 夜雨聆风
夜雨聆风我以前看别人用 Codex、Cursor、Claude Code,最容易产生一种错觉。
他们一会儿叫插件,一会儿用 Skill,一会儿接 MCP,一会儿又让工具去读 GitHub、Figma、浏览器、终端。看起来特别丝滑。
然后轮到自己,就很容易卡住。
我到底该不该叫这个插件?我该手动 @ 它,还是让 AI 自己判断?MCP 和 Skill 到底差在哪?工具越多是不是越强?
这件事一开始看着像玄学,其实没那么玄。你不用背下所有插件名,也不用把每个 MCP 都研究一遍。真正要学的是,把工具该不该用、什么时候用、能做到哪一步、哪些动作必须停下来确认,写成一套规则。
规则写清楚以后,Codex 这类工具是可以自己判断的。

开头先把几个误区拆掉。因为很多人不是输在不会用工具,而是先把工具想歪了。

先把几个名词拆开
不同产品的叫法会有点乱,但你可以先按四层来理解。
Tool 或 function,是一个具体动作。读文件、查天气、跑测试、搜索网页、获取订单,这些都是动作。它像一个函数,有名字,有参数,有返回结果。模型觉得需要它时,就发起一次调用。
MCP Server,是一组外部能力的接口。比如 Figma MCP 负责把设计稿结构、图层、资源交给 AI;GitHub MCP 负责把 issue、PR、仓库文件交给 AI。MCP 不负责替你想清楚怎么工作,它只是把外部系统接进来。
Skill,更像一份可复用的操作手册。它通常有一个 SKILL.md,告诉 AI 什么时候使用、先读什么、按什么步骤做、怎么验证、输出什么。它不一定连接外部系统,但能把一件事做得更稳定。
Plugin,则更像一个打包盒。它可以把 Skills、应用集成、MCP 服务器这些东西打包起来,变成一个可安装、可分享、可复用的工作流。

这个关系分清以后,很多混乱会少一半。
比如你让 Codex 根据 Figma 做 React 页面。Figma MCP 解决的是拿到设计稿上下文,前端实现 Skill 解决的是按项目规范落代码,浏览器工具解决的是跑起来看截图。三个东西不是互相替代,而是接力。
真正的问题不是会不会 @,而是会不会判断
很多人一开始用工具,容易走两个极端。
一种是完全不用工具,什么都靠模型硬猜。让它解释最新 API,让它修项目里的测试,让它看一个本地文件夹,结果它根本没读到真实东西,只能一本正经地猜。
