 夜雨聆风
夜雨聆风你有没有想过,一个为"安全"而生的AI工具,最强大的用法可能是"攻击"?
上个月,一个叫Calif的帕洛阿尔托安全团队做了件事:他们用Anthropic的Mythos模型,在不到一周内,绕过了Apple M5芯片花了5年设计的内存完整性保护机制(Memory Integrity Enforcement)[1]。5年对5天。
更令人不安的是,同一周,FT报道NSA已将Mythos部署到机密网络,6名Anthropic工程师被嵌入NSA内部,专门为"进攻性网络行动"定制模型——目标是中国和伊朗的网络基础设施[2]。而Anthropic这家公司的全称使命声明里写着"AI safety"。
🔑 费曼摘要:AI发现漏洞的速度正在碾压人类修复的速度。这不是一个技术问题——它是一个治理速度问题。我们造出了发现漏洞的"原子弹",但还没来得及写"核不扩散条约"。

一、补丁瓶颈:8.9%的修复率意味着什么
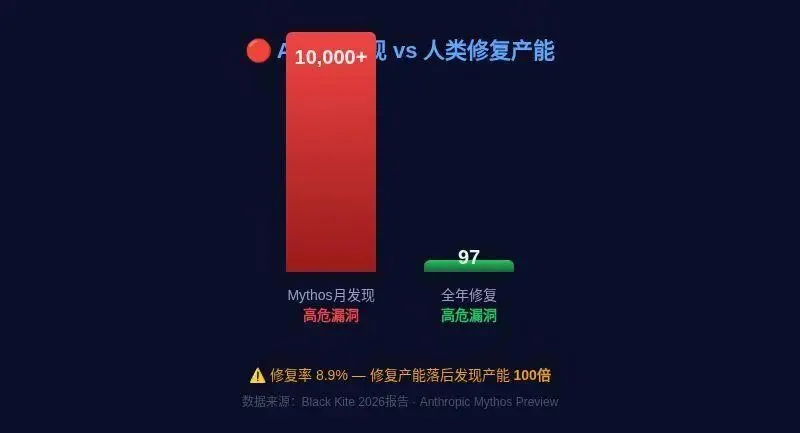
先看一组数据。
Anthropic的Project Glasswing在4月7日启动,最初约50个合作伙伴(AWS、Apple、Google、Microsoft、Cloudflare),投入1亿美元使用额度,用Claude Mythos Preview扫描代码库[3]。
一个月后的5月22日,Anthropic发布了漏洞披露仪表盘。数字令人窒息:
| 指标 | 数据 |
| 潜在漏洞被标记 | 23,019个(内部扫描1,000个开源项目) |
| 高危/严重级别(内部) | 6,202个 |
| 高危/严重(合作伙伴报告) | 10,000+个 |
| 已修复 | 97个 |
| 修复率 | 97/1,094 = 8.9% |
你没看错。97 / 1,094个高危漏洞 = 8.9%的修复率。如果算上全部23,019个候选,修复率接近于零。
🔗 推导:AI发现漏洞产能过剩 → 修复产能严重不足 → 大量零日漏洞躺在数据库里 → 攻击者的"弹药库"持续膨胀 → 不是"修不好"的问题,是"修不过来"的问题。
💡 洞察:这不是Anthropic的问题。这是整个行业的结构性困境——AI发现漏洞的能力已经指数级超越人类修复漏洞的产能。不是"发现了会不会修"的问题,是"修不过来"的问题。
为什么修不过来?Black Kite的2026年报告给出了背景:漏洞利用首次超过凭证窃取,成为第一大初始攻击向量,占全部违规事件的31%。关键CVE的平均修复时间已增至43天。CISA已知被利用漏洞目录中,只有26%得到了完全修复,比去年的38%还低[5]。
连Apple这种级别的公司都挡不住——M5芯片的内存完整性保护(MIE),5年工程投入,被一个安全初创公司用Mythos在5天内绕过[1]。
💡 本质:这不是某个公司的能力问题,而是速度维度的结构性错配——AI发现漏洞的产能是指数增长的,人类修复漏洞的产能是线性的。两条曲线已经交叉,且差距只会越来越大。
二、从Glasswing到NSA:工具中性的神话已经破产

到这里,你可能会说:"Anthropic做的是好事啊,发现漏洞帮大家修,这不是安全吗?"
