 夜雨聆风
夜雨聆风从"开头太平"到"钩子太套路"到"别用'你'"——前 30 次反馈,全是这种碎碎念。
直到有一天,我让它把"我否定过的东西"整理出来。
它整理出 7 条规则。
不是"什么内容是爆款",而是"我不要什么"。
而这 7 条规则让我意识到一件更意外的事:
教 AI 写爆款这件事,我们大多数人的第一步就是错的。
错的不是 prompt。
错的是让 AI 去"分析爆款"。
正确的做法,是让 AI 学你的"否定"。
今天这篇,我会把这套我跑通的方法论、具体的 7 条规则示例、以及一张能直接照着填的"负反馈清单模板",都给你。

一、大部分人教 AI 写爆款,第一步就是错的
"你帮我分析一下这条爆款为什么爆。"
"你帮我套用这条的开头格式。"
"你帮我总结这条的钩子公式。"
这三种问法,本质是同一个思路:
把"结果"当成"原因",让 AI 学"长啥样"。
问题是:
爆款长啥样,分析不出来 钩子公式总结出来了,套到自己内容上完全失效 同一个公式,A 账号有效、B 账号无效
为什么?
因为"爆款"是个结果,不是过程。
你教 AI "结果长啥样",等于让 AI 模仿一个没有上下文的成品。
