 夜雨聆风
夜雨聆风
【前排提醒】本文全程无废话,原理用大白话讲,代码可直接复制跑通,建议先收藏再看,手撸的时候对着抄就行。
上周我在公司差点酸成柠檬精:我花了整整3小时翻行业网站、找竞品数据、整理三季度的业务对比,眼睛都快瞎了才拼出半篇周报,隔壁做后端的哥们摸了一上午鱼,快下班10分钟就交了完整的周报,还附了3份行业案例。
我凑过去问他是不是偷偷找了外包,他甩给我一段代码:「哪有那么麻烦,我自己写的AI Agent,输入「整理2024年Q3AIGC行业融资数据+3个典型案例,按周报结构排版」,5分钟就出结果了。」
相信很多人都有这种感受:普通大模型用起来总觉得「差点意思」——问最新的行业数据它瞎编,算个复杂数值它算错,让它整理本地文件它说不会。而AI Agent最近火到发烫,说白了就是解决了普通大模型「只会背书不会干活」的问题,今天咱们就从原理到手撸,彻底搞懂这个神器。
一、原理篇:AI Agent真的没你想的复杂
我见过很多人讲Agent上来就甩一堆术语:什么ReAct框架、Tool Use、感知行动闭环,新手直接看懵。其实你把AI Agent当成你雇的一个刚毕业的实习生就好,两者的逻辑完全一样:
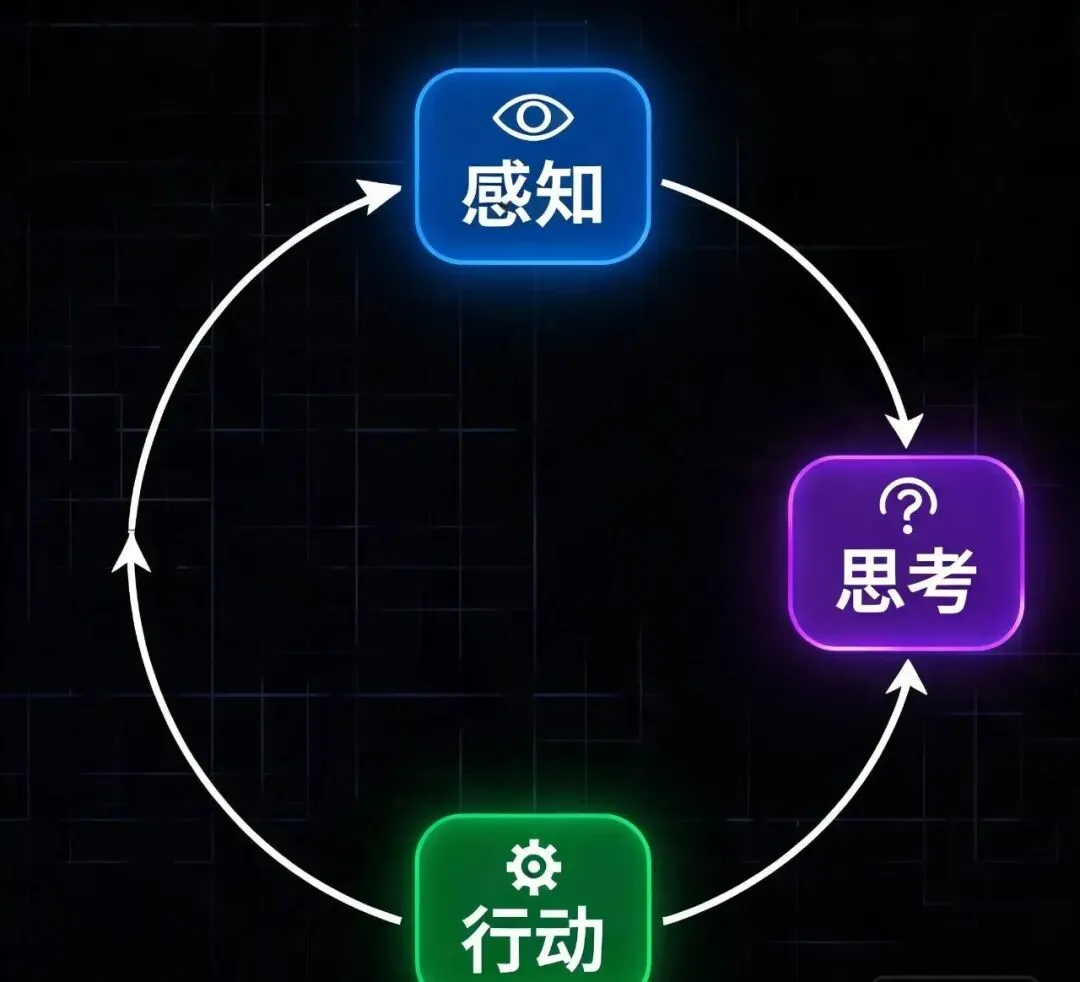
1. 核心逻辑:感知→思考→行动的循环
普通大模型就是没上过班的应届生:你问他什么他都只会用脑子里背过的知识答,不知道的就编,也不会用工具,让他算个账他能给你算错三次。
而AI Agent就是给这个应届生配了三样东西:
- 耳朵/眼睛(感知):能听懂你的需求,能看到工具返回的结果
- 脑子(思考):会判断「我现在有什么信息,还缺什么,下一步该干嘛」
- 手(行动):会用你给他配的工具,比如浏览器、计算器、文件阅读器
比如你让他做「2024年10月新能源汽车销量的平均值」这个任务,他的运行流程就是:
1. 感知:接收到你的需求,知道要找10月的销量数据,还要算平均
2. 思考:我脑子里的知识截止到2024年初,没有最新的10月数据,得用搜索工具搜
3. 行动:调用搜索工具,输入关键词「2024年10月新能源汽车销量排名」
4. 再感知:拿到搜索结果,看到前3名的销量分别是28万、21万、17万
5. 再思考:现在有数据了,需要计算三个数的平均值,得用计算器工具
6. 再行动:调用计算器,输入(28+21+17)/3
7. 再感知:拿到计算器返回的结果22万
8. 再思考:所有信息都齐了,可以回答用户了
9. 最终输出结果
你看,整个过程和人干活的逻辑一模一样,就是「想→做→看结果→再想→再做」的循环,没有任何高大上的东西。
2. 大家常说的ReAct模式是什么?
就是刚才这个循环的缩写:Re(Reason思考)+ Act(Action行动),说白了就是「走一步想一步」,每做一个行动之前先想清楚为啥要做,做完拿到结果再想下一步干啥,直到把活干完,就这么简单。
3. Tool Use(工具调用)是啥?
就是你给实习生配的工具箱,你提前列个清单告诉Agent:每个工具叫啥、能干啥、要传什么参数就行。比如:
> 搜索工具:可以查询2023年之后的所有公开互联网信息,入参是你要搜索的关键词
> 计算器工具:可以进行加减乘除的数值计算,入参是你要计算的数学表达式
Agent比你想的聪明得多,只要你把工具的功能说清楚,它自己就知道什么时候该用什么工具,完全不用你教。
现在你搞懂了吧?Agent和普通大模型的核心区别就是:普通大模型是「一锤子买卖」,给输入直接出输出,错了也不会改;而Agent是「会干活的助手」,会自己找工具、会调整、会迭代,直到把你的问题解决。
二、实战篇:手撸一个能联网+计算的Agent
咱们今天写的这个Agent非常简单,100多行代码就能跑通,实现两个核心功能:
1. 遇到不知道的最新信息,自动联网搜索
2. 遇到数值计算,自动调用计算器
3. 完全按照ReAct循环运行,直到给出正确答案
前置准备
你只需要有这两个东西就行:
- Python 3.8+版本
- 任意一个支持OpenAI兼容格式的大模型API Key(现在几乎所有主流大模型都支持)
- 可选:第三方搜索API的Key(没有的话我们先给模拟搜索结果,照样能跑通)
第一步先装依赖:
pip install requests python-dotenv regex然后在项目根目录建一个.env文件,填你的API信息:
# 大模型API配置,换成你自己的LLM_API_KEY = "你的大模型API Key"LLM_BASE_URL = "大模型的请求地址,一般是/v1/chat/completions"LLM_MODEL_NAME = "你要调用的模型名称"# 搜索API配置(可选,先用模拟的也可以)SEARCH_API_KEY = "你的搜索API Key"完整代码实现
直接复制下面的代码就行,关键步骤我都加了注释:
