 夜雨聆风
夜雨聆风我用国产的 DeepSeek,把 LangChain 官方那份《构建你的第一个 Agent》教程从头到尾跑了一遍。
这篇就是那条真正跑通的路径——8 个台阶,一步一个痛点,每个坑我都替你踩过了。
如果你想入门 AI Agent 开发,大概率遇到过这种尴尬:
·网上的教程要么是「三行代码造个 Agent」,跑是跑通了,但你完全不知道里面发生了什么;
·要么直接甩一堆 LangGraph 的 State、Node、Edge 概念,劝退。
我的体感是:Agent 不该一上来就学框架,而该顺着「痛点」一层层往上爬——每一步都是因为上一步太难受,才需要下一步。
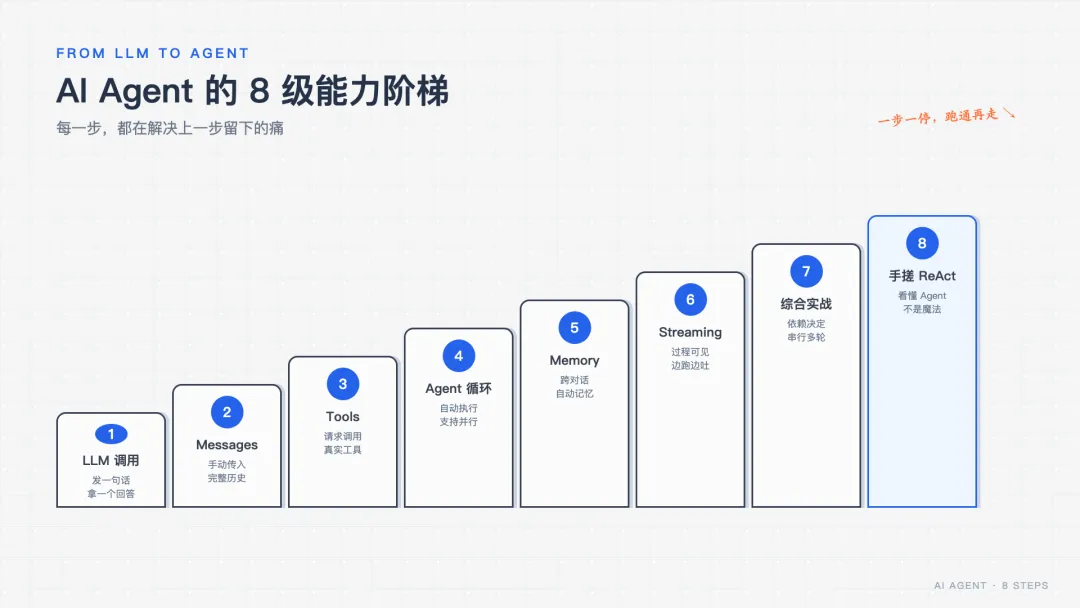
所以这篇我按 8 个台阶来讲,每个台阶就回答一个问题:我现在卡在哪,下一步怎么解? 代码只贴最关键的几行,重点是讲清楚逻辑,以及那些教程不会告诉你的坑。
用的模型是 DeepSeek——后面你会看到,国产模型不光能跑通整套教程,还逼我发现了一个官方教程压根没提的坑。
第 1 步:先发一句话,拿一个回答
最基础的一步:让程序跟大模型说句话。
from langchain.chat_models import init_chat_model model = init_chat_model("deepseek:deepseek-v4-flash") response = model.invoke("What is LangChain?")
就两个要点:
1.init_chat_model("厂商:模型名") 是个标准化接口。今天用 DeepSeek,明天想换 OpenAI、Claude,只改这个字符串,调用代码一行都不用动。不锁定厂商,这是 LangChain 最实在的好处。
2..invoke() 是统一的调用入口,发消息,拿回复。
💡 正因为这个标准化接口,我整套教程把模型换成 DeepSeek,notebook 代码一行没改——所有地方都是 from utils.models import model,只改模型配置那一处。
第 2 步:让它记住上一句话
单次问答没意思,我们要多轮对话。但这里有个反直觉的真相:
大模型本身是「无状态」的——它根本不记得你上一句说了什么。
那 ChatGPT 怎么能接着聊?答案是:每次都把完整的历史一起传进去。
messages = [ SystemMessage(content="你是一个简洁的技术助手"), HumanMessage(content="什么是 Agent?"), ] response = model.invoke(messages) messages.append(response)# 把 AI 回复加进历史 messages.append(HumanMessage(content="能举个例子吗?"))# 追加新问题 response2 = model.invoke(messages)# 带完整历史再问
第二句只问「能举个例子吗?」,完全没提 Agent,但模型靠着传进去的历史准确接上了话。
坑/认知:所谓「记忆」,此刻完全靠你手动 append 维护那个列表。每多一轮,列表长一截。记住这个累,第 5 步会有人来救你。
第 3 步:让它能「动手」查真实数据
大模型有两个硬伤:拿不到实时数据(比如今天天气),不能执行动作。工具(Tools)来补这块。
定义工具特别简单——普通 Python 函数加个 @tool 装饰器:
@tool def get_weather(latitude: float, longitude: float) -> str: """Get current temperature for given coordinates."""# ← 这行注释至关重要 ...