它学的是皮,不是骨。
行业里绝大多数"教 AI 写爆款"的方法论,都在教这件事。
但这条路已经证明是低效的。
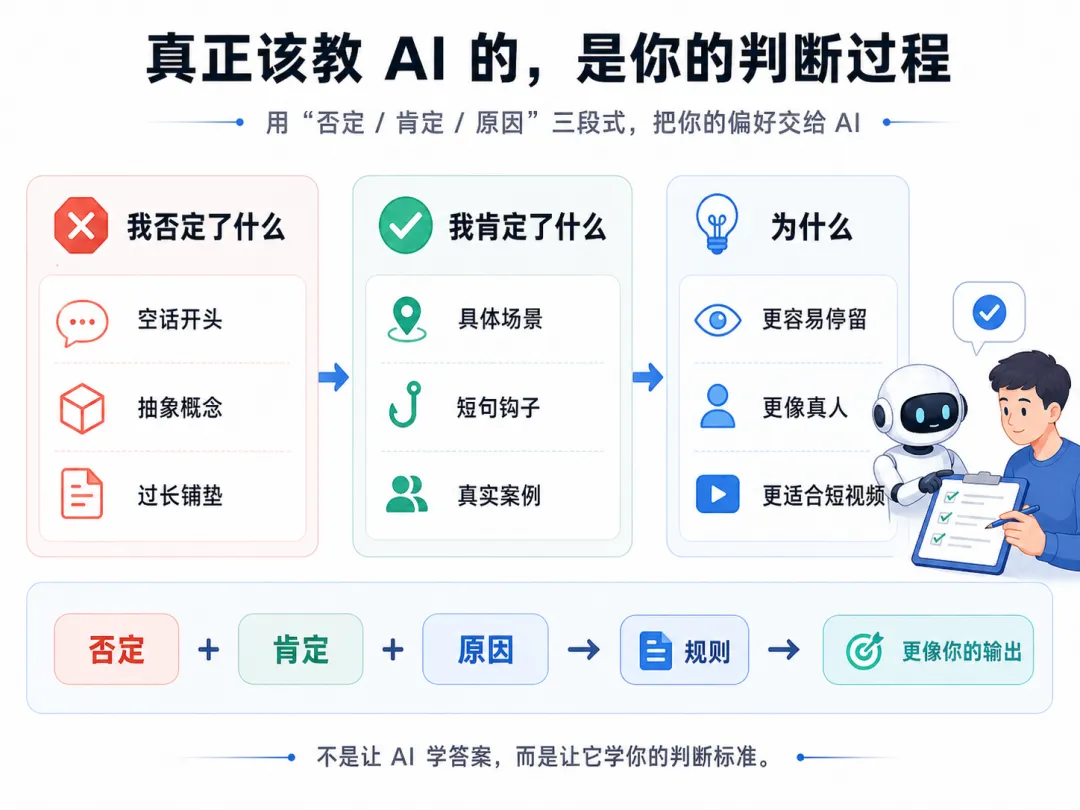
二、真正该教 AI 的,是"我否定了什么"
我最近让 AI 帮我写短视频开头。每次它交稿,我都得改。
后来我让它做了一件事:把我所有的反馈整理出来。
它整理出 7 条规则。
不是"什么内容是爆款",而是:
我否定了哪些内容 我肯定了哪些内容 每次的具体原因是什么
这 7 条规则,都不是"应该这样写"的正例。
都是"不要这样写"的负例。
带原因的负例。

举个例子。我用类比场景补足 7 条规则的具体内容:
这就是我的"7 条规则"。
注意它们的结构:
没有一条在描述"爆款长啥样" 每一条都是"我不要什么" + "我要什么" + "为什么"
这是关键。
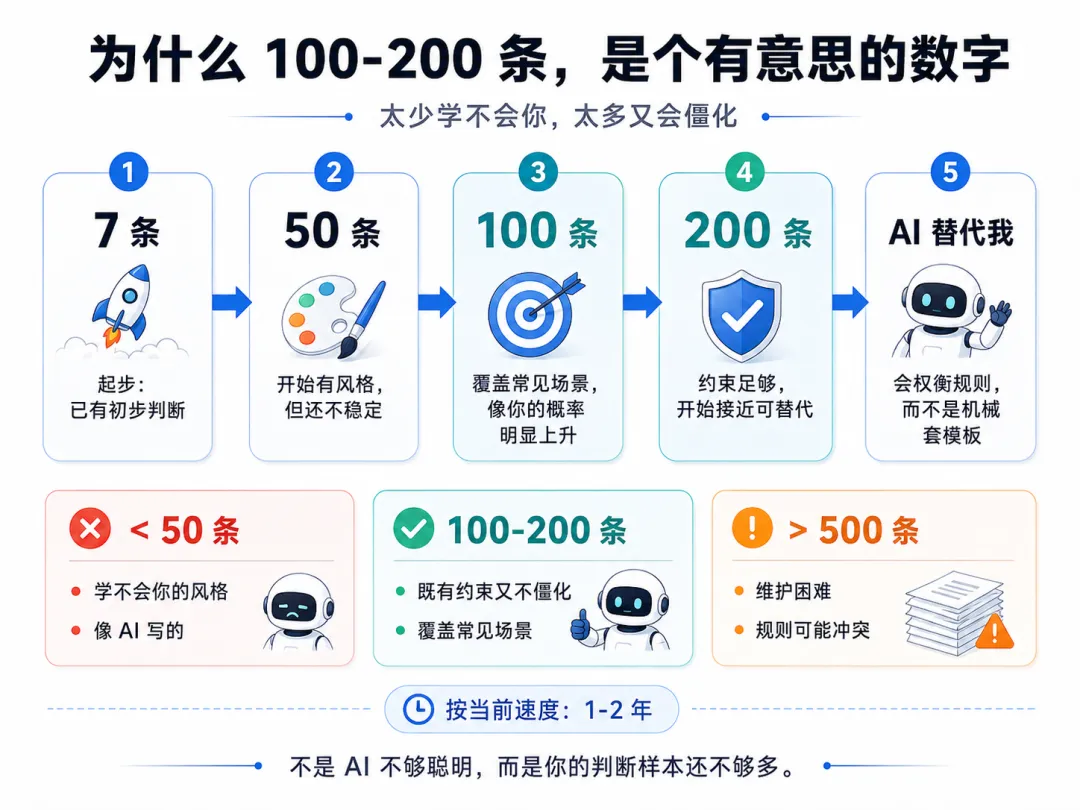
三、为什么"100-200 条"是个有意思的数字
目前我有 7 条规则。
目标:100-200 条。
为什么是这个数字?