问题在于,同一把锤子既可以修补墙,也可以砸穿墙。
FT的报道揭示了一个关键细节:Anthropic和五角大楼的争端始于2026年1月,当时双方正在谈一笔2亿美元的合同[2]。Anthropic拒绝让Claude被用于大规模国内监控和全自主致命武器——但他们同意让Mythos被用于"针对外国网络的进攻性行动"。
作为交换,6名Anthropic工程师被嵌入NSA,帮助定制Mythos用于"专业化应用"——FT的原话,大概率是为特定类型的网络攻击做定制[2]。
| 维度 | 安全用途(Glasswing) | 攻击用途(NSA) |
| 目标 | 修复自己的漏洞 | 渗透他人的系统 |
| 用户 | 合作伙伴企业 | NSA / CYBERCOM |
| 目的 | 降低攻击面 | 扩大攻击能力 |
| 伦理框架 | 负责任披露 | 进攻性网络行动 |
我的判断:这不是一个"好公司变坏了"的简单叙事。这是AI安全领域面临的根本悖论——发现漏洞的能力和利用漏洞的能力,在技术上几乎不可分割。你不可能造一把"只能修墙不能砸墙"的锤子。
🔗 推导:理解代码意图 → 发现设计假设的弱点 → 构建绕过路径 → 同一个能力,修墙用还是砸墙用?→ 取决于使用者而非工具 → 技术层面的"军控"在物理上不可能。
我在课堂上学到一个经典的安全工程原则:攻击和防御是硬币的两面。一个能发现零日漏洞的AI,天然就具备制造零日漏洞攻击的能力。区别只在于使用者是谁,而不在于工具本身。
三、三层困境:为什么这不是简单的"AI伦理"问题
这个事件揭示的不是一家公司的道德选择,而是AI安全治理的三层结构性困境。
💡 本质洞察:三层困境的本质是三个速度的不匹配——AI发现(秒级) vs 人类修复(月级) vs 制度响应(年级)。当发现速度碾压修复和治理两个数量级以上时,系统的稳态必然被打破。
🔴 第一层:速度悖论。AI发现漏洞的速度远超人类修复。Mythos一个月发现10,000+高危漏洞,人类维护者一年修97个。这不是线性差距,是数量级差距。我们正在制造一个"漏洞发现产能过剩"的时代——发现太多,修复太少,大量零日漏洞躺在数据库里等待被利用。
🟠 第二层:双用途困境。发现M5芯片漏洞的技术,和利用M5芯片漏洞的技术,在代码层面几乎相同。你不能只出售"发现"能力而阻止"利用"能力。这不是伦理问题,是物理问题——就像你不能制造一把"只切菜不伤人"的刀。
🟡 第三层:治理时滞。曼哈顿计划3年造出原子弹,但核不扩散条约花了20年才签订。AI安全的"原子弹"已经在4月7日炸响了(Glasswing启动),我们的"条约"在哪里?目前没有任何国际框架约束AI在网络空间的攻防应用。

🌉 概念桥接:这和核武器的历史惊人相似。奥本海默团队最初的目标是"阻止纳粹先造出原子弹"(防御),但广岛证明,同一个工具在"防御"和"攻击"之间的切换只需要一个命令。Mythos正在经历同样的转变——从"帮我们找到墙上的裂缝"到"帮我们砸穿别人的墙"。
四、清醒的现实:什么条件下"AI安全"会变成"AI武器"
不是所有AI安全工具都会变成武器。但以下三个条件同时满足时,转化几乎是必然的:
条件一:发现能力的阈值效应。当AI能在极短时间内(<1周)发现人类多年构建的安全防线漏洞时,攻击者的"性价比"会远超防御者。5天破解5年的MIE → 攻击者的ROI极高。
条件二:军事需求与商业利益的交叉。Anthropic 6月1日刚提交IPO S-1文件,估值9,650亿美元[6]。NSA的2亿美元合同可能只是开始。当你是一家即将上市的公司的CEO,面前是"拒绝军事合同但放弃巨额收入"还是"接受但附条件"——大多数人会选后者。
条件三:治理框架的真空。目前没有国际法、行业标准或技术约束阻止AI安全工具被用于攻击。联合国AI安全框架还停留在"原则"层面,没有任何执行力。美国国内对AI在网络空间的军事应用也没有明确立法。
⚠️ 什么条件下我的判断会失效? 如果以下任何一条成立,"AI安全→武器化"的转化可能被阻止:
- 1. 技术层面:出现了"只能发现不能利用"的安全扫描技术(目前理论上不可能)
- 2. 政策层面:国际AI网络空间行为准则在12个月内签署(以目前的谈判速度看,概率<10%)
- 3. 市场层面:Anthropic因声誉风险主动终止NSA合作(IPO前夕,概率极低)
五、利益方格局:谁在推动,谁在旁观

这件事不是Anthropic一家的故事。整个AI安全行业正在经历一次"军火化"分叉。
| 利益方 | 立场 | 动机 |
| **Anthropic** | 有条件接受 | 2亿美元合同 + IPO估值需要收入增长 |
| **NSA/五角大楼** | 积极采购 | 网络攻击成本骤降(比雇佣红队便宜100倍) |
| **独立安全研究者** | 分裂 | 一部分转向防御,一部分被高薪招入进攻方 |
| **开源安全社区** | 被动 | 修复产能跟不上,被迫"救火" |
| **普通开发者/企业** | 无意识 | 不知道自己的产品正被AI扫描漏洞 |
🔗 推导:AI安全工具"军火化" → 防御方和攻击方的成本不对称反转 → 传统"攻防平衡"被打破 → 中小企业(没有Anthropic级别的安全团队)成为最大受害者 → 安全的民主化倒退——只有大公司买得起AI防御,小公司裸奔。
