 夜雨聆风
夜雨聆风源码级拆解存储结构、压缩机制与树分支逻辑
什么是 Pi?
如果你关注 Coding Agent,可能听说过 Pi Coding Agent——GitHub 上一个极简的终端原生 AI 编码工具,目前 58.4k stars,MIT 协议开源。
图 1 | Pi Coding Agent 产品概览
简单说,Pi 是什么?
Pi 是一个开源的 AI 编码 Agent 工具,它的核心能力:你用自然语言告诉它想做什么,它调用 LLM 读写文件、执行命令,帮你完成编码任务。
但和我们熟悉的 Cursor、Windsurf 等产品不同,Pi 刻意走了一条"极简内核"路线。它不内置任何高级功能——没有 MCP 集成、没有子代理、没有权限弹窗、没有计划模式。这些功能全部通过扩展生态让用户自行组装。
Pi 的核心设计哲学——"刻意不做"
Pi 的作者 Mario Zechner 在博客中花了大量篇幅解释为什么不做这些功能。每一个"不做"背后都有一个清晰的论证:不是"做不到",而是"做了会让产品更差"。比如不做计划模式,是因为模型在执行中需要根据反馈动态调整,静态计划反而成为约束。
本质上,Pi 是一个"AI 编码 Agent 的 Linux"——极简内核,一切靠包管理和扩展生态。它的核心竞争力不在功能丰富度,而在架构的克制和扩展机制的表达力。
本文焦点
为什么要研究它的记忆管理?
Agent 产品设计中,记忆管理是最容易被忽视、但又最影响体验的关键环节。它决定了:当对话越来越长时,Agent 会不会"忘了"你之前的指令?当你回退到某个中间节点重新开始时,之前的信息怎么处理?上下文窗口快满时,系统怎么做取舍?
本文深入 Pi 的源码(v0.78.0),系统拆解它的记忆管理策略——包括记忆如何存储、上下文如何构建、压缩如何触发、树分支如何运作,并提炼出设计思考。
本文范围:聚焦 Pi 的记忆层(存储、压缩、分支),不涉及规划层、执行层、扩展体系等其他部分。
文章目录
- 一、记忆架构总览
— 一个文件,两种用途 - 二、记忆如何存储
— JSONL 格式、11 种条目、消息粒度 - 三、上下文如何构建
— 从叶子到根的遍历算法 - 四、两种摘要机制
— CompactionEntry 与 BranchSummaryEntry 对比,触发条件、摘要生成、增量更新 - 五、树分支机制详解
— leaf 指针、BranchSummary、孤儿节点 - 六、设计思考与同类对比
— Pi vs Claude Code 记忆策略对比
一、记忆架构总览:一个文件,两种用途
Pi 的记忆系统用一个 JSONL 文件承载所有信息,但这个文件被两种不同的方式使用:
图 2 | 存储层包含所有信息(完整记录),上下文层是每次动态生成的子集(发给 LLM)
核心原则
存储层(JSONL 文件)只追加不修改不删除——即使压缩了旧消息,原始文本仍然在文件里。
上下文层是每次和 LLM 交互时,从当前叶子节点沿 parentId 链回溯到根,动态构建的消息数组。
二、记忆如何存储
2.1 JSONL 格式:每行一个独立条目
Pi 把会话存储在一个 JSONL 文件中(每行一个 JSON 对象)。每个条目有唯一的 8 位十六进制 ID 和 parentId,形成一棵树:
{ "type": "session", "id": "s1", "version": 3, "cwd": "~/myapp" }{ "type": "message", "id": "a1", "parentId": null, "message": { "role": "user", "content": "帮我改 auth 模块" } }{ "type": "message", "id": "b2", "parentId": "a1", "message": { "role": "assistant", "content": [] } }{ "type": "message", "id": "c3", "parentId": "b2", "message": { "role": "toolResult", "content": "文件内容..." } }{ "type": "message", "id": "d4", "parentId": "c3", "message": { "role": "assistant", "content": [] } }{ "type": "message", "id": "e5", "parentId": "d4", "message": { "role": "user", "content": "不对,应该改另一个文件" } }
