 夜雨聆风
夜雨聆风
 导览:本期主要探讨如何利用多任务学习方法,在多目标互相打架的材料设计中,从11万个候选配方里精准筛出高潜力配方,并把预测精度硬拉了37.5%,帮助材料设计从盲人摸象到精准突围。
导览:本期主要探讨如何利用多任务学习方法,在多目标互相打架的材料设计中,从11万个候选配方里精准筛出高潜力配方,并把预测精度硬拉了37.5%,帮助材料设计从盲人摸象到精准突围。


材料设计从来不是单选题,而是极其苛刻的多目标统筹,传统试错易耗费大量精力。
2025年5月,北京科技大学材料基因工程高精尖创新中心联合 AiMaterials Research LLC 等团队,在材料学顶刊《Acta Materialia》发表了一篇论文,标题为「Design of superalloys with multiple properties via multi-task learning」。

这一群人运用AI从「十一万多个」作为候选的合金当中,成功筛选并合成出 4 种完全满足所有性能指标的新型高温合金。
当看到这个数字的时候,我在最开始的时候是存在疑问的,心里想着真的是人工智能得出的结论吗?然而在继续去了解之后发现,他们并没有使用大型的模型,而是采用「多任务学习」的方法,把预测的精度提升了37.5%。
▌传统单任务困境
钴基的耐高温合金被应用于飞机发动机的涡轮叶片,其工作的环境是极端恶劣的,需要在上千度的高温以及高压的条件之下长期地耐受。所以,合金的设计存在诸多严格的要求:密度需要低一些,从而避免飞机过重;高温强度需要足够,防止在高温之下软化;加工性能需要良好,微观组织不可以无序地生长,同时还需要具备抗氧化的性能。
元素之间存在复杂的相互作用。举例来说,添加钨来提高强度,元素之间存在复杂的相互作用。举例来说,添加钨来提高强度,却有可能改变合金的凝固过程——使得从液态到固态完全凝固的温度范围变大,这个"凝固窗口"一旦过宽,铸造时合金会出现严重的成分偏析,甚至产生裂纹,导致铸造失败;添加铬来增强抗氧化性,在高温之下铬氧化物又会挥发,破坏保护层。这种“顾此失彼”的现象,正是材料设计的难点之处。
