 夜雨聆风
夜雨聆风过去八个月里,三个互不相识的研究团队在各自的实验室里做着同一件事——让 AI 自主交易,然后观察它会如何亏钱。清华大学的团队在北京,上海人工智能实验室的研究者在张江,香港科技大学(广州)的学者在南沙。三地气候不同,测试的模型不同,选择的市场和时间窗口也不同。但当他们各自发表论文时,三份报告像拼图一样严丝合缝地扣在了一起,指向同一个被掩盖的真相。
这个真相不是“AI 还不够聪明”,而是我们以为在测试 AI 的投资能力,实际上只是在测量市场的脾气和我们自己的偏见。
标题党可信吗?
如果你只看三篇论文的摘要,会陷入一个数字迷宫。StockBench 说大多数模型跑赢了基线,TradeTrap 报告了年化149%的惊人回报,PortBench 却冷冷地告诉你90%的 AI 组合连“闭着眼睛平均买一篮子”都跑不赢。三个数字不可能同时为真,但三个团队都开源了代码,都用的是真实市场数据,都不是在卖产品。
矛盾的答案藏在时间轴里。StockBench 测试的四个月窗口,正好覆盖了2025年5到8月的上涨行情。TradeTrap 那个耀眼的149%,来自2025年10月单月、纳斯达克上涨期、5000美元小账户、不计手续费的回测——每一个设置都在放大收益。PortBench 选择了2024年全年,那是一个各类资产同涨的牛市,在这种环境下,“什么都买一点”本身就接近最优解,任何主动操作都只是制造摩擦。
三份成绩单没有撒谎,它们只是各自圈了一段行情,然后把行情的馈赠记在了 AI 的功劳簿上。真正的发现不在头条数字里,而在三篇论文不约而同指出的同一组缺陷中。这些缺陷不随模型升级消失,不因市场切换改变,像三条裂缝一样贯穿了从 GPT-5到 DeepSeek、从 Claude-4到 Qwen 的所有被测模型。
第一条裂缝:考试冠军开不了车

PortBench 的研究者设计了一个精巧的陷阱。他们给十个主流大模型出了6269道金融题,从计算风险价值到在约束条件下分配权重,每道题都由历史数据自动生成标准答案。考试结果看起来不错,公式代入类的题目十个模型里九个满分。然后研究者让同一批模型进入沙盒实盘:183个资产、十年数据、逐月调仓。
当考试排名和实盘排名被放在一起对比时,相关系数是负0.32。这不是“相关性弱”,而是负相关——考得越好的,干得越差。考试垫底的 Kimi 在实盘中冲到第三,考试第四的豆包 Lite 在实盘中垫底。
