 夜雨聆风
夜雨聆风如果一个 AI Agent 能连续跑 12 小时实验,它最缺的能力是什么?
不是再多写几段代码,而是知道哪些路走过、哪些坑踩过、什么时候该换方向。
一个自动科研 Agent 的真实瓶颈
现在很多代码 Agent 看起来都很像:读题、写代码、运行、报错、修复,再运行。
这个循环在小任务里够用。但一旦任务变成 Kaggle 风格的机器学习工程(Machine Learning Engineering, MLE),问题就变复杂了。
一个真实的 MLE 任务不是“把 bug 修掉”这么简单。它要决定数据怎么处理、模型用什么、loss 怎么选、训练策略怎么调、要不要 ensemble、提交格式有没有问题,还要在有限时间内不断试错。
这时,Agent 最大的问题不是不会写代码,而是不会组织长期搜索。
今天这篇 MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery,解决的正是这个问题。它把 LLM Agent 从“单次代码生成器”推进成一个带 搜索图、记忆 和 多种代码编辑模式 的自动 ML 工程系统。
论文最醒目的结果是:在 MLE-Bench 75 个任务上,MLEvolve 用 12 小时预算达到 65.3% 平均 medal rate。官方 README 也把它标为 MLE-Bench 榜单第一。
但这篇真正值得看的,不是这个数字本身,而是它背后的系统设计。
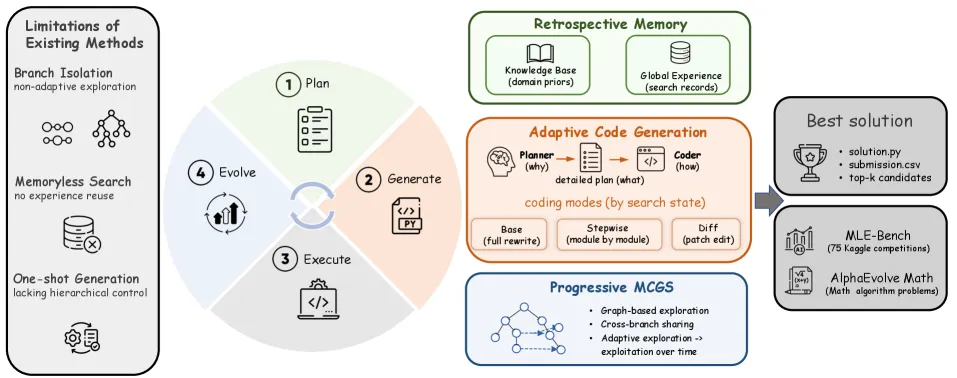
它不是一棵搜索树,而是一张会串门的搜索图
传统 MCTS 很适合解释成一棵树:根节点是初始方案,每个子节点是一次改进,表现好的分支继续往下走,表现差的分支慢慢被放弃。
问题是,机器学习工程不是下棋。不同分支之间经常有可以互相借鉴的经验。
比如一个分支发现“LightGBM 比神经网络稳定”,另一个分支发现“目标变量做 log transform 有帮助”。这两个发现本来应该能合并。但如果搜索结构是一棵硬树,分支之间天然隔离,Agent 很容易在不同分支里重复踩坑。
MLEvolve 的第一个核心模块叫 Progressive Monte Carlo Graph Search(Progressive MCGS)。名字听起来复杂,直觉很简单:别让每条实验路线孤独地跑到底,要允许分支之间共享信息。 这里的关键词是 跨分支流动 和 渐进式收敛。
源码里能看到这个逻辑。SearchNode 不只保存代码,还保存 plan、metric、bug 状态、stage、branch_id、children、reward 等搜索元数据:
PYTHON
@dataclass(eq=False)
class SearchNode(DataClassJsonMixin):
code: str
plan: str
metric: MetricValue
is_buggy: bool
stage: Literal["root", "improve", "debug", "draft", "fusion_draft", "evolution", "fusion"]
visits: int = 0
total_reward: float = 0.0
branch_id: Optional[int] = None这说明 MLEvolve 里的“代码”只是节点的一部分。每个节点同时是一份实验记录:它从哪里来,做了什么改动,结果如何,属于哪个分支,后续还能不能继续扩展。
更关键的是,搜索后期不是一直按普通 UCT 往下走。node_selection.py 里有一个软切换:前期偏探索,后期逐渐转向 Top-K exploitation。
PYTHON
def get_exploration_weight(time_elapsed, total_time,
switch_start=0.5,
switch_end=0.7,
min_weight=0.2):
