 夜雨聆风
夜雨聆风本文是《把 AI 关进笼子,让它替我合并一万个文件》系列第 1 篇。
一周以后的某个晚上,我跑了一次全量文件统计。三行命令,git ls-tree 列出两个分支的所有文件,comm 求一下差集:
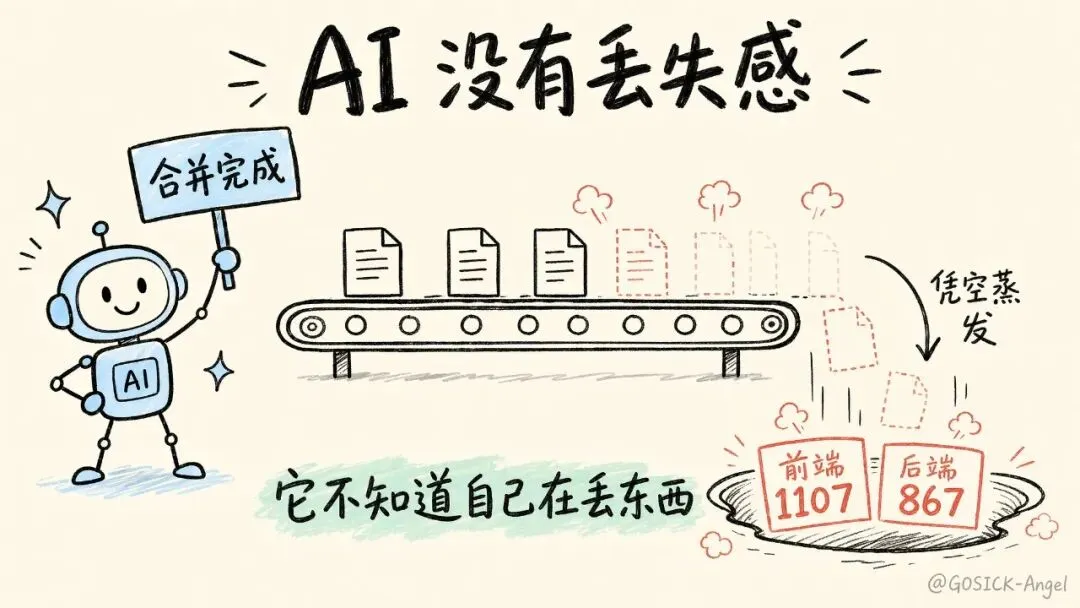
git ls-tree -r --name-only upstream-1.11.3 > upstream_files.txtgit ls-tree -r --name-only HEAD > head_files.txtcomm -23 <(sort upstream_files.txt) <(sort head_files.txt) > missing.txt屏幕上蹦出来的数字让我手一抖:前端漏合 1107 个文件,后端漏合 867 个。这都是我"已经合并完"的那部分里,凭空蒸发的。
我盯着 missing.txt 看了半天,心里只有一句话:这一周,几乎白干。
更扎心的是什么?整整一周,AI 全程没报一个错。它每合完一批就跟我说"合并完成",语气笃定得像个交差的实习生。它不是骗我——它是真的不知道自己漏了。这就是我后来反复跟人念叨的那句话,也是这整个系列的灵魂:
AI 没有"丢失感"——它不知道自己在丢东西。
可这活儿,纯人工根本干不完
你可能想说:那你别用 AI 了,老老实实手工合呗。
我也想啊。先报个体量你感受一下:合并对象是 Dify[1] 的上游版本 1.11.3,前端 5527 个文件、后端 2425 个文件,跨了一个大版本。直接 git merge?那会炸出成百上千个冲突,一个一个看,看到天荒地老。
先解释一下我到底在干嘛,免得没维护过 fork 的朋友一脸懵。
fork 是什么? 把它想象成:你照着别人的开源项目"分家另过",搬进自己的仓库,加了一堆自家装修——企业 SSO 登录、私有队列配置、安全加固。而 upstream(上游) 就是原房东,他还在不停翻新房子。所谓"合并",就是把房东最新的翻新搬进你这套已经装修好的房子里,又不能砸掉自家的墙。
这事难在哪?难的不是技术,是判断。每个有差异的文件,你都得回答三个问题:
1. upstream 改了啥、为什么改? 2. 我们自己改了啥、为什么改? 3. 两边的改动能不能同时留下、怎么留?
