 夜雨聆风
夜雨聆风上个月,我们团队在优化一个矩阵运算模块。算法是标准的矩阵乘法,复杂度 O(n³),没什么花活。我们的工程师花了两天时间把里面的循环重排、变量提前,能想到的编译器优化都做了。结果:性能提升了约 15%。
然后有个老哥走过来,看了一眼数据结构,说你这个矩阵是行主序还是列主序?我们说行主序。他说,改成列主序试试。
就这一个改动。性能翻了 5 倍。
同一个算法,同一个编译器,同一台机器。唯一变的是数据在内存里的排列方式。那一刻我真正意识到:现代软件开发的本质,早已不是算法之争,而是缓存战争。
最近上线了一套【AI Coding实战课程】,把用AI做开发的整套方法都拆开讲清楚了,如果你也在用AI写代码,但感觉用不顺,想系统提升AI编程能力,可以看下方海报了解详情👇

CPU 缓存是怎么工作的
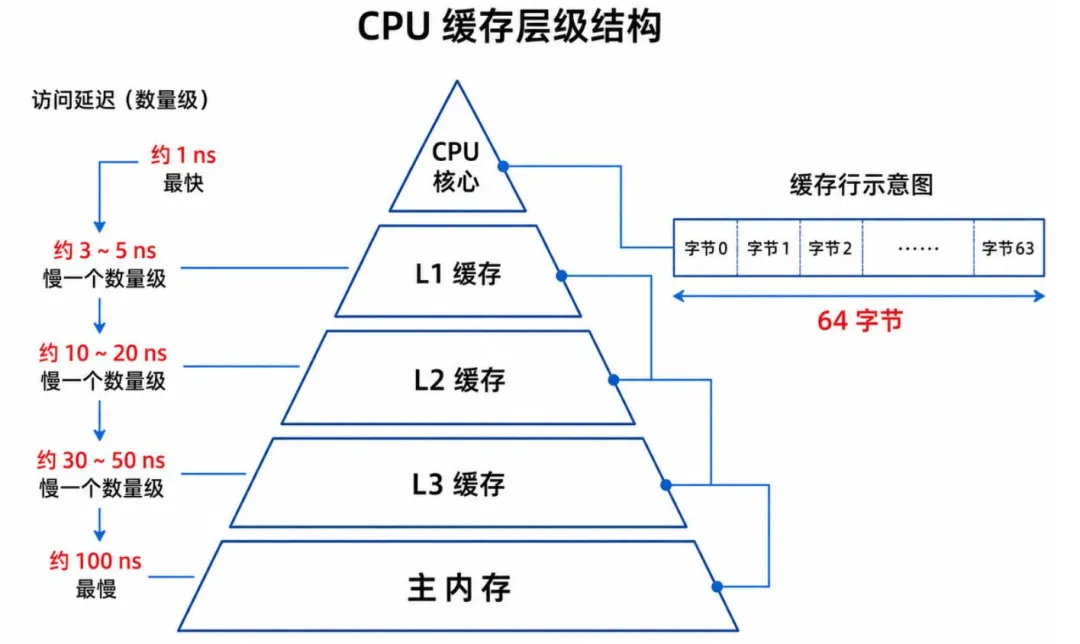
先说一个基础但很多人没深入想过的事实:CPU 的运算速度和内存的读取速度,差了数量级。
CPU 一个时钟周期可以做几十次运算,但等待内存返回数据可能需要几百个时钟周期。为了填平这个差距,硬件工程师在 CPU 和内存之间塞了三层缓存:L1、L2、L3。L1 缓存的访问速度和 CPU 寄存器接近,而 L3 则是所有核心共享的。
缓存的最小管理单位是缓存行(cache line),通常为 64 字节。当 CPU 读取一个变量时,它不会只把这个变量拿过来,而是把这个变量所在的整个 64 字节全抬进缓存。
这就引出了一个核心概念:局部性。如果你访问的数据在内存里是连续的,CPU 只需要发一次内存请求,后面的数据就都在缓存里了。这叫空间局部性。如果你连续多次访问同一个变量,CPU 也会把它留在缓存里不清出去。这叫时间局部性。
局部性是 CPU 缓存的"生命线"。你的代码算法再精妙,如果打破了局部性,性能就会崩盘。
三个让程序变慢的缓存杀手
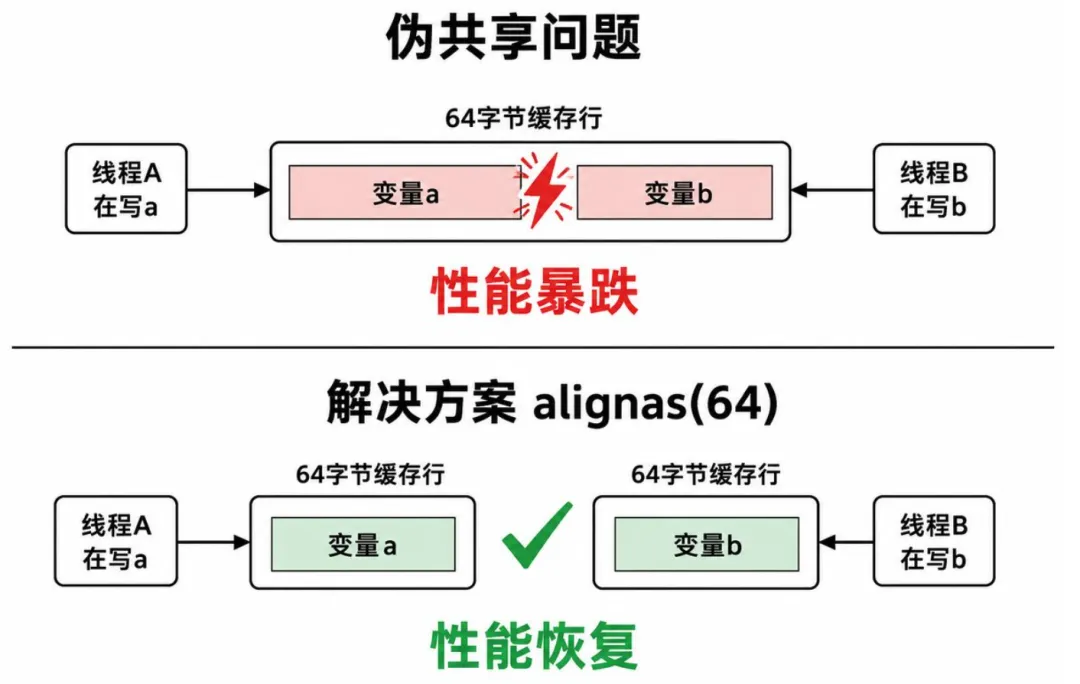
杀手一:伪共享
有一次,我们写了一个多线程计数器。两个线程分别对两个不同的变量自增:
structCounter {std::atomic<int> a{0};std::atomic<int> b{0};};// 线程 1 不断增加 a// 线程 2 不断增加 b我们觉得这是线程安全的,因为 a 和 b 是两个独立变量。但实测发现,性能极差。
问题在哪?a 和 b 在结构体里紧邻存放,它们很可能落在同一个 64 字节的缓存行里。线程 1 修改 a,CPU 就要把整个缓存行标为"无效",线程 2 的缓存里的 b 也跟着失效了。两个线程在"同一条马路"上互相踢踢,谁都跑不快。
这就是伪共享(false sharing)。解决方案很简单,把 a 和 b 分开到不同的缓存行:
struct alignas(64) PaddedCounter {std::atomic<int> value{0};};PaddedCounter ca;PaddedCounter cb;alignas(64) 确保每个计数器占满一整个缓存行,再也不会打架。性能立刻提升数倍。
杀手二:不连续内存访问
这是最常见的缓存杀手。来看看这两段代码:
// 方式 A:vector 连续存储std::vector<int> v(1000000);for (int i = 0; i < v.size(); ++i) { sum += v[i];}// 方式 B:list 链式存储std::list<int> l(1000000);for (auto it = l.begin(); it != l.end(); ++it) { sum += *it;}两段代码做的是同一件事。但在我的测试环境下,方式 A 比方式 B 快了 100 倍。
原因就在缓存。vector 的数据是连续存放的,CPU 读一次就能把后续几十个元素带进缓存。list 的节点分散在堆的各个角落,每访问一个元素都可能要去内存里读一次,缓存命中率极低。
这就是为什么大多数情况下,你应该优先用 vector。
杀手三:虚函数和动态分发
很多人喜欢用多态设计模式,虚函数看起来很优雅:
Base* obj = getObj();obj->compute(); // 虚函数调用但是每次调用虚函数,CPU 都无法预测下一条指令是什么。它只能等到运行时才去查虚表。这就打碎了代码的空间局部性,而且还会打乱分支预测。
在高频调用的热路径上,虚函数的开销可能比你想象的大得多。如果性能是第一优先级,可以考虑用 CRTP(奇异递归模板模式)来实现静态多态:
template<typename Derived>classBase {public:voidcompute(){static_cast<Derived*>(this)->computeImpl(); }};这种写法在编译期就确定了调用目标,没有运行时开销,也不会打乱缓存。
怎么写出缓存友好的代码
知道了坑,来看看实践建议。
第一,结构体字段按大小排序,避免内存洞。比如这两个结构体:
structBad {char a; // 1 字节int b; // 4 字节char c; // 1 字节}; // 可能占 12 字节structGood {int b; // 4 字节char a; // 1 字节char c; // 1 字节}; // 只占 8 字节第二,熔点布局设计(AoS vs SoA)。如果你对数组做同一个操作,把数据按字段分开存比按结构体存更快:
// AoS:结构体数组,不利于向量化structParticle {float x, y, z; };std::vector<Particle> particles;// SoA:字段分离,连续访问更快structParticles {std::vector<float> x, y, z;};第三,充分利用缓存行。把一起访问的数据放在一起,确保它们在同一个或相邻的缓存行里。
第四,对于可预测的访问模式,可以手动 prefetch
for (int i = 0; i < n; ++i) { __builtin_prefetch(&data[i + 64]); // 提前预取 process(data[i]);}当然,prefetch 不是万能药,用错了反而会污染缓存。
给你的速查清单
写代码时每次想到缓存,这张清单能帮你快速检查:
std::vector,少用 std::list | |
alignas(64) 分开 | |

那个矩阵优化案例给了我很深的印象。我们花了两天在算法层面挖掘,结果最终的突破点却是数据布局——这是一个典型的"软件工程师的硬件认知"问题。
今天的 CPU 性能已经不会因为你写了更少的指令而提升,它取决于你的数据如何在缓存里流动。所以,下次写代码时,别只想算法复杂度。多问自己一句:这段数据,在 CPU 看来是不是连续的?
C++ 校招 / 社招跳槽逆袭!从0到1打造高含金量项目,导师1v1辅导,助你斩获大厂offer!
很多同学准备校招时最焦虑的问题就是:“简历没项目,怎么打动面试官?”
为了解决这个痛点,我们推出了C++项目实战训练营
在这里,你可以:
系统学习 C++ 进阶知识 自选项目,从 0 到 1 实战造轮子 导师一对一指导,代码逐行 Review 拿到能写进简历的项目成果,秋招直接加分!
我们不只是教你写代码,更带你走一遍完整的项目流程: 从需求分析、架构设计、编译调试,到版本管理、测试发布,全流程掌握!
项目配套资料齐全,遇到问题还有导师帮你答疑,不怕卡壳!
项目准备好了,你只差一次出发。
相信我,这些项目绝对能够让你进步巨大!下面是其中某三个项目的说明文档
训练营适用人群:
备战春招和秋招的应届生,科班非科班均可, 工作 3 年以内,想跳槽的社招同学 如果你有以下困扰,欢迎联系我们,我们愿意为你提供帮助和支持 不知道该复习哪些内容,如何开始复习。 对面试考察重点不清楚,复习效率低下。 缺乏有含金量的实战项目经验。 想要提升自己的实战能力,提升做项目及解决问题的能力 对算法题无从下手,缺乏解题思路和常见解题模板。 自控力不足,难以专注于系统复习。 希望获得大厂的内推机会。 独自备战校招社招感到孤单,想要找到学习伙伴。
不适合人群:
缺乏耐心和毅力,急于求成的人 对编程逻辑思维基础薄弱,且不愿努力提升的人 只想快速获得成果而不注重基础学习的人
推荐阅读:
