 夜雨聆风
夜雨聆风量化是深度学习、大模型部署、模型压缩、推理加速和边缘计算中非常重要的一个术语,用来描述一种把模型中的高精度数值转换为低精度数值的技术。换句话说,量化是在回答:如何让模型在尽量保持效果的前提下,占用更少显存、运行得更快、部署成本更低。
在神经网络中,模型参数和中间计算结果通常是浮点数。例如,训练时常用 FP32 或 BF16/FP16 表示权重和激活值。量化则会把这些数值转换成 INT8、INT4 等更低精度格式。这样做会减少模型存储空间和计算开销,但也可能带来一定精度损失。
因此,量化常用于大语言模型本地部署、移动端推理、边缘设备运行、低延迟服务和高并发推理,是大模型工程化落地中的重要优化方法。
一、基本概念:什么是量化
量化(Quantization)指把连续或高精度的数值,近似映射为更少位数的离散数值。
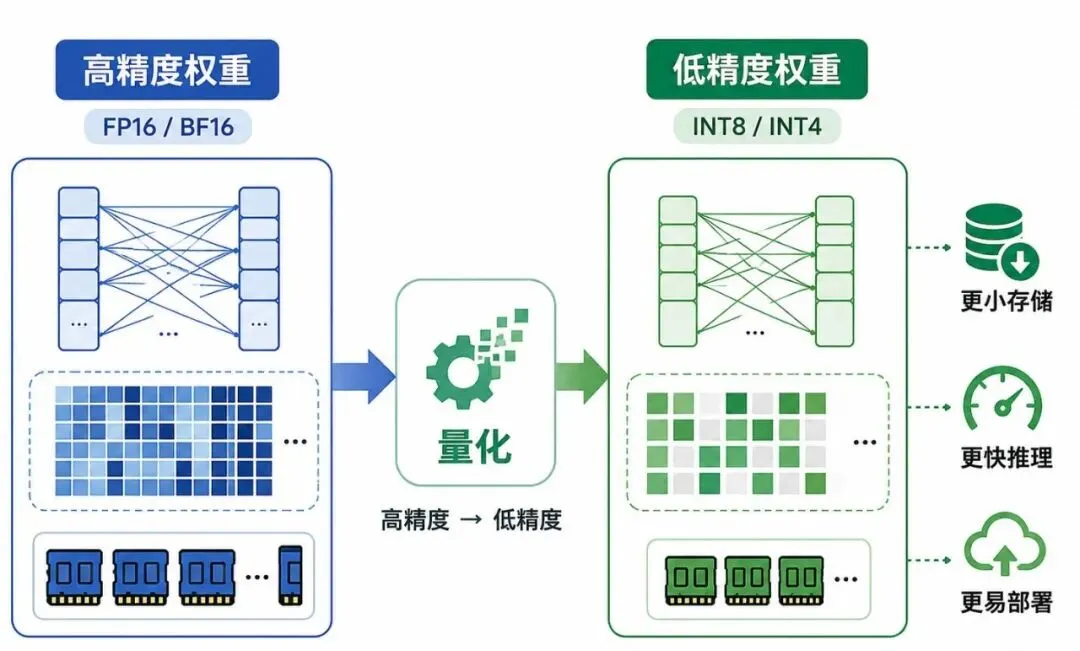
图 1:量化技术与低精度优化
例如,一个模型权重原本使用 FP16 存储,每个参数约占 2 字节;如果量化为 INT8,每个参数约占 1 字节;如果量化为 INT4,每个参数约占 0.5 字节。
可以简单理解为:FP32 / FP16 / BF16 → INT8 / INT4。
从通俗角度看:量化像是把一张高清照片压缩成体积更小的图片。压缩后文件更小、加载更快,但如果压缩过度,细节可能会损失。
在模型中,被压缩的不是图片,而是大量权重和计算值。
例如,一个 7B 参数模型,如果用 FP16 存储权重,大约需要:
也就是约 14GB 级别的权重存储。
如果使用 INT8,权重大小大约减半;如果使用 INT4,权重大小还可以进一步降低。
二、为什么需要量化
量化之所以重要,是因为大模型虽然能力强,但部署成本很高。
大模型通常面临几个问题:
• 参数量大,显存占用高
• 推理速度慢,响应延迟高
• 部署硬件要求高
• 并发服务成本高
• 难以运行在本地或边缘设备上
例如,一个大语言模型即使只做推理,也需要把大量权重加载到显存中。模型越大,显存压力越明显。
量化可以缓解这些问题。它的主要价值包括:
• 减少模型文件大小
• 降低显存占用
• 提高推理速度
• 降低部署成本
• 支持本地和边缘设备运行
• 提高高并发服务能力
从通俗角度看:量化不是让模型“更聪明”,而是让模型“更省”。它关注的是工程效率,而不是单纯提升模型能力。
三、量化到底压缩什么
量化可以作用在模型的不同部分。
