 夜雨聆风
夜雨聆风引言:为什么数据是AI时代唯一的"主权资产"?
2023年以来,近70%的中小企业管理层把"AI转型"挂在嘴边,半数以上的企业已经为大模型算力、SaaS工具付出了几万到几十万不等的成本,但工信部中小企业发展促进中心的调研显示,其中真正通过AI实现降本增效的企业不足15%。
绝大多数企业陷入了一个典型的资源错位陷阱:愿意为算力一掷千金,愿意为通用算法付费,却唯独对自己经营了几年、十几年沉淀下来的业务数据视而不见。不少企业的客户台账散落在不同销售的私人Excel里,历史订单和售后记录存在已经离职员工的硬盘中,生产、采购、财务数据各成孤岛,连自己查历史同比数据都要花一周时间整理,却指望通用大模型能给出贴合自身业务的精准决策建议,本质是拿着金饭碗要饭。

今天的AI产业已经进入了"同质化竞争"的阶段:头部大模型的能力差距正在快速收窄,算力采购已经变成标准化服务,任何企业只要愿意花钱就能买到同等水平的通用能力。在同模型、同算力的前提下,私有数据是唯一的胜负变量。通用大模型是公共基础设施,就像所有企业都能用上的电,而你的私有数据才是企业独有的"原料",决定了最终能生产出什么样的产品。
数据从来不是没用的"电子垃圾",它是企业所有经营决策、客户交互、生产实践沉淀下来的智慧结晶,是AI大脑的专属"基因"。没有自己的数据资产,企业的AI应用永远是无根之木。
一、核心观点:从"电子垃圾"到"数字石油"的飞跃
很多企业主会说:"我们有数据啊,电脑里存了好几百G的文件,各种报表加起来有几十万行。"但这些存放在不同地方、格式混乱、逻辑不通的内容,本质不是资产,是负担。
1. 重新定义数据资产
会计学里对资产的定义很明确:由企业拥有或者控制的、预期会给企业带来经济利益的资源。判断你的数据是不是资产,只看三个核心特征:
垃圾特征:
格式不一:销售数据存Excel,售后记录存企业微信聊天框,生产日志存纸质台账,互相之间不能打通;
逻辑断层:同一个客户在三个系统里名字不同、编号不同,根本无法还原客户的全生命周期价值;
不可检索:想要找历史信息时,翻遍了所有文件夹都找不到,相当于数据完全没有使用价值。
资产标准:
可联通:所有业务环节的数据基于统一的唯一标识打通,从线索到回款的数据可以自动串联;
可语义化:数据自带业务含义,AI可以直接读懂数据背后的业务逻辑;
可溯源:任何一个数据都能找到来源,确保数据的可信度。
我们服务过浙江宁波的一家中型服装外贸企业,2023年他们花了2个月把近3年的12000多份历史订单统一整理成标准化数据资产,上线了基于自有数据的报价AI工具,报价准确率从原来的62%提升到94%,报价时间从平均2天缩短到2小时,仅报价优化一项每年就能减少近500万的损失。
2. "脏数据"是AI决策的毒药
计算机领域有一个经典的GIGO原则:Garbage In, Garbage Out(垃圾进,垃圾出)。AI的决策质量完全取决于输入数据的质量,你给它喂错误、混乱、缺失的数据,它输出的结论必然也是错误的。
