 夜雨聆风
夜雨聆风用一家智能餐厅把 AI Agent 拆开讲清楚:大脑、工具、记忆、规划全打开
写在前面
如果把一个 AI Agent 比作一家智能餐厅,它是怎么把你的需求变成菜品端上来的呢?这离不开它的四大核心组件:大脑、工具、记忆、规划。
• 大脑:负责听懂点单、判定目标、决定顺序,是餐厅的指挥中心。 • 工具:负责实际动手,包括切配、烹饪、采购等动作,把决策转成可执行操作。 • 记忆:负责记录顾客偏好、当前步骤、已处理内容,保证流程不混乱、不重复。 • 规划:负责把整道菜拆成步骤,确定先后关系,确保任务按流程推进到完成。
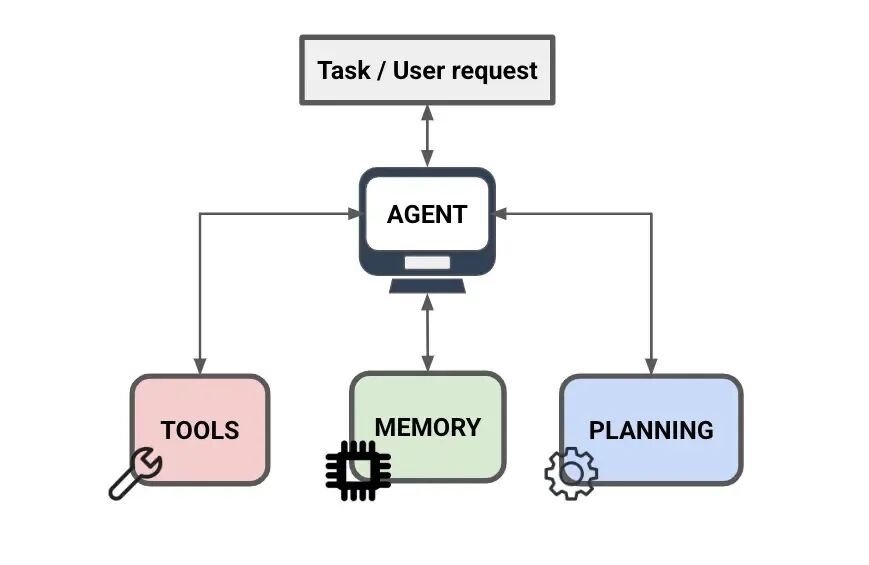
整体架构
下图展示了 AI Agent 五大层次组件及其协作关系。感知层接收外部输入,大脑负责理解与决策,规划层将任务分解,工具层负责执行,记忆层则贯穿始终,为所有环节提供状态支撑。
0、感知层(Perception)—— 餐厅的前台
角色:负责接待顾客,理解来自外部世界的所有输入。
Agent 在行动之前,必须先"看到"和"听到"外部信息。现代 Agent 已经不限于纯文本输入,而是具备多模态感知能力:
• 文本输入:用户的自然语言指令、文档内容、代码。 • 图像 / 视频:截图、设计稿、图表,Agent 可以直接"看图"理解。 • 结构化数据:表格、JSON、数据库查询结果。 • 环境状态:在计算机操作类 Agent 中,当前屏幕状态、网页 DOM 结构等。 • 工具返回结果:上一步工具调用的输出,会作为新的感知输入进入下一轮循环。
感知层的输入经过整合,形成 Agent 的"当前上下文",送入大脑进行理解和决策。
1、大脑(Brain)—— 也就是大模型
角色:餐厅的主厨兼经理。
这是 Agent 最核心的部分(比如 GPT-4、Claude、DeepSeek、通义千问)。
• 它负责听懂你想吃什么(理解意图)。 • 它负责指挥其他人干活(决策)。 • 如果没有它,整个餐厅就瘫痪了。
大脑做的三件核心事
| 意图理解 | ||
| 推理决策 | ||
| 工具调用判断 |
💡 关键概念:大脑的"智力天花板"决定了整个 Agent 的上限。同一套工具和规划框架,接入能力更强的基础模型,任务完成质量往往有质的飞跃。
关于"换更强的脑子":所以同样是用 Claude Code 或 Codex 跑一个 Agent,接 Claude Opus 4.8、GPT-5.5 这种旗舰模型和接小模型的体感是完全不一样的。如果想直接把"脑子"换成顶配,但又卡在海外信用卡和网络环境上,可以看看 Code80——真实订阅账号转 API,换个 endpoint 就能用上 Opus 4.8、Codex 这些旗舰模型,体验跟官方一致。详情可以到官网了解:code.ai80.vip。
2、工具(Tools)—— 厨房里的设备
角色:厨具和帮手。
光有主厨(大脑)是不够的,还得有锅碗瓢盆才能做菜。对于 AI Agent 来说,工具就是能把决策转化为真实动作的执行单元。
工具可以按照用途分为四大类:
| 信息获取 | ||
| 计算执行 | ||
| 内容生成 | ||
| 系统交互 |
常见工具举例:
• 🛒 联网搜索 —— 信息获取(像去菜市场买新鲜食材) • 🧮 代码解释器 —— 计算执行(像精密的烤箱,处理复杂计算) • 🎨 画图工具 —— 内容生成(像摆盘师,负责美观) • 🔌 API 接口 —— 系统交互(像外卖小哥,连接外部世界)
💡 函数调用(Function Calling):现代大模型通过"函数调用"机制来使用工具。开发者预先定义工具的名称与参数说明,模型在推理时会以结构化 JSON 的形式输出"我要调用哪个工具、传什么参数",由外部程序负责真正执行并把结果返回给模型。
3、记忆(Memory)—— 顾客记录本
角色:服务员的记性。
你肯定不喜欢每次去餐厅都要重新报一遍:我不吃香菜!