import osimport reimport requestsfrom dotenv import load_dotenv# 加载环境变量load_dotenv()LLM_API_KEY = os.getenv("LLM_API_KEY")LLM_BASE_URL = os.getenv("LLM_BASE_URL")LLM_MODEL_NAME = os.getenv("LLM_MODEL_NAME")SEARCH_API_KEY = os.getenv("SEARCH_API_KEY")# -------------------------- 1. 定义工具函数 --------------------------def search_tool(query: str) -> str: """联网搜索工具,入参是搜索关键词,返回搜索结果""" # 如果你没有搜索API,先用这个模拟结果测试,后面可以换成真实的搜索请求 mock_result = { "2024年10月新能源汽车销量排名": "2024年10月国内新能源汽车销量前三分别是:品牌A 28万辆,品牌B 21万辆,品牌C 17万辆", "2024年Q3 AIGC行业融资数据": "2024年Q3国内AIGC行业共发生融资42笔,总金额118亿元,其中多模态大模型赛道占比60%", } if query in mock_result: return mock_result[query] # 下面是真实搜索API的调用代码,有搜索API的可以放开注释用 # url = "第三方搜索API的请求地址" # headers = {"X-API-KEY": SEARCH_API_KEY, "Content-Type": "application/json"} # data = {"q": query, "num": 3} # response = requests.post(url, headers=headers, json=data) # results = response.json().get("organic", []) # return "\n".join([f"标题:{item['title']} 内容:{item['snippet']}" for item in results[:3]])def calculator_tool(expression: str) -> str: """计算器工具,入参是数学表达式,返回计算结果""" try: # 演示用,生产环境不要直接用eval,会有安全问题 result = eval(expression) return f"计算结果:{result}" except Exception as e: return f"计算出错:{str(e)}"# 工具列表,新增工具只要在这里加就行TOOLS = { "search": search_tool, "calculator": calculator_tool}# 工具描述,告诉大模型每个工具的作用和参数TOOLS_DESC = """1. search:联网搜索工具,用来查询你不知道的最新信息、实时数据、新闻事件,参数是你要搜索的关键词2. calculator:计算器工具,用来进行数学计算,参数是你要计算的数学表达式,比如(28+21+17)/3"""# -------------------------- 2. 大模型调用函数 --------------------------def call_llm(prompt: str) -> str: """调用大模型API,返回模型输出""" headers = { "Authorization": f"Bearer {LLM_API_KEY}", "Content-Type": "application/json" } data = { "model": LLM_MODEL_NAME, "temperature": 0, # 温度设为0,减少模型瞎编的概率 "messages": [ {"role": "system", "content": f"""你是一个会使用工具的智能助手,必须严格按照以下规则处理用户问题:1. 首先思考你当前有什么信息,是否需要调用工具,如果没有足够的信息就调用对应的工具2. 输出格式必须严格遵守以下要求,不能多输出任何其他内容: - 思考内容必须用<think>标签包裹,比如<think>我现在需要搜索2024年10月的销量数据</think> - 如果需要调用工具,必须用<tool>工具名</tool><params>参数</params>的格式,一次只能调用一个工具 - 如果已经有足够的信息回答用户,必须用<answer>最终回答内容</answer>的格式3. 