当前时间: 1970-01-01 08:00:00
分类:办公文件
评论(0)
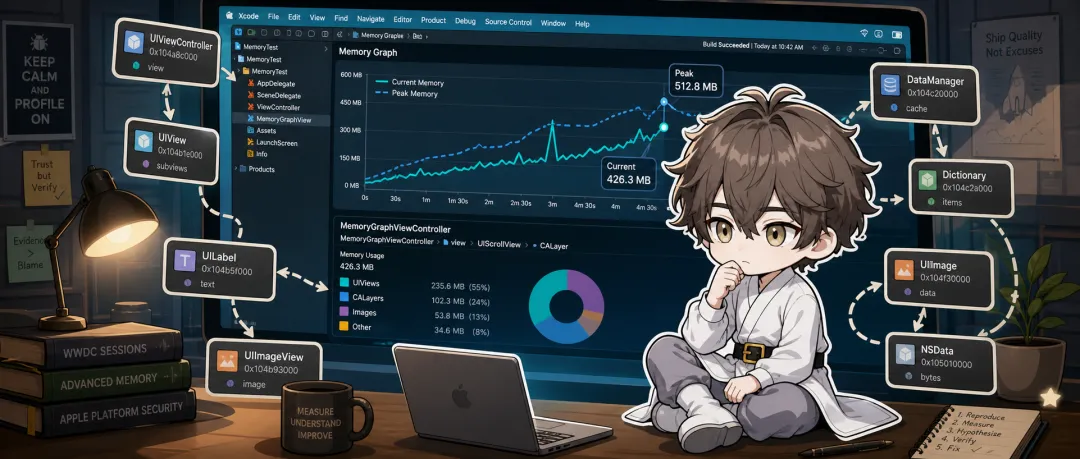
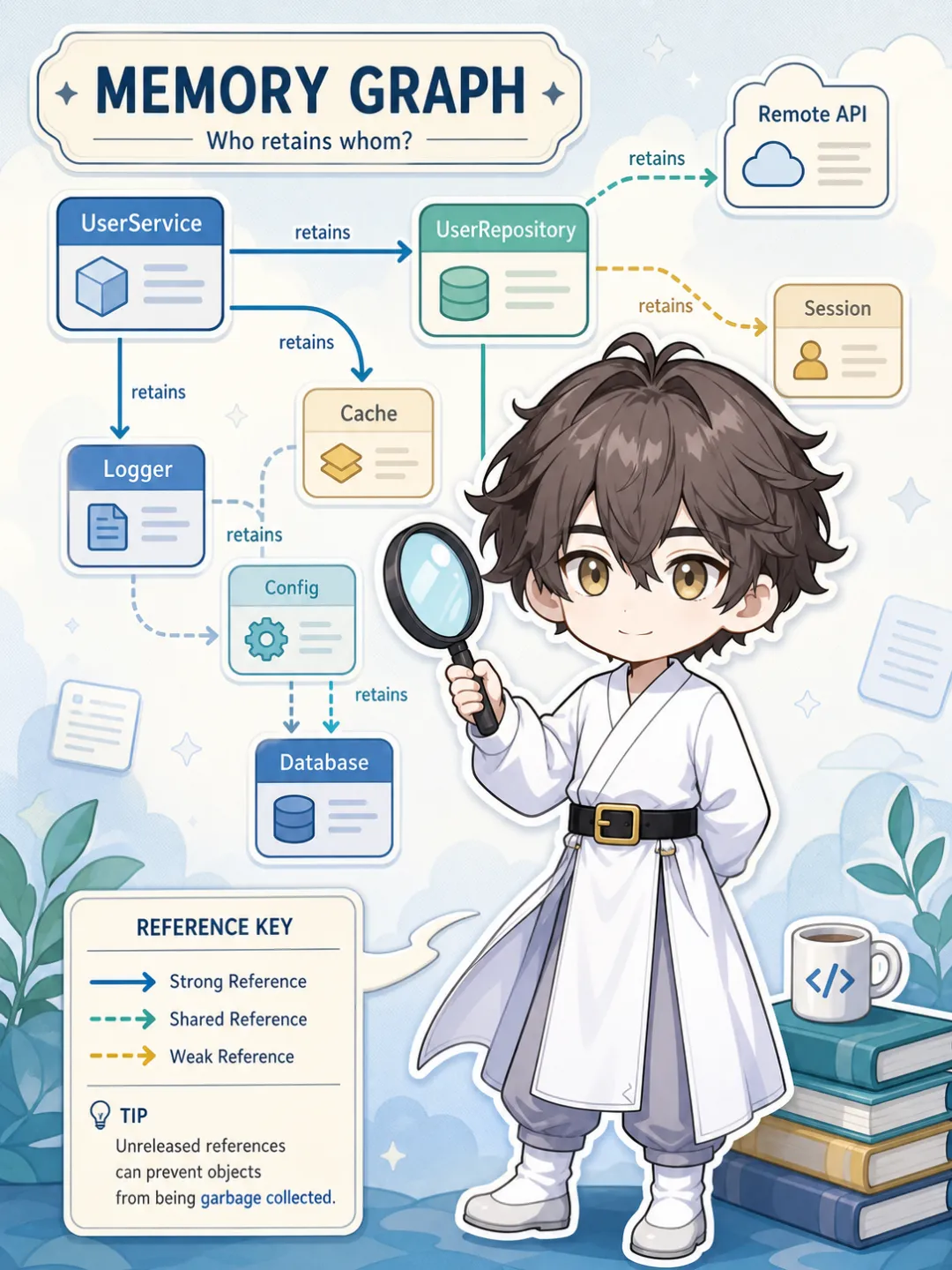
iOS 内存涨了,先别急着找循环引用测试同学甩来一句,「这个页面退出来以后,手机一直在发烫,是不是出现了内存问题?」很多团队的第一反应都很一致,开始翻闭包,翻 delegate,翻 timer,顺手再全局搜一遍 weak self。这套动作不能说错,但我现在越来越警惕这种条件反射。因为它很容易把一件还没看清的事,提前定性成另一件事。这几个词放在群里聊的时候,看起来像一回事。真到排查现场,它们其实差得很远。有时候你看到的只是峰值高。比如某次进入详情页,图片一次性解码太多,内存瞬间抬上去,过一会儿才慢慢回落。有时候是某段功能真的在持续加对象,但不是谁和谁互相咬住了,而是缓存根本没收,或者某次批量处理把一堆大对象都堆在了同一个阶段里。也有时候,问题确实就是循环引用,页面都退干净了,对象还稳稳挂在那儿。问题是,这三种情况,你如果上来就用同一种脑回路去查,效率会非常差。我现在更认的一条顺序很简单,先看现象,再看关系,最后才谈原因。Apple 在 Xcode 的内存排查文档里写得很直接,memory report 可以先看当前值和峰值。这个动作看起来很普通,但特别有用,因为它会逼着你先回答一个问题,你看到的到底是短时间峰值,还是一直涨着不下来。还有一个我以前也容易忽略的点,模拟器里一片绿色,不代表真机就安全。Apple 明确提醒过,Simulator 不会像 iPhone 或 iPad 那样发内存 warning,也不会因为 OOM 直接把你杀掉。所以你在模拟器里觉得「好像也还行」,这个结论最好别下得太早。我现在碰到内存问题,第一件事通常不是改代码,而是先在真机上把路径复现清楚,然后记住两个点,当前值怎么变,峰值怎么变。如果峰值抬得很夸张,我会先怀疑是不是图片、解码、批量数据或者大块分配。如果页面来回进出几次以后,基线一路往上抬,我才会更认真地怀疑对象没有释放干净。这一步我反而不急着开一堆 Instruments。我通常会先点 Debug Memory Graph。原因很简单,它不是告诉你「哪里一定有 bug」,而是先把对象之间谁在持有谁摊开给你看。因为很多人说自己在查循环引用,实际上查的是猜想,不是关系。你怀疑某个控制器没释放,那就别先开搜。先看它还在不在图里,在的话,是谁把它留住了。是闭包,是 Notification,是某个缓存容器,还是中间层对象压根就还活着。只要这个图没看,很多讨论都还是口水仗。当然,Memory Graph 也不是万能的。它更适合回答「谁还活着,谁在持有谁」,不太适合回答「这段操作到底多分配了多少内存」。所以第三步要补上另一个视角,分配路径。