1、权重量化
权重量化是最常见的形式。它把模型参数从高精度格式转换为低精度格式。
例如:
FP16 权重 → INT8 权重FP16 权重 → INT4 权重
权重量化主要减少模型存储和显存占用。
2、激活量化
激活值是模型推理过程中各层产生的中间结果。激活量化会把这些中间计算结果也转换为低精度表示。
它可以进一步减少计算和内存开销,但对模型精度影响可能更明显。
3、权重与激活同时量化
有些部署场景会同时量化权重和激活。
例如:
W8A8:权重 INT8,激活 INT8W4A16:权重 INT4,激活 FP16
其中:
• W 表示 Weight,即权重
• A 表示 Activation,即激活值
• 数字表示使用的位宽
从实践角度看,权重量化更常见,也相对容易;激活量化对硬件和算法要求更高。
四、量化的基本思想
量化的核心是把浮点数映射到整数。
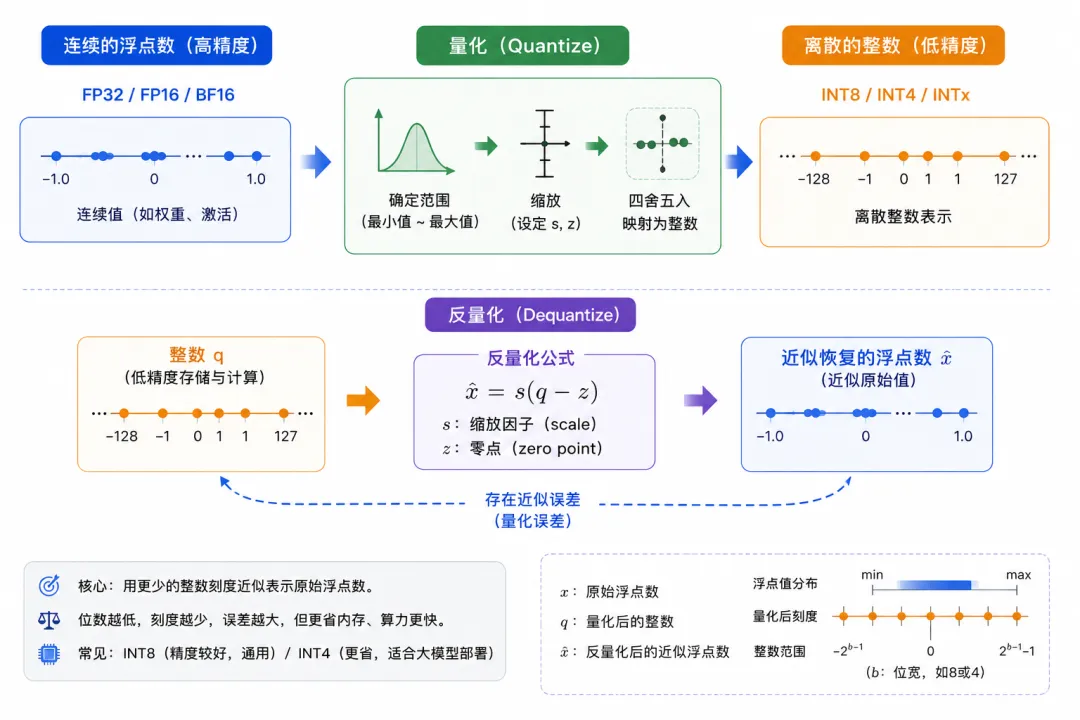
图 2:量化与反量化工作流程图
例如,一个浮点数 x 可以近似表示为:
其中:
• x 表示原始浮点数
• q 表示量化后的整数
• s 表示缩放因子
• z 表示零点
• round 表示四舍五入
反量化时,可以把整数近似恢复为浮点数:
其中:
• x̂ 表示恢复后的近似值
• q 表示量化整数
• s 和 z 用于还原数值范围
从通俗角度看,量化需要解决两个问题:用更少的数字刻度表示原来的数值;再尽量把这些刻度还原成接近原值的结果。
由于低精度表示的刻度更少,所以量化一定存在近似误差。
关键在于:误差是否足够小,模型效果是否还能接受。
五、常见量化方式
1、训练后量化
训练后量化通常称为 PTQ,即 Post-Training Quantization。它是在模型训练完成后,直接对模型进行量化。
优点是:
• 简单
• 成本低
• 不需要重新完整训练
• 适合快速部署
缺点是:
• 可能带来精度下降
• 对低位量化更敏感
• 复杂任务中需要校准数据
2、量化感知训练
量化感知训练通常称为 QAT,即 Quantization-Aware Training。它在训练或微调过程中模拟量化误差,让模型提前适应低精度表示。
优点是:
• 精度通常更好
• 适合对精度要求高的任务
• 适合更激进的低位量化
缺点是:
• 训练成本更高
• 实现更复杂
• 需要额外数据和调参
3、动态量化与静态量化
动态量化是在推理时动态确定部分量化参数。
