 夜雨聆风
夜雨聆风一、前言
有没有遇到以下的情况:
为什么你把需求扔给了聊天窗口让AI直接跑代码,AI会经常乱写一些你不想要的代码?
为什么有时候你让 AI 发起提案,时灵时不灵?
该如何才知道AI每一步都修改了什么代码?如何Review AI代码?
面对以上情况,我们需要一个管理工具,因此今天讲的主角OpenSpec开始登场。
二、快速认识OpenSpec
OpenSpec 是一个面向 AI 编程助手的轻量级 Spec-Driven Development(规格驱动开发,SDD)工具。它是一套流程规范约定,提供了一套结构化的流程规范,统一规定了 AI 服务应该暴露什么能力、接收什么格式的输入、返回什么格式的输出,让团队和 AI 助手在编码开始之前就对规格达成共识,从而减少错误、提升代码质量。它将 AI 编码从不可控的 "自由发挥" 转变为可预期、可验证的工程流程,彻底解决传统 AI 开发中需求理解偏差、代码风格混乱、难以追溯、协作困难等痛点。
2.1. OpenSpec工作流程指令解析
默认流程 - Default quick path (core profile):
/opsx:propose ──► /opsx:apply ──► /opsx:sync ──► /opsx:archive
意图/想法/需求 ──► 实现 ──► 同步代码 ──► 归档
自定义流程 - Expanded path (custom workflow selection):
/opsx:new ──► /opsx:ff or /opsx:continue ──► /opsx:apply ──► /opsx:verify ──► /opsx:archive
新功能/需求/bug ──► 撰写完善需求 ──► 实现 ──► 验证 ──► 归档
默认的全局配置文件为 core,其中包含 propose、explore、apply、sync 和 archive 四个指令功能(全局默认开启),如果使用自定义流程的指令需要手动开启,通过openspec config profile 启用扩展的工作流命令,然后再执行 openspec update。
2.2.安装与初始化
环境要求 Node.js 20.19.0 或更高版本
# 全局安装 OpenSpec
npm install -g @fission-ai/openspec@latest
# 进入你的项目目录,进行初始化
cd your-project
openspec init
初始化时,OpenSpec 会提示选择使用的 AI 工具(Claude Code、Cursor、OpenCode、Qoder 等)。根据使用的 AI 工具不同,OpenSpec 会生成不同的目录结构,我这里选择了Claude Code和OpenCode,OpenSpec会生成3个文件夹:openspec、.claude、.opencode。
openspec放的是所有规范的文件,目录结构如下:
openspec/
├── specs/ # Source of truth (your system's behavior)
│ └── <domain>/
│ └── spec.md #主规范文件
├── changes/ # Proposed updates (one folder per change)
│ └── <change-name>/
│ ├── proposal.md # 意图/想法/需求
│ ├── design.md # 技术方案与架构决策
│ ├── tasks.md # 带复选框的任务清单
│ └── specs/ # Delta specs (what's changing)
│ └── <domain>/
│ └── spec.md
└── config.yaml # Project configuration (optional)
.claude或者.opencode这类基于不同AI编程工具生成的文件夹存放的是适配的Command和Skill,目录结构如下:
.claude/
├─commands/
│ └─opsx/
│ apply.md
│ archive.md
│ explore.md
│ propose.md
│ sync.md
└─skills/
├─openspec-apply-change/
│ SKILL.md
├─openspec-archive-change/
│ SKILL.md
├─openspec-explore/
│ SKILL.md
├─openspec-propose/
│ SKILL.md