在以往的时候,运用机器学习去处理材料的情况之下,采用那种「单任务学习」的方式,分别地去开展对密度模型、凝固范围模型等模型的训练工作,看上去好像是合理的,然而却属于头痛的时候就医治头部、脚痛的时候就医治脚部的做法。
论文明确指出,这种做法忽略了其本质所在:密度、凝固范围等方面的性能虽然表现得不一样,实际上是源自于24种元素的配比情况,要是将模型进行拆分来训练的话,就没有办法识别出背后所共享的物理机制。除此之外,材料数据仅仅只有数百个样本,单独地去训练密度模型极其容易出现过拟合的状况。
所以这篇论文就换了个思路。
▌多任务学习破局
「多任务学习」指的是多个相关任务共用一套特征提取网络(编码器),再各自用独立网络(解码器)做预测,一起训练、互相借力,能够进行复用并且从中受益。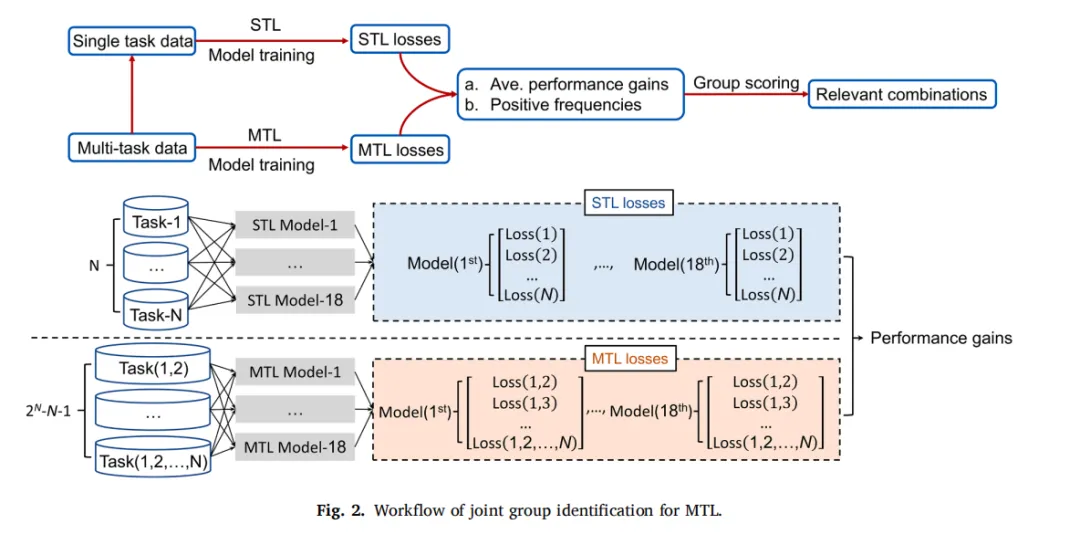
图2. MTL 联合组识别工作流程
先去制作一个具备共享性质的「编码器」,把元素的配比情况当作输入内容,让这个编码器先去摸清楚这款合金的基础特性情况,之后处于下层位置的解码器再针对各自的任务分别开展预测工作。
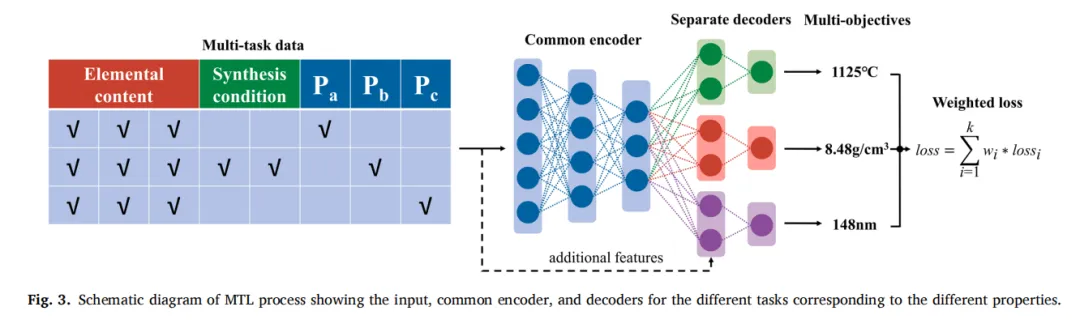
图3. MTL 流程示意图,展示不同任务对应的输入端、通用编码器及解码器,这些任务与不同属性相对应
这一招真的极为绝妙,知识能够进行复用,在学习固溶温度的时候了解了钨所起到的作用,在预测凝固温度的时候同样能够加以运用,大家相互协作来防止出现过拟合的情况,而且共享编码器学习出来的高维特征空间里面隐藏着合金真正的深层规律内容。
然而这里存在一个极大的问题,并非是什么任务都能够凑到一起的,强行把两个会相互产生负面影响的任务塞到一起只会造成相互干扰的情况,这被称作「负迁移」。