上万个文件,每个都问这三个问题——人脑会当场死机。我没有退路,只能想办法:既榨干 AI 的勤快,又堵住它的盲区。
这一堵,就是七周。下面是我用血换来的几条原则。
坑一:没带地图就进了原始森林
第一周我是怎么干的?我让 Claude 把当前代码和 upstream 1.11.3 都分析一遍,出一份合并计划。计划看着可漂亮了——前端、后端每个目录都拆成大约 12 个步骤,井井有条。我就说"帮我执行 Phase X",它合一批,我瞄一眼,觉得差不多就放行。
然后就有了开头那两千个凭空消失的文件。
复盘的时候我才想明白:你一上来就让 AI 把两个分支、几十个目录一口气分析完,它为了控制上下文,是会偷懒的。它给你的不是逐文件清单,是"大概的数值"。计划里写"这个目录大约 12 步"——那个"大约",就是漏合的温床。
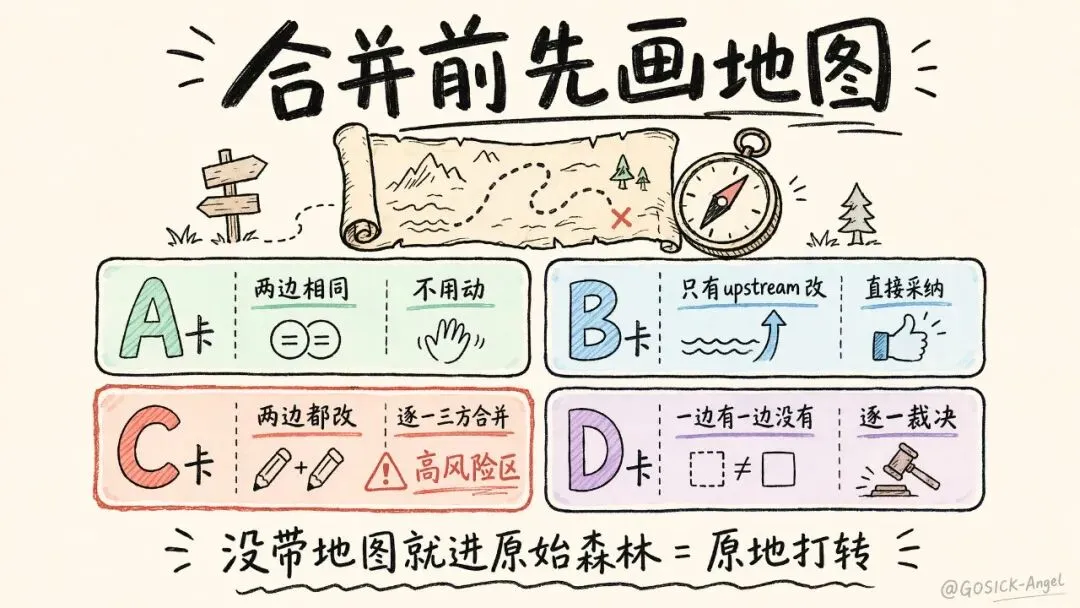
所以现在每次大型合并,我第一天必做一件事:跑全量文件分类脚本,把所有文件贴上四种"通行证"。
| A 类 | ||
| B 类 | ||
| C 类 | ||
| D 类 |
有了这张地图,你才知道工作量有多大、高风险区在哪、做到什么程度才算完。合并前不画地图就开干,等于没带地图就进了原始森林——你以为自己在前进,其实早就在原地打转。
坑二:让 AI 自己审自己,等于让运动员当裁判
这是整个七周里我捞到的最值钱的一条经验。
起因是一次让我血压飙升的事故。AI 花了好久"完成"了一个复杂模块的合并,我审查时发现——它把我们自己写的一段配置解析能力,悄悄用 upstream 的版本盖掉了。没报错,没警告,就这么没了。
那一刻我彻底想通了:AI 的目标是"让合并后的代码能跑起来",不是"确保什么都没丢"。它没有丢失感,因为它压根不知道那段代码对我们意味着什么。
解法是把 AI 拆成两个互相对立的角色,分别跑在两个独立会话里:
• 执行官(Executor):唯一动手干活的。给它三条铁律——不准删当前分支任何功能、不准漏 upstream 任何改动、所有差异必须用注释标清楚( # TODO [merge]、# Current branch enhancement、# Merged from upstream X.Y.Z)。它的性格就是个闷头干活、干完就觉得"我做完了"、从不回头检查自己漏没漏的实习生。• 审判官(Judge):只许看、不许碰。它的任务不是帮执行官找通过的理由,而是专门找漏洞——upstream 的逻辑消失了没?fork 的独有功能被弱化了没?注释和代码行为对不上没?只要中一条,立刻否决。
为什么要分两个会话?因为执行官干完活会有心理包袱,下意识觉得"我没错"。审判官在干净的独立会话里冷眼旁观,没有这个包袱。这跟"不能 review 自己的 PR"是一个道理——你自己看自己的代码,永远有盲区。
实战第一仗:API 的第一个 Phase 就被审判官当场否决,揪出来的正是那个配置解析能力回退的问题。重做、复查,证实那确实是真漏。
这里我还踩过一个小坑:试过让 Claude Code 通过 MCP 自动调 codex 审查,效率是高,但 MCP 偶尔卡死无响应,Claude Code 傻等也不知道;它有时还会把自己的看法当 prompt 喂给 codex,反而带偏了审查。最后结论:审查这环,单独开一个干净的会话最稳。
这两个对立角色具体怎么设计提示词、怎么让它们隔离又协作,我留到第 2 篇细讲。
坑三:每一步不踩实,错误会扩散到分不清是谁干的
合并我分成了好多个阶段(Phase)。每个阶段做完,必须过一组门禁检查才能进下一阶段:
# 后端cd api && uv run ruff check . # stylecd api && uv run basedpyright . # type checkcd api && uv run pytest tests/ -x -q # unit test# 前端cd web && pnpm type-check # 0 errors onlycd web && pnpm lint:quietcd web && pnpm build:fastcd web && pnpm test做之前觉得这是额外负担,做之后发现是救命绳。
前端最惨的时候,合完一大批文件跑 type-check,蹦出来 1367 个类型错误。要是没门禁,这些错误会一路扩散,最后你根本分不清哪个错是哪次合并引入的——整个项目变成一锅糊。
有了阶段门禁,每次失败都能精确定位到"是这个 Phase 的哪几个文件惹的祸"。前端最终的轨迹是 1367 → 0,分八个阶段,每一步都干干净净过门禁才往前挪。
门禁怎么"踩实"才不会回退、写文件出事了怎么一键读档,第 4 篇专门聊这个。
坑四:别看两边 diff,要看三方
大多数人(和 AI)合并时只盯着"两边的差异"。这不够。
打个比方:只看两边 diff,就像只听原告和被告各说一句话——你只知道"现在两人说法不一样",但不知道到底是谁先动的手、为什么动。
正确姿势是三方对比:把"案发前现场"也调出来——同时看共同祖先(merge-base)、upstream、当前分支三个版本:
MERGE_BASE=$(git merge-base HEAD upstream/main)git show "$MERGE_BASE":api/services/app_service.py > /tmp/base.pygit show upstream/main:api/services/app_service.py > /tmp/upstream.pygit show HEAD:api/services/app_service.py > /tmp/current.pydiff3 /tmp/current.py /tmp/base.py /tmp/upstream.py举个真实的例子:某个函数,upstream 重构了,我们也改了(加了企业功能)。只看两边,感觉冲突复杂得要命。三方一对,发现 upstream 改的和我们改的根本是不同的部分——压根不冲突,直接合就行。
只看两边,你会把"各改各的"误判成"打架",白白浪费一堆人工裁决。
坑五:AI 的记忆靠不住,得给它一份进度文档
一次大型合并,跨了几十个会话。AI 的上下文是有限的,会话一切换,前面的规则、进度、"哪些定制功能碰不得"——全忘光。
我的办法很土但极其管用:把进度全写进一个 Markdown,每开新会话就 @ 它一下。
文档里有什么?当前各 Phase 的状态、雷打不动的执行规则、一份"关键定制功能(不可丢失)"清单(HTTP-only Cookie 认证、SSO 登录、双套队列配置……)、还有门禁命令。新会话一开,把文档扔进去,AI 立刻知道:背景是啥、规矩是啥、做到哪了、哪些墙不能砸。
文档代替记忆,会话切多少次都不丢上下文。 这个"用外部存储给 AI 续命"的思路,到了系统里演化成了一套跨会话记忆机制,第 5 篇[2]展开。
收尾:安全审计不是"有空再说"
七周合完,我没急着收工,而是做了一次专项安全审计。
为什么非做不可?因为合并过程里有大量地方,为了让代码"先跑起来"做了妥协,安全这事没在每一步盯。收尾统一审一遍,能逮到一堆过程中漏掉的雷。