2.2 11 种条目类型
| message | ||
| message | ||
| message | ||
| message | ||
| custom_message | ||
| compaction | ||
| branch_summary | ||
| model_change | ||
| leaf | ||
| label | ||
| custom |
2.3 消息存储粒度:一条消息 = 一个独立 JSONL 行
这是最容易混淆的地方。一个完整的「用户输入 → 模型思考 → 调用工具 → 获取结果」交互,在 JSONL 中是多条独立行:
图 3 | 消息存储粒度:thinking + text + toolCall 打包在同一条 assistant 消息内,但 toolResult 是独立的一条
关键规则
assistant 的 thinking + text + toolCall 全部打包在同一条消息的 content 数组里,共享一个 ID - toolResult
每条独立存储,不与 assistant 打包,有自己独立的 ID,parentId 指向对应的 assistant - bashExecution
独立于 toolResult,有自己的记录 一轮 LLM 输出 = 一条 assistant 消息,不管这一轮里调用了多少个工具 如果 assistant 同时调用多个工具(如同时读 3 个文件),多个 toolCall 在同一条 assistant 消息中,但每个工具的 result 各是一条独立的 toolResult
三、上下文如何构建
每次和 LLM 交互前,Pi 通过 buildSessionContext() 函数从当前叶子节点沿 parentId 链回溯到根,动态构建发给 LLM 的消息数组。
图 4 | buildSessionContext() 从叶子(A-7)沿 parentId 回溯,遇到 compaction 跳到 firstKeptEntryId
/*** 从叶子节点 ID 向上回溯构建会话上下文* @param {string} leafId - 叶子消息 ID* @returns {Array} 按时间正序排列的上下文消息*/function buildSessionContext(leafId) {let currentId = leafId;const result = [];// 向上回溯父节点直到 nullwhile (currentId !== null) {const entry = entriesById.get(currentId);// 未找到条目直接退出if (!entry) break;if (entry.type === "message") {// 普通消息:直接加入result.push(entry);} else if (entry.type === "compaction") {// 压缩消息:转为摘要,并跳转到压缩链首节点result.push(transformToSummary(entry));currentId = entry.firstKeptEntryId;continue;} else if (entry.type === "branch_summary") {// 分支摘要:转为分支摘要消息result.push(transformToBranchSummary(entry));} else {// 其他类型(leaf、model_change 等):跳过}// 继续向上找父节点currentId = entry.parentId;}// 反转:从最早 → 最新return result.reverse();}
关键:遇到 compaction 条目时,不是跳过它继续向上回溯,而是直接跳到 firstKeptEntryId。这意味着被压缩的消息(A-0~A-2)虽然仍在 JSONL 文件中,但不会出现在发给 LLM 的上下文里。
四、两种摘要机制
Pi 的记忆系统中存在两种完全不同的摘要,解决两个不同的问题:

简单来说:CompactionEntry 是"因为装不下所以要压缩",BranchSummaryEntry 是"因为换路线所以要传承"。前者由上下文窗口驱动,后者由用户分支切换行为驱动。
