 夜雨聆风
夜雨聆风PART 01
数据参数决定“喂什么给模型”。
tokenizer 参数决定“输入怎么切、保留多长”。
模型参数决定“模型要解决什么任务”。
训练参数决定“模型怎么学、学多快、学多久”。
评估参数决定“我们怎么看它学得好不好”。
PART 02
train.csv
dev.csv
test.csv
train.csv 是训练集,模型会直接用它更新参数。
dev.csv 是验证集,训练过程中用来观察模型有没有学起来。
test.csv 是测试集,最后才用来评估模型最终表现。
训练时看 train loss 和 dev 指标。
调参数时主要参考 dev。
最终写结果时再看 test。
sequence,label
ATCG...,1
GCTA...,0sequence 是输入序列。
label 是任务标签。
label=1 是启动子
label=0 是非启动子
precision
recall
F1
基因内部序列
远离 TSS 的基因组窗口
非启动子的调控区
长度和 GC 含量匹配的背景序列
PART 03
encoding = tokenizer(
sequence,
truncation=True,
padding="max_length",
max_length=MAX_LENGTH,
return_tensors="pt",
)1 表示真实 token
0 表示 padding 出来的空位
input_ids
attention_mask
labels
PART 04
base model 可以理解成“负责读序列的主体模型”。它会把 DNA、蛋白或者文本序列变成一组向量表示,但它本身不一定知道你要做二分类、三分类,还是回归。