另一种是工具焦虑,什么任务都想叫插件。改一句话也叫,解释一段文本也叫,明明当前对话里就有足够信息,还要绕一圈外部系统。最后慢,吵,还容易误调用。
所以我现在会让 AI 先过三问法。
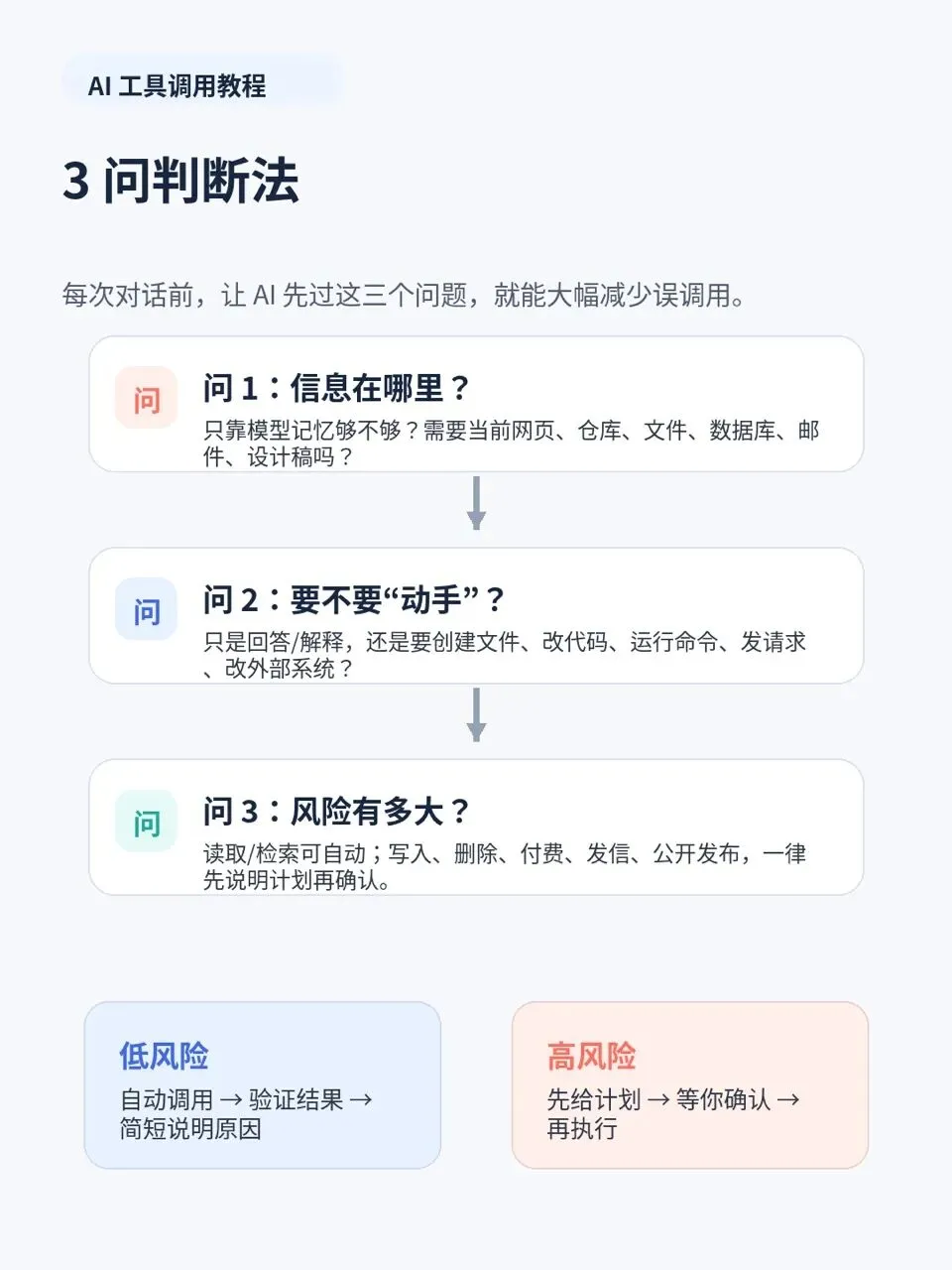
三问法可以直接这样用
• 信息在哪里,如果只靠当前对话和常识就够,不调用工具;如果需要网页、文件、仓库、数据库、邮件、设计稿,就要考虑工具。
• 要不要动手,如果只是解释和判断,可以先推理;如果要改文件、跑命令、生成图片、创建文档、调用外部系统,就要工具。
• 风险有多大,只读检索可以自动;写入、删除、付款、发信、公开发布、改权限、生产部署,必须先停下来说明计划。
你会发现,这三问比记插件名更重要。
因为插件名会变,产品入口会变,MCP 服务器也会变。但判断逻辑不会变。任何一个 AI 工具,只要它能访问外部系统,都绕不开这三件事。
新手优先用自动选择,但要让它说清楚
很多教程里会频繁写 @ 某个插件。这个没错,但它适合你已经很清楚工具库的时候。
如果你还不熟,我反而建议先用自动选择。不要每次自己纠结该叫哪个工具,先让 AI 判断,然后让它解释为什么。
这里关键不是对 AI 说你自己看着办。这个太空了。你要把自动选择的规则写出来。

这段话的价值,不在于它多高级。它只是把边界讲清楚。
AI 最怕的不是任务难,而是边界含糊。你说帮我处理一下,它就只能猜。你说哪些能自动、哪些要确认、哪些不能碰,它就有了一个判断器。
Skill 能不能自动触发,description 很关键
很多 Skill 不好用,不是因为流程写得不行,而是 description 写得太虚。
比如,帮助提升开发效率。用于处理代码问题。强大的文档助手。
这种描述人看了都不知道该什么时候用,AI 更难判断。
Skill 的 description 本质上是触发器。系统通常先把 Skill 的名字、description 和路径放到上下文里,模型觉得匹配,才会打开完整 SKILL.md。description 写不清,它可能根本不会加载。

写公众号排版 Skill 也是一样。
不要写,做公众号排版。
可以写,当用户要求把长文改写成微信公众号发布稿,并需要标题、导语、正文节奏、配图建议和移动端排版时使用;不要用于学术论文、短视频脚本或英文营销邮件。
