 夜雨聆风
夜雨聆风摘要:GPU 功耗墙从 100% 降到 80%,性能未必明显掉。能效曲线、power cap 和负载差异决定电费账。
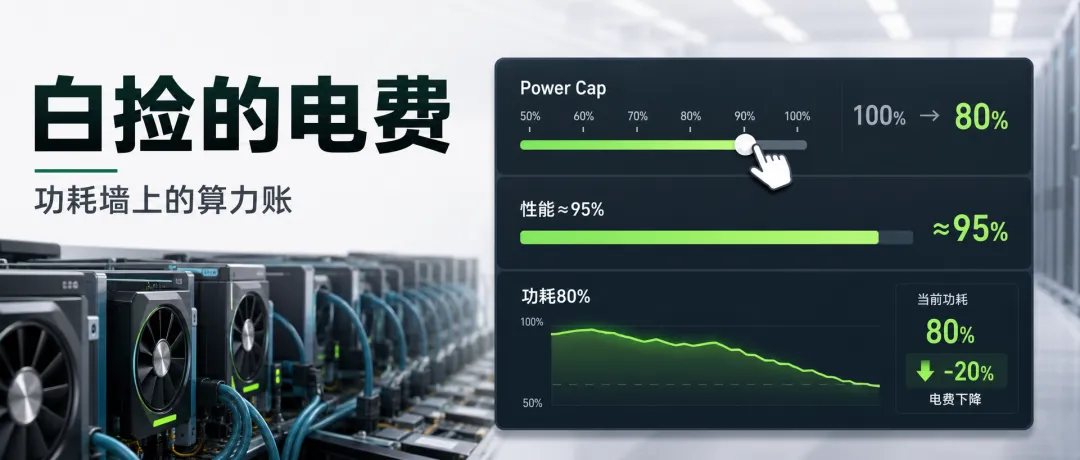
从一次"调慢却没变慢"的实验说起
水冷上线那阵子,我做过一个很简单的实验。
挑了一张正在跑训练的卡,把它的功耗墙——也就是允许的最大功耗——从出厂的 100% 一路往下压。压到 90%,训练曲线没什么变化;压到 80%,我盯着每一步的耗时看了好久,几乎感觉不出来变慢。可机柜的电表明显转慢了,那张卡的进出水温差也小了一截,芯片读数凉了好几度。
这就有点反常识了。功耗少了十几个百分点,活儿干得几乎一样快,电费和热量却实打实地降了。那少烧的那部分电,本来是花在哪儿的?
第一篇里我把这件事记成了"账二"的一半:**降功耗,几乎是一顿白捡的午餐。**当时只用一句话带过,这一篇就专门把它讲透——这笔"白捡的电费"到底从哪来,以及更要紧的:知道了这个道理之后,一座 AI 机房该怎么花自己的功耗预算。
先说清楚边界。这里先谈"能效曲线长什么样、功耗策略为什么这么定";至于推理怎么抢占训练、容器之间怎么协作、功耗墙具体由谁实时去拧,那是后面几篇的事。先把"为什么"立住,后面再谈"怎么做"。
第一层:功耗和性能,根本不是一条直线
很多人下意识觉得,功耗和性能是成正比的:多给一成电,就多干一成活。如果真是这样,那压功耗就是纯亏,白捡的午餐根本不存在。
可芯片不是这么工作的。数字电路的动态功耗,大致正比于"电压的平方乘以频率",写成公式就是 P ∝ V²·f。频率越高,需要的电压也越高,而功耗对电压是平方级的敏感。这就埋下了一个很别扭的结构:你想再往上抠出那么几十、上百兆赫兹的频率,得同时把电压抬上去,于是功耗不是线性涨,而是被电压的平方狠狠放大。
后果就是:功耗曲线最顶端那一段,边际收益极差。
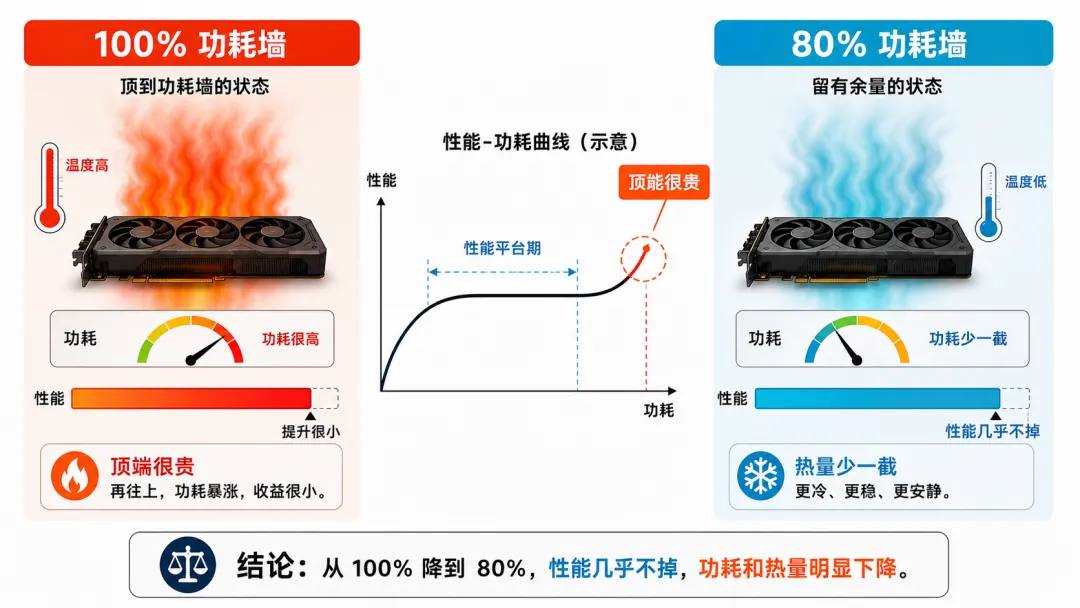
打个比方,这就像开车:时速从 60 提到 90,油耗涨得有限;可你想从 110 再榨到 130,风阻是平方级往上涨的,油门得踩到底,油耗陡增,时间却没省下多少。芯片冲高频和汽车冲高速,是同一种"越到顶越费"的曲线。
厂商为什么偏偏把卡默认设在这条曲线的最顶端?因为出厂规格、跑分榜、发布会上的那串数字,比能效更好卖。把电压和功耗灌到不成比例,只为多换那一点点频率,在营销上是划算的;但对一台买来干活、而不是刷榜的卡,这笔账完全不成立。你买到手的"100% 功耗",很多时候就站在收益最差的位置上——而且没人拦着你走下来,厂商也留好了功耗墙这个旋钮让你自己调。