classification head 可以理解成“接在主体模型后面的分类器”。它拿到 base model 输出的向量,再输出每个类别的分数。比如启动子预测里,它最后输出两个分数:非启动子一分,启动子一分。
如果模型支持 `AutoModelForSequenceClassification`,说明 HuggingFace 可以直接帮你加载“主体模型 + 分类头”。这种最省事,基本可以沿用这篇的训练代码。
如果模型只有 base model,说明它只提供了“读序列的主体模型”,没有最后的分类器。你就需要自己接一个 classification head,否则模型只能输出向量,不能直接输出类别。
如果模型需要特殊 tokenizer 或特殊输入格式,那数据处理也要跟着改。比如有的模型要求先切 k-mer,有的模型要求输入蛋白氨基酸序列,有的模型对大小写、特殊符号有要求。这个时候不能只改 MODEL_NAME,还要检查 tokenizer 和 Dataset 这两块。
第 0 类:非启动子
第 1 类:启动子
DNABERT-2 主体负责理解序列。
classification head 负责把这种理解映射到你的具体标签。
for param in model.base_model.parameters():param.requires_grad = False
PART 05
Loss=0.6985
Loss=0.6241
1e-5
2e-5
3e-5
5e-5
Loss 完全不降:可能学习率太小,也可能数据或标签有问题。
Loss 忽上忽下很厉害:可能学习率太大。
训练集 Loss 降得很好,验证集不涨:可能过拟合,不一定是学习率问题。