Apple 对 Allocations instrument 的描述我很认同。它最有价值的地方,不是让你盯着一整条长时间线发呆,而是可以用 Mark Generation 把某个功能前后切开看。比如你准备进入一个重页面,先标一下 generation,做完这次操作再标一次。这样你会更容易看见,这段过程中到底新增了哪些分配,它们有没有回来,最大的几类是谁。之前大家都在说「感觉内存变大了」,现在你能看到到底是谁变大了。我很喜欢 Apple 在 TN2434 里反复强调的那个思路,先盯大头,先看 Persistent Bytes。因为很多时候,真正把内存拖上去的不是一串细碎的小对象,而是那几个体量很大的分配来源。你先把大头找出来,后面的路径会顺很多。如果 Memory Graph 已经明确告诉你,页面退掉以后对象还被一条强引用链留着,那就查循环引用,别客气。如果 Allocations 告诉你新增的大头是图片相关分配,那就先回去看资源尺寸、解码时机和复用策略。如果增长集中在某段数据写入流程,Apple 也明确提到过,Core Data 事务过大,本身就会把变化先堆在内存里,这时你要想的是事务边界,不是 weak self。如果问题更像缓存,那就回头看缓存淘汰条件,而不是继续在对象生命周期里打转。我现在最怕的一种排查方式,就是一边没有证据,一边动作特别大。今天加一圈弱引用,明天拆一个回调层,后天顺手把架构也改了。最后内存可能确实好了,但团队其实并不知道到底是哪一步解决了问题。这样的修法,短期看像推进,长期看是在消耗可判断性。先确认你看到的是峰值、持续增长,还是功能期内的大块分配。如果真是循环引用,那这一套顺序不会拖慢你,反而会让你更快收口。如果根本不是循环引用,这套顺序会替你省掉很多无效劳动。还有一步我觉得特别适合团队化,就是把回归也做掉。Apple 提供了 XCTMemoryMetric,可以给关键流程设 baseline。这个动作的意义不是让测试报告变得更漂亮,而是别让同一个内存问题在两周以后又换个入口重新出现。我反对的是,问题刚冒头,我们就把它默认解释成循环引用。真正浪费时间的是,现象还没分清,原因已经被我们自己偷偷写进结论里了。所以下次再听到一句「内存怎么没降」,我更建议先慢半步。先看 memory report,先看 Memory Graph,必要时再去 Allocations 里记账。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-05 19:43:06 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/716982.html
- 运行时间 : 0.096611s [ 吞吐率:10.35req/s ] 内存消耗:4,732.42kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=b16c04a1d7923fb9c6300b3e1c8b799a
- CONNECT:[ UseTime:0.000468s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.000683s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000295s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000272s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.000514s ]
- SELECT * FROM `set` [ RunTime:0.000207s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.000619s ]
- SELECT * FROM `article` WHERE `id` = 716982 LIMIT 1 [ RunTime:0.000423s ]
- UPDATE `article` SET `lasttime` = 1780659786 WHERE `id` = 716982 [ RunTime:0.000754s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000234s ]
- SELECT * FROM `article` WHERE `id` < 716982 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.000406s ]
- SELECT * FROM `article` WHERE `id` > 716982 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.000439s ]
- SELECT * FROM `article` WHERE `id` < 716982 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.000621s ]
- SELECT * FROM `article` WHERE `id` < 716982 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.000874s ]
- SELECT * FROM `article` WHERE `id` < 716982 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.001486s ]

0.098399s

 夜雨聆风
夜雨聆风