我那次实验的数字,其实和业界被反复引用的实测直觉对得上。游戏卡领域有个很经典的例子:同一张卡在同一个场景,功耗墙 100% 时跑 42 帧、烧掉约 570 瓦;把功耗墙拖到 80%,帧数只掉到 40 帧(差不多 -5%),功耗却降到约 480 瓦(降了将近 16%)。深度学习这边的研究结论也类似——给训练任务做功耗封顶,常常能省下约 15% 的能耗,而训练时间只多出一点点。
把这个边际递减用一张表摆出来,直觉就很清楚了:
注意最右边那一列:功耗往下压,每一瓦电换来的性能反而越来越高。从 100% 到 80%,性能只让出了约 5 个点,能效却抬了快两成。那让出去的功耗去哪了?在 100% 那一档,它基本是白白烧成了热——既花了你的电费,又反过来给散热系统添了一份要带走的负担。
如果把"顶端这段电花得值不值"画成饼,大概是这样一个刺眼的比例:
最后那 20% 的功耗,只买到了大约 5% 的性能。对一台拿来跑生产的机器,这部分支出几乎是纯亏。而且它亏的还不止电费——多出来的热,正是上一段说的、要散热系统额外去对付的那份。降功耗的同时顺手降了温,也就顺带护了寿命(高温怎么折寿,前面两篇已经算过账,这里不再展开),这是同一个动作捎带的好处。
所以"白捡的电费"不是玄学:它是芯片功耗-频率曲线的形状,本来就给你留了一段几乎免费的下调空间。问题只是,你愿不愿意从那个最难看的顶端走下来。
第二层:压功耗有两种工具,一把钝器,一把手术刀
知道了顶端那段电不值,接下来就是怎么把它省掉。这里有两种思路,得分清楚,因为它们的代价完全不同。
第一种是功耗墙(power cap)。它简单粗暴:直接给整张卡的最大功耗设一个上限,卡自己会在这个上限内动态调整频率和电压。你不用关心曲线长什么样,只要说一句"最多烧到 X 瓦",剩下的交给硬件。它是一把钝器,但钝得可靠——一行命令、一个数值,即时生效,几乎没有翻车风险。NVIDIA 的卡上,它就是一个标准接口:读得到这张卡允许的功耗下限和上限,再写一个目标值进去,卡立刻照办。我那次实验拧的就是它,后面那套守护进程调的也是它。
第二种是降压(undervolting)。它精细得多:不动频率上限,而是去改"电压-频率曲线"本身,让卡在跑同一个频率时用更低的电压。因为功耗对电压是平方级敏感,电压降一点,功耗和发热就降一大块;运气好时,省下来的热裕量还能让卡把频率冲得更高,出现"既降功耗又不掉、甚至略涨性能"的局面。它是一把手术刀。