这一群人没有盲目行事,他们把所有的组合情况全部尝试了一遍,总共是57种组合,运用评分机制去查看哪种组合所带来的增益是最大的,最后筛选出了「三组组合」:γ′固溶温度加上γ′尺寸,固相线温度加上液相线温度,密度加上相分类,这是特别符合物理方面直觉的,AI在这个地方并非是盲目地去寻找规律,而是真正理解了相关内容。
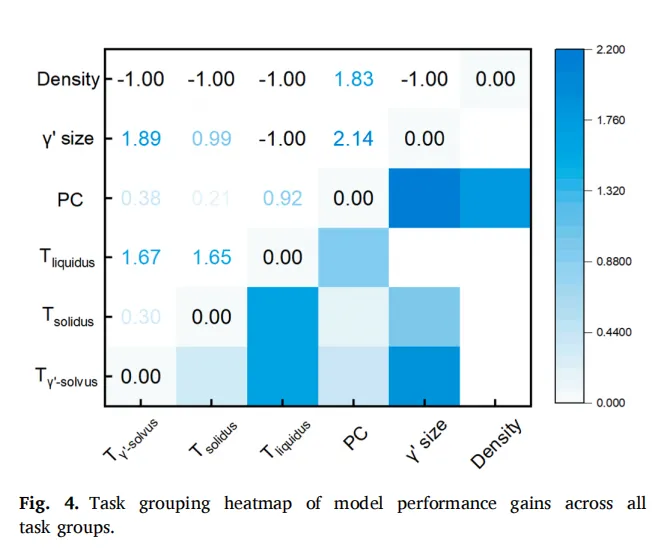
图4. 所有任务组中模型性能提升的任务分组热图
最终结果较传统单任务学习将平均归一化误差降低 37.5%,解决了高温合金数据稀疏、性能关联复杂、传统模型易过拟合的核心难题。
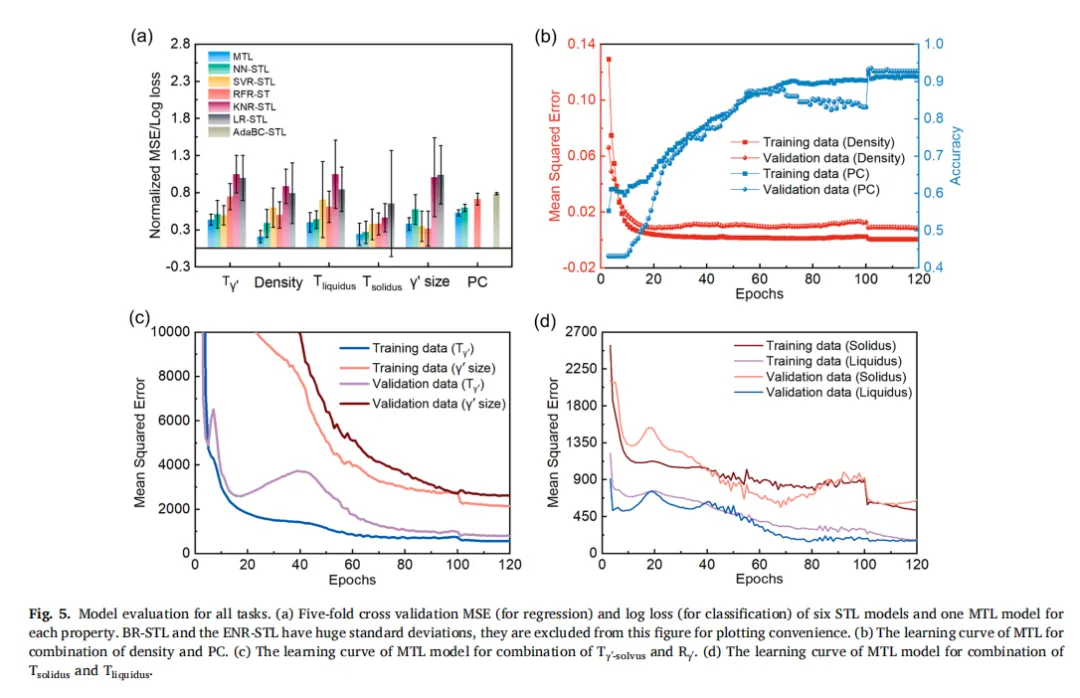
图5.所有任务的模型评估结果
模型的事情搞定之后,下一步就是要思考如何从「11万」多个配方里面挑选出那个「最为出色的配方」。
他们把编码器输出的几十维隐向量,用PCA降到二维。「PCA是一种降维技术,核心思想是:在尽可能保留原始数据信息的前提下,把高维数据投影到低维空间。」
这些维度怎么来的?
论文中,他们通过Optuna超参数优化来自动搜索最佳的网络结构。优化后的共享编码器包含4层全连接层,针对不同任务组的神经元配置分别为:
· (γ' 固溶温度,γ' 尺寸)组:[56, 56, 28, 28]
· (固相线温度,液相线温度)组:[88, 88, 44, 44]
· (密度,相分类)组:[88, 88, 44, 44]
在这个论文中,为什么要用PCA降维?
编码器最后一层的神经元数量就是编码器输出向量的维度,编码器输出的是28维、44维、44维的向量(根据不同任务组),每个维度代表合金的某种"隐藏特征"。这些维度是神经网络自动学到的,人类无法直观理解。
用PCA把它压缩到2维(第一和第二主成分),这样就可以:
1. 画图看 —— 在平面上画出所有合金
2. 发现规律 —— 找到"最优合金聚集在哪个区域"
PCA的妙处在于,它找出了"最重要的两个方向"——沿着这两个方向,合金的差异最大,信息损失最少。换句话说,PCA把所有关键信息压缩成了二维。结果就是:图上靠得近的两个点,意味着它们在神经网络眼中的所有重要特征都接近,因此实际性能也就越接近。