SGD 是老派基础款。
Adam 是自适应学习率。
AdamW 是 Adam 的改进版,对权重衰减处理更合理。
optimizer = torch.optim.AdamW(
model.parameters(),
lr=LEARNING_RATE,
weight_decay=0.01
)scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=int(0.1*total_steps),
num_training_steps=total_steps,
)numwarmupsteps = int(0.1*total_steps)totalsteps = len(trainloader)*NUM_EPOCHSPART 06
zero_grad forward loss backward optimizer.step scheduler.step
模型大
序列长
显存小
batch size 被迫设得很小
PART 07
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")input_ids = batch["input_ids"].to(DEVICE)
attention_mask = batch["attention_mask"].to(DEVICE)
labels = batch["labels"].to(DEVICE)
model.to(DEVICE)`fp16=True`
`bf16=True`
模型大
序列长
显存紧张
想加速
def disable_dnabert2_flash_attention():
...普通 attention 是原始路线。
flash attention 是高速路线。
高速路线在不同 CUDA / Triton / PyTorch 组合下可能堵车。
我们为了教程稳定,走普通路线。
PART 08
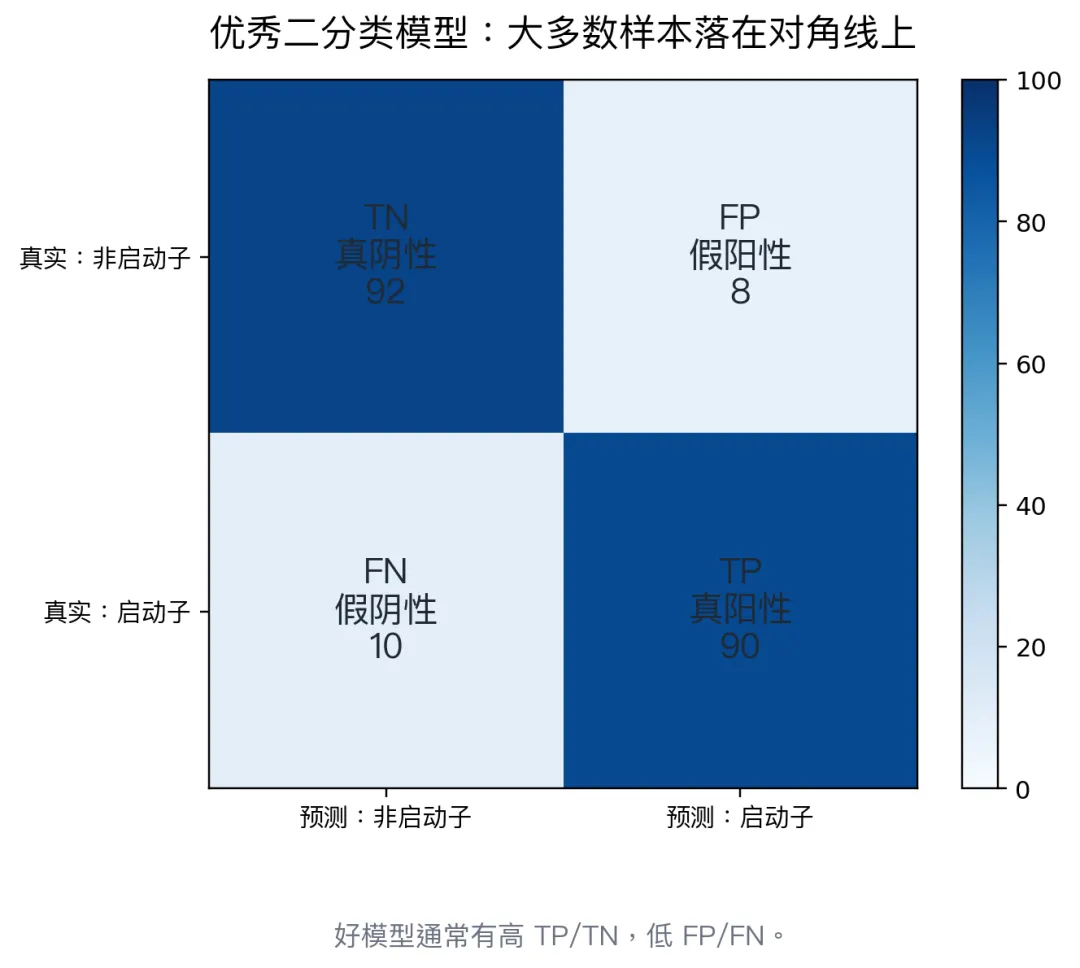
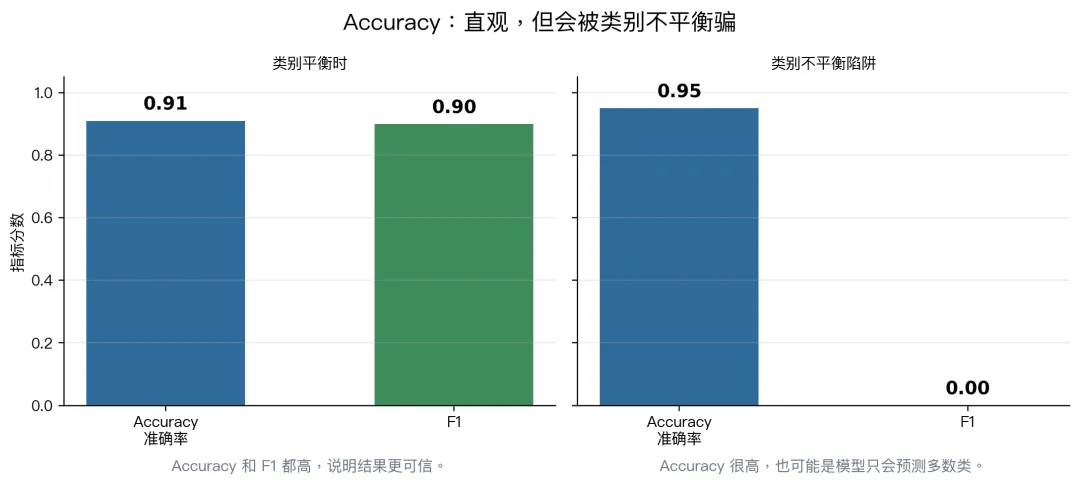
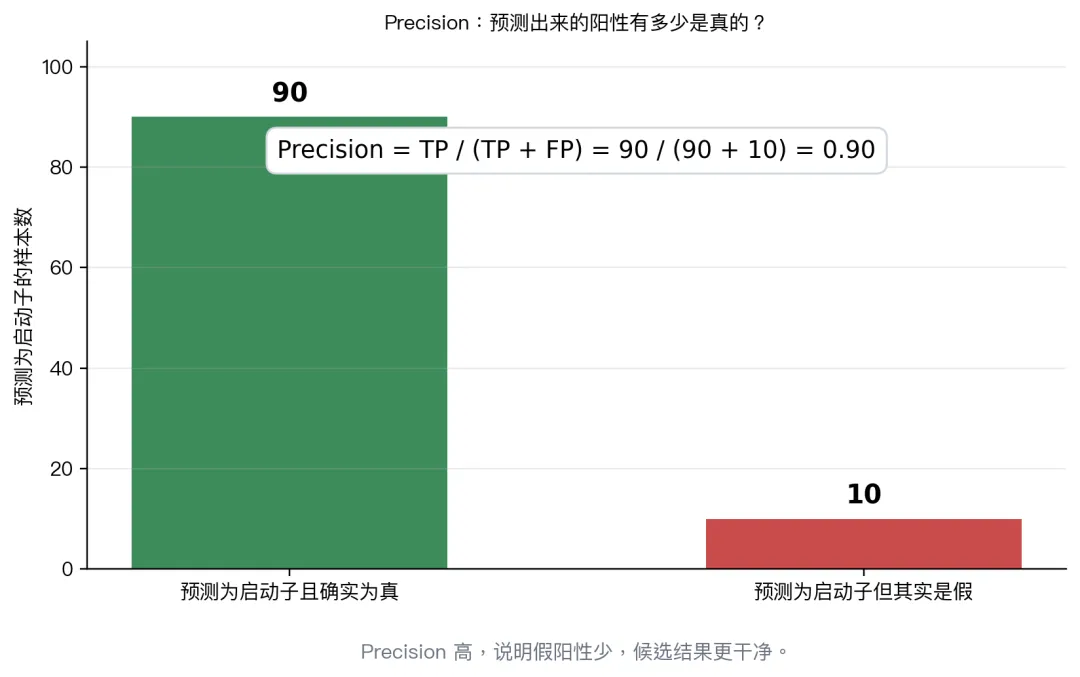
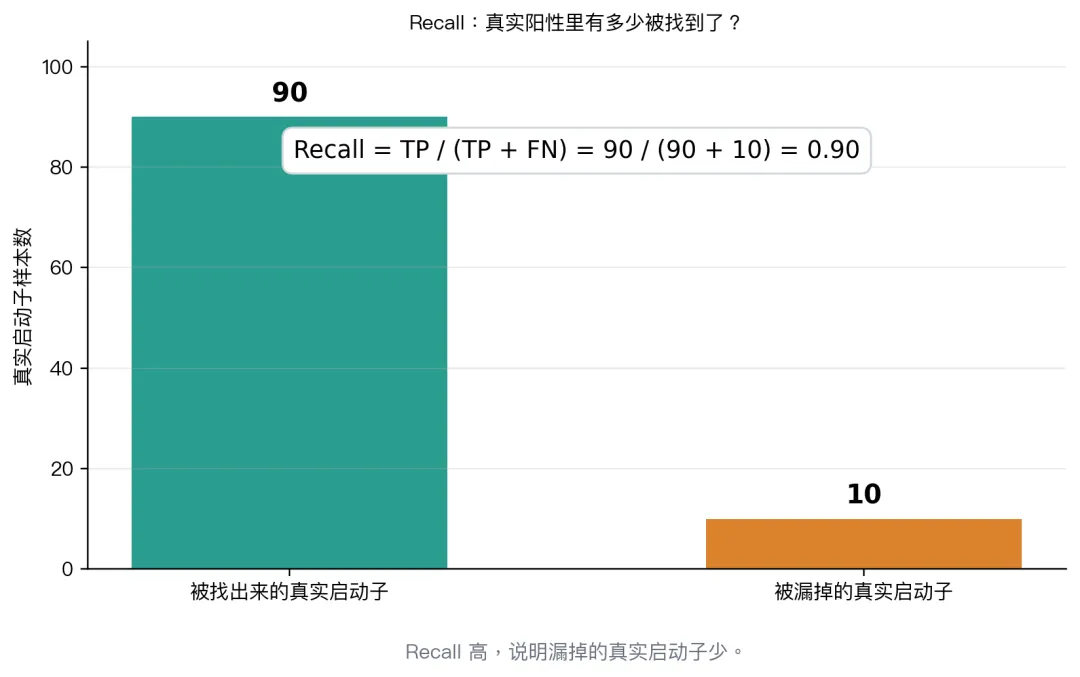
如果你的任务更怕假阳性,就重点看 precision。
如果更怕漏掉真阳性,就重点看 recall。
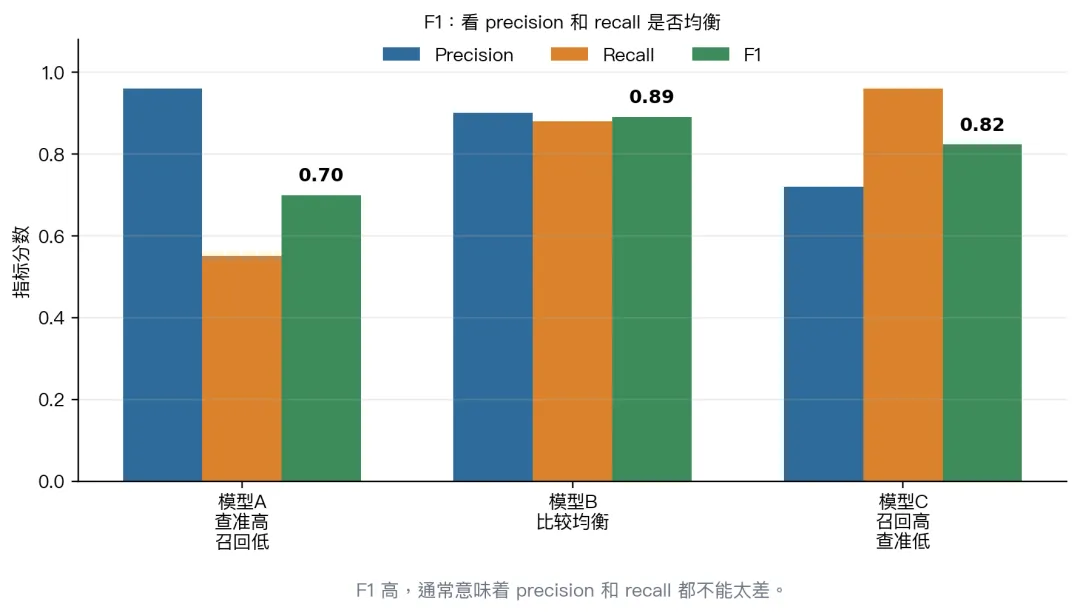
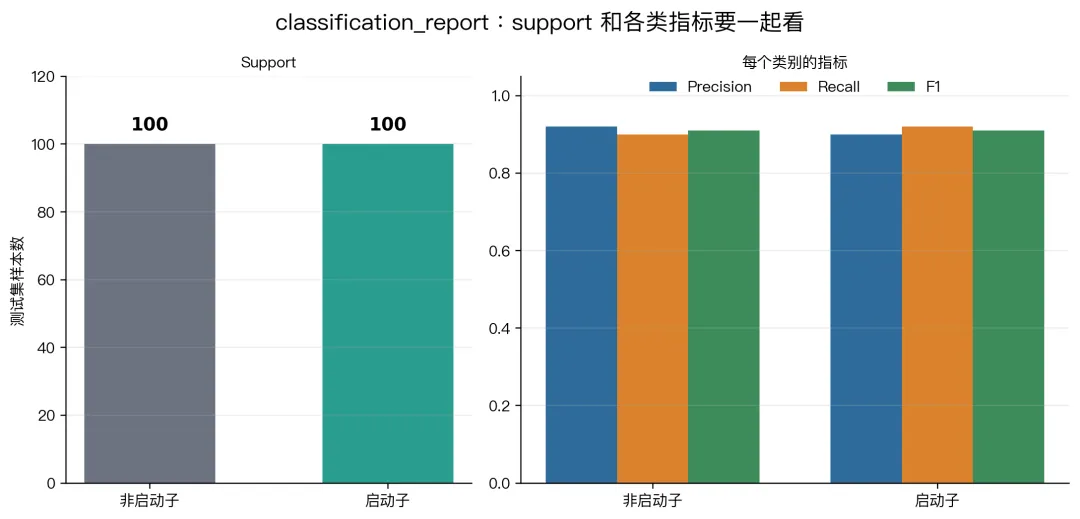
PART 09
model.save_pretrained("./promoter_model")
tokenizer.save_pretrained("./promoter_model")如果启动子概率 > 0.8,才认为是启动子。这样 precision 可能提高,但 recall 可能下降。
如果启动子概率 > 0.3,就先纳入候选。这样 recall 可能提高,但假阳性也会变多。
如果你后续实验很贵,可以设高一点。
如果你是初筛候选位点,可以设低一点。
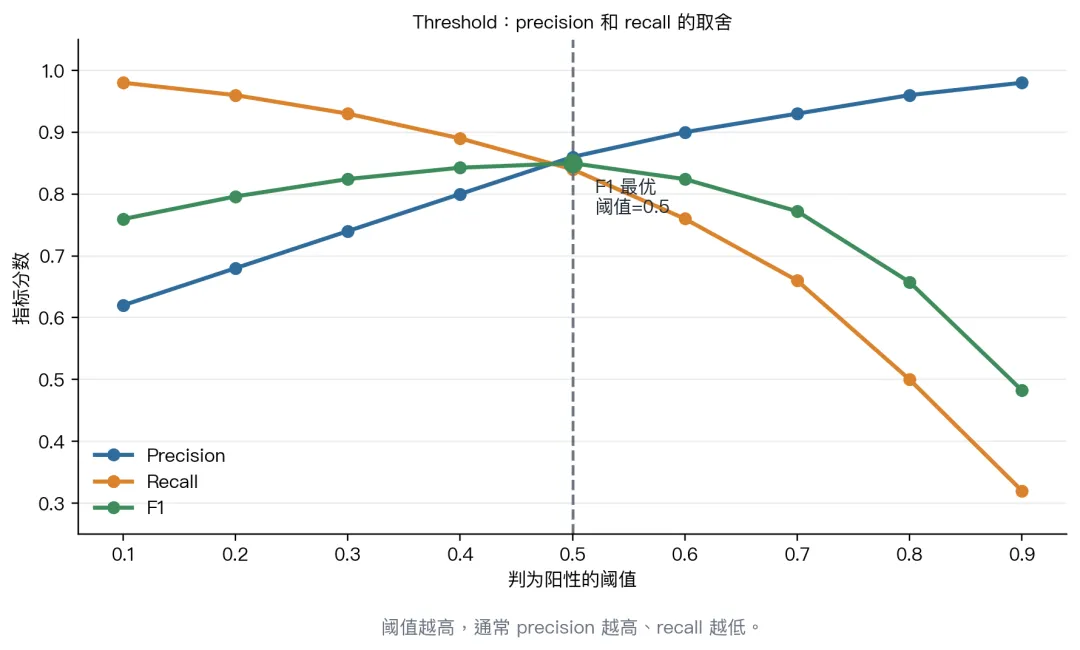
PART 10
PART 11
