 夜雨聆风
夜雨聆风
你有没有这种感觉:现在再去学 JDK 垃圾回收,好像有点“复古”。
Copilot 能补业务代码, Cursor 能改接口, ChatGPT 能给你生成一整个 Java 类。你丢一句“帮我写个商品缓存”,它几秒钟就把 Map、put、get、异常处理都摆出来。
看起来挺香。
然后问题来了: AI 都会写代码了,我们为什么还要学 JDK 垃圾回收?为什么还要理解堆、老年代、 Full GC 、 G1 、 ZGC 这些听起来像面试黑话的东西?
我的答案:
AI 可以帮你写代码,但生产环境炸了,背锅的人还是你。
这话不浪漫,甚至有点烦。
但工程就是这么一回事。代码能跑,不代表系统扛得住;接口能通,不代表大促当天 P99 不会飞上天; IDE 里没有红线,不代表 JVM 里没有一堆对象正悄悄把老年代塞满。
AI 会写业务,但它看不见你的堆
AI 写 Java 业务代码,已经很像一个手脚很快的初级同事。
你让它写订单创建,它能写。让它写商品详情查询,它也能写。让它把支付回调用策略模式拆一下,它甚至能拆得挺像那么回事。
可你要问它:这个对象能不能长期活着?这批临时对象会不会在一次大促流量里把 Eden 区打爆?缓存上限应该怎么设?一次 Full GC 卡 800ms ,用户会不会在支付页点第二次?
它会给你一堆正确但没用的话。
“建议监控 GC 日志。”
“建议合理设置堆大小。”
“建议优化对象生命周期。”
嗯。
听着像开会。
真正的问题在于, AI 并不知道你的电商系统长什么样。它不知道你们商品详情页有多少 SKU ,不知道促销活动会不会一次性把几十万个商品快照塞进内存,不知道你们对 P99 延迟的容忍线是 100ms 、 300ms ,还是“别挂就行”。
JVM 垃圾回收不是抽象概念。它是你系统里的仓库管理员。
用户浏览商品,会创建商品详情对象;用户加购物车,会创建购物车快照;用户下单,会创建订单对象、库存扣减请求、优惠券计算结果、支付流水上下文。大多数对象很快就没用了,像电商仓库里大促临时堆出来的包裹,来得快,走得也快。
问题是,谁来清?
JDK 的 GC 来清。
但 GC 怎么清、什么时候清、清的时候要不要暂停业务线程、清完会不会留下碎片、对象为什么会晋升到老年代,这些东西 AI 不替你承担后果。
OpenJDK 这些年为什么要不断演进 G1 、 ZGC 、 Shenandoah ?不是为了让术语更吓人,而是因为现代 Java 应用早就不是“写个类,跑个 main 方法”那么简单了。 Oracle 的 GC 调优文档里一直把吞吐量、停顿时间、内存占用放在一起讲,因为它们本来就是一组互相拉扯的指标。
