 夜雨聆风
夜雨聆风
训练和推理的定义

训练和推理的区别

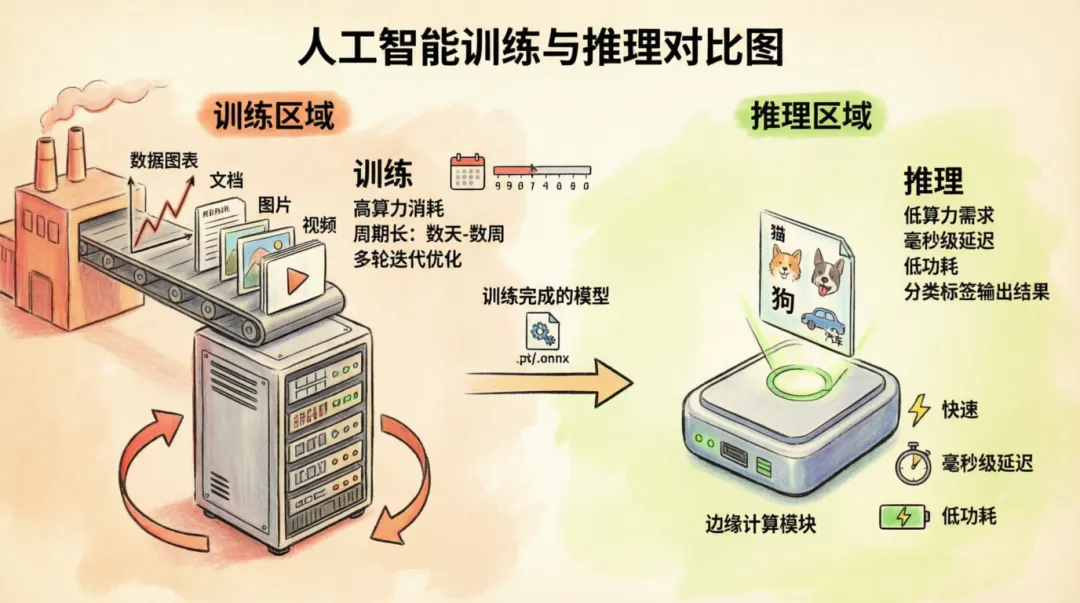
训练和推理的工作流程

损失计算:把预测结果与真实答案进行对比,计算出两者之间的差距。就像老师批改学生答案,算出丢了多少分、错在哪里。
反向传播:根据计算出的损失,从输出端逆向推导出每个参数对损失的责任大小。就像根据丢分原因倒推回去,分析是哪道题、哪个知识点出了问题。
权重更新:根据反向传播得出的责任大小,调整模型的参数以减少下次预测的损失。就像学生根据错题分析修正自己的认知,下次遇到类似题目能答对。
与复杂的训练过程相比,推理过程要简单得多,通常包含以下几个主要步骤:
输入预处理:将原始数据(文本、图片或语音等)转化为模型可以理解的数值。就像厨师拿到食材后,先洗菜、切菜、称重配比成适合下锅的“标准形态”。
前向传播:将处理好的数据传入训练好的模型,仅执行一次前向计算,得到预测结果。就像厨师按照早已熟记于心的菜谱,把配好的食材依次下锅、快速翻炒,一气呵成,不再边做边尝边改。
输出解码:将模型生成的原始结果转换为用户可读的最终答案。就像厨师把做好的菜肴精心装盘、端上餐桌,让食客看到的是色香味俱全的成品,而不是半成品让客户自己判断。
训练与推理是AI落地的“黄金搭档”,覆盖我们生活与产业的方方面面。训练负责让AI“变聪明”,在算力中心里啃海量数据、打磨大模型、优化算法,支撑起AI绘画、自动驾驶、工业质检、医疗影像分析等复杂能力;推理则让AI“好用”,在手机、终端、云端快速响应用户需求,实现语音对话、智能推荐、实时检测等即时服务。从日常聊天到智能制造,从智慧医疗到智慧城市,AI的每一次“思考”与“回应”,都是训推协同的结果 。
AI的每一次“思考”与“回应”,看似神奇,背后都是训练与推理的无数次协同。而河北人工智能计算中心,正在为这场协同搭建最坚实的舞台。依托昇腾算力底座,它让科研创新跑出加速度,也让中小微企业不再被算力门槛挡在AI大门之外。当训推能力真正“用得起、用得好”,便为区域产业智能化升级装上了“加速器”。