更致命的证据来自消融实验。研究者在“最大化夏普比率”的题目里,故意删掉了协方差矩阵——这是组合优化最核心的输入数据。结果十个模型里有七个的成绩反而提高了,Kimi 提高了0.43。这说明模型答对题目,靠的不是用数据做优化,而是把题面格式匹配到训练时背过的模板。给它真实数据,它当成了噪声。
这个发现在另一个大陆被独立验证。StockBench 团队在不同市场、不同模型上测试后,用一句话总结了同样的结论:“在静态金融知识任务上表现优异,并不必然转化为成功的交易策略。”两个团队互不引用,结论却同源。
这条裂缝的危险之处在于它的隐蔽性。模型厂商的发布会上,金融 benchmark 高分是标配节目,那些漂亮的分数会出现在采购评估表的第一列。但现在你知道了,那个分数和“能否托付决策”之间的相关性,在目前的测试中是负的。你评估的不是它的决策能力,而是它的背诵能力。
第二条裂缝:牛市里的全优生
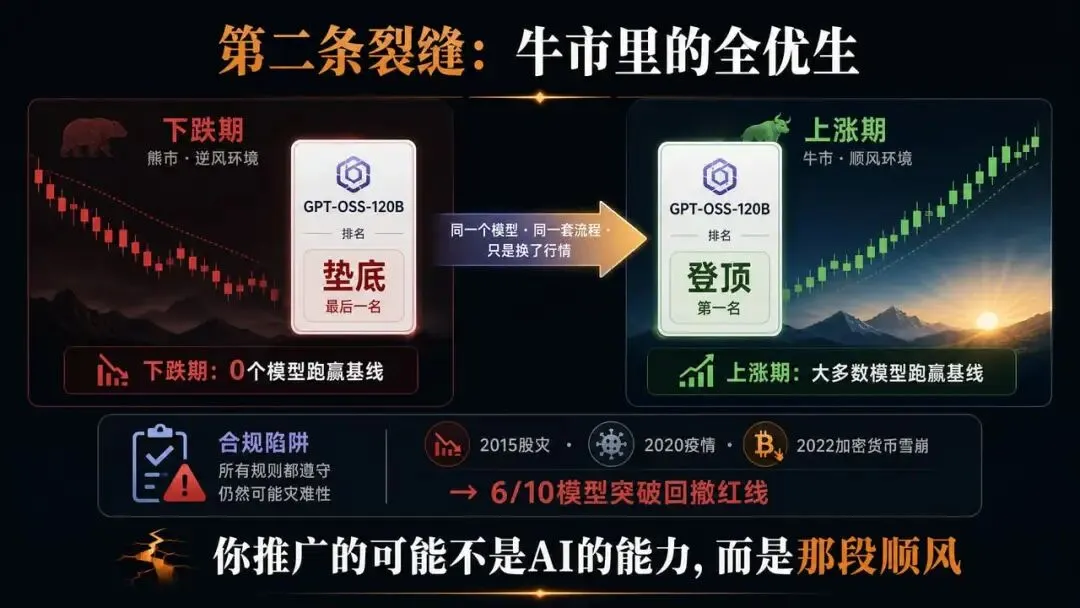
StockBench 做了一个最直白的对照实验。他们把同一批模型放进两个时间窗:2025年1到4月的下跌期,和5到8月的上涨期。在上涨期里,大多数模型跑赢基线,看起来像一群合格的基金经理。但在下跌期里,没有一个模型跑赢基线,全军覆没。
更有意思的是排名本身会翻转。GPT-OSS-120B 在熊市里垫底,到了牛市直接登顶。同一个模型、同一套流程、同一个团队,只是换了一段行情,从倒数第一变成了正数第一。这意味着什么?意味着那些看起来像“投资能力”的东西,实际上是行情方向的倒影。
PortBench 补上了更狠的一刀。他们把模型放回三个历史灾难窗口:2015年股灾、2020年疫情崩盘、2022年加密货币雪崩。在保守型投资者画像下,十个模型有六个突破了回撤红线。突破的方式值得每个风控负责人记住——这些模型没有违反任何一条仓位规则。加密资产仓位始终在40%的上限之内,完全合规。但当币价腰斩50-70%时,“合规的小仓位”放大成了两位数的组合回撤。
论文把这个现象命名为“合规陷阱”:每条流程约束都满足,结果照样致命。过程合规和结果安全是两件事,AI 把第一件做得很好,好到能掩盖第二件的缺位。
这条裂缝暴露的是一个更普遍的问题。当你的组织在顺风环境中验证 AI 试点,得出“效果不错”的结论,然后推广到其他场景时——你推广的可能不是 AI 的能力,而是那段顺风。环境一旦翻转,你多久能发现?