你选了一个方向,另一个方向就会疼。
这才是真实工程。
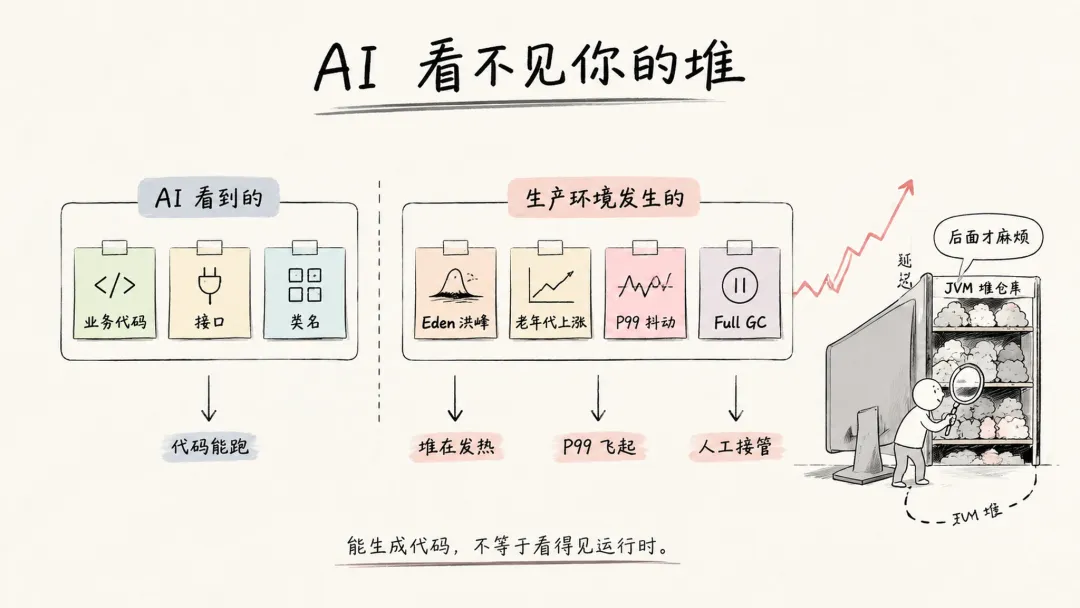
AI 擦不掉的屁股,通常都在内存里
讲个很常见的事故。
一个电商团队想做商品详情缓存。需求很朴素:热门商品别每次都查数据库,先放内存里,访问快一点。
于是有人让 AI 生成了一个缓存工具类。
看起来没毛病。
public class AIGeneratedCache {private static Map<String, ProductDetail> cache = new HashMap<>();public void put(String key, ProductDetail value) {cache.put(key, value);}public ProductDetail get(String key) {return cache.get(key);}}
代码清爽,结构简单,还没有报错。
坏就坏在“没有报错”。
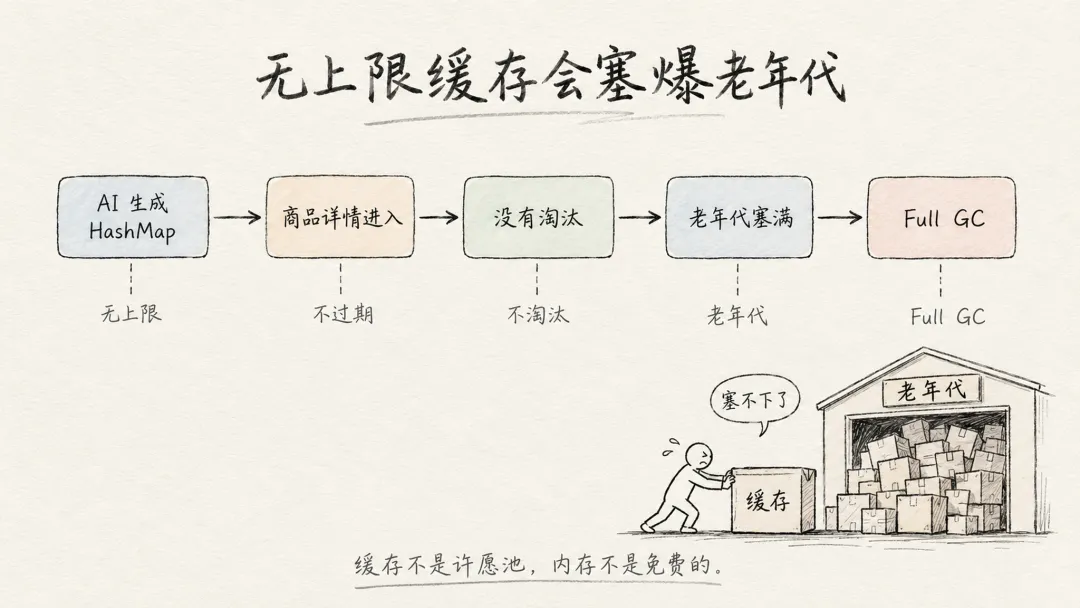
这个 HashMap 没有最大容量,没有过期时间,没有淘汰策略。商品详情对象如果还带着图片 URL 、营销标签、库存快照、活动价、推荐信息,单个对象未必大得离谱,但架不住它一直涨。
一万条,两万条,十万条。
老年代开始发烧。
等到某个周五晚上,运营突然开了个限时促销,页面流量上来,缓存也跟着膨胀。 JVM 先是 Minor GC 变频繁,然后老年代顶不住, Full GC 开始冒头。
用户那边看到的不是“老年代空间不足”。
用户看到的是:商品页转圈、下单按钮没反应、支付页卡住。
这就很烦了。
更离谱的是,有些 AI 还会顺手给你塞一个 SoftReference,说“内存紧张时 JVM 会自动回收软引用对象,所以可以做缓存”。
半对。
软引用确实是 Java 里的引用类型, Oracle 的 API 文档也明确说,软可达对象会在 JVM 抛出 OutOfMemoryError 之前被清理。但它什么时候清、清多少、清完你的缓存命中率变成什么鬼样子,不是你能精确控制的。
拿它当生产缓存策略,就像把电商仓库的淘汰规则写成“仓库快爆了你们看着扔吧”。
这不是架构。
这是糊弄学。
懂 GC 的人一眼就会问几个问题:
这个缓存有没有上限?对象生命周期多长?商品详情对象里有没有大字段?高峰期会不会批量创建大对象?缓存淘汰是按时间、数量,还是权重?出了 Full GC ,能不能从 GC 日志里看出是老年代增长、晋升失败,还是元空间问题?