你可以使用的工具列表如下:{TOOLS_DESC} """}, {"role": "user", "content": prompt} ] } response = requests.post(LLM_BASE_URL, headers=headers, json=data) return response.json()["choices"][0]["message"]["content"]# -------------------------- 3. ReAct循环核心逻辑 --------------------------def run_agent(user_query: str, max_rounds: int = 5) -> str: """ Agent主运行逻辑 :param user_query: 用户的问题 :param max_rounds: 最大循环次数,避免无限调用工具 :return: 最终回答 """ current_prompt = user_query for i in range(max_rounds): print(f"===== 第 {i+1} 轮交互 =====") # 调用大模型拿到输出 llm_output = call_llm(current_prompt) print(f"大模型输出:{llm_output}\n") # 匹配是否有最终回答 answer_match = re.search(r"<answer>(.*?)</answer>", llm_output, re.S) if answer_match: return answer_match.group(1).strip() # 匹配思考内容(可选,打印出来看Agent的思考过程) think_match = re.search(r"<think>(.*?)</think>", llm_output, re.S) if think_match: print(f"Agent思考:{think_match.group(1).strip()}\n") # 匹配要调用的工具和参数 tool_match = re.search(r"<tool>(.*?)</tool>", llm_output, re.S) params_match = re.search(r"<params>(.*?)</params>", llm_output, re.S) if not tool_match or not params_match: return "大模型输出格式错误,请重试" tool_name = tool_match.group(1).strip() tool_params = params_match.group(1).strip() # 调用对应的工具 if tool_name not in TOOLS: current_prompt += f"\n你调用的工具{tool_name}不存在,请重新选择工具" continue print(f"调用工具:{tool_name},参数:{tool_params}\n") tool_result = TOOLS[tool_name](tool_params) print(f"工具返回结果:{tool_result}\n") # 把工具返回的结果加到prompt里,让大模型继续处理 current_prompt += f"\n你调用了{tool_name}工具,参数是{tool_params},返回结果是:{tool_result},请继续处理用户的问题" return "已超过最大调用次数,无法完成任务"# -------------------------- 4. 测试Agent --------------------------if __name__ == "__main__": query = "2024年10月新能源汽车销量排名前3的品牌销量分别是多少?计算它们的平均销量" result = run_agent(query) print(f"===== 最终回答 =====\n{result}")运行效果
你直接运行这段代码,就能看到类似下面的输出:
===== 第 1 轮交互 =====大模型输出:<think>用户需要2024年10月的新能源销量数据,这个是最新信息,我没有,需要调用search工具搜索</think><tool>search</tool><params>2024年10月新能源汽车销量排名</params>Agent思考:用户需要2024年10月的新能源销量数据,这个是最新信息,我没有,需要调用search工具搜索调用工具:search,参数:2024年10月新能源汽车销量排名工具返回结果:2024年10月国内新能源汽车销量前三分别是:品牌A 28万辆,品牌B 21万辆,品牌C 17万辆===== 第 2 轮交互 =====大模型输出:<think>现在已经拿到了三个品牌的销量,需要计算平均值,调用calculator工具</think><tool>calculator</tool><params>(28+21+17)/3</params>Agent思考:现在已经拿到了三个品牌的销量,需要计算平均值,调用calculator工具调用工具:calculator,参数:(28+21+17)/3工具返回结果:计算结果:22.0===== 第 3 轮交互 =====大模型输出:<answer>2024年10月新能源汽车销量前三的品牌分别是品牌A(28万辆)、品牌B(21万辆)、品牌C(17万辆),三者的平均销量是22万辆。</answer>===== 最终回答 =====2024年10月新能源汽车销量前三的品牌分别是品牌A(28万辆)、品牌B(21万辆)、品牌C(17万辆),三者的平均销量是22万辆。你看,整个过程Agent完全自己判断该用什么工具,自己处理返回结果,最后给出正确答案,是不是非常香?
