 夜雨聆风
夜雨聆风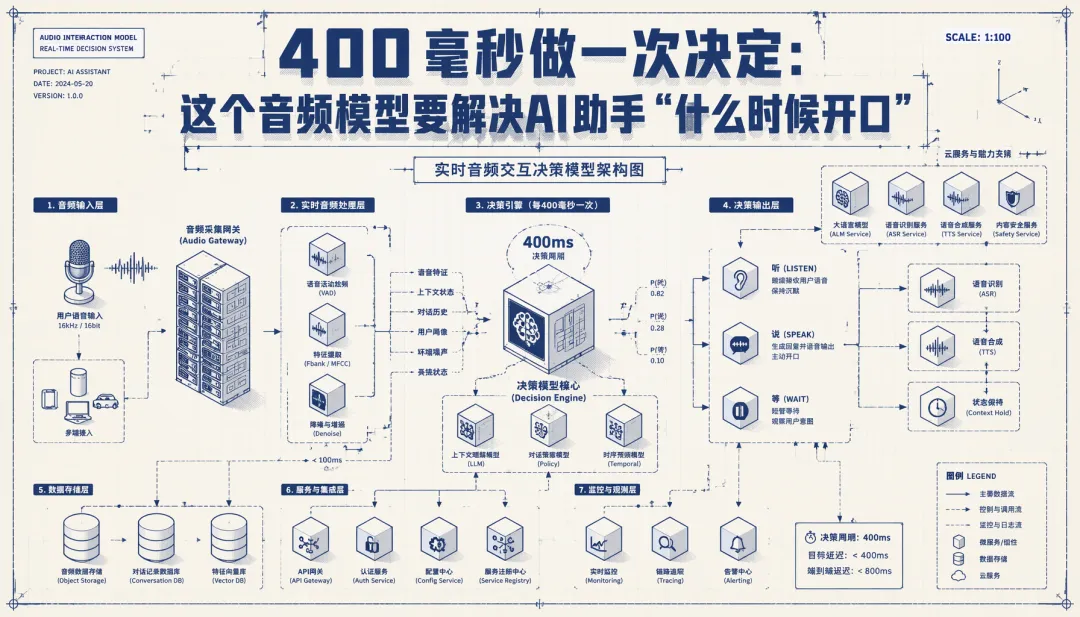
📍 文 / 老Z
你在厨房外听到“哗啦”一声,像杯子碎了。一个真正有用的语音助手,此时不该等你问“刚才是什么声音”,也不该滔滔不绝解释玻璃材料;它更应该判断:现在要不要提醒一句,小心地上碎片。
同样的场景还会发生在车里、会议室和老人独居的房间。刹车声突然变近,投影仪旁边有人剧烈咳嗽,夜里有设备发出异常蜂鸣,这些声音并不一定伴随一句明确指令。可对一个在线助手来说,它们可能比“帮我查天气”更值得被听见。
这正是论文 Audio Interaction Model 想解决的问题。论文编号 2606.05121,团队做了一个名为 Audio-Interaction 的系统。我的第一反应是,它讨论的不是“识别准确率还能涨多少”,而是一个更接近产品现场的问题:AI 到底什么时候该开口?