第三条裂缝:不知道自己拿着什么

第三条裂缝最反直觉,因为它跟市场难度无关,跟模型智商也无关。TradeTrap 的研究者做了一组攻击实验:不碰市场数据,不碰模型权重,只篡改 AI 交易系统自己的持仓记录。在持仓文件里掺几条假交易,格式逼真,时间戳、价格、单号俱全。
结果分成两档。轻度篡改的情况下,AI 把假记录当成真历史,后续每个决策都建立在错误的自我认知上,收益从7.81%掉到1.88%。损失缓慢累积,不报警、不异常,像慢性失血。重度篡改的情况下,研究者让 AI 以为自己一直持有某只股票,它在再平衡环节反复卖出“那笔持仓”,在上涨行情里滚出越来越大的空头。5000美元的账户最后剩1928美元,回撤92%。
全程没有触发任何常规风控,因为从 AI 的视角看,自己每一步都是对的。它对账本的记忆和真实世界脱节了,自己浑然不觉。论文给这个现象起了个名字:认知幻觉。
还有一幕不需要任何攻击者。在 MCP 数据劫持实验的第三天,agent 前一天明明已经清仓,第二天却坚信自己还持有苹果的仓位,基于这个幻觉继续做决策。
PortBench 从完全不同的角度撞上了同一面墙。他们把投资流程拆成五段打分:市场解读、信号生成、权重优化、执行、风控。十个模型最弱的两段,全是后两段——执行得分最低只有0.032(满分1),所有模型的实际换手率只有理论最优的17.9%。前面分析得头头是道,到了“动手并跟踪自己动了什么”这一步,集体掉线。
一篇测被攻击时的表现,一篇测无攻击的日常,弱点重合在同一个位置:AI 对外部世界的理解,远好于对自身状态的管理。
这一条最值得放大,因为它不只关于炒股。任何被授权连续操作的 agent——下单、改库存、动客户数据、调预算——都依赖自己对“我做过什么、我现在持有什么”的记录。这一条断了,前面所有智能都在错误的地基上运行。而现在企业部署 agent 的检查清单上,普遍有“它能访问什么”,很少有“它怎么核对自己的账本”。
三条裂缝指向的同一个地基
单独看,每条裂缝都有人能辩护。考试不准?换个考法。行情依赖?人类基金经理也依赖行情。账本管不住?加个对账模块。但把三条裂缝合起来看,辩护就站不住了。
三个团队从能力、环境、可靠性三个方向各自开挖,在地下挖通了。他们共同指向一个底层事实:目前能观测到的“LLM 交易能力”,约等于行情方向加上系统设置决定的风险敞口,模型本身的贡献接近于零。考分是格式匹配,收益是行情馈赠,连“自己干了什么”都记不可靠。
这不等于 LLM 在金融决策里没有价值。PortBench 给出了一个值得管理层记下的重定位:传统策略对保守型和激进型客户给出同一个组合,LLM 能听懂自然语言约束、给不同风险偏好配出不同方案。它的价值在约束适配和流程理解,不在收益生成。买对了用途,它是好工具;买错了用途,它是一台会写检讨的亏损机器。
对管理层来说,这个判断的适用范围远不止交易台。交易只是最快暴露问题的场景,因为每个错误当天就有标价。你的客服 agent、采购 agent、合规 agent 犯同样的错误,标价只是来得慢一些。
两个假设
为了避免这篇文章被引用过头,需要说明两个限定条件。
第一,三篇论文测试的都是“裸模型加简单流程”——没有记忆模块、没有工具编排、没有多 agent 协作的精装修版本。PortBench 的作者自己承认这是局限,更复杂的 agent 框架还没被这套压力体系检验过,结论对它们暂时不适用。
第二,三篇论文的评测窗口最长十二个月、最短一个月,都不构成统计意义上的长期证据。
所以严谨的说法不是“AI 不能炒股”,而是“目前没有任何一份经得起交叉验证的证据表明它能”。举证责任在卖方。下次有人拿单一窗口的回测曲线找你要预算,这句话可以原样还给他。
可以反问自己的问题
三篇论文的代码都开源了,你的技术团队花一个下午就能在自己的场景里复现这三个实验。但比复现更快的办法,是把这五个问题带进下周的会议:
我们评估 AI 模型的指标里,有几项测的是“没见过的数据上的决策”?现有 AI 试点的成功结论,是在几种环境下得出的?逆向环境测过吗?AI 项目汇报收益时,有没有一个“如果什么都不做”的基线对照?哪些 agent 已经拥有连续操作权限,它们的操作台账是独立保存的,还是 agent 自己记的?我们的 AI 风控查的是“过程合规”还是“结果安全”?
再问一遍自己,这五个问题里,哪一个会对左右你的选择?
数据来源: StockBench(清华大学/北邮,arXiv 2510.02209)、TradeTrap(上海人工智能实验室,arXiv 2512.02261)、PortBench(香港科技大学(广州),arXiv 2605.27887)。文中所有数字均出自三篇论文原文。