但这里有个最关键的认知,很多人一开始想错:
⚠️ 大模型自己不执行工具,它只「请求」调用。真正执行的是你的代码。
整个闭环是这样跑的(我问西雅图天气):
【第1步】模型请求调用: get_weather {'latitude': 47.6, 'longitude': -122.33} 【第2步】你的代码执行工具,拿到真实结果: {"temperature_fahrenheit": 58.2, "weather_code": 2} 【第3步】把结果喂回模型,它生成最终回答: 西雅图现在 58.2°F(约 14.6°C),多云为主。 如果你想出门,建议带一件外套哦!😊
看到没——模型不仅报了真实气温,还自己把天气代码 2 翻译成「多云」、换算成摄氏度、加了出门建议。真实数据 + 大模型的语言能力,这就是工具的威力。
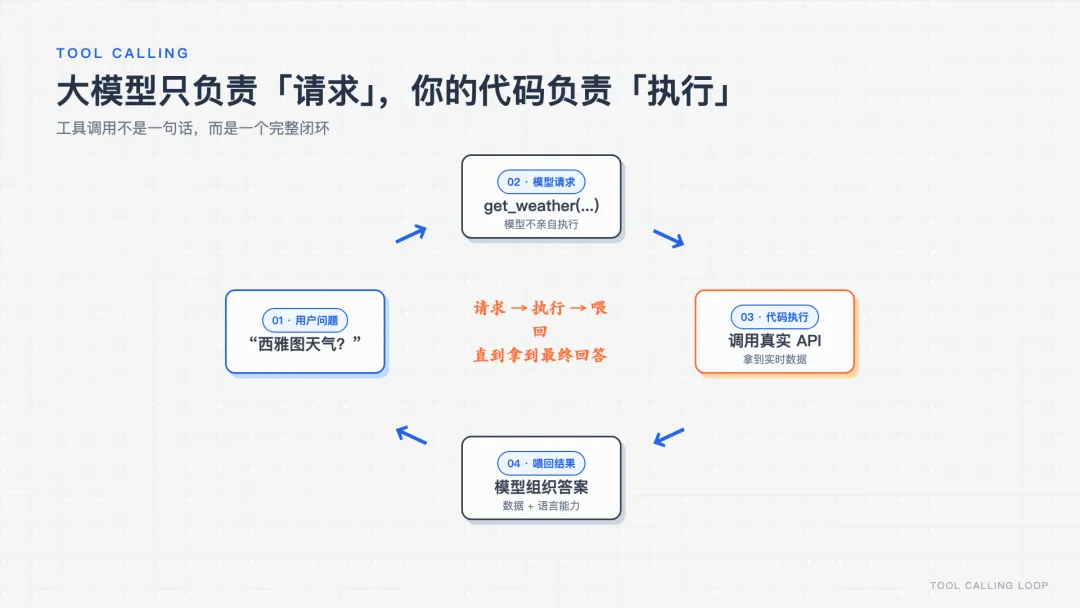
坑:这套「请求→执行→喂回」的流程,全是手动的。如果模型想连续调好几个工具,你就得手写一大堆 if-else 来派发。累,且容易错。
第 4 步:把那个累人的循环自动化
第 3 步的手动流程里藏着三个写死的假设,现实分分钟打脸:
·你只取了「第一个」工具调用 → 但模型可能一次要调好几个工具;
·你手写 if 工具名 == ... 派发 → 每加一个工具就得改代码;
·你喂回一次就结束 → 但模型拿到结果后可能还想再调下一个。
本质上,「请求→执行→喂回」应该循环进行,直到模型不再要工具为止。create_agent() 就是把这个循环打包好了:
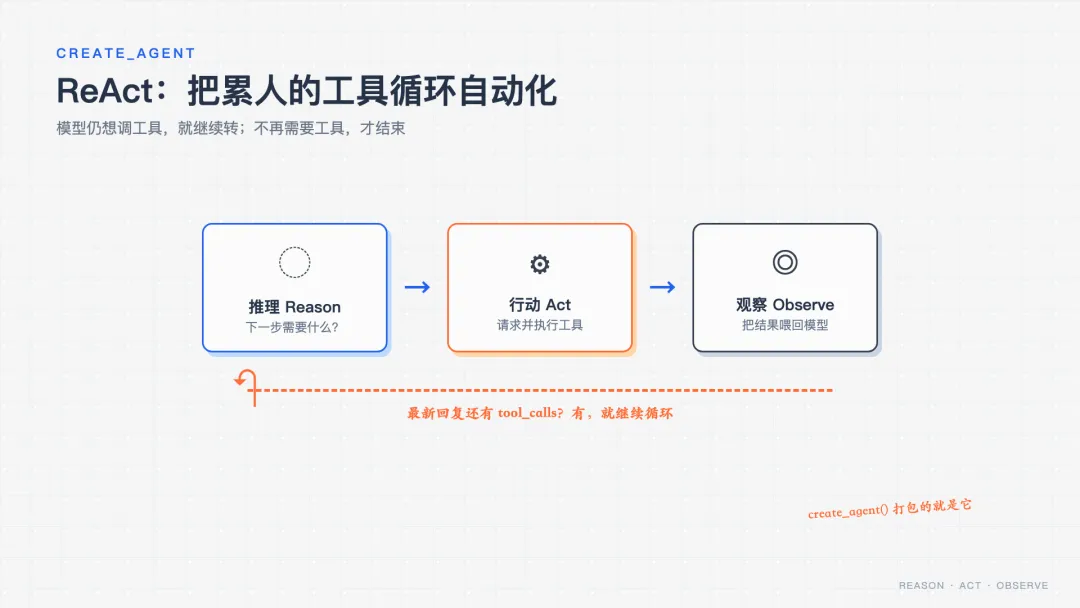
from langchain.agents import create_agent agent = create_agent( model=model, tools=[get_weather, search_movies], system_prompt="You are a helpful assistant.", )
