 夜雨聆风
夜雨聆风想象一下,你让一个家用机器人清理餐桌。在当前的AI范式下,这个简单的指令需要调动一系列孤立的模型:一个视觉语言模型(VLM)来识别碗碟并生成计划,一个视觉-语言-动作模型(VLA)来生成抓取动作序列,一个“世界模型”来模拟和验证未来的状态。这种碎片化的架构不仅计算效率低下,更限制了智能体对物理世界的整体理解。
为了打破这种局面,NVIDIA提出了 Cosmos 3,一个全新的全模态(Omnimodal)世界模型家族。它在单一网络架构内,统一了语言、图像、视频、音频和动作五种模态的理解与生成能力,为物理AI提供了一个可扩展的通用基础。Cosmos 3 将视觉语言模型、视频生成器、世界模拟器和世界-动作模型的功能集于一身,标志着从“拼接式”AI向“原生统一”AI的重大跨越。
论文标题: Cosmos 3: Omnimodal World Models for Physical AI
机构: NVIDIA
论文地址: https://arxiv.org/abs/2606.02800
开源代码地址: https://github.com/NVIDIA/cosmos
项目主页: https://research.nvidia.com/labs/cosmos-lab/cosmos3
模型地址: https://huggingface.co/collections/nvidia/cosmos3
导读
为机器人、自动驾驶等物理AI应用构建基础模型,面临一个根本性矛盾:理解世界与生成世界(或行动)通常被视为两个独立的问题。Cosmos 3 的核心洞察在于,理解需要推理世界的未来演化,而生成依赖于对世界和行为的紧凑、结构化表征。将两者统一,才能让智能体真正“知行合一”。
本文详细介绍了Cosmos 3在架构设计、大规模数据构建、高效训练策略和全面评估方面的关键技术。通过在广泛的理解和生成基准测试上取得顶尖结果,Cosmos 3证明了全模态世界模型作为具身智能体通用后背(backbone)的可扩展性和强大潜力。
方法:一个模型,五项全能
Cosmos 3 的设计围绕一个核心理念:所有模态的输入和输出都应在一个统一的序列中处理。其灵魂是混合Transformer(Mixture-of-Transformers, MoT)架构。
1. 混合Transformer架构:理解与生成的“双核”
Cosmos 3 采用了“双塔”式解码器结构,在每个Transformer层内包含两套独立的参数集:
• 推理塔(Reasoner Tower):专门处理自回归(AR)子序列,负责视觉理解和文本推理。这部分初始化自预训练的视觉语言模型(VLM),继承了强大的语义和逻辑能力。
• 生成塔(Generator Tower):专门处理扩散(DM)子序列,负责图像、视频、音频和动作的生成。它通过流匹配(flow-matching)目标进行训练,逐步去噪来产生高质量的输出。
这两个“塔”并非完全隔离。通过双流联合注意力机制,生成塔可以“看到”推理塔的上下文信息(如文本指令),而推理塔则保持自回归的因果独立性。这种设计既保证了强大的推理能力,又赋予了模型强大的生成和控制能力。
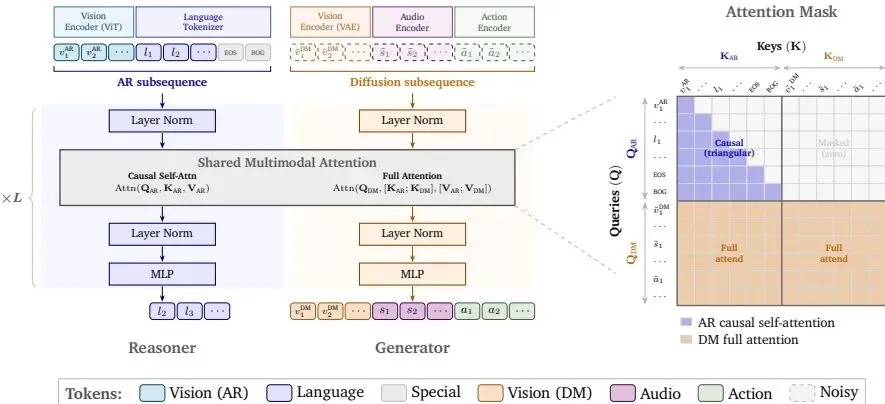 图:Cosmos 3 的混合Transformer架构。 自回归序列(AR)和扩散序列(DM)由独立的参数集处理,但通过注意力机制交互。AR因果自注意力保证了推理的递归性质,而DM全双向注意力允许无条件地关注所有上下文。
图:Cosmos 3 的混合Transformer架构。 自回归序列(AR)和扩散序列(DM)由独立的参数集处理,但通过注意力机制交互。AR因果自注意力保证了推理的递归性质,而DM全双向注意力允许无条件地关注所有上下文。