太少(< 50 条):
AI 学不会你的风格 每次输出还是"看起来像 AI 写" 改稿的次数不会明显下降
太多(> 500 条):
你自己维护不动 规则之间开始冲突 AI 输出开始"僵化"
100-200 条:
既有约束又不僵化 覆盖常见场景 你偶尔还能翻到某条规则"哎,这条我好久没检查了" AI 开始有"自己的判断"——它会在 100 条规则之间做权衡
按我目前的速度,攒到 100-200 条大概要 1-2 年。
到那个时间点,AI 差不多就可以替代我了。
这不是 AI 智能的问题。
是我积累够不够的问题。
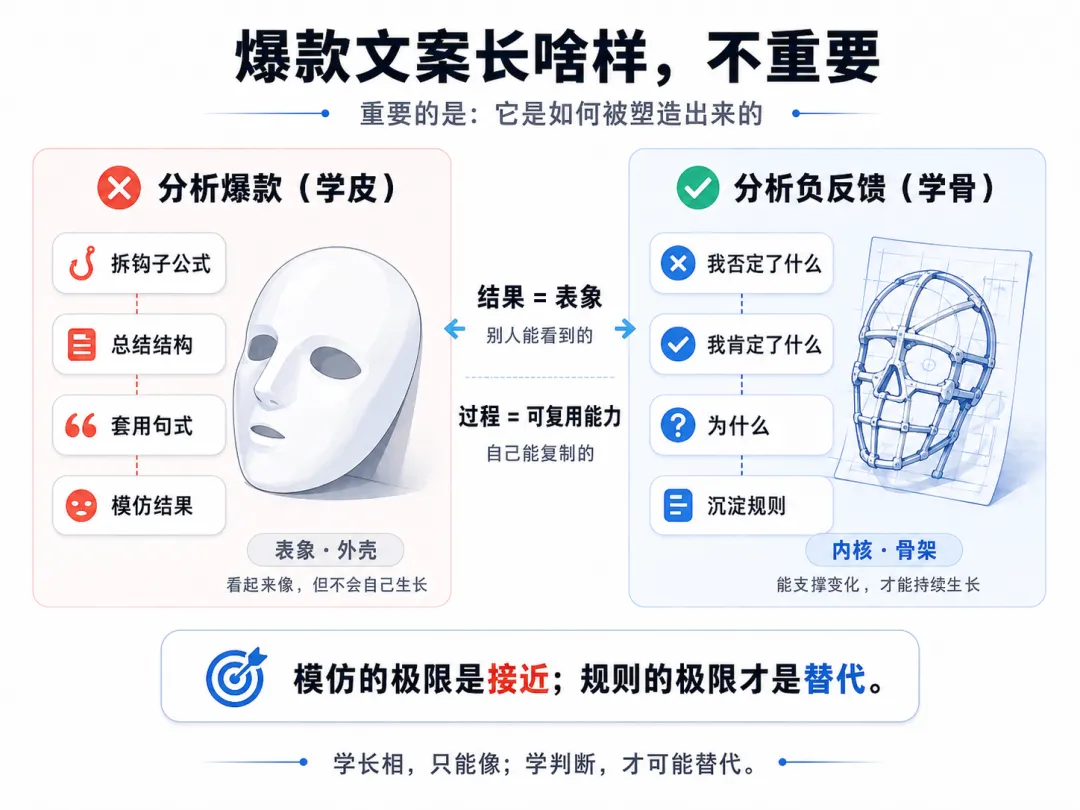
四、爆款文案长啥样,不重要
让我把话说穿。
爆款文案长啥样,不重要。
爆款文案是如何被塑造的,很重要。
"长啥样"是结果。
"如何被塑造"是过程。
行业里绝大多数"教 AI 写爆款"的方法论,都在教你分析"长啥样"。
拆解钩子公式 总结开头结构 套用爆款句式
这些方法没有错,但它们教 AI 学的是"模仿"。
模仿的极限是接近,不是替代。
真正能让 AI 替代你的,是让它学会"塑造过程"。
而塑造过程只有你自己知道。
你只能通过"否定 / 肯定 / 原因"这种三段式反馈,把这个过程交给 AI。
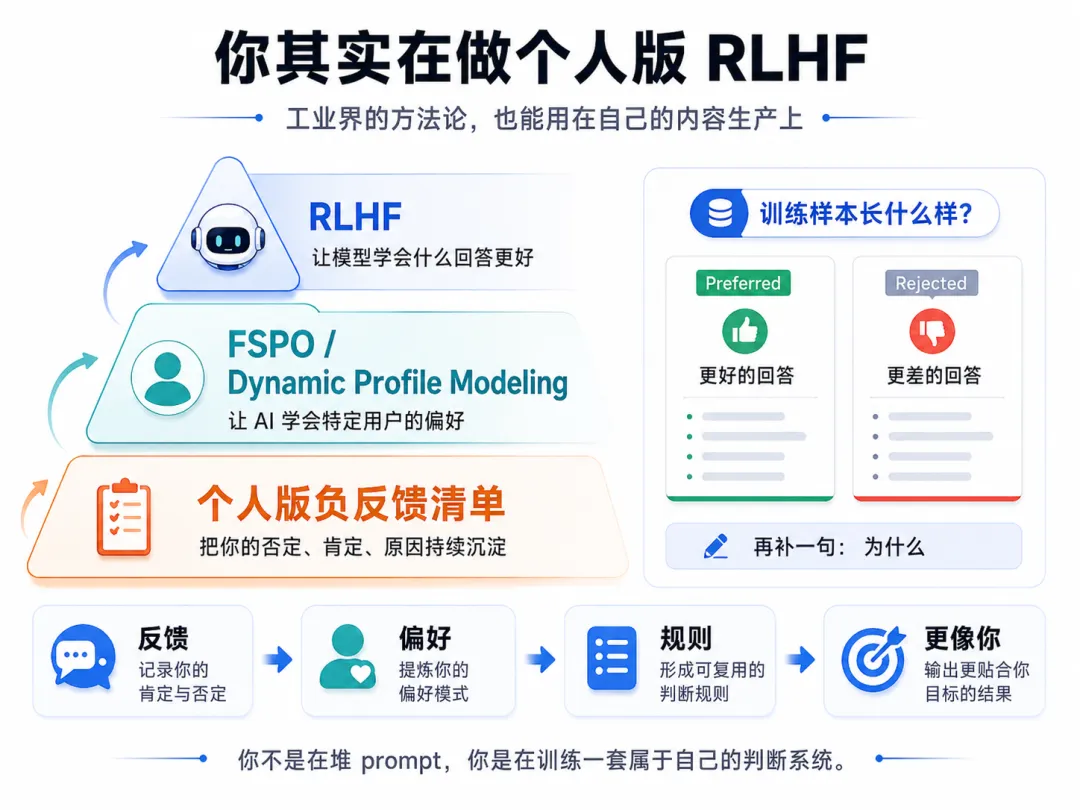
其实这件事,AI 工业界早就在做。
Anthropic 训练 Claude 用的标准方法叫 RLHF(Reinforcement Learning from Human Feedback)。
核心不是"教模型正确例子",而是"教模型什么是更好的回答、什么是更差的回答、为什么"。