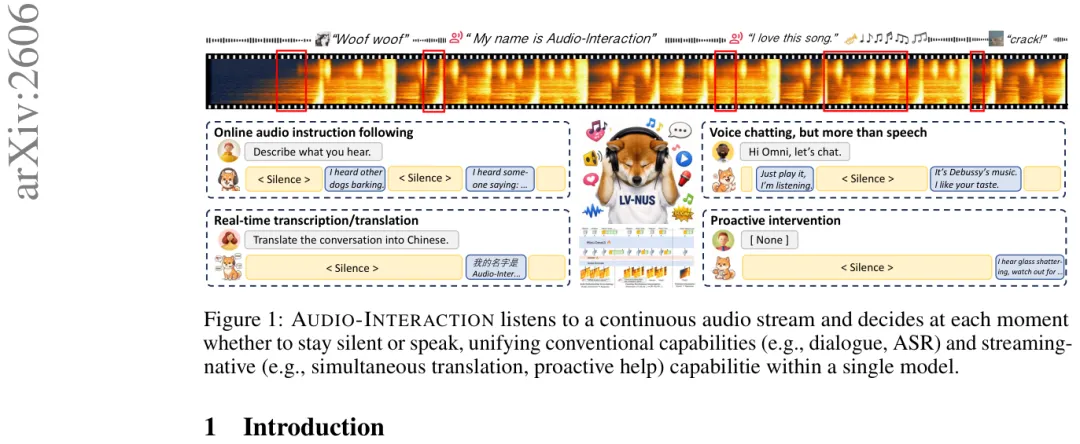
过去很多音频模型的默认姿势,是等一段录音结束,再给出一个答案。Audio-Interaction 改成持续听音频流,在每个时刻判断保持沉默还是回应。我觉得这里最有意思的地方,是它把“沉默”也当成一种需要训练的能力,而不是把所有声音都变成回答欲。
不是更会聊天,而是让AI开始“听世界”
普通语音助手主要听人话,很多大音频模型则把声音当成文件处理:你给它一段完整音频,它再分析。即便一些实时语音聊天系统能边说边回,也常被限制在对话任务里,咳嗽、警报、猫叫、碎玻璃、音乐变化,往往只是背景。
这类系统的问题不只是“慢半拍”。它们默认世界会在用户按下按钮、说完一句话、上传完录音后才开始被理解。可声音的价值常常就在发生当下:警报晚几秒就不是同一个体验,玻璃碎裂后再等用户询问也不够自然。
Audio-Interaction 的切入点更激进:音频不是一段输入,而是一条持续发生的世界线。系统以 400 毫秒为一个音频块,每来一小段,就做一次选择:继续听,还是开始回应。AI 最难的也许不是多说,而是别在不该说的时候乱说。
在这个框架下,语音识别、实时翻译、音频理解、语音聊天、音乐跟随、主动帮助,不再需要分别塞进不同系统。它们都变成同一个问题:在连续声音里理解上下文,并在合适时机给出反应。
这点让我觉得它更像一次范式改写,而不只是又一个语音聊天模型。过去我们把“说得像人”当作语音助手的终点;这篇论文提醒我,真正难的是让助手像人一样听现场,知道什么时候不说,什么时候必须说。
论文用 SoundFlow 来组织这套流程。它不是单独一个模型结构名字,而是一整套从数据、训练到推理的管线:前面造连续音频数据,中间训练“沉默或回应”的控制能力,后面用异步队列降低实时交互卡顿。

真正重的活在数据:2.6M条连续音频怎么造出来
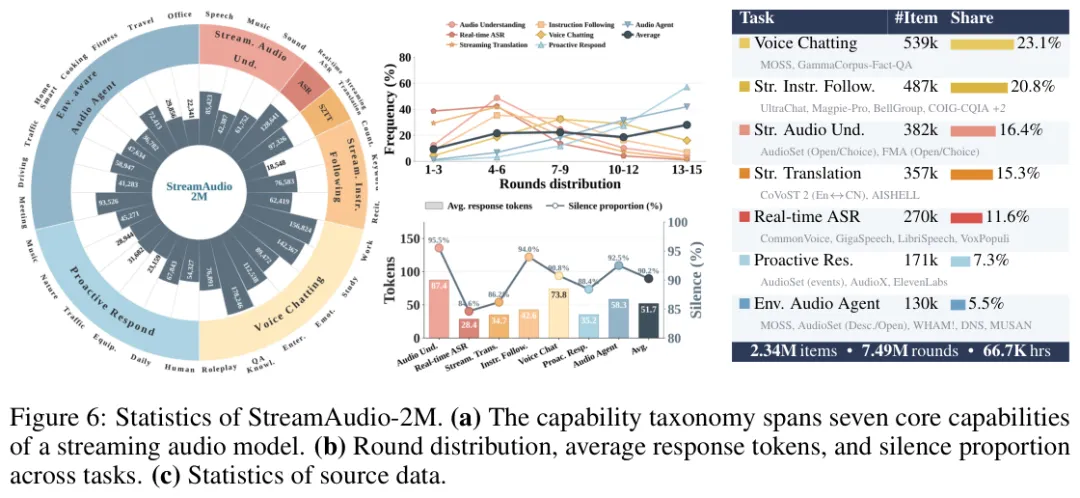
我认为这篇论文最重的部分,其实不是某个花哨模块,而是 StreamAudio-2M。这个数据集包含 2.6M 条样本、约 302k 小时音频,覆盖 7 类能力和 28 个子任务。每条样本也不是孤立问答,而是 3 到 15 轮连续交互。
为什么这很难?因为真实世界的声音不会像考试题一样排队出现。会议室里可能有人讲话,窗外有车鸣,手机又突然响起警报。如果只是随机拼接短音频,很容易出现常识冲突,模型学到的不是“现场感”,而是混乱剪辑。
