 夜雨聆风
夜雨聆风【AI数智工厂】千万份工业文档,正在被连成一张网
机器可以复制,但经验很难复制。而知识图谱,正在把"经验"变成可以复制的东西。
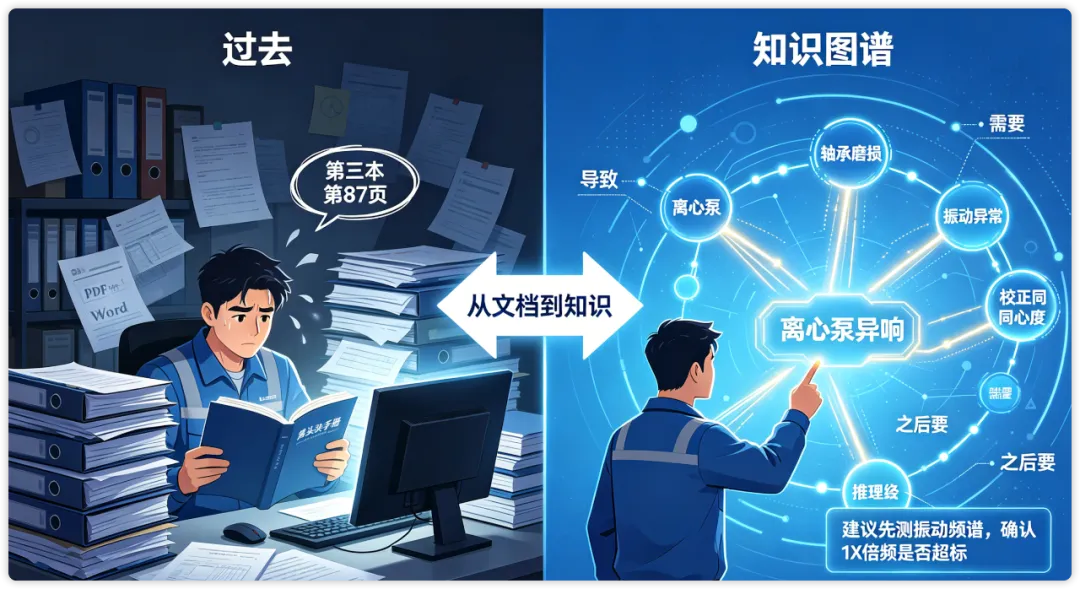
01 "第三本第87页"
小李进厂第三个月,第一次独立处理设备故障。
一台离心泵异响,他按照培训课上学的流程,先查设备台账,再翻维修手册,最后打开那个存着历年故障记录的共享文件夹。
一搜,出来三百多份文档。
PDF、Word、Excel、扫描件,乱七八糟地堆在文件夹里。有的文件名是"新建文本文档(2).txt",有的是"2018年维修记录-张工.pdf"。
他花了四十分钟,终于在一本扫描版的维修手册里找到了类似案例。
第三本,第87页。
页面上是老师傅十年前手写的批注:"此种异响多因轴承间隙过大,更换后需重新校正同心度。——老周,2014.3"
小李照着做了。故障排除了。
但他心里清楚:如果老周当年没写这句批注,他根本不知道从哪下手。
而老周,下个月退休。
02 那些没被写下来的东西,才是最贵的
制造业有一个长期被忽视的痛点:知识断层。
不是没文档。恰恰相反,大部分工厂的文档堆积如山——操作规程、维修手册、故障记录、应急预案、培训材料,少说也有几十万字、几千份文件。
问题是,这些文档是"死的"。
它们躺在文件夹里,彼此之间没有联系。你搜"离心泵异响",搜出来三百份文档,却没法告诉你:异响和轴承间隙有关,轴承间隙和润滑周期有关,润滑周期和设备负荷有关。
这些关系,只存在于老周的脑子里。
老周在厂里干了二十七年。他知道3号压缩机的脾气——天气一潮就容易跳闸;他知道反应釜的搅拌电机每年入冬前必须换一次密封圈;他知道某个阀门的手感不对,八成是执行器里的弹簧疲劳了。
这些东西,叫隐性知识。
不会写进任何手册,不会出现在培训PPT里。老周也说不清自己是怎么判断的,它就是日积月累,长在了他的肌肉记忆里。
然后,老周退休了。
那些知识,跟着一起走了。
03 一张网,怎么把"文档"变成"知识"