静态量化则通常需要提前使用校准数据估计数值范围。
可以简单理解为:
• 动态量化:运行时更灵活
• 静态量化:部署时更固定
实际选择取决于模型结构、硬件支持和部署目标。
六、量化与蒸馏、剪枝的区别
量化经常和蒸馏、剪枝一起出现,但三者目标不同。
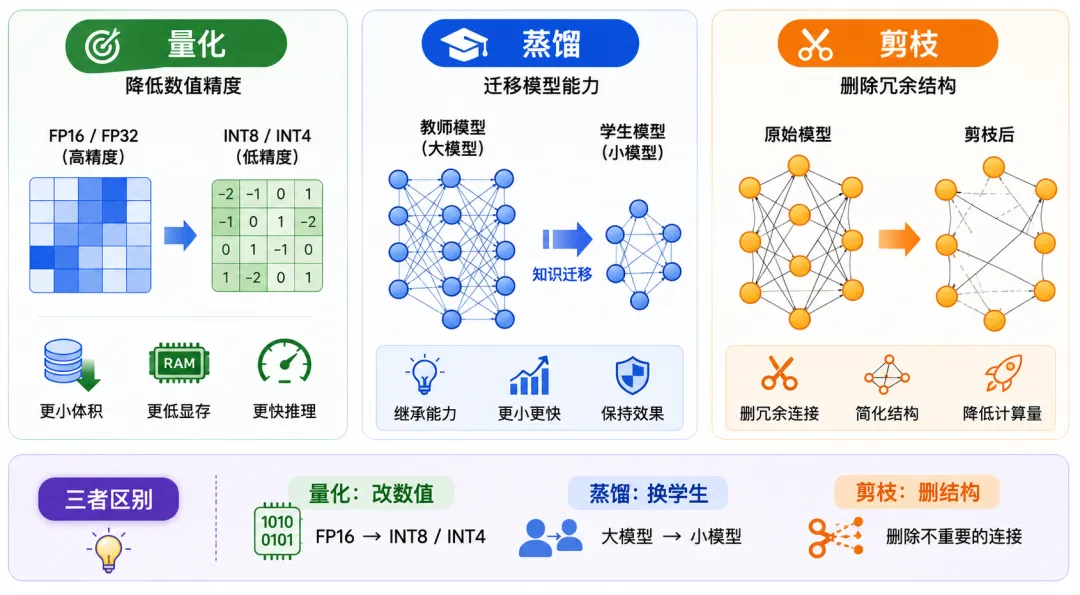
图 3:量化、蒸馏与剪枝的对比
1、量化
量化关注的是:用更低精度表示模型数值。
它主要改变数值表示方式,不一定改变模型结构。
2、蒸馏
蒸馏关注的是:让小模型学习大模型的能力。
它通常涉及教师模型和学生模型。
3、剪枝
剪枝关注的是:删除模型中不重要的连接、通道、神经元或结构。
它会减少模型实际结构或计算路径。
可以概括为:
• 量化:降低数值精度
• 蒸馏:迁移模型能力
• 剪枝:删除冗余结构
实际工程中,这些方法可以组合使用。
例如:先蒸馏得到小模型,再量化部署。
七、量化的优势、局限与常见误解
1、量化的主要优势
量化最大的优势是降低模型部署成本。
它可以让模型:
• 文件更小
• 显存占用更低
• 加载更快
• 推理更快
• 更适合本地部署
• 更适合移动端或边缘设备
对于大语言模型而言,INT8 或 INT4 量化常常是本地运行的重要前提。
2、量化的主要局限
量化也有局限。
首先,量化会引入数值误差。
精度越低,误差通常越明显。
其次,不同模型对量化敏感程度不同。
有些模型 INT8 几乎不掉效果,有些模型 INT4 后效果下降明显。
再次,量化效果依赖任务。
简单任务可能影响较小;复杂推理、长文本生成、代码生成等任务可能更敏感。
此外,量化加速还依赖硬件和推理框架支持。
如果硬件不支持低精度高效计算,模型虽然变小,但不一定明显变快。
3、常见误解
误解一:量化一定会让模型变快。
不一定。是否变快取决于硬件、框架和算子优化。
误解二:量化只是压缩模型文件。
不完全对。量化还可能影响显存、带宽、计算速度和部署方式。
误解三:INT4 一定比 INT8 更好。
不一定。INT4 更省,但更容易损失精度。
误解四:量化不会影响模型效果。
不对。量化是近似计算,可能影响输出质量。
八、如何选择量化方案
选择量化方案时,需要综合考虑任务、硬件和效果要求。
如果任务对准确性要求高,可以优先考虑:
• FP16 / BF16
• INT8
• QAT
如果部署资源有限,可以考虑:
• INT8 权重量化
• INT4 权重量化
• 混合精度量化