果然逮到一个 HIGH 级:某处用了 dangerouslySetInnerHTML,却没过 DOMPurify 净化,妥妥的 XSS 风险。这是合并 upstream 一个新功能时引进来的,那次合并的单测完全没覆盖到这个场景。
教训:安全审计是收尾的必选项,不是 nice-to-have。
七周战果
前端 5527 个文件 → 5526 个成功合入(1 个有充分理由豁免)安全审计评分 9.2 / 10端到端测试 27 个全部通过中途产出 80+ 份报告、被审判官否决数次、1367 个类型错误清零这活儿,纯人工真做不完。用 AI 做,只要方法对,是能干成的。
但是——这套手艺太依赖我盯着了
复盘到这儿,我心里其实有点不爽。
上面这五条原则、这套门禁、这个执行官+审判官,全靠我一个人盯着:手动跑分类脚本、手动开两个会话、手动维护进度文档、手动收尾审计。哪天换个项目、换个同事来干,这套经验就得从头口口相传一遍。手工方法不可复用、不可审计、出错了也很难恢复。
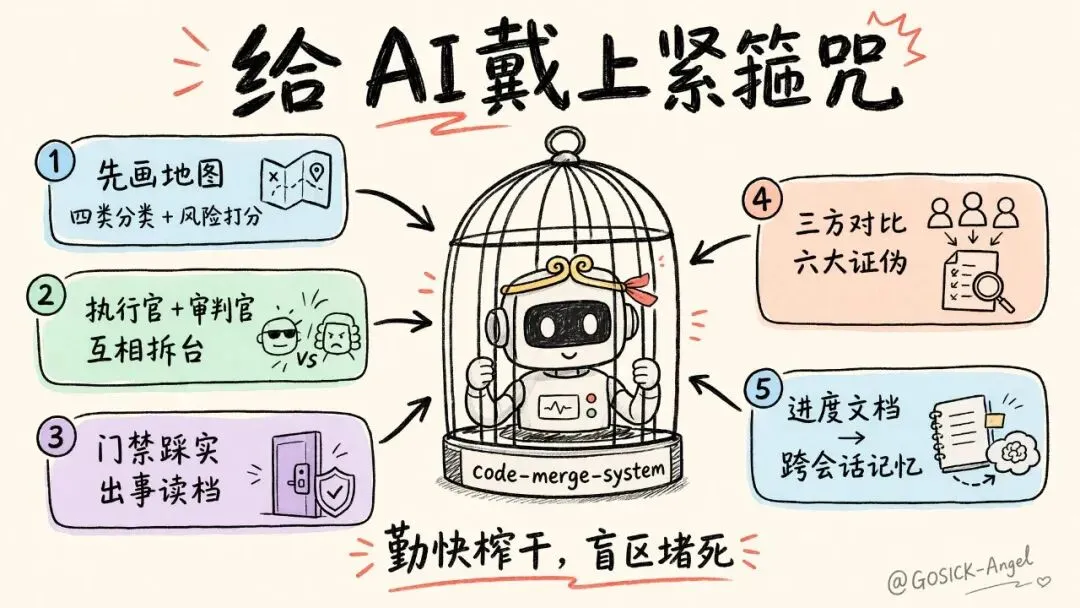
所以我把它产品化了——做成一个通用、开源的多 Agent 代码合并流水线 code-merge-system。
一句话概括它和 git merge 的区别:git merge 给你一堆冲突,它给你一条决策流水线。 上面那五条血泪原则,全被我焊进了代码里变成不可违反的规则:
• 那张"画地图再出发"的四类文件清单 → 变成开跑前的自动三方分类 + 风险打分(阈值 0.3 以下自动合、0.6 以上直接送人工)。 • 那对"执行官+审判官" → 变成两个真正隔离的 Agent,审判官全程只读,还故意请另一家公司的模型(执行官用 GPT、审判官用 Claude),防止同家模型自己放过自己。 • "门禁踩实"和"出事读档" → 变成"写文件前先存档、异常立刻回滚"的唯一写入通道,就像打 Boss 前先存档。 • "三方对比"和"别丢东西" → 变成六个专门扫"AI 偷偷丢东西"的检测器,配上那句我最爱的话:LLM 负责理解语义,工具负责证伪——工具说"不行",AI 再能说会道也没用。 • "进度文档代替记忆" → 变成一套跨会话的分层记忆。
整个系统的核心,就是给 AI 戴上紧箍咒:让它替你干一万个文件的脏活累活,但每一步都被人和工具死死管着,绝不让它"以为自己做完了"就放行。
后面五篇,预告一下
这一篇我只讲了"为什么需要它"和"踩坑是什么感觉",没碰任何实现细节。接下来五篇,每篇拆一块:
• 第 2 篇:怎么让两个 AI 互相制衡,执行官和审判官到底怎么设计才不串通。 • 第 3 篇:怎么治"AI 没有丢失感"这个绝症——六种丢失模式扫描器是怎么逮住偷偷被覆盖的代码的。 • 第 4 篇:怎么让每一步都不可逆地踩实——快照、回滚、断点续跑。 • 第 5 篇:怎么让 AI 跨几十个会话还记得规矩。 • 第 6 篇:把这些工程手艺打包成同行能直接用的东西。
项目已经开源了,pip install code-merge-system 就能装。第一次跑会开个浏览器向导带你配置,想先看看它打算怎么合、又不想真动文件,就来一发:
merge upstream/main --dry-run它会把计划、风险分布、每个文件的合并策略都摆给你看,一个字节都不写。项目已开源,如果你觉得哪里傻、哪里能更好,欢迎来 GitHub(https://github.com/GOSICK-Angel/code-merge-system) 拍砖、提 issue——我踩过的坑,不想让你再踩一遍。
引用链接
[1] Dify: https://github.com/langgenius/dify
