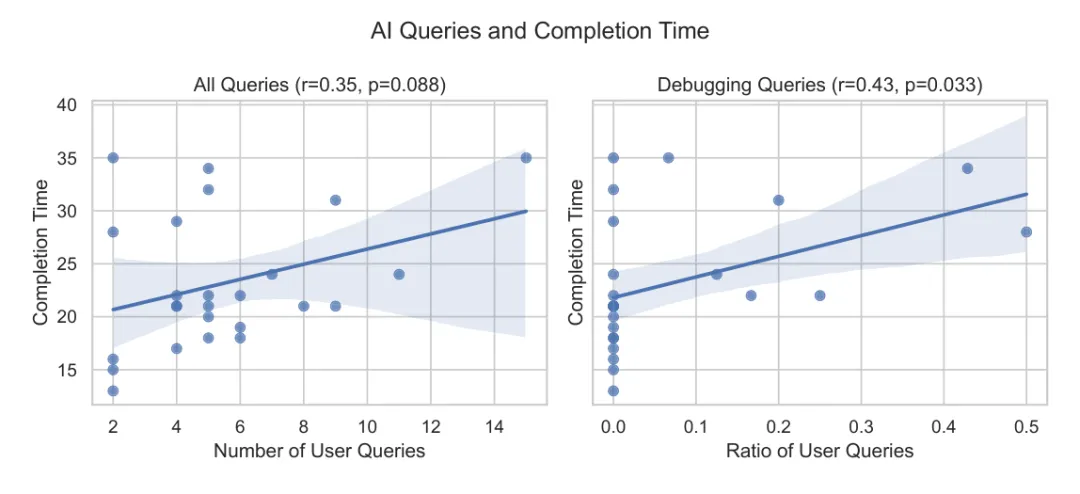
[图18: AI 提问与完成时间关系。总提问数与时间正相关但未显著;调试类问题占比越高,完成时间显著越长。]
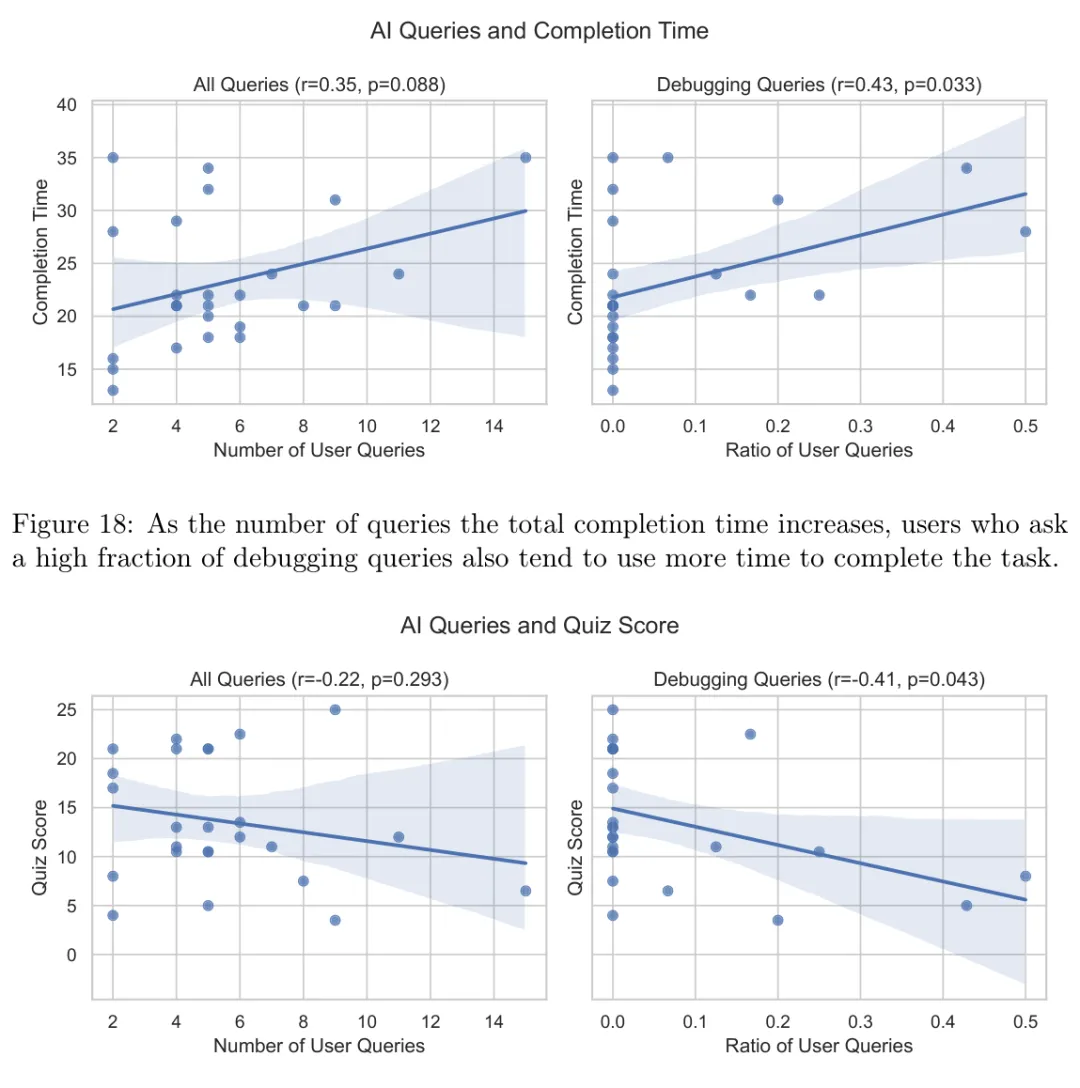
[图19: AI 提问与测验成绩关系。总提问数与成绩无清晰关系;调试类问题占比越高,测验成绩显著越低。]
二、高分模式:把 AI 当教练
4. Generation-Then-Comprehension:先生成,再理解
先让 AI 写代码,再追问为什么这么写。
样本数:n=2 平均完成时间:24 分钟 平均测验分数:86%
这类人看起来也用了生成代码,但关键差异在于:他们没有停在"能跑",而是继续追问"为什么"。
5. Hybrid Code-Explanation:代码和解释一起要
提问时明确要求 AI 给代码,同时解释实现思路。
样本数:n=3 平均完成时间:24 分钟 平均测验分数:68%
这种方式牺牲一点速度,但保留了理解。
6. Conceptual Inquiry:只问概念,自己写代码