Agent 的记忆分为以下几种类型:
• 短期记忆(In-Context Memory):即当前对话的上下文窗口。记住刚才你说了啥(比如你刚点了鱼,下一句说"要微辣",它知道是指鱼)。受限于模型的上下文长度,通常在 8K 到 200K token 之间。 • 长期记忆(External Memory):记住你的长期偏好(比如你是素食主义者,或者你的家庭住址)。通常通过向量数据库(如 Pinecone、Milvus、Chroma)实现持久化存储。 • 情节记忆(Episodic Memory):对历史任务执行过程的记录,包括"上次遇到这种情况我是怎么处理的",帮助 Agent 从过去的经验中学习。 • 语义记忆(Semantic Memory):抽象的知识和事实,通常来自预训练阶段已经内化的内容,也可通过 RAG(检索增强生成)动态补充。
RAG:让 Agent 拥有"外挂知识库"
检索增强生成(Retrieval-Augmented Generation,RAG) 是目前最主流的长期记忆实现方案。其核心流程如下:
用户提问 (Query) ↓向量化检索 (Embedding + Search) ↓召回相关内容 (Top-K Chunks) ↓注入上下文生成 (LLM + Context) ↓回答 (Answer)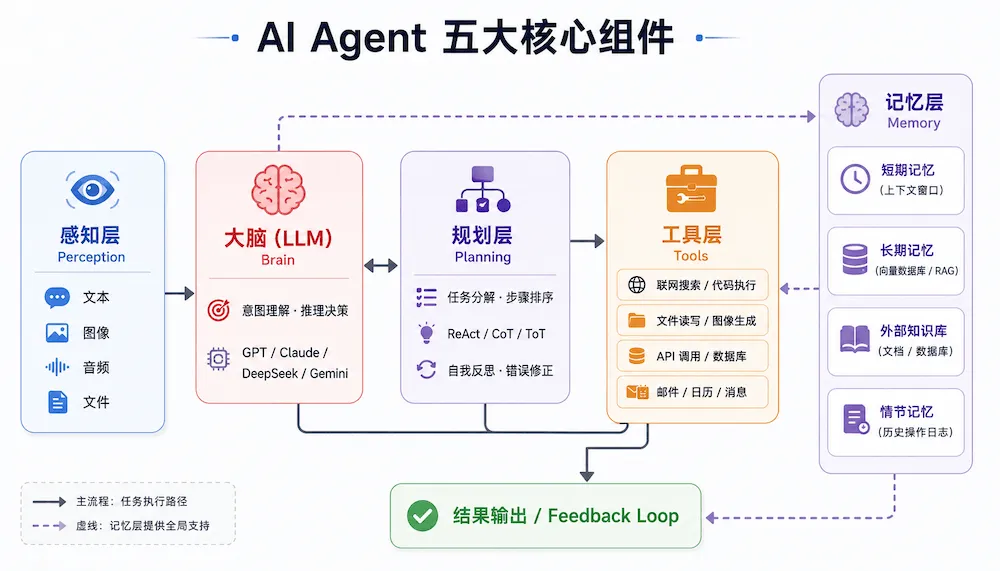
4、规划(Planning)—— 烹饪流程单
角色:后厨的出餐 SOP。
当你点了一份佛跳墙,主厨不会乱做,而是会在脑子里生成一个清单:
1. 先备料(鲍鱼、海参…) 2. 再熬汤 3. 最后慢炖
Agent 也是一样。当你给它一个复杂任务(比如"写一份竞品分析报告"),它会自己拆解:
• 第一步:去搜集竞品 A、B、C 的资料。 • 第二步:对比它们的价格和功能。 • 第三步:把对比结果写成文章。 • 第四步:检查一遍有没有错别字。
主流规划策略
规划策略决定了 Agent 如何"思考"再"行动",不同策略的推理深度与适用场景不同:
| CoT | |||
| ReAct | |||
| ToT | |||
| Reflection |