一个好 Skill 至少写清这些
• 什么时候使用,触发词、任务类型、输入材料。
• 什么时候不要使用,排除场景越清楚,误触发越少。
• 第一步先做什么,先读文件、先跑测试、还是先确认目标。
• 过程中怎么验证,预览、测试、截图、事实核对、差异对比。
• 输出格式是什么,Markdown、PR、表格、Word、JSON、代码补丁。
• 风险边界是什么,哪些动作需要确认,哪些目录不能碰。
插件太多,不一定更强
这块我自己也踩过坑。工具装多了以后,会有一种错觉,好像能力突然变大了。
但工具太多也会带来副作用。上下文变挤,选择变难,误调用变多。尤其是 Skill 很多的时候,模型先看到的是一堆名字和 description,列表有预算限制,描述太多就会被压缩,极端情况下还会漏。
所以不要让 AI 背全家桶。
更稳的做法是拆工具箱
• 按任务拆,代码审查、测试修复、文档生成、前端还原、数据分析。
• 按系统拆,GitHub、Figma、Google Drive、本地终端、数据库。
• 按风险拆,只读工具、可写工具、生产环境工具、需要审批工具。
如果你维护的是一个团队 Agent 或自建 API 工具库,可以让模型先看到工具箱名称和高层描述,再按需加载具体工具。这个思路跟 tool search、命名空间、MCP server 分组很像。
普通人不一定要搭这么复杂,但思路要记住。工具不是越多越好,是越容易选对越好。
最容易翻车的,是半自动
我觉得很多人用 Codex 类工具出问题,不是因为完全没给权限,也不是因为完全放开权限,而是卡在一个很尴尬的半自动状态。
你嘴上说让它自己看着办,但它真正要读文件时,你又没告诉它可以读哪里。它想跑测试,你没有告诉它测试命令。它想改代码,你没有告诉它哪些目录别碰。它想调用外部工具,你又没说哪些动作需要先问你。
结果就是,每一步都像在猜。
最典型的例子,是你让它修一个 bug,却没有提供运行命令。它可能会凭经验改一段代码,然后说建议你运行测试。听起来挺负责,但这其实还没形成闭环。更好的方式,是从一开始就告诉它,安装用什么命令,测试用什么命令,lint 用什么命令,失败以后允许它重试几轮。
还有一种,是你让它写一篇基于最新资料的文章,却没说可以联网,也没说只能用官方来源。它就会在记忆里找,找不到就补。补出来的东西有时候很像真的,这才危险。