time_progress = time_elapsed / total_time
if time_progress < switch_start:
return 1.0
elif time_progress < switch_end:
decay_progress = (time_progress - switch_start) / (switch_end - switch_start)
return 1.0 - (1.0 - min_weight) * decay_progress
else:
return min_weight翻译成人话就是:前半程多试方向,中后程逐渐押注表现好的候选。它不像一个只会随机试错的脚本,更像一个比赛工程师:前几小时广撒网,后几小时盯着最有希望的方案打磨。
真正的自进化,靠的是会记笔记
很多 Agent 论文都会说自己有 memory。但 MLEvolve 里的记忆不是聊天记录,而是实验经验。
论文把这部分叫 Retrospective Memory。它包含两层:一层是 cold-start domain knowledge base,用于一开始给任务类型推荐已有经验;另一层是 dynamic global memory,把搜索过程中每个有效节点的 plan、代码摘要、metric、成功/失败标签保存下来。
源码里 GlobalMemoryLayer.save_node() 很直接:
PYTHON
record = MemRecord(
record_id=f"node_{node.id}",
title=f"{node.stage} - {node.id[:8]}",
description=node.plan or "",
method=code_summary,
label=label,
timestamp=timestamp,
)它保存的不是“用户刚才说了什么”,而是一次实验的结构化经验:这个节点是什么阶段、计划是什么、方法摘要是什么、结果标签是什么。
更重要的是,Planner 会用这些记忆来修正下一步计划。planner_with_memory.py 里先生成一个初始 plan,再检索相似的成功记录和失败记录,把它们用于 refine:
PYTHON
similar_success_records = agent_instance.global_memory.retrieve_similar_records(
query_text=query_text,
top_k=2,
label_filter=1,
)
similar_fail_records = agent_instance.global_memory.retrieve_similar_records(
query_text=query_text,
top_k=2,
label_filter=-1,
)这就是 MLEvolve 的“自进化”味道。它不是简单把历史上下文塞进 prompt,而是把历史实验变成可检索、可过滤、可用于规划的经验库。
类比一下,人类 Kaggle 选手也会做类似的事:这个 augmentation 上次有效,那个 loss 上次让验证集崩了,某个后处理策略只在 tabular 任务里有用。MLEvolve 只是把这套经验管理显式写进系统。
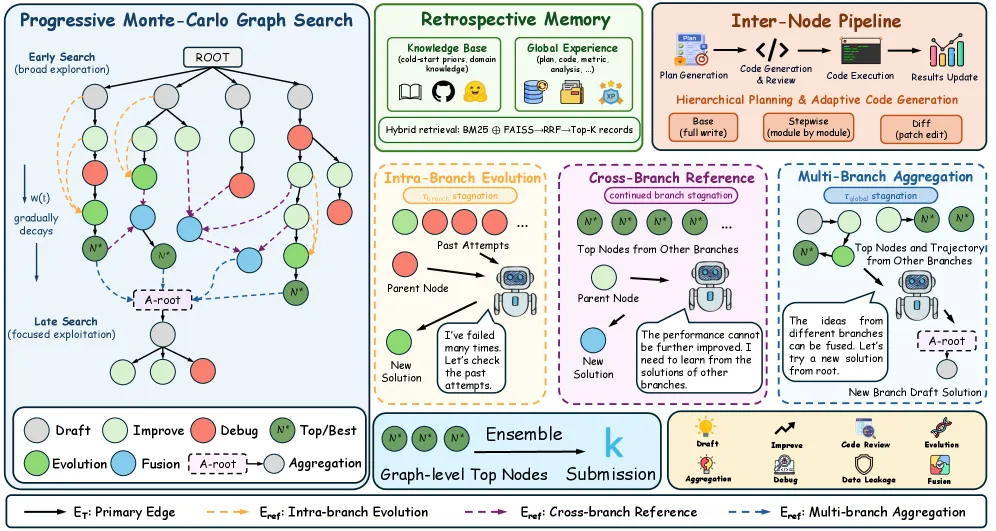
停滞之后,不是继续微调,而是换一种进化方式
这篇论文还有一个很实用的判断:不是所有“改进”都应该长一个样。
如果一个分支刚开始跑,普通 improve 就够了。当前方案有 bug,就走 debug。分支卡住了,就应该换策略:要么沿着这个分支的历史轨迹做 evolution,要么从别的分支拿成功经验做 fusion。
在 agent_search.py 里,调度逻辑很清楚:
PYTHON
if is_branch_stagnant(self, parent_node.branch_id, threshold=stagnation_threshold):