2. 动作:作为核心模态的世界因果变量
Cosmos 3 最具革命性的地方在于,它将动作(Action) 提升为核心模态。这意味着模型不再是简单地“看视频”,而是理解“什么动作导致了状态的改变”。
• 统一动作表征:无论是机械臂的旋转,还是自动驾驶汽车的方向盘转角,Cosmos 3都将其映射到一个共享的几何化潜在动作空间。它将动作分解为自我感知(Ego)、末端执行器(Effector)和抓取状态(Grasp state)等通用组件。
• 多样化的生成模式:通过灵活安排输入输出序列中的令牌(tokens),Cosmos 3能够支持三种动作学习模式:
◦ 正向动力学(Forward Dynamics):给定动作,预测未来的视觉状态。
◦ 逆向动力学(Inverse Dynamics):给定视觉状态变化,推断出导致该变化的动作。
◦ 策略(Policy):联合预测动作和未来的视频帧。
这意味着,Cosmos 3可以充当一个世界模拟器,在“行动”之前就“想象”出世界的变化。
 图:动作序列配置。 通过改变哪些令牌是“干净的”(输入条件)和哪些是“嘈杂的”(需要生成),Cosmos 3可以无缝地在正向动力学、逆向动力学和联合预测(策略)模式间切换。
图:动作序列配置。 通过改变哪些令牌是“干净的”(输入条件)和哪些是“嘈杂的”(需要生成),Cosmos 3可以无缝地在正向动力学、逆向动力学和联合预测(策略)模式间切换。
3. 令牌编排:统一的任务表达
所有任务都被表达为一种统一的令牌序列格式: [AR子序列] --> [DM子序列]
• AR子序列:包含语言令牌和由ViT编码的图像/视频令牌,用于理解和推理。
• DM子序列:包含由VAE编码的图像、视频、音频和动作令牌。其中,“干净”的条件令牌(如控制信号、起始帧)位于前方,“嘈杂”的需要生成的令牌位于后方。
这种简洁而通用的格式使Cosmos 3无需任何架构修改,即可处理从文本到图像、视频到视频、甚至是条件化视频迁移(如由深度图、边缘图生成RGB视频)和动作生成等数十种任务。
实验与结果:全方位领先的物理AI基础
Cosmos 3在理解、生成和控制三大维度上接受了严苛的考验。其结果清晰表明,统一的全模态模型不仅可行,而且在多项任务上超越了专门化的模型。
图像与视频生成:开源新王者
在图像生成(T2I)和视频生成(I2V/T2V)任务上,Cosmos 3表现惊艳。
• T2I生成:其专门优化后的 Cosmos3-Super-Text2Image 模型在 UniGenBench 基准上取得了最高总体分,并在 Artificial Analysis 的文本到图像排行榜上,成为排名第一的开源模型。更关键的是,它在物理场景(如机器人、驾驶)的生成上表现尤其出色。
 图:由 Cosmos3-Super-Text2Image 生成的示例图像。 该模型能生成物理合理、几何一致且极其逼真的图像,展现出作为真实世界图像模拟器的巨大潜力。
图:由 Cosmos3-Super-Text2Image 生成的示例图像。 该模型能生成物理合理、几何一致且极其逼真的图像,展现出作为真实世界图像模拟器的巨大潜力。
• I2V 生成:Cosmos3-Super-Image2Video 在 Artificial Analysis 的图像到视频排行榜上同样位列开源模型第一。在专门的物理基准 Physics-IQ 上,它达到了 43.8分 的新高度,显着优于其他模型,表明其深刻理解并能够模拟物理规律。
视频理解与推理:领域专家