就这么几行。它内部自动跑的是 ReAct 循环(推理→行动→观察→再推理)。
我问它「纽约天气 + 推荐科幻片」,它返回的完整历史是 5 条消息,最妙的是第 2 条:
[1] AIMessagetool_calls 数量: 2← 关键!一条消息里同时塞了两个请求 - get_weather{'latitude': 40.71, 'longitude': -74.01} - search_movies {'genre': 'sci-fi'} [2] ToolMessage63.5°F← 天气结果 [3] ToolMessageDune, ...← 电影结果 [4] AIMessage综合两个结果的最终回答
模型判断出「查天气」和「推荐电影」是两个互不依赖的需求,于是在一条消息里一口气发出 2 个调用,并行执行。这是第 3 步手写代码做不到的。
易踩的坑:调用方式变了!输入要传字典{"messages": [...]}(不再是裸列表),返回的是整段历史(不只最后那句答复)。很多人在这里卡住。
第 5 步:让它跨对话记住你
第 4 步的 Agent 很强,但有「金鱼记忆」——每次调用都从零开始,互相不记得。
还记得第 2 步那个「手动 append 维护历史」的累活吗?现在有人来接管了:checkpointer + thread_id。
from langgraph.checkpoint.memory import MemorySaver agent = create_agent(..., checkpointer=MemorySaver())# ① 加个存储器 config = {"configurable": {"thread_id": "会话A"}}# ② 给个会话 ID agent.invoke({"messages": [...]}, config=config)# 每次带同一个 config
实跑效果:
# 同一个 thread_id —— 有记忆 我:"我叫 Alice,喜欢科幻片" 我:"我叫什么?喜欢什么?"→ "Your name: Alice 🎀Movies: Sci-fi 🚀"✅ 记住了 # 换一个新 thread_id —— 失忆 我:"我叫什么?"→ "抱歉,你还没告诉我你的名字"❌ 隔离生效
机制很简单:checkpointer 按 thread_id 分桶存档,同一个 ID 第二次调用时,先把上次的历史读回来拼上,再喂给模型。换个 ID = 开一个新聊天窗口 = 完全失忆。
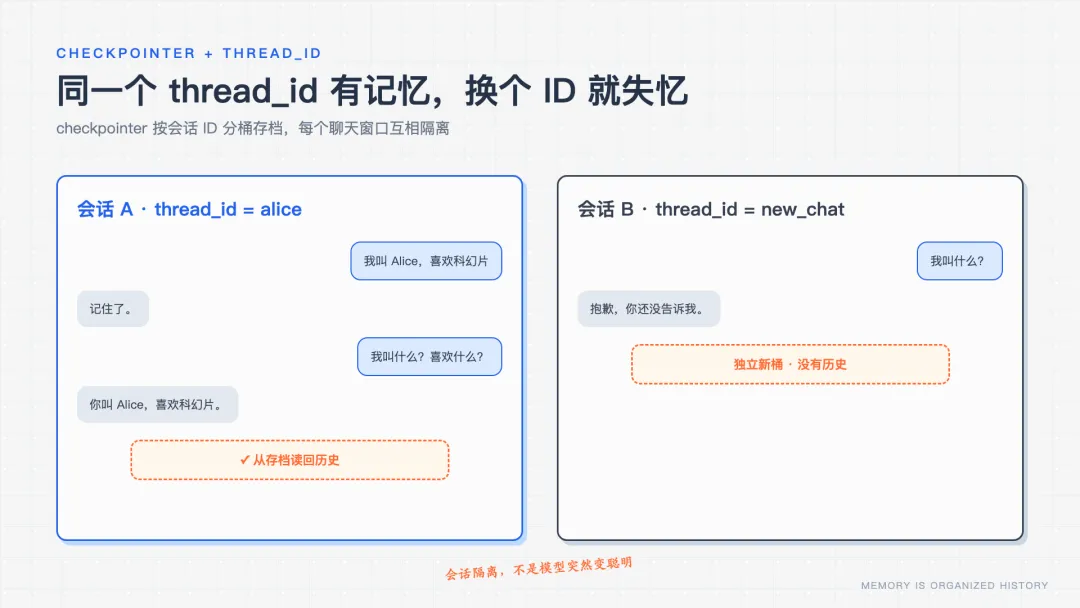
升级点:第 2 步你要手动维护列表、想开多个会话还得自己开多个变量;现在全自动,不同 thread_id 自动隔离。
第 6 步:别让用户干等——流式输出
.invoke() 有两个体验问题:干等(整个循环跑完才一次性吐结果,中间像卡死)、黑箱(不知道它在思考还是在调工具)。
解法是把 .invoke() 换成 .stream(),边跑边吐。它有两种模式:
# 模式一:updates —— 看 agent 每一步在干嘛(调试/进度提示) Step: modelTool call: search_movies← 第1步:决定调工具 Step: toolsContent: Dune, Interstellar← 第2步:工具执行结果 Step: modelContent: Here are some...← 第3步:生成最终答复 # 模式二:messages —— 一个字一个字蹦(ChatGPT 那种打字机效果)
⚠️ 这里是本文最大的坑——也是 DeepSeek 的「独家」
官方教程跑下来一切正常。但我用 DeepSeek 时,打字机模式如果照抄教程会出问题。我 dump 了流式吐出的第一个 token,发现:
content_blocks = [{'type': 'reasoning', 'reasoning': ''}]← 不是 text,是 reasoning!