后来我在另一家电厂,看到了不一样的做法。
他们的设备档案室里没有堆积如山的纸质文件夹。取而代之的,是一个知识图谱系统。
先别被这个名字吓到。它的原理,说出来并不复杂。
想象你在白板上画一张工厂的关系图——用圆圈代表各种事物,用箭头代表它们之间的联系:
• 轴承磨损→ 导致 →振动异常• 振动异常→ 需要 →更换轴承• 更换轴承→ 之后要 →校正同心度• 3号压缩机→ 属于 →C车间• 老周→ 擅长维修 →离心泵
在知识图谱里,每一个圆圈叫做**"实体"(Entity),每一条箭头叫做"关系"**(Relation)。
一个实体、一个关系、另一个实体,三者拼在一起,就叫一个**"三元组"**。这是知识图谱里最基础的积木块。
把成千上万个三元组拼起来,就织成了一张巨大的网。千万份文档,被拆成亿万个知识片段,重新组合,彼此连接。
这时候,奇迹发生了。
你问系统:"离心泵异响怎么办?"
它不会给你三百份文档让你自己翻。它会沿着图谱里的关系链,一步步推理:
"异响可能由三种原因导致:轴承间隙过大(概率45%)、叶轮不平衡(概率30%)、汽蚀(概率25%)。其中轴承间隙过大,最常见于运行超过8000小时的设备,建议先测振动频谱,确认1X倍频是否超标。——参考案例12条,涉及3号泵、7号泵、2019年大修记录。"
答案不是搜出来的,是推理出来的。
就像老周站在旁边,把自己二十七年的经验,一条一条说给你听。
04 这和翻文件夹,到底差在哪?
为了理解这件事的价值,我们把它和小李的遭遇做个对比:
| 存了什么 | ||
| 怎么查 | ||
| 知识状态 | ||
| 隐性知识 | ||
| 小李的体验 |
最本质的差别在于:文件夹存的是"信息",图谱存的是"知识"。
信息是零散的、孤立的。知识是连接的、有因果的。
文件夹告诉你"这里有一份关于轴承的手册"。图谱告诉你"轴承磨损会导致振动异常,振动异常需要更换轴承,更换轴承之后必须校正同心度"。
前者是堆砌,后者是脉络。
05 这张网,是怎么建出来的?
说点实际的。如果一家工厂想建自己的知识图谱,要怎么做?