💡 ReAct 示例:Agent 接到任务"查明天北京天气并发送提醒" → 思考:需要先查天气 → 行动:调用天气 API → 观察:返回"明天有雨" → 思考:条件成立,需要写提醒 → 行动:调用发送消息工具 → 任务完成。
5、Agent 运行循环(Agent Loop)
以上各组件并非孤立存在,它们组成一个持续迭代的感知—思考—行动—观察闭环,这就是"Agent Loop"。Agent 不断重复这个循环,直到任务完成或达到终止条件。
感知 (接收输入 / 环境状态) ↓思考 (LLM 推理 / 规划分解) ↓行动 (调用工具 / 执行操作) ↓观察 (获取结果 / 更新记忆) ↓任务完成 / 达到终止条件 ────────→ 结束 ↓继续循环(任务未完成)↺这个循环让 Agent 具备了在失败时自我纠错的能力:如果某一步工具调用返回了错误或意外结果,"观察"阶段会将这个信息反馈给大脑,大脑在下一轮"思考"时就会调整策略。
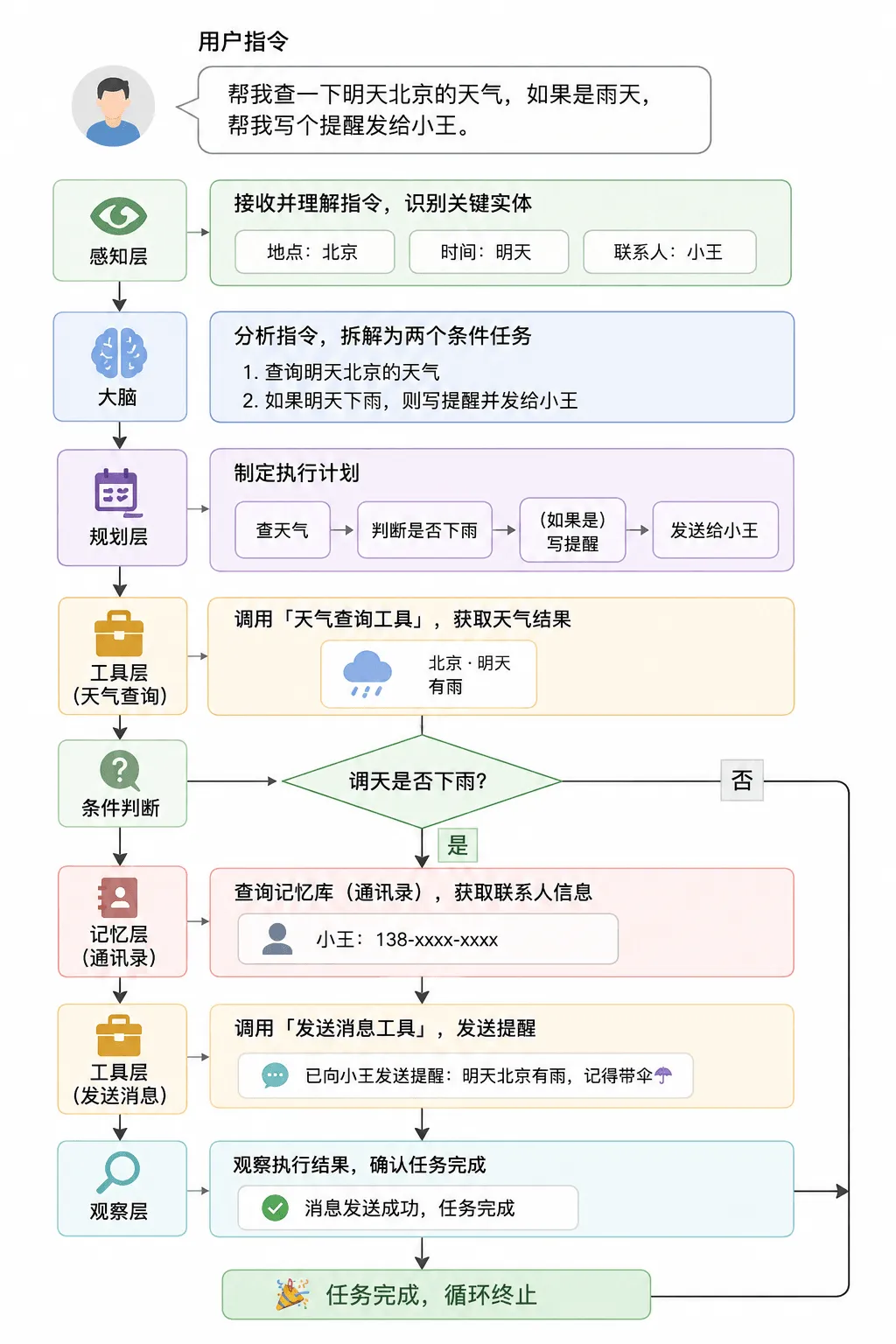
总结:一个完整例子
当你对 Agent 说:
"帮我查一下明天北京的天气,如果是雨天,帮我写个提醒发给小王。"
Agent 内部是这样运转的:
1. 感知层:接收到自然语言指令,识别出关键实体"北京"、"明天"、"小王"。 2. 大脑:听到指令,分析出两个条件任务:查天气,若下雨则发提醒。 3. 规划:先查天气 → 判断是否下雨 → (如果是) 写提醒 → 发送。 4. 工具:调用"天气查询工具",获取到结果——明天有雨。 5. 记忆:去通讯录(记忆库)里查询"小王"的联系方式。 6. 工具:调用"发送消息工具",把提醒发出去。 7. 观察:确认消息发送成功,任务完成,循环终止。
运行过程示意图:
五大组件一览
| 感知层 | |||
| 大脑 | |||
| 规划 | |||
| 工具 | |||
| 记忆 |
常见问题(FAQ)
Q1:Agent 和普通的 ChatGPT 对话有什么本质区别?
A:普通对话只有"大脑"——你问它答,做不了实际的事。Agent 是大脑+工具+记忆+规划组合起来的完整系统:它会主动规划步骤、调用真实工具(搜索、API、文件操作)、记忆中间状态、根据结果反复纠错,直到任务真的完成。一句话:Agent 是会动手干活的 AI,而不是只会说话的 AI。