2023年广东佛山有一家中型五金制造企业,就是因为用了没有清洗过的历史生产数据训练需求预测模型,模型给出了错误的旺季需求预判,企业提前采购了3000万的原材料,最后实际销量只有预测的40%,库存积压直接导致企业现金流断裂。
二、思想认知:数据治理是"一把手工程",而非"IT杂活"
1. 认知升级:数据治理本质是业务逻辑的梳理
数据是业务活动的记录,数据治理的过程,其实是把企业的业务流程、规则、经验显性化、标准化的过程。比如你要打通销售和售后的数据,本质是要明确"从线索获取到成交再到售后的全流程节点有哪些"——比如"成交客户"的定义,销售部门认为签了合同就算,财务部门认为付了首款才算,如果这个规则不统一,数据永远对不上。

我们接触过江苏苏州的一家工业零部件制造企业,一开始老板让IT部门牵头做数据治理,IT部门花了3个月整理了一套数据标准,结果业务部门都不认可。后来老板亲自牵头,每周开跨部门数据会议,只用了1个月就确定了统一的数据标准,现在他们已经能做到实时查看每个订单的生产进度、利润情况,决策效率提升了60%以上。
2. 责任对齐:谁产生数据,谁负责质量
必须明确一个核心原则:谁产生数据,谁对数据质量负责。销售在系统里录入客户信息,这个数据的质量就是销售的责任;生产车间上报生产进度,这个数据的质量就是车间主任的责任。给每个数据字段设置"所有者",明确录入规范和考核要求,错误率超过阈值的对应责任人扣绩效。
3. 长期主义:数据的"复利效应"
数据是唯一会越用越值钱、越积累价值越大的资产。你今天整理了1000条历史客户数据,可能当下只能做一个简单的客户分层;等你积累到10000条,就可以训练销售预测模型;等你积累到10万条,还可以分析不同行业客户的需求变化,指导产品研发。亚马逊从1994年开始积累用户数据,推荐系统贡献了35%以上的销售额,供应链预测准确率比行业平均高20%,这就是数据复利的力量。
三、实现路径:中小企业"轻量化"数据基座三步走
1. 资产盘点——"翻箱倒柜"找金矿
第一步做全面的数据资产盘点,覆盖所有业务环节:前端业务数据(客户信息、订单、售后记录)、后端运营数据(采购、生产、库存、财务)、非结构化数据(产品文档、培训材料、会议纪要)。我们服务过的一家深圳跨境电商企业,盘点时发现运营部门存了近5年的120多万条客户邮件往来记录,整理后训练了智能客服回复模型,客服效率提升了50%。
2. 数据清洗与标签化——给AI准备"精饲料"
数据清洗的核心是解决"四不"问题:补全缺失值、删除重复值、修正错误值、统一标准值。清洗完之后要给数据打标签——标签是业务含义的提炼,是让AI读懂数据的关键。中小企业一开始先做10-20个核心业务标签就够了。
3. 构建"轻量级数据中枢"
三种低成本方案:
方案一(100人以下):用飞书多维表格/腾讯云文档高级功能,年费几百块;