if evo_ok and fus_ok:
if random.random() < self.acfg.fusion_vs_evolution_prob:
result_node = fusion_agent.run(self, parent_node)
else:
result_node = evolution_agent.run(self, parent_node)
elif fus_ok:
result_node = fusion_agent.run(self, parent_node)
elif evo_ok:
result_node = evolution_agent.run(self, parent_node)
else:
result_node = improve_agent.run(self, parent_node)这里最关键的词是 stagnant。
一个普通 Agent 看到分数不涨,可能继续让 LLM “try another improvement”。但 MLEvolve 会明确判断:这个分支是不是停滞了?如果停滞,就不要再做小修小补。
improve_agent.py 里的 prompt 也很有意思。它把改动分成三层:Tier 1 是训练细节优化,Tier 2 是组件和表示变化,Tier 3 是系统级范式转移。连续不涨时,它会要求模型别再只调学习率,而要提出 Tier 2 或 Tier 3 的变化。
这很像真实工程里的复盘:如果模型已经连续几轮没有提升,你不能一直说“再调一下 batch size”。你要问的是:是不是模型类型错了?是不是目标建模错了?是不是需要 ensemble、pseudo-labeling 或完全不同的数据流?
代码生成也不是一种模式打天下
MLEvolve 的第三个核心点是 Hierarchical Planning with Adaptive Code Generation。
直觉上,它把“想做什么”和“怎么改代码”拆开。
Planner 先决定要改哪些组件、为什么改、保留哪些东西;Coder 再根据计划实现。这样做的好处是,Agent 不会一边想战略、一边直接大段重写代码,把实验因果关系弄乱。
代码仓库里也能看到三种生成模式:
PYTHON
Each module implements a different code generation strategy:
- base_coder: Single-shot plan + code generation
- stepwise_coder: Multi-agent stepwise generation
- diff_coder: Diff-based code generation最值得注意的是 diff mode。默认配置里它是打开的:
YAML
agent:
steps: 500
time_limit: 43200
use_diff_mode: True
use_stepwise_generation: True
use_evolution: True
use_fusion: True
use_global_memory: True这几个配置其实很能说明系统哲学:12 小时、500 步、开 diff、开记忆、开 evolution、开 fusion。
也就是说,MLEvolve 假设任务是长周期的,代码会反复演化,所以每次都全文重写并不合适。很多时候,更稳的方式是先规划,再局部 patch。
diff_generate_and_apply() 的流程也很工程化:先把 planner 的结构化结果格式化成 improvement plan,再让 LLM 生成 SEARCH/REPLACE 式 diff,最后尝试 apply,失败时重试。
这解决了一个很现实的问题:自动 ML 工程里,代码不是一次性产物,而是一个不断被小心修改的实验对象。
结果为什么强?