半自动最常见的三种失败
• 能读但不知道读哪里,最后读了一堆无关文件。
• 能改但不知道改到哪一步,最后顺手重构太多。
• 能查但不知道可信来源,最后把社区传闻写成确定事实。
所以自动调用不是一句授权。它更像一份工作说明书。你把路线、权限和验收写出来,它才能少猜。
几个真实任务里,AI 应该怎么选
我们拿几个场景讲,会更直观。
你说,项目里有一个测试挂了,帮我定位并修复。
这时候就不该只靠模型猜。正确路线应该是读仓库上下文,运行测试,看失败日志,修改最小范围代码,重跑测试,再总结改动。这里需要本地 shell、文件读写、测试修复 Skill。
你说,把这个 Figma 页面做成 React 组件。
这时候 Figma MCP 负责拿设计稿结构和资源,项目文件工具负责看现有组件规范,前端实现 Skill 负责落代码,浏览器预览工具负责截图验证。别让一个工具包打天下。
你说,写一篇 2026 版 MCP 入门教程。
这里涉及最新资料,就不能只靠模型记忆。应该先查官方文档或你提供的资料,再写结构,再做事实核对。凡是最新、价格、版本、政策、接口变化,都要有外部资料支撑。
你说,帮我看这封客户邮件,拟一个回复。
读取邮件可以用邮箱连接器自动做。但真正发送邮件,就属于影响外部系统,必须让你确认。
自动调用之后,还要复盘
工具调用最怕黑盒。它用没用对,你不知道;读了哪些范围,你不知道;结果够不够可靠,你也不知道。
所以我建议你给 AI 加一个很小的复盘要求。
这四行非常朴素,但很有用。
它会让自动调用从黑盒操作,变成可审计过程。你一眼就能看出它是不是过度调用、漏调、误调用。
安全边界一定要写死
一听自动调用,很多人第一反应就是怕 AI 乱改文件、乱发邮件、乱部署。这个担心是对的。
解决方式不是禁止所有工具,而是把权限分层。
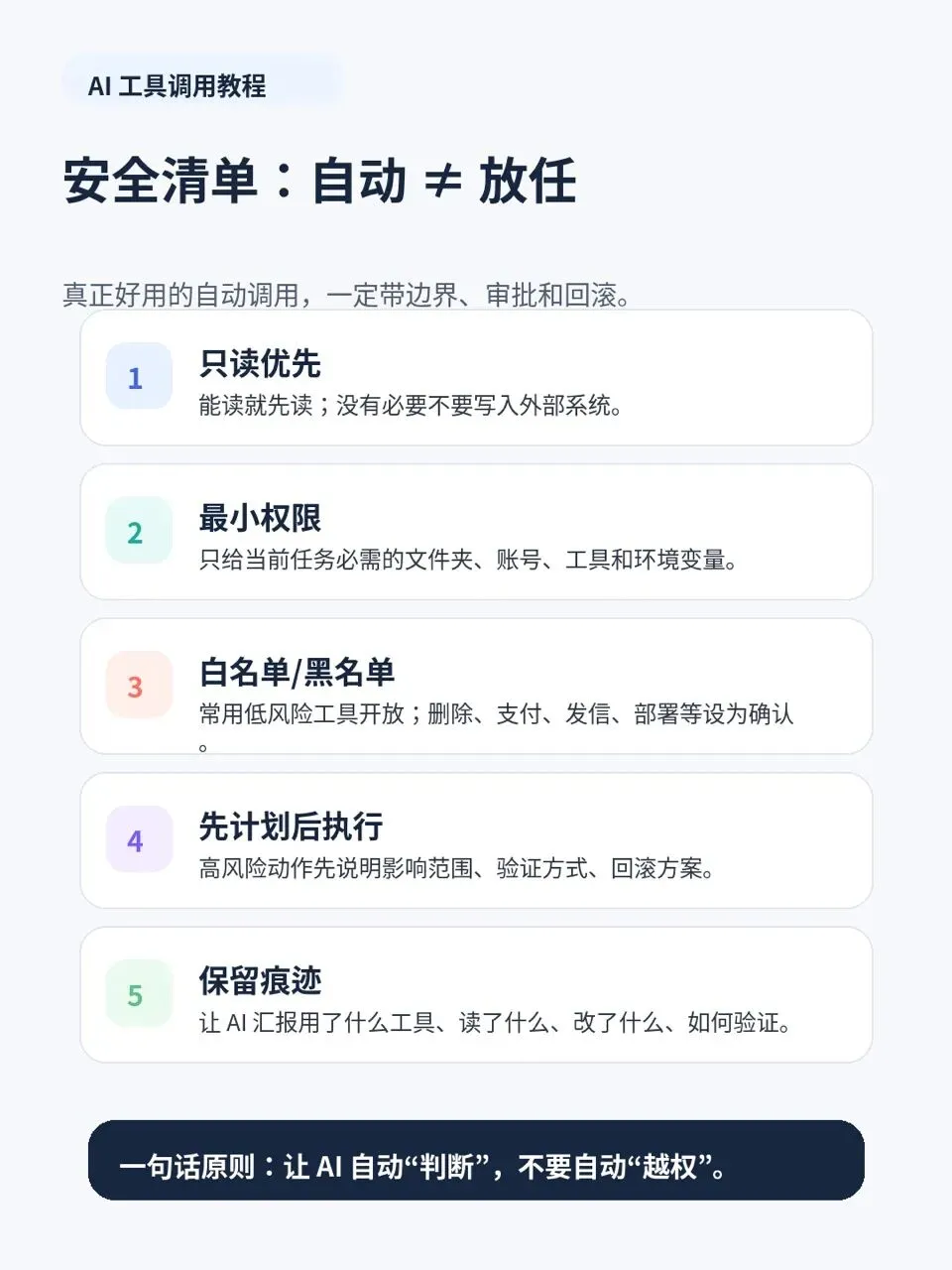
我会这样分
• 低风险,只读检索和分析,可以自动。比如读文档、查 issue、搜索网页、看日志。
• 中风险,本地可回滚写入,通常先说明计划。比如改代码、生成文件、重跑测试。
• 高风险,影响外部系统,必须确认。比如发邮件、改日历、创建 PR、写数据库。
• 极高风险,不可逆或生产影响,默认禁止或多重确认。比如删除数据、支付、生产部署、公开发布。