然后他大概率会把代码改成这样:
public classGCFriendlyCache{private Cache<String, ProductDetail> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(10, TimeUnit.MINUTES).build();}
Caffeine 官方文档里讲得很直接:缓存可以按大小、权重、时间和引用来淘汰。这里真正值钱的不是“用了 Caffeine”这个动作,而是你终于承认了一件事:
内存不是免费的,缓存也不是许愿池。
你不需要每天调 GC ,但你要能在凌晨接管
学 GC 不是为了每天盯着 JVM 参数看。
说实话,大多数业务系统平时也不需要你手动折腾 GC 。你把服务写得正常一点,内存别乱涨,默认 G1 跑得挺好。 JDK 从 9 开始默认使用 G1 ,后面的 ZGC 、 Shenandoah 又把低延迟场景往前推了一大截。
但这不代表你可以完全不懂。
电商系统有个很残酷的特点:平时没事,不代表大促没事。
平时商品浏览是细水长流,大促当天就是洪峰。平时库存扣减是几百 QPS ,大促开场可能瞬间冲上去。平时你觉得“对象创建多一点也无所谓”,到了高峰期,它会变成一车一车往临时仓库里倒包裹。
仓库管理员开始疯狂盘点。
业务线程开始等。
你看监控,发现 CPU 没满,数据库也没满,网络也没满,但接口就是慢。这个时候 AI 能干什么?
它可以帮你解释 GC 日志字段。
可以。
但它不知道那次促销规则是不是让每个订单都生成了十几份优惠计算中间对象;不知道商品推荐是不是把原本应该分页加载的数据一次性拉进了内存;不知道某个静态集合是不是从上线那天开始就没清过。
这些要靠人。
靠一个知道“对象从哪里来,到哪里去,为什么留下来”的人。
这里有个很朴素的判断标准:如果你看到生产环境 Full GC 频繁发生,只会说“加内存试试”,那你其实还没接管系统。
你只是在给仓库加面积。
有时候加面积有用,有时候只是让垃圾堆得更久,下一次盘点更疼。
为什么必须学?五个理由就够了
第一个理由: AI 写的代码需要人来 Review 。
以前 Review 主要看业务逻辑,现在还要看“这段代码对 JVM 友不友好”。有没有无上限集合?有没有把大对象塞进长期引用?有没有在循环里制造临时对象风暴?有没有把本来该局部存在的东西挂到静态字段上?
这些都不是语法问题。
IDE 不会红。
第二个理由:性能问题不能靠模板答案排查。
Full GC 、 P99 抖动、吞吐下降,这些问题很少是单点原因。你要把 GC 日志、堆转储、对象引用链、业务时间线拼在一起看。像查仓库账一样,哪批货什么时候进来的,为什么没出库,谁还在引用它。
AI 可以帮忙整理,但方向要你定。
第三个理由:架构决策要懂底层。
选 G1 还是 ZGC ?堆要开多大?年轻代比例要不要动?对象分配速率高的时候,是调参数,还是改代码?如果你完全不懂 GC ,只能在网上抄参数。
抄参数这事儿,挺玄学的。
别人的电商仓库卖手机壳,你的仓库卖冰箱,货架规则能一样吗?