DeepSeek 这类带推理能力的模型,流式吐出的内容块里不只有正文(`text`),还有「推理过程」(`reasoning`)。 如果你不过滤,模型的内部思考就会混进最终输出,画面一团乱。
教程里那行看似无关紧要的过滤——
if block.get('type') == 'text':# 只要正文,挡掉 reasoning
——对 DeepSeek 来说不是可有可无的,是必须的。这就是「拿国产模型跑外国教程」才会撞见的细节,官方文档不会替你写。
第 7 步:串成一个真正的个人助手
前面都是单点能力,第 7 步把「工具 + 自动循环 + 记忆」全塞进一个 Agent,造个能记住你偏好的助手。
这一步我故意设计了两个有依赖关系的工具:先 查用户偏好,再 按偏好推荐电影。关键在于——推荐工具需要一个「类型」参数,但用户从没说过自己爱看哪类,这个参数只能从「查偏好」的结果里读出来。
我问:「我是 Alice,查我的偏好并推荐电影」。Agent 跑出 6 条消息:
[1] 调 get_user_preferences(user_id='Alice')← 第1轮:先查偏好 [2] 返回 "Loves sci-fi movies..."← 拿到线索 [3] 调 book_recommendation(genre='sci-fi')← 第2轮:依赖[2]! [4] 返回 "Arrival, Ex Machina, The Martian" [5] 最终推荐
最硬的证据在第 [3] 步:那个 genre='sci-fi',用户全程没说过,是 Agent 读了第 [2] 步的偏好自己推断填进去的。所以它必须等 [2] 回来才能发 [3]——物理上无法并行,只能分两轮。
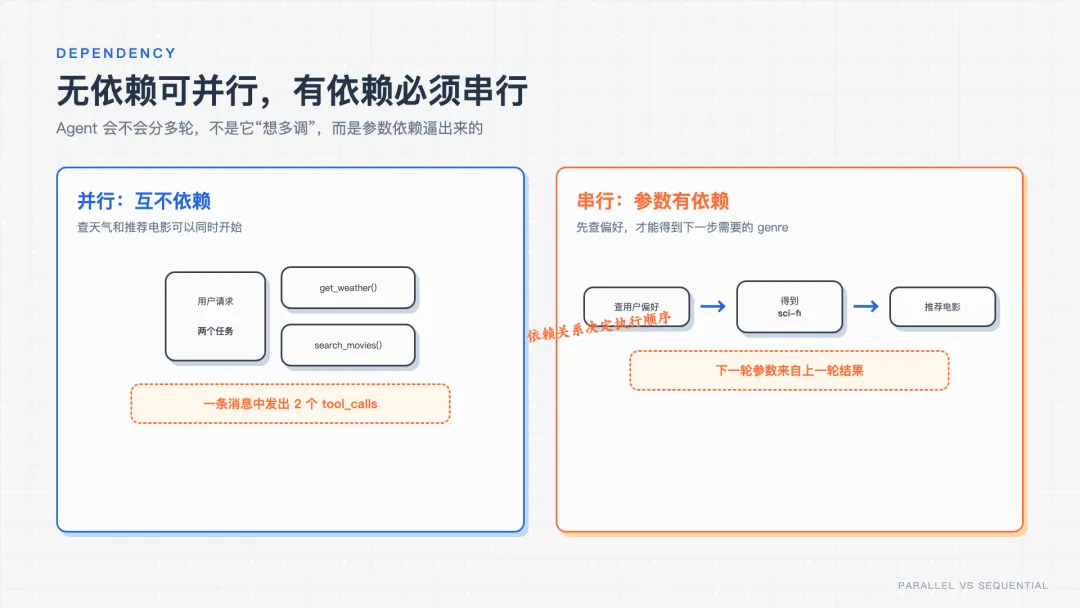
🔑 这就是关键认知:Agent 会不会分多轮,不是它「想多调」,而是参数依赖逼出来的。第 4 步的天气+电影没依赖,所以一条消息并行发;这里有依赖,就老老实实串行跑两圈。
第 8 步:拆开看——create_agent 根本不是魔法
前 7 步都在用create_agent(),第 8 步我们把它拆开,用 LangGraph 的三个原语亲手搭出一模一样的东西:
·State:图的「记忆结构」,就是那个 {"messages": [...]};
·Node:处理状态的函数(一个调模型,一个执行工具);
·Edge:连接节点、决定下一步去哪。
核心就一个判断函数,它是整个 ReAct 循环的「开关」:
def should_continue(state): if state["messages"][-1].tool_calls:# 最新回复还想调工具 return "continue"# → 去执行工具,继续循环 else: return "end"# → 没工具要调了,结束
然后 6 行把它拼成图,compile() 一下——画出来跟官方 `create_agent` 的图拓扑完全一致,只是节点名字不同。