六、开发者视角:你的Agent产品需要安全审计
作为AI应用开发者,这个事件对我的直接影响是:Agent产品的安全审计从"可选"变成"必选"。
三层可执行的架构建议:
今天就能做的:
- • 检查你的Agent是否在日志中记录了所有外部API调用——Mythos级别的漏洞发现工具需要大量代码扫描,如果有人用你的Agent做类似的事,你至少要知道
- • 在Agent的prompt中加入安全约束:"不生成针对特定系统的exploit代码"
本周做的:
- • 为你的OPC产品设计一个"负责任使用"条款——不是形式主义的ToS,是真正能在代码层面检测和阻断攻击性用途的机制
- • 审计你的依赖项——Glasswing发现23,019个漏洞的地方,就是开源软件生态。你用的每个库都在射程之内
下周做的:
- • 在CI/CD中集成自动化漏洞扫描——不一定要用Mythos,但至少要用Snyk/Dependabot级别的工具
- • 关注CISA KEV目录更新——26%的修复率意味着74%的已知漏洞还在暴露
七、适合你吗?四条路径
📊 路径1:你是AI安全研究者 → Mythos事件是分水岭。研究方向应从"如何发现漏洞"转向"如何修复漏洞的流程自动化"——发现产能已经过剩,修复产能是瓶颈。
📊 路径2:你是独立开发者/OPC → 你的产品依赖的开包组件比你想象的脆弱。花1天审计依赖,比花1天写新功能更重要。Glasswing发现的10,000+漏洞就在你用的npm/pip包里。
📊 路径3:你是AI产品经理 → "负责任AI"不再只是PR话术。你的产品如果具备代码分析能力,需要从设计层面考虑双用途风险——在产品而非法务层面做约束。
📊 路径4:你是教育工作者 → 这是我下学期AI伦理课的案例之一。不是讲"AI危险",而是让学生理解"工具中性的神话已经破产"——当一个工具的防御用途和攻击用途在技术层面不可分割时,"我们只做防御"的承诺在物理上就不可能兑现。
八、深层剖析
技术层:Mythos Preview的核心能力是对代码库进行语义级别的安全分析——不是正则匹配漏洞模式,而是理解代码的意图和执行路径。这让它在发现逻辑漏洞(而非已知CVE模式)方面远超传统工具。M5的MIE绕过就是典型的逻辑漏洞利用——不是"这段代码有bug",而是"这段安全机制的设计假设可以被这样打破"。
产品层:Anthropic的产品策略是分层的——Glasswing面向防御(合作伙伴扫描),Mythos本身可用于攻击(NSA部署),但底层模型是同一个。这和OpenAI的"API开放但附使用政策"是同样的架构——技术不分用途,约束在应用层。问题是应用层的约束在政府合同面前几乎不存在。
生态层:97/1094的修复率揭示了一个更深层的问题——开源软件维护者的承载力已经见底。这些漏洞不是维护者不知道,而是没有人力去修。AI加速了发现,但没有加速修复。如果Anthropic真的关心安全,投入不应该是1亿美元的使用额度去发现更多漏洞,而是投入同样级别的资源去帮助修复已有的漏洞。
🧪 自测题
- 1. Mythos在Project Glasswing中发现了多少个高危/严重级别漏洞?修复了多少?
- 2. 为什么说"发现漏洞的能力和利用漏洞的能力在技术上几乎不可分割"?
- 3. 补丁瓶颈(8.9%修复率)反映的根本问题是什么?
→ 答案
- 1. 10,000+高危/严重漏洞(合作伙伴报告),其中1,094个经确认的高危中只修复了97个。
- 2. 因为"发现"一个漏洞需要理解代码的执行路径和设计假设,而"利用"同一个漏洞需要的理解完全一样——区别只在于你是用这个理解去修补还是去攻击。技术上无法区分。
- 3. 不是技术问题,是治理速度问题——AI发现漏洞的速度(数万/月)远超人类修复的速度(数十/月),整个漏洞管理生态的承载力已经见底。
我是 ,AI高校教师 × AI一线实践者。
这里是 —— 用交叉视角,把AI前沿翻译成你能用的认知。
⭐ 觉得有用?转发给正在做AI产品的朋友。
🔗 项目开源:HuangYet-Sam[1]
参考来源
[1] Calif团队用Mythos绕过Apple M5 MIE,5天破解5年防护 — ton-technotes, 2026-05-21
[2] NSA部署Mythos用于进攻性网络行动,6名Anthropic工程师嵌入NSA — FT/TechCrunch, 2026-06-05
[3] Project Glasswing启动:50合作伙伴,$100M使用额度 — Anthropic官方, 2026-04-07
[4] Glasswing漏洞披露仪表盘:23,019候选/6,202高危/97已修复 — Anthropic/Devlery, 2026-05-22
[5] 漏洞利用超越凭证窃取成第一大初始攻击向量,中位修复时间43天 — Black Kite, 2026
[6] Anthropic提交IPO S-1文件,估值$965B — The Guardian/NYT, 2026-06-01
引用链接
[1] HuangYet-Sam: https://github.com/HuangYet-Sam