第四个理由:面试不会消失。
别自欺欺人了。大厂 JD 里“熟悉 JVM 调优”不是摆设, GC 也不是考官无聊才问。 AI 越普及,能写 CRUD 的人会变多,能解释线上系统为什么抖的人反而更稀缺。
面试问 GC ,本质不是问你背没背过“标记-清除、标记-复制、标记-整理”。
它是在问:系统变慢时,你有没有能力往下挖一层。
第五个理由:越往上走,越绕不开。
初级工程师可以只关心功能做没做完。高级工程师要关心系统稳不稳。架构师和技术专家还要关心一个更麻烦的问题:这个系统在业务放大 10 倍之后,会不会以一种很难看的方式死掉。
内存问题就是这种东西。
平时安静,发作很丑。
这个系列怎么讲:不背八股,拿电商系统跑一遍
接下来这个系列,我不想把 GC 写成一串术语。
什么 Eden 、 Survivor 、老年代、 Minor GC 、 Major GC 、 Full GC 、 G1 、 ZGC ,如果只按定义讲,读者很快就困了。更麻烦的是,定义背完了,线上照样不会看。
所以我们换个方式。
整套文章只盯着一个主线:电商系统。
商品浏览、购物车、下单、支付、库存扣减、优惠券、限时促销,这些场景都会不断创建对象,也会不断暴露内存管理问题。
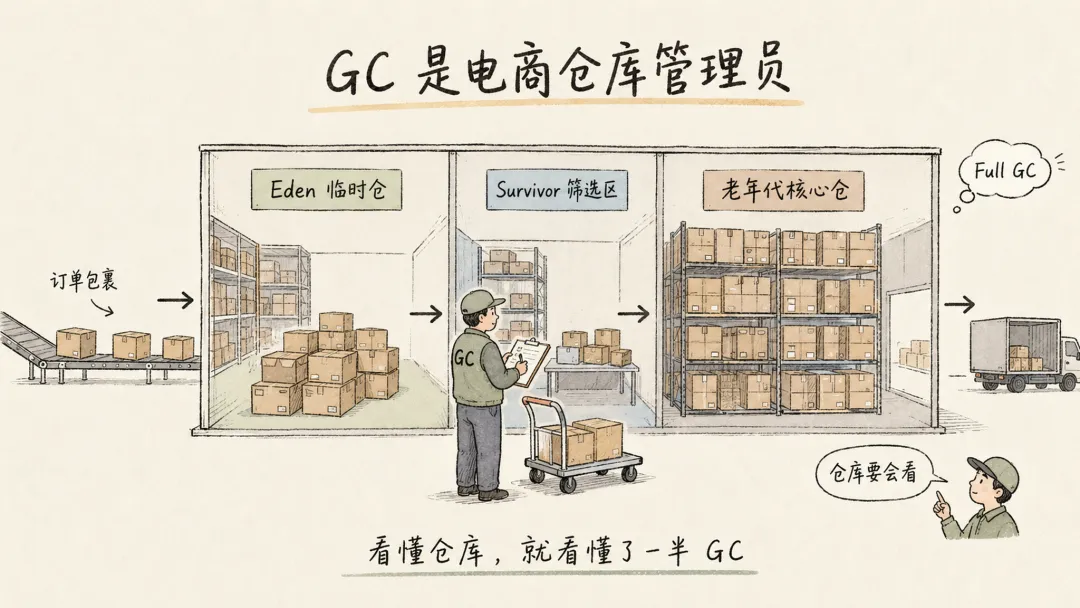
Eden 区是什么?
就是大促临时仓,短命对象疯狂进来,过一会儿大部分都该清走。
Survivor 区是什么?
就是筛选区。经历一轮盘点还活着的对象,先别急着送去核心仓,再观察一下。
老年代是什么?
就是核心库存区。用户会话、热数据、长期引用对象待在这里。一旦这里开始拥挤,系统就紧张了。
Full GC 是什么?
全仓库大盘点。盘点时很多业务线程要停下来,仓库管理员说“别发货了,我先看看哪些东西还能要”。
听起来好笑,但你顺着这个类比走一遍,会发现 GC 的很多设计都不是玄学。它关心的无非是三件事:
谁是垃圾?
怎么清理?
清理时能不能少影响发货?
这三个问题,后面每一篇都会反复出现。
我们会从最基础的“为什么需要 GC”讲起,再讲引用计数和可达性分析,讲三种基础回收算法,讲分代模型,讲 Serial 、 Parallel 、 CMS 、 G1 、 ZGC 。每篇都配电商场景,每篇都给一段能跑的 Java 示例。
不是为了炫技。
是为了让你看到代码背后那间仓库。
学 GC ,不是怀旧,是给 AI 兜底
我不反对用 AI 写代码。
相反,我觉得不用才有点亏。能让机器生成模板、补单元测试、解释日志、整理排查思路,这些都该用。工程师没必要把时间浪费在重复劳动上。
但别把 AI 当成系统责任人。
它像自动驾驶。路况正常时,它很舒服;导航清楚时,它很省心;可一旦前面突然施工、暴雨、路面塌了一块,方向盘还是要有人接。
JDK 垃圾回收就是这样的方向盘之一。
你不需要每天摸它。
但你得知道它在哪。
下一篇,我们从最朴素的问题开始:
Java 为什么需要 GC ?
一个电商系统每天创建几百万个订单对象、商品快照对象、购物车对象。用完之后,如果没人清,会发生什么?
仓库管理员要上班了。