先准备小数据,确认代码能跑通。 检查 sequence 和 label 是否正确。 设置 num_labels。 根据序列长度设置 MAX_LENGTH。 从 BATCH_SIZE=16 开始,显存不够就降。 从 LEARNINGRATE=3e-5、NUMEPOCHS=5 开始。 看 train loss 是否下降。 看 dev F1 是否提升。 如果 train 好、dev 差,考虑过拟合和数据问题。 最后只在确定方案后看 test。
PART 12
MODEL_NAME = "zhihan1996/DNABERT-2-117M"
MAX_LENGTH = 128
BATCH_SIZE = 16
LEARNING_RATE = 3e-5
NUM_EPOCHS = 5
num_labels = 2用 DNABERT-2 作为预训练模型。
每条序列最多保留 128 个 token。
每次训练 16 条序列。
用 3e-5 的学习率微调。
完整看训练集 5 遍。
最后输出两个类别:非启动子和启动子。
序列窗口多长,决定 MAX_LENGTH。
类别有几个,决定 num_labels。
显存多大,影响 BATCH_SIZE。
验证集表现,决定 LEARNINGRATE 和 NUMEPOCHS。
任务目标,决定看 precision、recall 还是 F1。
PART 13
MAX_LENGTH 管输入多长。
BATCH_SIZE 管一次吃多少。
LEARNING_RATE 管学得多快。
NUM_EPOCHS 管学几遍。
num_labels 管输出几类。
optimizer 管怎么更新。
scheduler 管学习率怎么变。
metrics 管怎么判断结果。