团队的做法是先规划场景,再细化成一串音频事件,然后通过检索或生成找到对应片段。后面还要处理停顿、噪声和边界,让拼接后的长音频更像真实录音,而不是几段素材硬粘在一起。
这里还有一个容易被忽略的细节:训练集中必须有大量“不该回应”的片段。一个主动助手如果只学会捕捉异常声,很快就会变成烦人的广播员。论文专门加入理解场景后仍应保持安静的样本,目的就是压住这种误触发。
这点让我比较服气。很多论文喜欢把亮点压在模型名称上,但在实时音频交互里,数据如果没有时间连续性,模型很难学会什么时候该忍住。换句话说,训练“别说话”需要大量真的不该说话的声音。
同时我也会把这部分看成未来竞争的关键。谁能拿到更真实的家庭、车载、办公和公共空间长音频,谁就更可能把主动提醒做得可靠。单靠短音频题库,很难逼近真实使用里的混乱声场。
分数说明一件事:它没有只会“瞎插话”
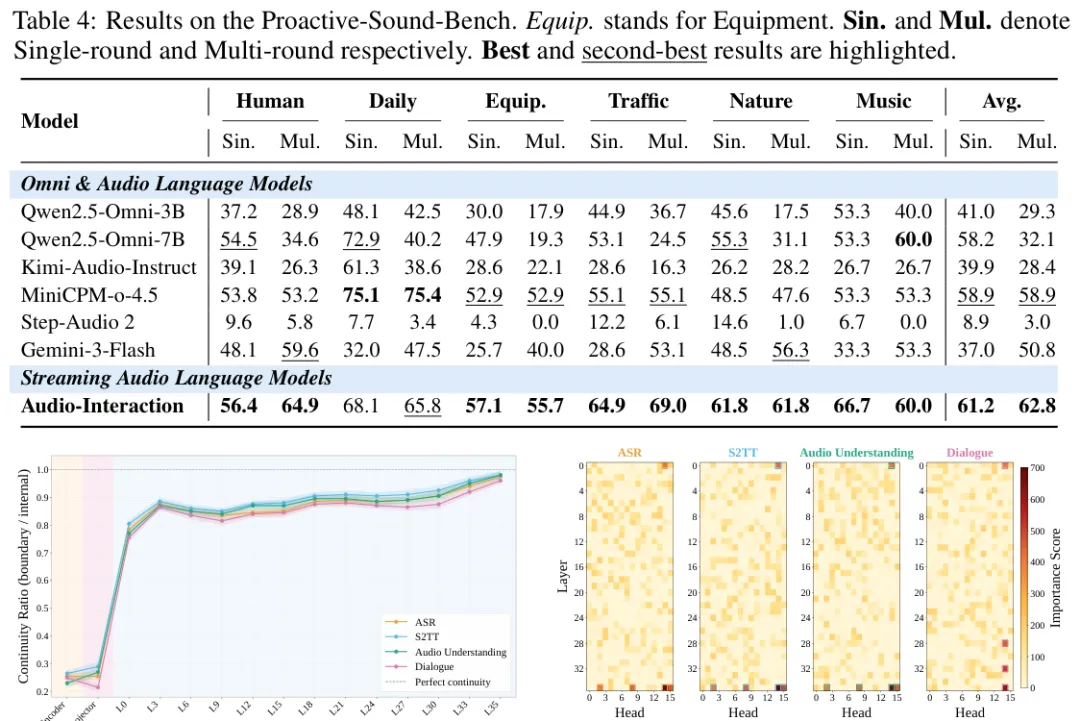
看结果,Audio-Interaction 没有为了实时能力把基础能力丢掉。在 MMAU 音频指令设置下,它的平均分是 58.15;在语音翻译 CoVoST2 上,英中和中英方向分别达到 55.22 和 35.21 BLEU。这说明它不是只会做触发器,仍保留了主流音频任务能力。
更关键的是主动响应。论文新建了 Proactive-Sound-Bench,用 644 个需要触发或保持沉默的声音事件测试模型。Audio-Interaction 在 Single 和 Multi 两档平均分为 61.2 与 62.8,尤其 Multi 档比很多通用模型稳得多。
实时体验还要看延迟。论文里的 FIFO 异步调度,把音频编码和文本解码拆成排队协作。保留该设计时,恢复监听后的首块延迟为 392 毫秒,卡顿率为 0;去掉后延迟变成 831 毫秒,卡顿率升到 5.2%。
我更在意另一组数字:当连续片段从 1 段增加到 5 段,Audio-Interaction 仍保留超过 91% 的单段准确率,而基线下降超过 30%。这比短音频榜单更接近真实使用,因为用户不会每十秒清空一次世界。
这些数字也让“主动插话”听起来没那么玄。它不是听到响声就机械开口,而是在连续上下文里判断这个声音是否和当前任务、环境安全或用户意图有关。这个差别很重要,否则主动助手只会从聪明变吵闹。
但我最担心的,也是它最有商业价值的地方