只向 AI 问概念问题,错误自己解决。
样本数:n=7 平均完成时间:22 分钟 平均测验分数:65%
这是高分模式中最快的一类,也说明 AI 并非不能用于学习。关键是不要让 AI 替你完成最需要训练的那部分。
编者注: 如果要给团队制定 AI 编程规范,我会把这六类模式直接做成 checklist。不是简单禁止 AI,而是鼓励"解释型使用"和"概念型使用",限制"无脑粘贴"和"代替调试"。
七、复制粘贴最快,但不一定更懂
研究还观察了 AI 代码的采纳方式:有人直接粘贴 AI 输出,有人手动复制,有人混合使用,也有人基本自己写。
直接粘贴 AI 代码的人完成任务最快。但在测验分数上,手动敲一遍 AI 代码并没有明显更好。
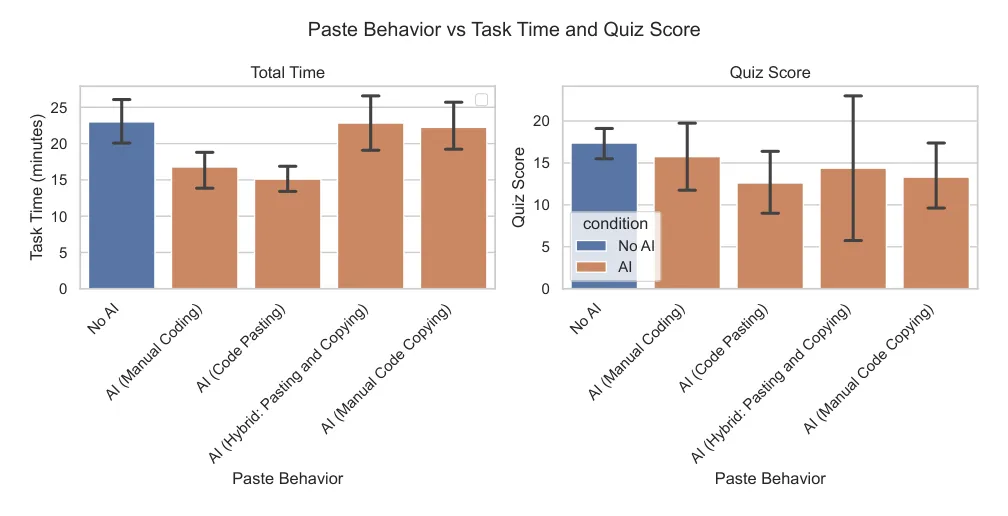
[图13: AI 代码采纳方式与任务时间、测验分数关系。直接粘贴 AI 输出的参与者最快;手动复制 AI 代码者速度接近无 AI 组,但测验分数并未明显更高。]
这说明,学习的关键不是"手有没有敲键盘",而是"脑子有没有处理信息"。机械地把 AI 代码打一遍,和复制粘贴本质差异不大;真正有用的是解释、比较、预测、验证。
八、参与者自己的感受:AI 让人"变懒"是有体感的
论文还收集了参与者反馈。AI 组中,有人说:
"用了 AI 助手之后,我感觉自己变懒了。我没有像平时那样仔细读 Trio 的介绍和代码示例。"
也有人说:
"我希望自己多花点时间理解 Cosmo 的解释。"
还有人提到:
"我对 Trio 有一个大概了解,但理解中仍有很多空白。"
相比之下,无 AI 组的反馈更偏向"任务有趣""说明帮助我理解 Trio"。这和量化结果互相印证:无 AI 组更辛苦,但也更像是在学习。
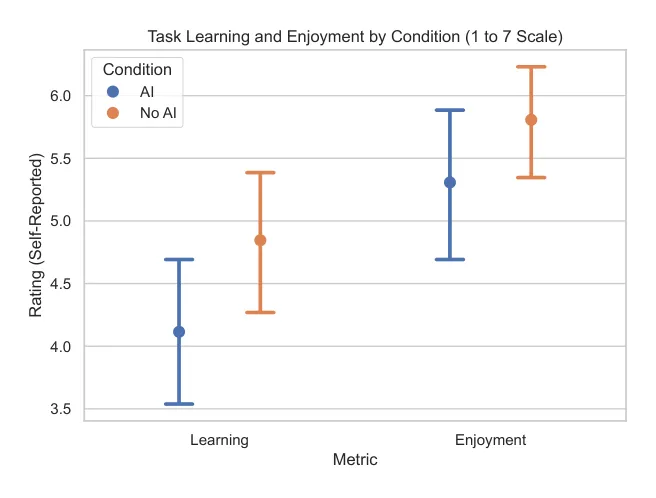
[图9: 自报告学习和愉悦度。无 AI 组报告了更高的学习感,两组任务愉悦度都较高。]
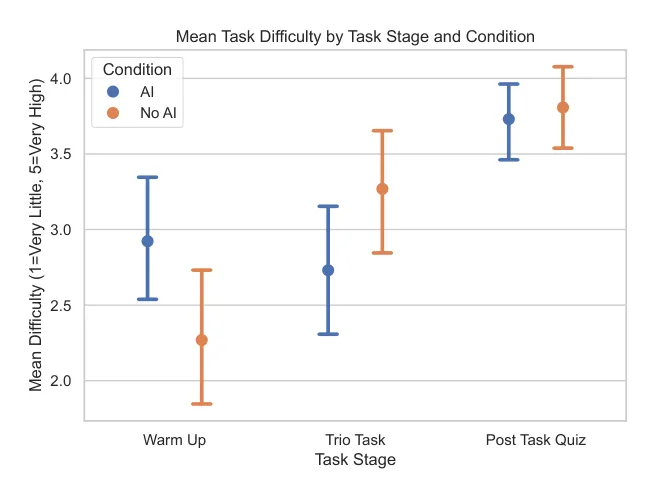
[图10: 不同阶段自报告难度。AI 组觉得 Trio 编程任务更容易,但两组都觉得后续测验有挑战。]
九、这篇论文对工程团队意味着什么?