方案二(100-500人):用FineBI、简道云、明道云等轻量BI工具,年费几千到几万;
方案三(有技术能力):买云服务器,用MySQL+MinIO搭私有数据中台,一次性几万块。
四、方法参考:RAG架构——中小企业低成本"用数"神器
1. 什么是RAG(检索增强生成)
RAG就是"先检索你的私有数据,再把相关内容和问题一起交给大模型,让大模型基于你的私有数据给出回答"的技术框架。工作流程只有三步:将私有数据做向量化处理存入向量数据库;用户提问时先检索相关数据;将检索到的数据和问题一起传给大模型生成回答。
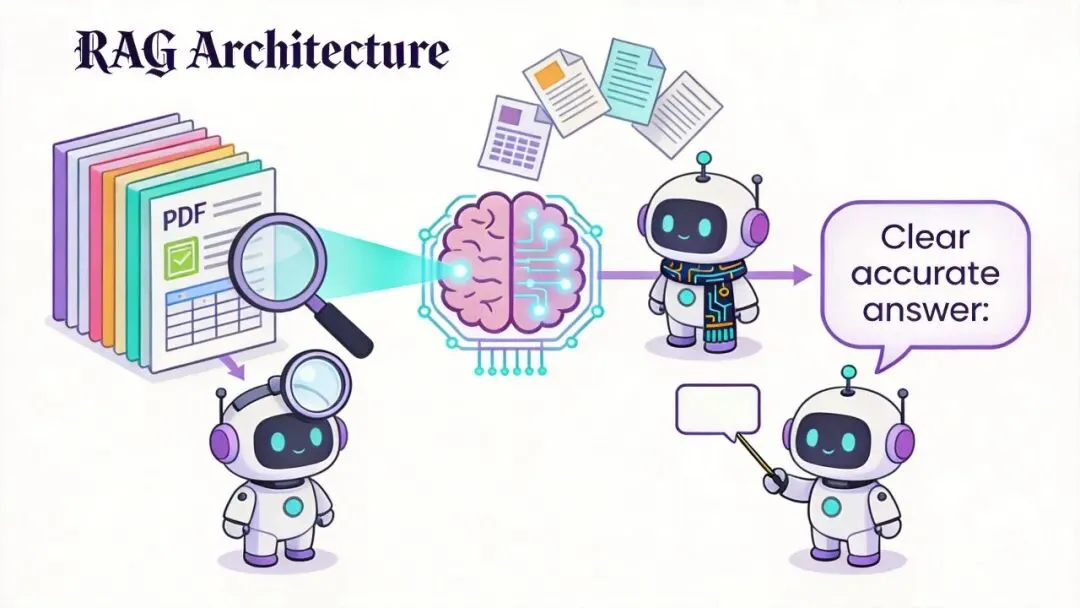
2. 为什么RAG是中小企业的救星
RAG完美适配中小企业的需求:
成本低:只需几千元云服务费,不需要招算法团队;
见效快:有整理好的数据,一周就能搭好能用的RAG应用;
准确率高:基于真实私有数据回答,准确率可达95%以上。
3. 应用示例
智能客服场景:杭州一家智能家居企业,上线RAG智能客服助手后,新员工培训周期从1个月缩短到3天,客服回复准确率从75%提升到92%,客户满意度提升28%。
销售支持场景:上海一家企业服务公司用了RAG销售助手后,销售成单率提升22%,新人开单周期从3个月缩短到1.5个月。
内部知识管理场景:深圳一家互联网公司用了RAG内部知识助手后,跨部门沟通时间减少40%,新人入职适应周期缩短一半。
五、避坑指南:数据建设的"三大深坑"
1. Excel依赖症
Excel天生不适合做企业级数据管理:没法实时多人协同、没法自动跨表关联、容易丢失、权限控制弱。我们见过不止一家企业因为销售离职带走了存客户数据的Excel,导致整个区域的客户信息丢失。核心业务数据必须统一存在线上系统里。
2. 贪多嚼不烂
东莞一家制造企业一开始想做全链路数据平台,预算80万、6个月。我们建议先从最痛的库存数据入手,只花2万、1个月就上线了库存预警功能,第一个月减少了100多万库存积压。看到效果后才继续投入,总投入不到20万。
3. 安全裸奔
2023年江苏一家贸易企业因员工电脑被植入木马,客户数据被竞争对手窃取,不到半年流失30%的老客户。中小企业只要做好四点就能避免90%的安全风险:核心数据统一存在企业云服务器;设置严格的权限控制;定期做数据备份;签订保密协议。
六、实战建议:开启"30天数据唤醒计划"

小结
AI时代,没有数据资产的企业,永远只能做行业的跟随者。你今天花在数据治理上的每一分钱、每一分钟,未来都会十倍、百倍地回报给你。
不要觉得数据建设是大企业的事,中小企业体量小、流程灵活,反而更容易把数据用好。不需要搞复杂的系统,不需要花很多钱,从今天开始,先把散落在各处的核心数据整理起来,搭一个最简单的RAG应用,你就已经超过了90%的竞争对手。
算力可以买,算法可以买,但你经营了十几年沉淀下来的客户数据、业务经验、行业认知,是永远买不来的——这才是你在AI时代真正的"主权资产"。