下面分别拆解两种机制的完整实现。
4.1 CompactionEntry:上下文压缩
触发条件
压缩不是等到 100% 满才触发,而是提前预留缓冲区:

4.2 摘要生成:用什么、怎么生成
压缩摘要调用当前配置的同一个 LLM生成(不是单独的小模型),使用专门的提示词。摘要输出长度限制为 reserveTokens 的 80%(约 13k tokens),防止摘要本身膨胀。
首次压缩的提示词要求输出7 个固定板块:
## Goal(用户想达成什么)## Constraints & Preferences(约束与偏好,或 "(none)")## Progress### Done(已完成的任务)### In Progress(当前工作)### Blocked(受阻问题,如有)## Key Decisions(关键决策及理由)## Next Steps(有序的下一步列表)## Critical Context(关键数据、示例、引用)## Files(readFiles + modifiedFiles 列表)
注意最后两个板块:Next Steps 和 Files 列表是最关键的字段。它们让压缩后的 Agent 有明确的行动方向和上下文信息,而不是需要重新从头分析。这被称为"行动导向摘要"。
4.3 增量更新:后续压缩怎么做
第二次及以后的压缩,不会从头重新摘要所有消息,而是用增量更新模式:
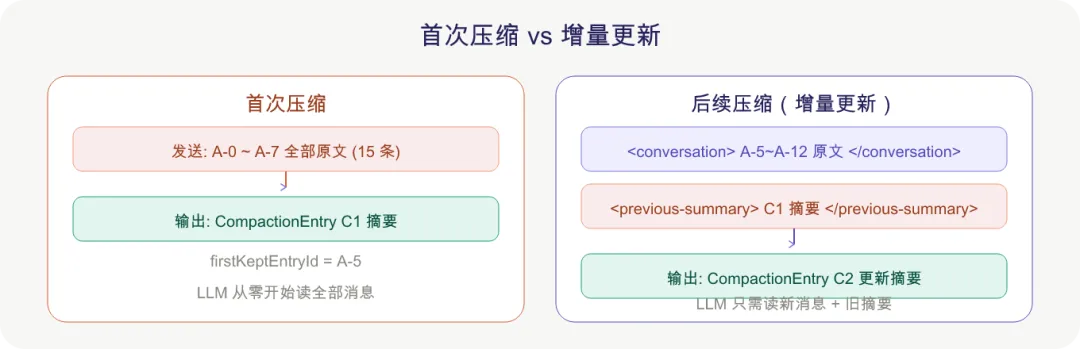
图 6 | 首次压缩从头摘要全部消息,后续压缩只读新消息 + 旧摘要做增量融合
4.4 压缩前后 JSONL 的变化
压缩不会修改 JSONL 文件中的任何已有内容,只是在末尾追加一条 compaction 条目:
{ "type": "session", "id": "s1", "version": 3, "cwd": "~/myapp" }{ "type": "message", "id": "a1", "parentId": null, "message": { "role": "user", "content": "帮我改 auth 模块" } }{ "type": "message", "id": "b2", "parentId": "a1", "message": { "role": "assistant", "content": [] } }{ "type": "message", "id": "c3", "parentId": "b2", "message": { "role": "toolResult", "content": "文件内容..." } }{ "type": "message", "id": "d4", "parentId": "c3", "message": { "role": "assistant", "content": [] } }{ "type": "message", "id": "e5", "parentId": "d4", "message": { "role": "user", "content": "不对,应该改另一个文件" } }// ... 中间更多 message 行(id: f6 ~ t19)全部保持不变{ "type": "message", "id": "t19", "parentId": "s18", "message": { "role": "assistant", "content": [] } }
原始消息永远不会被删除或修改。压缩只是在 JSONL 末尾追加一条记录,告诉系统从哪条消息开始用摘要替代原文发给 LLM。
五、树分支机制详解
Pi 的整个会话是一棵树,所有分支地位平等,没有"主/从"之分。leaf 指针指示当前活跃节点,它决定了 buildSessionContext() 的遍历起点。
5.1 /tree 命令:查看和切换分支
用户输入 /tree 后,终端显示会话树视图,每行显示节点类型和内容预览:
用户选择节点后:
选的是 user / custom_message → 文本填入编辑器,可修改后重新发送(相当于从该节点"重新开始") 选的是 其他类型 → leaf 指针直接跳到该节点,继续对话
5.2 BranchSummary:自动生成的探索经验
当用户切换到另一个分支时,被放弃的旧分支不会丢失——Pi 会自动生成一条 BranchSummary注入新分支的上下文,让 Agent 知道"之前尝试了什么路线、为什么放弃了"。