代价也在这把手术刀上。每一颗芯片的体质都不一样——同型号、同批次,有的能在很低的电压下稳定,有的稍微一降就崩,这就是常说的"硅片彩票(silicon lottery)"。所以降压没法一套参数全机房通刷,得一张卡一张卡地试,还要长时间压力测试去验证稳定性。一旦电压给得过激,表现不是直接报错,而是偶发的计算出错或者随机崩溃,排查起来非常折磨。
两者的取舍,摊开看更清楚:
我的选型直觉很简单:**要省心、要稳、要能批量统一管理,用功耗墙;要把能效压到极致、且愿意为单卡花调试时间,再上降压。**对一座几十上百张卡、还要靠程序自动调节的机房来说,功耗墙是默认答案——它可编程、可即时回调、对每张卡行为一致,天生适合交给守护进程去拧。降压更像是给少数关键卡做的精装修,不适合当成全局策略。
后面整套自动调节的故事,都建在功耗墙这把钝器上。它不够锋利,但足够听话——而"听话",对一个要无人值守跑很久的系统来说,比锋利重要得多。
第三层:机房视角下,功耗就是吞吐,就是钱
把镜头从单卡拉远到整座机房,这笔账会变得更重。
有个容易被忽略的事实:今天的 AI 机房,瓶颈往往不在算力,而在电力和散热。一个机柜能塞多少卡、能跑多满,常常不是被 GPU 的算力卡住,而是被这一柜的供电容量和制冷能力卡住。机柜的总供电是按额定上限设计的,水冷回路一分钟能带走多少热也是有上限的——这两个数字才是真正的天花板。在这种"电力受限"的格局里,能效不再是一个环保口号——每一瓦电能换出多少有效吞吐,直接等于你的产能和成本。
这一点会带来一个很实在的连锁反应。假设每张卡靠功耗墙省下一成功耗,一柜八张卡省下的总量,可能就够再塞进一两张卡而不超供电上限;省下来的那部分热,也给水冷回路留出了应对夏天高温、或某个泵降速时的缓冲。换句话说,省下来的功耗不只是省电费,它还直接换成了机柜的承载能力和抗风险余量。同样一笔电力预算,花得省,就能多干活、多扛意外。
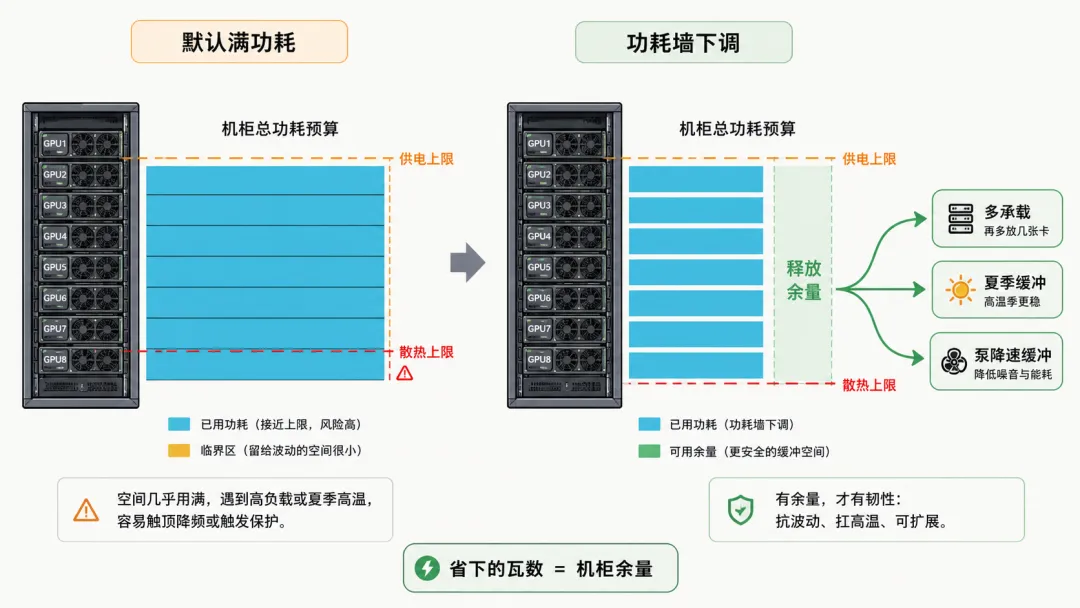
也正因为如此,学界这些年很关注"温度感知的动态电压频率调节(DVFS)"——根据负载和温度实时调电压、调频率,把卡始终摁在能效曲线的甜点上。多项实测显示,相比默认设置,挑对频率能给训练任务省下约 8.7%23.1% 的能耗,给推理任务省得更多,能到约 19.6%26.4%。这些数字背后是同一个道理:默认档位几乎总是偏激进,主动往下调,普遍都有得赚。
但机房和单卡有个关键区别:机房里的卡,负载类型是不一样的。这就引出最实用的一招——别给所有卡、所有时刻都用同一个功耗墙,而要按负载类型分配功耗预算。
具体到我那套守护进程,策略分成三档:
• 常态:不管跑什么,先把功耗墙压到约 0.9。这一刀砍掉的,正是第一层里那段最不值钱的顶端功耗,基本无感,却人人受益。 • 训练独占某卡时:进一步启用一个更低的"空闲功耗限制",约 0.65。训练这种后台任务对延迟根本不敏感,慢一点没人在意,正好拿来换能效和低温——让卡降频慢跑,凉着干活。 • 推理一进来:立刻解除那个低限制,把功耗放回常态档,优先保住在线服务的响应速度。
判断"推理来没来"的信号也很朴素:守护进程盯着每张卡上各进程的 GPU 利用率,一旦有非训练进程的利用率冒过一个很低的阈值(默认 2%),就认定有在线请求落到了这张卡上,马上把它从"省电模式"切回"满血模式"。
这套差异化逻辑,用流程图看最直观:
图里只有两个判断,却把三档策略都串起来了:常态档是地板,训练独占时往下探到省电档,推理一出现就立刻弹回。整张卡的功耗预算,跟着它当下扛的活儿走。
为什么值得这么麻烦地分档?因为前面那些能效数字告诉我们,训练和推理对功耗的"性价比"诉求根本不同。把它们摆在一起对比,策略的逻辑就闭环了:
同一张卡,在不同时刻、扛不同的活儿,就该花不同的功耗。这不是抠门,而是把有限的电力和散热预算,精准地投到最需要它的地方去。
结论:先从那个最难看的顶端走下来
回到开头那次"调慢却没变慢"的实验。
它给我的真正启发,不是"原来能省电",而是默认设置几乎从不站在能效最优的位置上。厂商把卡顶在曲线最难看的那一段,是为了规格表好看;而一座要长期跑生产的机房,完全没必要替这份好看买单。从顶端往下走一步,你几乎什么都没损失,却同时拿到了三样东西:更低的电费、更凉的芯片、更多的供电与散热余量。
更进一步,功耗不该是一刀切的固定值,而该是跟着负载走的预算:常态压掉最不值钱的顶端,训练独占时再往下探,去换能效和低温;推理一来,立刻放回去保性能。这就是这一篇要立住的"为什么"。
但留了个尾巴没解决:功耗墙到底该压到 0.9 还是 0.85?该在多少度、停留多久才动手?这些数,靠人盯着监控手动去拧,既慢又不可能 7×24 守着。真正优雅的做法,是让功耗墙自己长出一只手,实时追着温度走——温度有余量就往下压,温度逼近红线就松开。下一篇,我们就来讲怎么用一个经典的反馈控制器,把冷冰冰的功耗墙,变成一个会自动微调的"温控旋钮"。
边界也别省略:自动调节功耗、按负载差异化分配功耗预算,只应该用在你自己有权管理的设备上。功耗墙拧得不当,轻则任务变慢,重则可能影响线上服务甚至搞坏数据;技术本身中立,后果与责任都在使用者。请别把这些操作伸到不属于你的机器上,也别拿去干扰别人正在跑的系统。