三、进阶篇:Agent还能怎么变强?
刚才我们写的是一个最简版的Agent,如果你想让它变得更厉害,可以加这三个核心能力:
1. 多工具组合
现在我们只有搜索和计算器两个工具,你可以随便加新工具,只要按照「写工具函数+加工具描述」的步骤来就行,比如:
- 加个读取本地PDF的工具:让Agent帮你整理简历、论文里的信息
- 加个发邮件的工具:让Agent写完周报直接给领导发过去
- 加个查询数据库的工具:让Agent帮你查业务数据,不用你写SQL
- 加个写代码的工具:让Agent写完代码直接运行调试
Agent会自动判断什么时候用什么工具,哪怕你加十几个工具,它也不会搞混。
2. 记忆能力
现在的Agent是「单次失忆型」,这次对话完就忘了你是谁,你可以给它加记忆模块:
- 短期记忆:把历史对话都存在一个列表里,每次请求都带给大模型,这样你上次说过你是做运营的,下次它整理资料就会自动按运营的视角来
- 长期记忆:用向量数据库存你过去和Agent的所有对话、上传的所有文档,需要的时候检索相关信息,比如你半年前上传过一份行业报告,现在问它相关的问题,它能自动把报告里的内容找出来用
3. 规划能力
现在的Agent是「走一步看一步」,遇到复杂任务比如「写一份10页的行业分析报告」就容易乱,你可以给它加规划模块:
先让Agent把任务拆成3-5个步骤,比如:
1. 搜索2024年AIGC行业的整体市场规模
2. 搜索3个头部公司的核心产品和市场份额
3. 搜索行业面临的政策风险和技术瓶颈
4. 汇总所有信息,按照报告结构排版
然后Agent按照步骤一步步执行,遇到问题还能自动调整步骤,就像人做项目先写Todo List一样,复杂任务的完成率会高很多。
接入大模型的小Tips
如果你觉得自己写的Agent经常犯傻,大概率是这两个问题:
1. 大模型能力太弱:换个能力强一点的大模型,尤其是支持原生函数调用的,格式输出会准很多
2. Prompt写得太松:把规则写得越严格越好,比如明确要求「必须用
总结&行动建议
核心概念回顾
今天讲的三个Agent核心点,你记住就不算白看:
1. ReAct循环:Agent的核心运行逻辑,就是「思考→调用工具→看结果→再思考」的循环,和人干活一模一样
2. Tool Use机制:是Agent突破大模型知识边界的核心,你给它配多少工具,它就能干多少活
3. 感知行动闭环:Agent不是一次性输出结果,而是会根据工具的返回动态调整行为,直到完成任务
下一步行动建议
我知道很多人看完文章就收藏吃灰,今天给你三个非常容易落地的行动,今天就能做完:
1. 先跑通代码:花10分钟把上面的代码复制到本地,填上你自己的大模型API Key,测试3个不同的问题,看看Agent的运行过程
2. 加一个新工具:比如你经常需要查天气,就写个调用天气API的工具,加到Agent的工具列表里,测试一下能不能正常调用
3. 改个小需求:比如把Agent改成你的周报素材助手,专门用来搜索行业数据和案例,以后找素材的活都让它干
如果你跑通了代码,或者加了好玩的工具,欢迎在评论区晒出你的成果,有问题也可以留言,我会一一解答~
(本文首发于我的技术公众号,每周更新AI实战干货,欢迎关注)