如果模型用于本地大语言模型推理,需要重点关注:
• 显存占用
• 上下文长度
• KV Cache
• 推理框架支持
• 量化格式兼容性
• 实际任务效果评估
从实践角度看,量化方案不是越低越好,而是要在效果、速度、显存和成本之间取得平衡。
比较稳妥的思路是:先用较高精度建立基线;再尝试 INT8 或 INT4;最后用真实任务评估效果。
九、Python 示例
下面用简化示例说明量化的基本思想。
示例 1:估算权重存储大小
def estimate_size(num_params, bytes_per_param):size_gb = num_params * bytes_per_param / (1024 ** 3)return size_gbnum_params = 7_000_000_000print("FP16:", estimate_size(num_params, 2), "GB")print("INT8:", estimate_size(num_params, 1), "GB")print("INT4:", estimate_size(num_params, 0.5), "GB")
这个例子只估算权重大小。实际推理还需要考虑 KV Cache、激活值和框架开销。
示例 2:浮点数到整数的简单量化
import numpy as npx = np.array([-1.0, -0.5, 0.0, 0.5, 1.0])scale = 0.1zero_point = 0q = np.round(x / scale).astype(np.int8)x_hat = q * scaleprint("原始值:", x)print("量化值:", q)print("反量化:", x_hat)
这个例子展示了:浮点数 → 整数量化值 → 近似恢复。
示例 3:量化误差
error = np.abs(x - x_hat)print("误差:", error)print("平均误差:", error.mean())
量化误差越小,说明低精度表示越接近原始数值。但在真实模型中,需要看最终任务效果,而不是只看单个数值误差。
量化是一种把模型中的高精度数值转换为低精度数值的模型压缩与推理优化方法。它可以减少模型大小、降低显存占用、提升部署效率,但也可能带来精度损失。对初学者而言,可以把量化理解为:用更少的数值位数近似表示模型参数和计算结果,让模型运行得更省、更快、更容易部署。