而真正让我「哇」的一刻在跑测试时。我用中文问「推荐几部科幻电影」,模型把参数填成了中文 '科幻',而工具里的词条是英文,于是:
[1] 调 search_movies(genre='科幻')← 填了中文 [2] 返回 "No movies found"← 查不到! [3] 调 search_movies(genre='Sci-Fi') ← 模型看到失败,自己改用英文重试! [4] 返回 "Dune, Interstellar..."← 成了
没有人写代码教它「失败了改英文」。是工具返回的「失败」被喂回模型,循环又转了一圈,模型自己调整了策略。
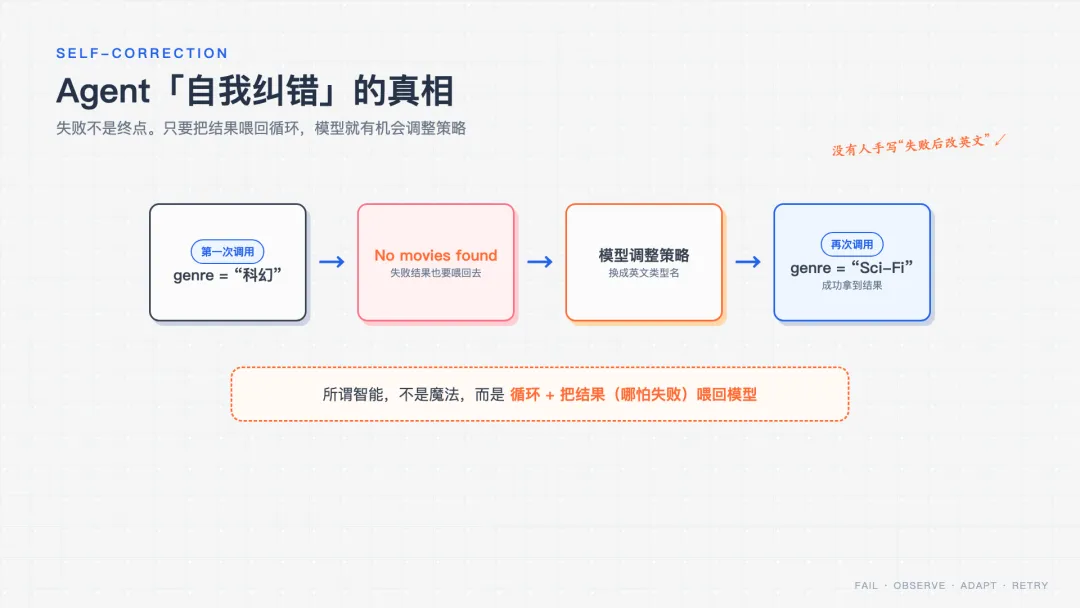
这就是 Agent「智能」的真相:所谓自我纠错,不是魔法,而是「循环 + 把结果(哪怕是失败)喂回去」这个机制设计出来的。看懂了这一层,你就不再怕这个框架了。
8 步回顾:每一步都在解决上一步的痛
步:1 LLM 调用·解决的痛点:最基础:发一句话拿一个回答
步:2 Messages·解决的痛点:模型无状态,多轮对话靠手动传历史
步:3 Tools·解决的痛点:让模型能查实时数据(但它只「请求」,你来「执行」)
步:4 create_agent·解决的痛点:手动调工具太累 → 自动循环,还支持多工具并行
步:5 Memory·解决的痛点:跨对话失忆 → checkpointer 自动记
步:6 Streaming·解决的痛点:干等+黑箱 → 边跑边吐(DeepSeek 记得过滤 reasoning)
步:7 综合实战·解决的痛点:串成个人助手,看清「依赖逼出多轮」
步:8 手搓 ReAct·解决的痛点:拆开 create_agent,看清它只是一张普通的图
最后,聊聊我是怎么学下来的
这 8 步我不是「看」完的,是「跑」完的。分享一个我觉得最有用的学习方法:
3.一步一停:每个概念单独写一小段能跑的代码,不贪多。跑通了,再走下一步。
4.亲手实跑,盯着输出看:上面那些 tool_calls 数量: 2、reasoning 块、中文 genre 自我纠错——全是我跑出来、dump 出来才发现的,光看文档根本撞不见。
5.边学边记,串起伏笔:每一步留个「钩子」指向下一步(比如第 2 步的「手动 append 好累」直接埋了第 5 步的 checkpointer)。这样 8 步不是 8 个孤立知识点,而是一条有因果的线。
很多坑——DeepSeek 的 reasoning 块、调用方式从列表变字典、工具节点不能直接调——都是真跑才会撞到的,文档默认你不会犯。所以与其纠结「学没学懂」,不如打开编辑器,把每一步都跑一遍。
下一站是多 Agent 协作(一个 Agent 不够用,让多个 Agent 分工配合)。等我跑通了再来分享。
如果这篇对你有用,欢迎转发给同样想入门 Agent 的朋友。有问题也欢迎在评论区聊。
——我们下篇见。