这篇研究不是说"不要用 AI 写代码"。更准确地说,它提醒我们:
AI 带来的生产力收益,并不会自动转化为人的能力成长。
对软件团队,尤其是培养初级工程师的团队,有几个直接启示。
一、不要只看任务是否完成,还要看人是否形成理解。
二、对新人使用 AI,应优先鼓励"问概念、要解释、自己调试"。
三、代码评审中可以追问:这段 AI 生成代码为什么这样写?有哪些失败模式?
四、关键技能训练阶段,可以设置有限 AI 或学习模式,而不是全自动代理模式。
五、安全关键领域更要谨慎,因为未来人类需要监督 AI,而监督能力本身不能被 AI 外包掉。
从个人角度,也可以给自己定几条简单规则:
一、让 AI 写代码后,必须能用自己的话解释。
二、遇到错误时,先自己读一次 traceback,再问 AI。
三、问 AI 时多问"为什么"和"还有哪些替代方案",少问"直接给我答案"。
四、把 AI 当老师或结对伙伴,不要当代写外包。
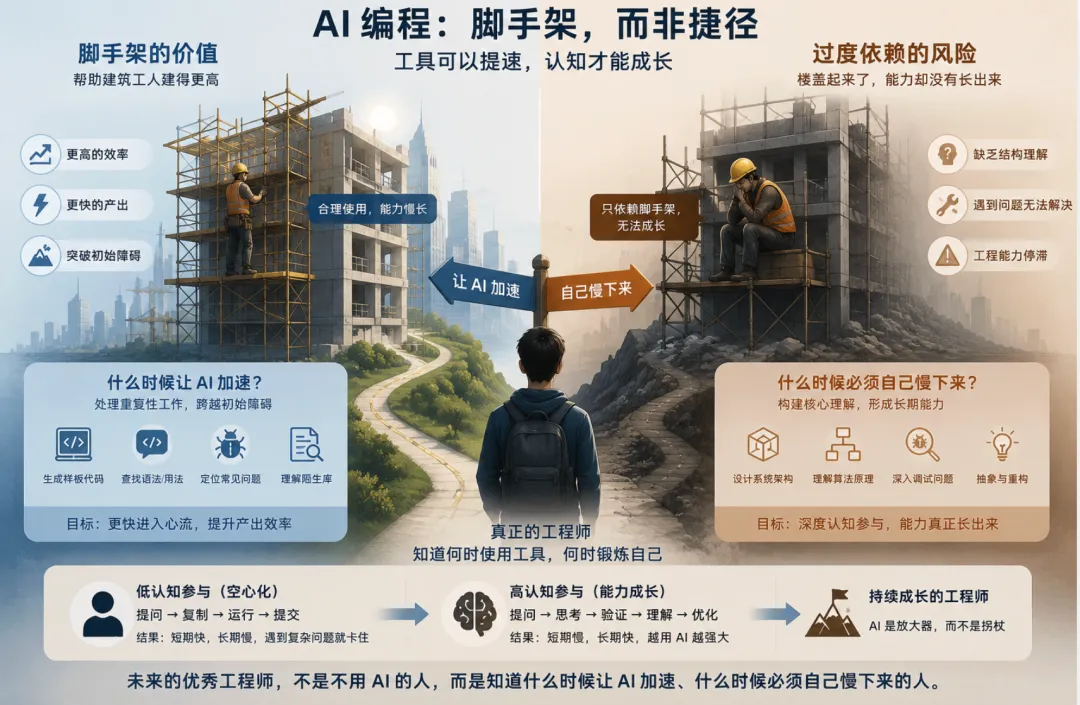
十、总结:AI 可以是脚手架,也可以是拐杖
这篇论文最有价值的地方,是把 AI 编程从"效率工具"重新放回"技能形成"的语境里。
脚手架可以帮助建筑工人建得更高,但如果人一直依赖脚手架而不理解结构,楼盖起来了,工程能力却没有长出来。AI 也是如此。它可以帮我们越过初始障碍,也可能让我们绕开最重要的学习环节。
对从业者来说,真正的问题不是"用不用 AI",而是"怎么用 AI 还能保持认知参与"。未来的优秀工程师,可能不是不用 AI 的人,而是知道什么时候让 AI 加速、什么时候必须自己慢下来的人。