Q2:为什么有时候 Agent 看起来很笨?
A:90% 的情况是"脑子"没选对。大脑的智力天花板决定了整个 Agent 的上限——同一套规划框架和工具,接 GPT-3.5 和接 Claude Opus 4.8 的体感差距是巨大的。剩下 10% 是工具配置(少了关键工具)或记忆策略(上下文管理混乱)的问题。
Q3:CoT、ReAct、ToT、Reflection 到底怎么选?
A:简单推理用 CoT(数学题、逻辑题);需要调工具的动态任务用 ReAct(搜索 + 决策 + 再搜索);多路径权衡用 ToT(创意、复杂决策);长文 / 代码生成用 Reflection(让它自己审稿改稿)。实际工作里 ReAct 用得最多,因为大部分活儿都需要"边想边查边干"。
Q4:什么是 Function Calling?为什么它对 Agent 这么重要?
A:Function Calling 是大模型调用工具的标准协议——开发者预先定义工具的名称和参数,模型推理时输出一个结构化 JSON,告诉外部程序"我要调哪个工具、传什么参数"。没有这个机制,Agent 就只是聊天机器人;有了它,Agent 才能让外部程序真的去执行操作。
Q5:RAG 和长期记忆是一回事吗?
A:RAG 是实现长期记忆最主流的方案,但不是全部。RAG 用向量数据库(Pinecone、Milvus、Chroma)把外部文档检索出来注入上下文,让模型"看见"它训练时没有的内容。长期记忆还包括情节记忆(历史任务过程)和语义记忆(抽象知识),通常需要多种存储和检索策略组合。
Q6:Agent Loop 卡死了怎么办?
A:Agent Loop 设计了"任务完成 / 达到终止条件"两个退出口。卡死通常是因为:① 缺失终止条件(要么强制设最大轮数,要么让模型显式判断"完成");② 工具失败但没把错误传给观察阶段;③ 上下文压缩丢了关键约束。解决思路一般是:加显式终止判断、把工具错误结构化返回、关键约束保留在 system prompt 而不是上下文里。