我把它拆成四步——
第一步:把文档"搬"进系统
把厂里所有能数字化的资料都收集起来:操作规程、维修手册、故障记录、培训材料、历史工单,甚至老师傅的口述录音。全部扫描、识别、入库。
这是地基。没有数据,后面都是空谈。
第二步:从字里行间"抽"知识
用自然语言处理技术,从非结构化的文本里自动提取实体和关系。
比如原文是:"压缩机振动过大通常由轴承磨损引起,需要及时更换并重新校正同心度。"
系统会从中抽出:
• 实体:压缩机、振动过大、轴承磨损、更换、校正同心度 • 关系:引起、需要
当然,自动抽取不可能百分之百准确。所以还需要人工审核,特别是那些老师傅才有的"隐性知识",机器读不出来,需要人手动补进去。
第三步:把"同名不同义"的东西对齐
不同文档里,同一个东西可能有不同叫法:
• "离心泵"、"循环泵"、"P-101" → 可能是同一台设备 • "异响"、"噪音"、"异常声响" → 可能是同一种故障
这一步要把它们统一,避免图谱里把同一个东西当成两个东西。
第四步:让图谱"跑"起来
把清洗好的三元组存入图数据库,然后就可以开始用了:
• 查询:"3号压缩机常见故障有哪些?" • 推理:如果A导致B,B需要C,那么A发生时应准备C • 推荐:基于相似性推荐历史案例 • 预警:发现异常模式时主动推送
到了这一步,图谱才算真正"活"了。
06 老师傅退休了,但他的经验留了下来
那家电厂的老师傅姓王,大家都叫他王工。
王工退休前,被设备部拉去做了整整两个月的"知识提取"。不是让他写文档——文档他写了半辈子,够多了。而是让他坐在系统前面,对着图谱说:"这个和那个,是有关联的。"
"反应器超温,不一定只是冷却问题。先查进料流量,流量波动才是根因。"
"压缩机振动大,别急着拆轴承。先摸一摸联轴器护罩的温度,如果明显偏高,八成是对中出了问题。"
"这个阀门,冬天和夏天的故障模式完全不一样。冬天是冻凝,夏天是密封老化。"
每一条经验,被编码成图谱里的一条边。
王工退休那天,在欢送会上说了一句话:
"我以前最怕的,就是我这辈子摔过的跤、吃过的亏,后来的人还得再摔一遍。现在好了,我把跤都标在地图上了,你们绕开走。"
那张地图,就是知识图谱。
07 这张网,每天都在自己长厚
知识图谱最厉害的地方,不是它能把文档连起来。
是它自己能学习。
每一次故障处理,都是一次喂给图谱的"养料"。
• 小李按照图谱的建议,换了离心泵的轴承,故障排除了。他点了一个"有效",系统记住:这条路径是对的。 • 小李又遇到一台泵,按图谱建议操作后没解决问题。他补充了一条新的经验:"此种异响在变频运行模式下,还需检查谐波干扰。"系统记住了这个新场景,下次再有人问,答案会更完整。 • 三个月后的月度分析,系统发现"3号生产线"的某类故障频率明显高于其他产线。它自动标注了一个异常节点,推送给设备主管。
每一次故障的解决,都在让图谱变得更聪明。
它不是静态的数据库,而是一个活的、会生长的知识体。
老周的经验,王工的直觉,小李的新发现——全部沉淀在里面,越积越厚。
08 对工厂来说,这意味着什么?
说点实际的。
维修效率提升了。
过去处理一个复杂故障,平均要翻十几份文档,打三四个电话问人,折腾两三个小时才能定位根因。现在,打开图谱,五分钟拿到完整推理链。维修时间缩短,停机损失减少。
新员工培训变快了。
过去一个新维修工要独立上手,得跟着老师傅混半年,把该摔的跤都摔一遍。现在,他面对设备时,图谱就是他的"随身老师傅"。三个月,基本能处理常见故障。
知识不再依赖个人。
老师傅退休了,经验不会消失。它被编码进了图谱,留了下来。谁都可以调用,谁都可以补充。
决策有依据了。
设备该修还是该换?备件库存该加还是该减?产线改造先动哪一段?图谱里的历史数据和关联关系,能给出一个有迹可循的答案,而不是靠"我觉得"。
09 写在最后
有人说,制造业的下一场革命,不是机器人,是知识管理。
我越来越觉得这句话是对的。
机器可以复制,产线可以扩建,但一个老师傅脑子里二十七年的经验,没法复制。
而知识图谱,正在把"经验"变成可以复制的东西。
千万份文档,正在被连成一张网。每一个节点,都是一个知识片段。每一条边,都是一段因果关系。
当这张网足够密,工厂里就再也不需要有人记得"第三本第87页"了。
答案,会自己找到你。
就像王工还在你身边。
你们厂有老师傅退休过吗?那些没被写下来的经验,后来怎么样了?欢迎在评论区聊聊你见过的最痛的一次"知识断层"。