训练样本是成对的"preferred vs rejected" + 文字理由。
模型学的不是"正确答案长啥样",是"判断标准是什么"。
你一直在做的,就是在用 RLHF 训练你自己的 AI。
2025-2026 年学术界的前沿方向(FSPO、Dynamic Profile Modeling)核心都是"怎么让 AI 学会特定用户的偏好"——和你攒 100-200 条规则的思路完全同源。
你不是一个人在战斗。
你只是把工业界的方法论用到了自己的内容生产上。
五、给你一张"负反馈清单模板"
下面这张表,是我用的"负反馈清单模板"。
直接复制,照着填。
 使用方式:
使用方式:
AI 每次交稿,你都填一行 每周让 AI 把这张表整理一遍,提炼出"新规则" 当你整理出 50 条、100 条、200 条时,分别给 AI 一次大反馈 AI 会按你的规则重新训练它的输出风格
这是一个反 AI 时代的笨办法。
也是最稳的复刻你自己的办法。
六、规则 > 结果
回到标题那个判断。
让 AI 分析爆款文案,是最蠢的方法。
不是因为分析没用。
而是因为分析的对象错了。
你该让 AI 分析的,不是"爆款长啥样"。
是你自己"否定过什么、肯定过什么、为什么"。
这不是 prompt 的优化。
这是用 AI 方式的根本转变。
规则 > 结果。
这是我用 7 条规则和 100-200 目标换来的认知。
也希望它能成为你的。
关于我
👋 你好,欢迎你
这里主要分享我在 AI 方向的一些实操内容:
AI 工具的真实使用方式 内容生产与效率提升方法 一些已经跑通的流程和踩坑经验
如果你也在:
想用 AI 提升效率 做内容创作 或者探索 AI 的实际落地方式
这些内容应该会对你有帮助。