如果你只记住一句话,就是让 AI 自动判断,不要让 AI 自动越权。
还有一个反直觉的点,真正会用工具的人,也会很明确地告诉 AI 什么时候不要用工具。
比如你只是让它帮你判断一段话顺不顺,没必要联网。你只是让它解释一个已经贴出来的报错,没必要去读整个仓库。你在讨论一个还没定型的想法,也没必要马上创建文件。工具调用是有成本的,慢是一部分,更大的成本是它会把简单问题复杂化。
所以一个成熟的规则里,既要写可以自动调用什么,也要写什么场景下别调用。这个边界越清楚,AI 越像助手,而不是一个到处翻箱倒柜的实习生。
可以直接放进 AGENTS.md 的规则
下面这段规则,你可以放到 Codex 项目的 AGENTS.md、Cursor rules、Claude Code 项目说明,或者自己的常用提示词里。
最后,把这件事想成设计选择权
插件、Skills、MCP、Tool search,这些名词看起来很多,但底层逻辑很简单。
它们都是在给 AI 扩手脚。让它能看到更多信息,做更多动作,按照更稳定的流程工作。
但手脚多了,不代表人更聪明。真正决定体验的,是选择权怎么设计。
哪些事可以自动,哪些事要解释,哪些事必须等你点头,哪些事压根不该做。
这套边界写清楚以后,Codex 才真的会从一个聪明聊天框,变成一个可靠的工作搭子。
新手今天可以怎么开始
如果你现在还没自己的工具规则,不用上来就设计一套很大的体系。先从三个常用任务开始就行。
比如,你每天最常让 AI 做的是改代码、写文章、处理文档,那就先给这三个任务各写一段规则。改代码时可以读仓库、跑测试、生成补丁,但涉及删除数据、改环境变量、安装新依赖要先问。写文章时可以查官方资料、读取你给的素材、生成配图建议,但不能编造来源,不能把内部处理过程写进正文。处理文档时可以提取结构、改写格式、生成摘要,但不能主动上传或公开分享。
写完以后,找一个低风险任务试一次。不要一上来就让它改生产项目,也不要一上来就接公司邮箱。先让它读一个本地小项目,跑一个测试,修一个小问题。看它有没有说明用了什么工具,读了哪些文件,结果是否验证。
如果它做得不好,不要马上怪模型。先看 description 是不是太虚,权限边界是不是没写,验证命令是不是缺了。很多时候,问题不在 AI 不聪明,而在你没把工作台摆好。