论文的 case 很有画面感。比如客厅里有人说喜欢这段音乐,随后传来咳嗽声,Audio-Interaction 不只回应音乐,还会提醒喝点水。另一个场景里,警报响起后它提醒找安全位置,后面听到猫叫又能描述出来。
这也带来一个真实存疑点:AI 凭什么决定打断人?碎玻璃、警报、咳嗽相对容易解释,可如果是争吵声、婴儿哭声、老人轻微喘息、设备异响,提醒和打扰之间的边界会非常细。误报会烦人,漏报又可能危险,隐私责任也绕不开。
所以我反而觉得,它最有价值的落点不一定是手机里的聊天助手,而可能是耳机、车载座舱、家庭机器人、会议助手和看护设备。它们需要的不是更会闲聊,而是把“声音里的环境变化”变成可行动信号。
想象一个车载场景:后排孩子突然哭闹,车外传来急促鸣笛,导航还在播报路线。助手如果能区分哪些声音只是背景,哪些需要降低音乐、提醒司机或暂停播报,体验会完全不同。这个方向很有诱惑力。
我也会保留一点谨慎。StreamAudio-2M 做得很大,但其中大量长流来自策划、检索、生成和拼接。真实开放环境的混响、多人重叠、设备距离、方言和噪声,仍可能让主动响应变得不稳定。方向值得看,但还不能神化成万能管家。
另一个被低估的问题是个性化。有人希望助手听到咳嗽就提醒,有人会觉得被监视;有人在车里需要高敏感度,有人在办公室则更在意安静。主动音频助手如果没有清晰的用户偏好和场景开关,再强的模型也可能败给体验细节。
从开发者角度看,这类系统还需要一套新的评测语言。过去我们问“识别对了吗”,现在还要问“该不该说”“说早了还是晚了”“提醒是否过度”“沉默是不是更好”。这些问题很难只靠单个准确率覆盖,也会让产品测试变得更像安全演练。
我喜欢这篇工作的原因也在这里:它把一个模糊的用户体验问题,拆成了可以训练、可以测量、可以做延迟优化的工程问题。它没有把现实复杂性全部解决,但至少把门打开了。对音频 AI 来说,这扇门通向的不是聊天框,而是持续在线的环境理解。
如果把它放进更长的技术脉络里,文本助手解决的是“读懂你写了什么”,视觉模型解决的是“看见画面里有什么”,而这类音频交互模型开始追问“正在发生的事值不值得打断你”。这个问题更贴近物理世界,也更难伪装成一次漂亮演示。

Audio-Interaction 像是实时音频 Agent 的早期雏形。它真正想改变的,不是让 AI 多听见几个声音标签,而是让模型在连续世界里学习一件很人类的事:多数时候安静,关键时刻开口。
✍️ 老Z ·
欢迎转发,谢绝洗稿