└─openspec-sync-specs/
SKILL.md
三、不同场景的使用
3.1. 场景1 - 独立开发者使用
独立开发者面临的问题是项目从 产品设计→需求→项目架构设计→开发→测试 整个项目的生命周期都是一个人负责,那么就会面临需求容易跑偏,在编程时,AI会给出很多不同方向的临时需求优化或者设计,如果你一开始不去管理和梳理AI做得这些临时需求,最终项目完成后,你发现成品与最初的需求设计天差地别,最重要的是你还不知道改了哪些需求和设计,无法追踪。对于独立开发者来说,使用 OpenSpec 的最大实际收益是将需求+变更+代码实现一体化的管理起来。不需要每次打开 AI 会话你都要重新解释背景;由于由spec需求文档管理,AI 直接读 openspec/specs/ 就能理解系统现状。
独立开发者使用OpenSpec的核心工作流程即可:
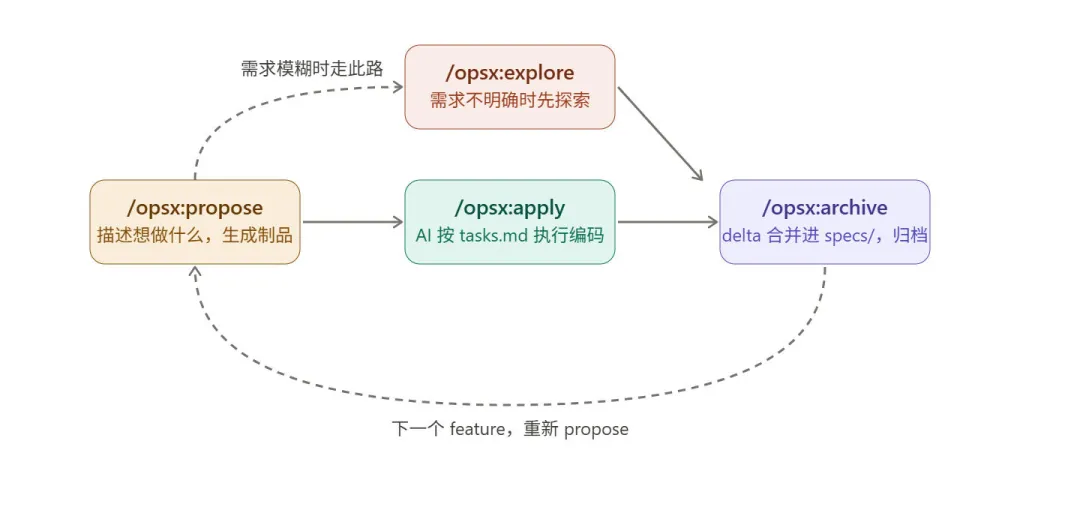
具体流程操作流程可以参考官网的命令执行,这里就不复制了,就讲几个编程需要值得注意的几个点:
1.注意context hygiene问题,在开始实现每一个新需求前清空上下文窗口,保持整个 session 中良好的上下文避免被历史对话干扰。
2.需求规范提交归档,保证每次/opsx:apply实施代码验证通过后,马上git commit 代码并将需求变更同步主spec并归档,后续测出有bug另起一个需求变更,保证每一个commit都是一次change,方便后续需求回退或者变更。最好是做成自动化脚本或者自动化流程来处理,避免代码写嗨了或者多个窗口同时写代码时忘记了。
3.2. 场景2 - 团队使用
个人开发只需要管理自己就OK了,团队开发需要管理的是认知一致性,如何让团队所有人的认知都在一个频道内,这就需要规范与共识,而要达成规范和共识,就需要有效地管理和处理多人认识决策的冲突,因此在项目中就需要处理两个问题:多人并行变更的冲突管理 和 异步审查沟通。OpenSpec通过expanded profile来规范项目的通用配置和处理Spec变更冲突,以及一套工作流命令来规范流程。
OpenSpec的核心工作流程是每个成员在各自的 changes/ 子目录中独立推进变更,互不干扰;当提 PR 时首先审查的不是代码 diff,而首先是 proposal.md 和 spec delta,然后再是代码。所有变更就绪后,用 /opsx:bulk-archive 统一合并。批量归档时 OpenSpec 也会检测 spec 冲突——例如两个变更都修改了 specs/ui/,系统会检查代码库,按时间顺序依次 apply,并在存在冲突时提示人工介入,而不是静默覆盖。
下面稍微讲一下团队结合OpenSpec管理的流程是怎样的?
1.配置统一:固定工作流、项目文档规范、命名规范、代码规范以等,规定项目基准目录 openspec/specs/ 不允许手动修改,所有需求改动只能通过changes变更归档合并修改。
2.环境统一:使用的库、skills、cli等都统一。
3.启用架构决策记录(ADR):通过 spec-driven-with-adr 自定义 schema,可以在 spec 旁边保存架构决策记录。
4.规划和提案:创建feature分支,使用/opsx:new + /opsx:ff 构建需求,发起MR指派开发进行下一步需求评审
5.Spec PR 评审:评审修改需求后,使用/openspec:continue 迭代文档
6.代码实现:使用/openspec:apply命令执行。另外可以使用Git Worktree + SubAgent并行实现多个任务需求。
7.验证(Verify):在merge前,使用/opsx:verify验证所有 tasks 是否完成、所有 spec 里的需求是否有对应代码、所有场景是否覆盖;实现是否符合 spec 意图、边缘情况是否处理;代码结构是否反映了 design.md 里的决策、命名规范是否一致。如果验证不通过则重新/opsx:continue修正文档,重新apply实现代码,然后验证直至通过。
8.归档并合并到main分支
四、总结
openspec使用下来的感受是自由度高,换个词就是粗狂,非常多的地方需要自定义并需要时间磨合验证,面对大型项目团队这个成本非常高,需要有非常有经验的Tean leader来制定很多规范与流程,也需要时间磨合验证调整,后续的交接项目的学习成本也高。当然了,也是有好处的,好处是轻量级自由度高,可以根据团队情况不断调整磨合来适应团队变化,适合初创团队或者项目,以及小团队和个人。
下一篇讲解下它的竞品Spec-Kit。
