 夜雨聆风
夜雨聆风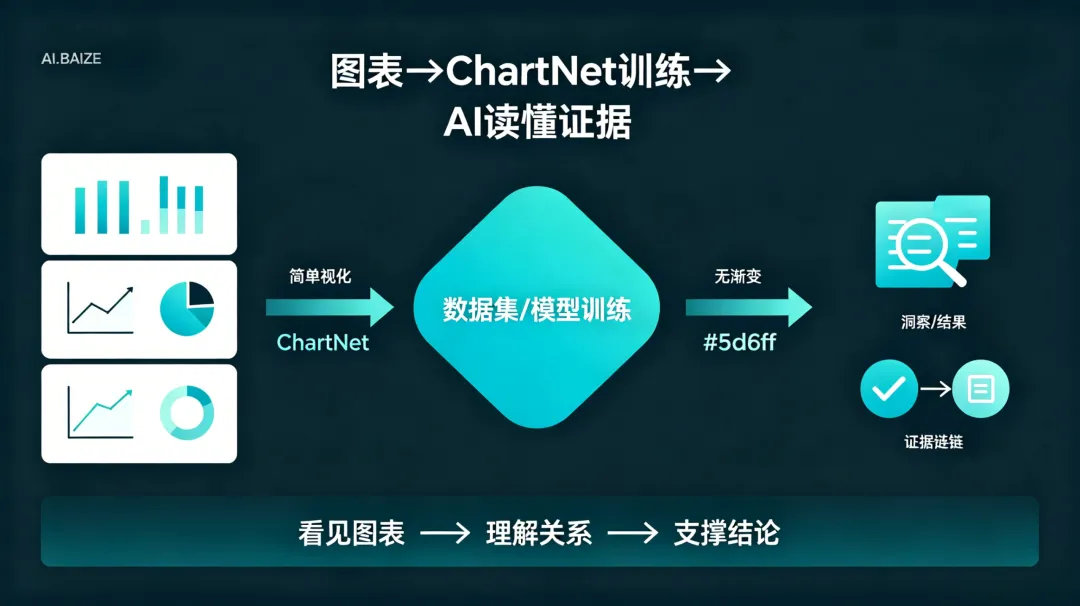
6月3日,MIT和IBM相关研究团队发布了ChartNet数据集,用来提升AI对图表的理解能力。
这件事听起来不像模型发布那么热闹,但它击中了一个很实际的问题:AI会写文章、会总结文档,却经常看不懂图表。
英文圈已经有MIT、TechTimes、Digital Watch等报道,中文圈目前几乎没有独立文章。
发生了什么
ChartNet不是一个新大模型,而是一个面向图表理解的数据集和训练资源。
它要解决的问题很具体:让AI更准确地读懂柱状图、折线图、饼图、科学图表、商业仪表盘这类视觉化数据。
这类任务比普通图片识别更难。因为AI不只是要看见图里有什么,还要理解坐标轴、单位、趋势、比例、图例、数值关系。
比如一张销售趋势图,普通视觉模型可能能看出“这里有几根柱子”。但真正有用的是:哪个季度增长最快?哪个产品线下滑?图表里是否存在异常值?这些才是业务判断需要的信息。
ChartNet的意义就在这里:它不是教AI“看图”,而是教AI从图表里读出证据链。
报道中提到,经ChartNet训练或微调后,一些小型开源模型在特定图表理解任务上的表现可以超过更大的通用模型基线。这个说法要加限定——不是全面反超GPT-4o,而是在图表理解这个专门任务上出现了明显提升。
英文圈在聊什么
英文圈的讨论集中在一个问题:为什么小模型也能在特定任务上超过大模型?
答案其实不神秘。大模型很强,但它不是每个细分任务都天然最优。图表理解需要非常专门的数据训练,需要模型学会图表语法,而不是单纯扩大参数。
这点很关键。过去一年,大家讨论AI能力时,常常默认“模型越大越强”。但ChartNet这个案例提醒我们:在企业应用里,数据集质量和任务适配,可能比模型大小更重要。
英文圈还在讨论另一个方向:图表理解是企业AI落地的关键入口。
企业内部大量信息不是自然语言,而是图表、报表、仪表盘、PPT、财务曲线、科研图像。AI如果读不懂这些东西,就很难真正进入决策场景。
说白了,AI不能只会读文字,还要会读证据。
中文圈漏了什么
中文圈对多模态AI的讨论,多数还停在“看图说话”“图片识别”“生成图片”这些层面。
但企业真正需要的不是让AI描述一张图,而是让AI解释图表背后的数据关系。这个差别很大。
比如做市场分析,不是问AI“这是什么图”,而是问它“这张图说明哪个渠道转化率下降了”。做科研阅读,不是问AI“图里有什么”,而是问它“这组实验结果是否支持作者结论”。
ChartNet这个选题的价值就在于,它把AI视觉能力从“看见”推进到“读懂”。中文圈目前还没有围绕这个角度做系统分析。
我的看法
这个选题跟数字出版和内容生产关系很近。
我做教学时,经常发现学生写报告会堆很多图,但图和文字之间是断的。图放在那里,正文只是简单说“如图所示”,没有解释趋势、没有提炼证据,也没有把图表和结论连起来。
AI现在也有类似问题。它能生成一段看起来很流畅的总结,但如果它不真正理解图表,结论就可能是空的。
未来的数字出版、数据新闻、科研论文阅读,都会越来越依赖“图表证据链”。谁能把图表里的信息读出来、讲清楚、和正文结论对应起来,谁就能做更可靠的内容分析。
对AIGC内容生产来说,这也是一个提醒。我们不能只追求“生成得像不像”,还要追求“证据是否能支撑”。如果AI能读懂图表,它就能帮我们检查数据报告、分析传播效果、理解用户画像,而不是只会改标题和写文案。
我更愿意把ChartNet看成一个信号:AI落地企业场景,不一定靠更大的模型,而是靠更好的任务数据。
大模型解决通用能力,专业数据集解决具体工作。真正能进入工作流的AI,往往是两者结合。
你怎么看小模型在专业任务上超过大模型这件事?留言聊聊。
信息来源:MIT News, TechTimes, Digital Watch, 6月3-4日报道