在物理AI相关的推理任务上,Cosmos 3展现了其“理解”世界的深度。
• 在机器人、智慧基础设施和自动驾驶等专门领域的基准测试中,Cosmos 3的表现不仅碾压所有开源模型,甚至超越了包括 Gemini 3.1 Pro 在内的部分封闭模型。
• 这得益于其Reasoner部分在大量领域特定数据(如机器人操作链式思维、驾驶场景因果推理)上的后训练,使其具备了在特定物理场景中进行专业级推理的能力。
音频生成:声音与视觉的精准对齐
Cosmos 3不仅“看”得清楚,还能“听”得明白。在 Cosmos-SoundBench 基准上,其生成的视频音频在语义对齐和音画同步方面超越了所有开源和封闭模型(如 Seedance-1.5-Pro 和 Veo-3.1)。
 图:音频-视频事件对齐示意图。 生成的音频频谱图显示了与视觉撞击(锤击)事件精确对齐的尖锐瞬态,证明了其对物理因果关系的理解。
图:音频-视频事件对齐示意图。 生成的音频频谱图显示了与视觉撞击(锤击)事件精确对齐的尖锐瞬态,证明了其对物理因果关系的理解。
机器人控制:从世界模型到行动策略
Cosmos 3最激动人心的能力是其作为机器人策略基础模型的应用。
• 在RoboLab仿真基准上,Cosmos3-Nano-Policy-DROID 模型在各项任务成功率上均大幅超越了此前的最优模型 DreamZero 和 π0.5,特别是在精细操作任务上优势明显。
• 在RoboArena真实世界基准上,该模型凭借社区众包的A/B测试,成功登顶排行榜第一,证明了其强大的泛化和实际部署能力。
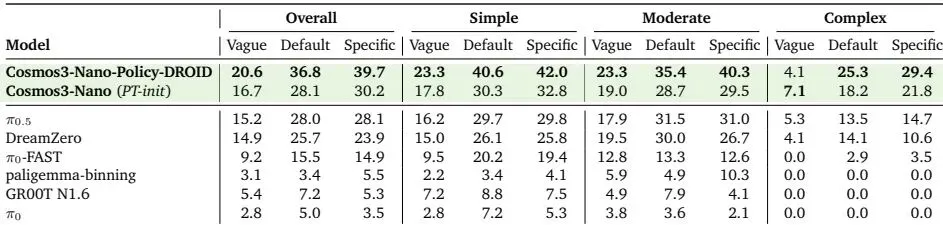 图:RoboLab-120基准上的任务成功率。 Cosmos3-Nano-Policy-DROID 在所有任务难度和指令粒度上都取得了最高分。
图:RoboLab-120基准上的任务成功率。 Cosmos3-Nano-Policy-DROID 在所有任务难度和指令粒度上都取得了最高分。
 图:Cosmos3-Nano-Policy-DROID 在真实世界机器人上的长时程任务执行。 模型能够理解“将螺丝刀和手套放入紫色容器”的指令,并拆解为“抓取-放置”等子任务序列。
图:Cosmos3-Nano-Policy-DROID 在真实世界机器人上的长时程任务执行。 模型能够理解“将螺丝刀和手套放入紫色容器”的指令,并拆解为“抓取-放置”等子任务序列。
总结:通往通用物理AI的基石
Cosmos 3 的发布,是物理AI领域的一个里程碑。它证明了将感知、推理、模拟和行动统一在一个单一、可扩展的框架内,不仅可行,而且能产生前所未有的协同效应。其核心贡献在于:
1. 统一的全模态架构:MoT双塔设计优雅高效地处理了理解与生成两种不同性质的任务,是未来模型设计的范本。
2. 动作作为核心模态:将动作与语言、图像等并列,为机器人学习和世界模拟提供了全新的因果接口。
3. 物理先验的注入:通过大规模结构化数据和合成数据,模型学会了遵守物理定律,生成的视频和动作更加真实可靠。
4. 卓越的可扩展性:从4B参数的Edge模型到64B参数的Super模型,再到针对特定任务的后训练,Cosmos 3给出了从端侧到云端的完整解决方案。
通过开源代码、模型和基准,NVIDIA Cosmos 3为全世界的AI研究者提供了一个强大的基础平台。未来的物理AI智能体,或许将不再需要拼接各种“特异功能”,而是由一个像Cosmos 3这样的“全能大脑”统一指挥,在真实世界中自由地感知、推理、模拟和行动。
关注「AI论文热榜」,紧跟最前沿、最硬核的AI技术进展!
如有项目开发、科研指导等需求,请联系小编,微信号: GCgcong