然后他们在图上圈出目标区域,给11万个候选配方算坐标,算距离。有意思的是,这个算法并不是简单的线性加权,如果你想探索极限的高固溶温度合金,就可以把固溶温度的权重设为3,其他的设为1,算完距离排个序,把前10名拉出来做验证实验。
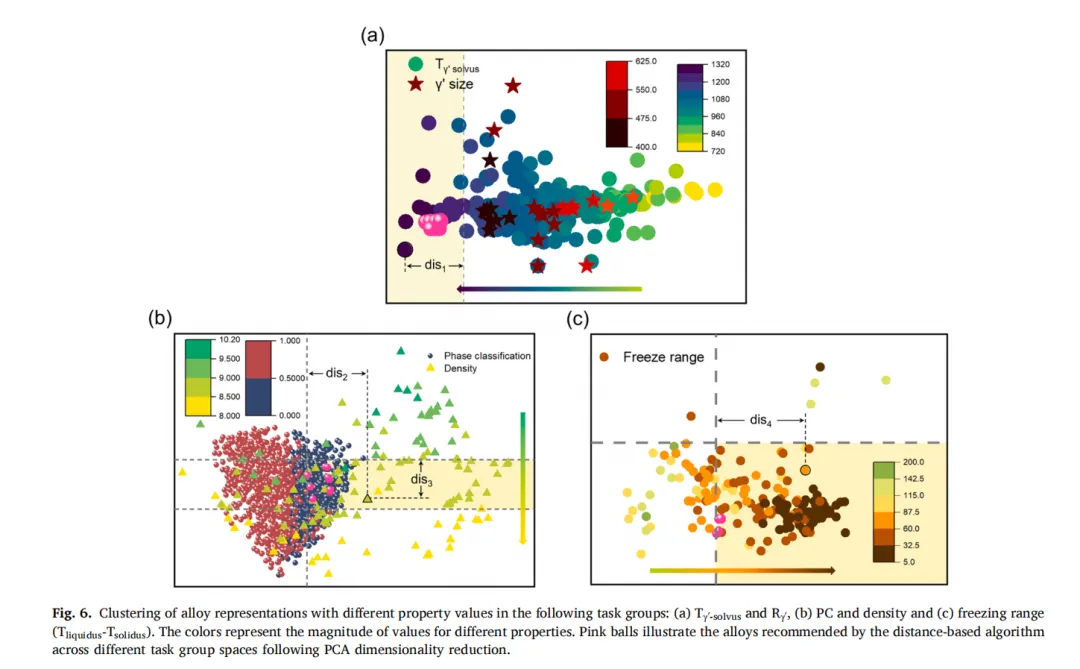
图6.不同属性值合金表征在以下任务组中的聚类情况
▌实验室里见真章
AI吹得再天花乱坠,最后也得看实验室里能不能做出来。
为了验证,这帮人还真去烧合金了,真空电弧熔炼,做固溶热处理、时效处理,测密度,用差热分析确定相变温度,上扫描电镜看微观组织,这一套流程走下来,没有任何投机取巧的空间。
结果出来,10个里面有4个合格了。其中「Alloy 8」是最特别的,γ′固溶温度干到了1220度,刷新了文献记录。密度才8.82,比很多镍基单晶还轻。凝固范围54度,好加工。长期时效后尺寸才520纳米,没怎么变大。

图7. 合金8的典型显微组织及选定元素分布
单把一个指标拉满其实不难,难的是这几个互相打架的指标,几乎全部兼顾了。对比了一下文献里的基准合金,虽然不算碾压,但是全面领先。
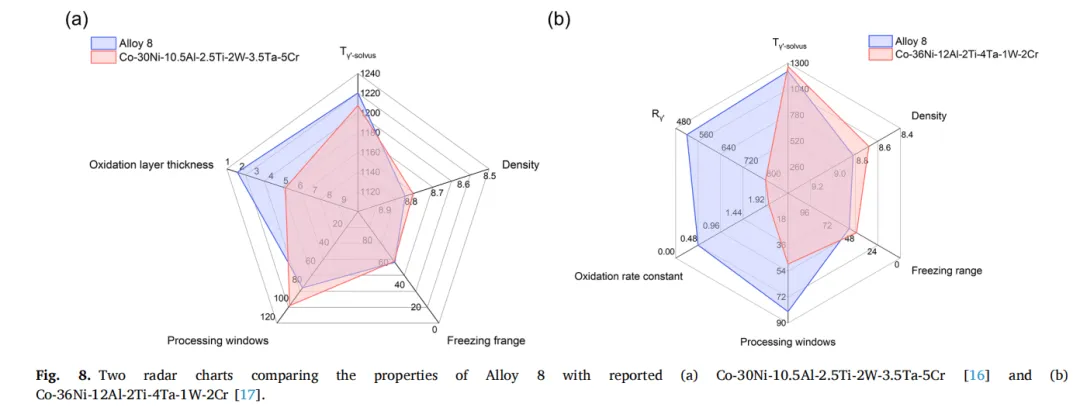
图8. 两幅雷达图对比合金8与已报道材料
所以,怎么把仅有的数据榨干,才是真本事。
它不追求模型体量有多大,而是追求机制上的联通。通过挖掘不同性能之间的内在关联,让原本孤立的数据彼此互相成就。
AI在这里根本不是要取代实验,它就是个带路的,把11万条路缩到10条,告诉你这几条最值得走。以后做电池材料、做催化剂,全都能套这个逻辑。我们大可不必总想着让AI一步登天,很多时候光是AI把明显不通的路提前筛掉,就已经能帮助我们省下很多精力了。




点击👇阅读原文可跳转原论文链接
原文链接:https://www.sciencedirect.com/science/article/abs/pii/S1359645425004495