论文和官方 README 给出的主结果是:MLEvolve 在 MLE-Bench full set 的 75 个任务上,使用 Gemini-3.1-Pro-preview,12 小时预算,达到 65.3±0.8% average medal rate。
相比很多 24 小时预算的系统,它的一个卖点是时间更短。论文还报告它在数学优化任务上能和 AlphaEvolve 类方法竞争,说明这个框架不只适用于 Kaggle 式 ML pipeline,也能迁移到代码形式的算法优化任务。
不过我更愿意把结果理解为一个系统结论:当任务需要长期实验时,Agent 的能力上限很大程度取决于搜索组织能力,而不是单次代码生成能力。
单次生成能力当然重要。没有强 LLM,代码质量上不去。但在 MLE-Bench 这种任务里,真正拉开差距的往往是:它有没有保存失败经验?会不会避免重复试错?能不能在分支之间迁移思路?到后半程能不能集中资源打磨高分方案?
MLEvolve 给出的答案是:这些都应该变成系统模块,而不是靠 prompt 里一句“be smart”。
需要冷静看的地方
这篇很值得读,但也不能直接理解成“自动机器学习科学家已经来了”。
第一,它的主实验仍然依赖很强的闭环评测环境。MLE-Bench 给了明确任务、数据、提交格式和验证信号。真实科研里,很多问题没有这么清楚的自动评价函数。
第二,它使用的资源并不轻。论文实现细节提到每个任务最多 500 个 expansion steps、12 小时、21 vCPU、234GB RAM 和单张 H200 GPU。对个人开发者来说,这是系统研究,不是轻量工具。
第三,代码里的很多策略本质上还是工程启发式。比如什么时候进入 Top-K exploitation,什么时候触发 fusion/evolution,阈值如何设置,这些都可能影响很大。
但这不削弱它的价值。恰恰相反,它说明自动科研 Agent 的进展并不只来自“模型更聪明”,还来自一整套实验管理、搜索调度和经验复用工程。
从业者能学到什么
如果你在做 coding agent、AutoML agent 或自动实验系统,MLEvolve 至少给出四个启发。
第一,别把 memory 做成聊天记录。 真正有用的记忆应该是实验记录:plan、代码摘要、metric、成功/失败标签、父节点结果。
第二,搜索结构比 prompt 更重要。 单纯让模型“多想想”不够,系统要定义什么时候探索、什么时候利用、什么时候跨分支融合。
第三,代码生成要分模式。 初始方案可以全文生成,成熟方案更适合 diff patch,复杂方案可以 stepwise 拆成数据、模型、训练等模块。
第四,停滞检测应该显式化。 如果分数不涨,系统需要触发更大幅度的策略变化,而不是继续随机微调。
MLEvolve 最有价值的地方,是它把这些经验写成了代码。
它不是在说“LLM 可以替代 Kaggle 工程师”,而是在展示:如果要让 Agent 像一个认真工作的 Kaggle 工程师,它至少要会搜索、会复盘、会记笔记、会在关键时刻换方向。
论文信息
标题:MLEvolve: A Self-Evolving Framework for Automated Machine Learning Algorithm Discovery
作者:Shangheng Du, Xiangchao Yan, Jinxin Shi, Zongsheng Cao, Shiyang Feng, Zichen Liang, Boyuan Sun, Tianshuo Peng, Yifan Zhou, Xin Li, Jie Zhou, Liang He, Bo Zhang, Lei Bai
论文:https://arxiv.org/abs/2606.06473
代码:https://github.com/InternScience/MLEvolve
项目页:https://internscience.github.io/MLEvolve/
分类:cs.AI, cs.CL
关注「论文收割机」,每周为你精选最值得关注的 AI 论文。