BranchSummary 注入 LLM 上下文时,会带有一个固定的提示词前缀:"The user explored a different conversation branch before returning here." 这告诉 LLM 当前信息来自一条被放弃的探索路线,而非当前工作路径。
图 7 | BranchSummary 让 Agent 在新分支知道之前尝试了什么,避免重复错误
5.3 复杂场景:压缩后从中间节点切换分支
这是最复杂的边界情况——假设 A 分支已经触发了一次压缩(C1),用户想从被压缩覆盖范围内的某个中间节点切换到新分支 B。
图 8 | C1 CompactionEntry 的 parentId 指向 A-7,切换到 A-3 后回溯路径走不到 C1 → 自然忽略,不需要特殊处理
核心处理逻辑
buildSessionContext() 只沿 parentId 链回溯。切换到 A-3 后,回溯路径是 A-3 → A-2 → A-1 → A-0,C1 的 parentId 指向 A-7,不在新路径上,自然被忽略。
5.4 BranchSummary 的特殊性质
BranchSummary 有一个重要特点:它不会被后续压缩覆盖。BranchSummary 永久留在上下文中,每次构建上下文时都会被转换为合成消息发给 LLM。
这意味着如果用户频繁切换分支,会产生多条 BranchSummary 累积占据上下文空间,不可压缩。Pi 对此的策略是信任用户自行控制切换频率。
六、设计思考与行业对比
6.1 三个核心设计洞察
图 9 | 压缩不可避免会有信息损失,树结构让损失可逆
图 10 | 压缩摘要不仅记录过去,更要指示未来——Next Steps 是最关键的字段
图 11 | BranchSummary 让探索过的路线虽然放弃,但获得的认知被保留
三个洞察总结
- 树结构的核心价值不是"分支",是"不删除"
——压缩不可避免会有信息损失,树结构让损失可逆。即使不做分支切换,保留完整历史本身就是巨大的安全网。 - 压缩摘要的关键不是"怎么压缩",是"怎么让 Agent 压缩后还能继续工作"
——行动导向摘要(Next Steps + Files)比总结型摘要有价值得多。 - BranchSummary 解决的不是"记忆"问题,是"探索不浪费"问题
——失败的路线不应该被完全丢弃,获得的认知应该传承到新分支。
6.2 同类对比:Pi vs Claude Code
比较有可比性的同类产品是 Claude Code——同为终端编码 Agent场景下长会话的上下文管理问题。但两者走了完全不同的技术路线:

图 12 | 同为终端编码 Agent,Pi 选了"树形 + 单层压缩",Claude Code 选了"线性 + 5 层渐进"
两种路线的取舍
- Pi 的赌注
:树结构 + 单层压缩 = 简单可预测。缺点是压缩成本高(每次都调 LLM),优点是实现简单、分支探索零损失 - Claude Code 的赌注
:5 层渐进 = 成本最优。缺点是管线复杂、无分支回溯,优点是 80% 的压缩不需要调 LLM - 关键差异
:Claude Code 用 Session Memory 后台异步预提取来"提前准备摘要",压缩时直接替换,零 LLM 成本。Pi 没有这个机制——每次压缩都是实时调用 LLM
写在最后
Agent 的记忆管理不是一个"存储"问题,是一个"注意力分配"问题。Agent 的上下文窗口就是它的"注意力"——每次和 LLM 交互时,你必须决定在有限的注意力空间里放什么信息。
Pi 的答案是:完整的原始记录(永不丢失)+ 动态裁剪(每次只放需要的)+ 行动导向摘要(压缩后仍可工作)+ 树分支(信息损失可逆)。
这个答案不是唯一的。Pi 刻意不做跨会话记忆、不做 RAG、不做渐进式压缩,因为它的场景是单次编码会话,对话通常几百条消息,线性遍历够用。对于跨会话的需求,Pi 依赖 AGENTS.md——一个放在项目根目录的 Markdown 文件,手动记录项目级上下文(技术栈、约定、架构说明等)。每次新建会话时 Pi 自动读取,用"项目级静态配置"替代了"跨会话动态记忆"。
Pi 给我们的最大启发是:好的记忆设计不是选择最复杂的方案,而是在对的场景选择最合适的方案。它的"不删除"原则和"行动导向"摘要格式,是几乎任何 Agent 记忆系统都可以直接迁移的设计模式。
